2024年五一杯数学建模
C题 煤矿深部开采冲击地压危险预测
原题再现:
“煤炭是中国的主要能源和重要的工业原料。然而,随着开采深度的增加,地应力增大,井下煤岩动力灾害风险越来越大,严重影响着煤矿的安全高效开采。在各类深部煤岩动力灾害事故中,冲击地压已成为威胁中国煤矿安全生产最重要的灾害之一,冲击地压事故易造成严重的人员伤亡和财产损失。近年来,研究人员进行了大量深入的研究,采取了许多防控措施,中国煤矿安全形势持续稳步改善。但是,冲击地压事故仍时有发生,煤矿安全形势依然严峻,冲击地压的监测预警和有效防控仍是煤矿安全生产中亟待解决的科技问题。在深部煤矿开采过程中,可以监测声发射(AE)和电磁辐射(EMR)信号,电磁辐射和声发射传感器每30秒采集一个数据,可通过这些数据的变化趋势判断目前工作面或巷道是否存在冲击地压危险。电磁辐射和声发射数据随着采煤工作面的推进波动,一般在冲击地压发生前数天(如0-7天,即大约冲击地压发生前7天内)会有一些趋势性前兆特征,因此我们将电磁辐射和声发射数据分为5类,(A)正常工作数据;(B)前兆特征数据;©干扰信号数据;(D)传感器断线数据;(E)工作面休息数据,其中,A、B、C 类为工作面正常生产时的数据,D类为监测系统不正常时的数据,E类为停产期间的数据。附件1给出了2019年1月9日-2020年1月7日采集的电磁辐射和声发射数据,并且标记出了所对应的A、B、C类以及D或者E类(D/E)数据。请建立数学模型,完成以下问题:
“问题1:如图1,已知现场工作面的部分电磁辐射和声发射信号中存在大量干扰信号,有可能是工作面的其他作业或设备干扰等因素引起,这对后期的电磁辐射和声发射信号处理造成了一定的影响。应用附件1和2中的数据,完成以下问题。

“(1.1) 建立数学模型,对存在干扰的电磁辐射和声发射信号进行分析,分别给出电磁辐射和声发射中的干扰信号数据的特征(不少于3个)。
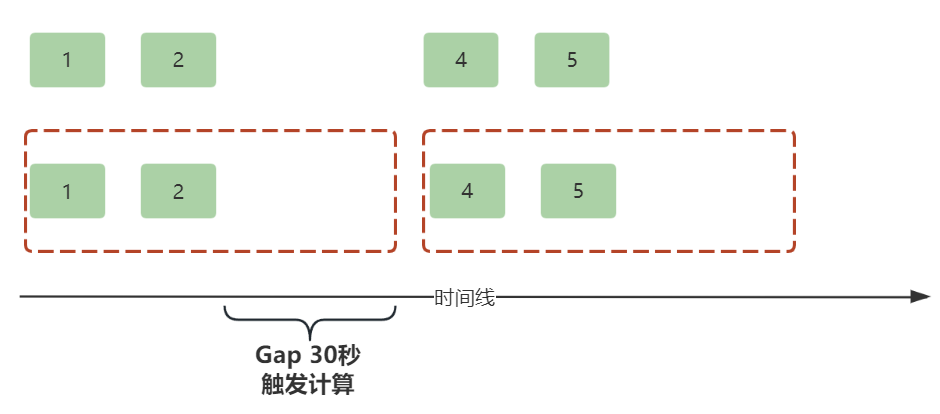
“(1.2) 利用问题(1.1)中得到的特征,建立数学模型,对2022年5月1日-2022年5月30日的电磁辐射和2022年4月1日-2022年5月30日及2022年10月10日-2022年11月10日声发射信号中的干扰信号所在的时间区间进行识别,分别给出电磁辐射和声发射最早发生的5个干扰信号所在的区间,完成表1和表2。

“问题2:已知在发生冲击地压危险前约7天内,电磁辐射和声发射信号存在随时间循环增大的趋势(如图2所示),这类信号我们称为前兆特征信号。在出现前兆特征信号之后的约7天内,有可能发生冲击地压,所以一般情况下出现前兆特征信号之后,会采取一定措施尽可能的防止冲击地压发生。应用附件1和2中的数据,完成以下问题。

“(2.1) 建立数学模型,对电磁辐射和声发射信号中的前兆特征信号进行分析,重点分析信号的变化趋势,分别给出电磁辐射和声发射信号危险发生前(前兆特征)数据的趋势特征(不少于3个)。
“(2.2) 利用问题(2.1)中得到的特征,建立数学模型,对2020年4月8日-2020年6月8日及2021年11月20日-2021年12月20日的电磁辐射和2021年11月1日-2022年1月15日声发射信号中的前兆特征所在的时间区间进行识别,分别给出电磁辐射和声发射信号最早发生的5个前兆特征信号所在的时间区间,完成表3和表4。


“问题3:为了尽早的识别前兆特征信号,在前兆特征信号出现的第一时间发出预警,需要在每次数据采集的时刻对危险进行预判。附件3给出了一些非连续时间段采集的电磁辐射和声发射信号数据。请建立数学模型,给出附件3中的每个时间段最后时刻出现前兆特征数据的概率,完成表5。

整体求解过程概述(摘要)
“虽然煤炭是我国主要的能源和工业原料,但随着开采深度的增加,地应力增加,导致地下煤岩动力灾害的风险增加。岩爆是最严重的灾害之一。虽然采取了预防和控制措施,但事故仍然时有发生,煤矿安全形势严峻。因此,监测、预警和有效防治仍然是亟待解决的科技问题。声发射和电磁辐射信号监测可以及时判断岩爆危险性,并每隔30秒提供数据。通常,在冲击地压发生的前几天,会出现一些趋势前兆特征,这为预防提供了可能。
“问题1:首先,我们分析了本文提出的干扰信号。从原理图中可以看出,干扰信号的值是离群值。在数据的清理和降噪过程中,我们可以将离群点作为干扰信号集进行分离。我们通过Q-Q图筛选了总共1432个离群值和离群值,然后过滤掉连续时间段中的干扰。最后得到381个干扰信号。得到了干扰信号的几个特征点。对于处理的数据,我们将把离群值返回到0,并将它们视为缺失值。对于缺失的值,我们将使用插值来完成它们。
“问题2:首先,我们分析了本文提出的信号前兆特征,发现本文所强调的前兆特征是周期数据在一定时间段内连续发生的时候。因此,前兆特征必须包括连续性和周期性的基本特征。考虑到周期时间序列,我们使用sarima分解时间序列模型对原始数据进行分解,提取前兆发生时产生的特征,并在此特征提取模型中预测测试集数据,以查看它是否是前兆特征数据。因此,在提取时间序列分解模型后,我们对原始数据进行迭代预测,最终获得4-10、5-8、5-10、5-28、5-1。前体特征首次出现的三个时间点。
“问题3:最后一个问题是结合前两个问题的模型。首先,我们使用样条插值算法来完成数据。由于数据波动性太强,很容易导致时间序列模型的白噪声失效,因此我们使用滤波算法对其进行平滑,然后将其代入问题2中建立的时间序列分解模型中进行迭代求解。最终结果为0.92,0.51,0,1,0.93。
模型假设:
“假设1:电磁辐射和声发射信号的干扰信号具有特定的频率范围特性。
“合理性:许多设备和操作在运行过程中会产生特定频率的电磁辐射和声发射信号,这些信号可能会在特定范围内干扰目标信号,因此考虑频率范围是合理的。
“假设2:干扰信号在时间上具有不规则的周期变化。
“合理性:由于各种因素,许多工作和设备的运行可能会产生干扰信号。根据固定的时间表,这种干扰信号可能不会发生。因此,合理地考虑干扰信号具有不规则的周期变化。
“假设3:干扰信号的强度可能随着时间或特定操作的进展而变化。
“合理性:不同的操作或设备可能产生不同强度的干扰信号,干扰信号的强度可能随着操作的进展或设备状态的变化而变化。
“假设四:工作面上存在与其他作业或设备相关的信号特征,以区分干扰信号和目标信号。
“合理性:野外工作面可能有各种作业或设备,它们产生的信号可能具有特定的特征,可以用来区分干扰信号和目标信号。
问题分析:
“问题1分析
“首先,对本文提出的干扰信号进行分析,通过原理图可以得出干扰信号的值是离群值的结论。在数据的清洗和降噪过程中,我们可以将离群值作为干扰信号集进行分离。通过Q-Q图共筛选出1432个离群点和离群点,然后滤除连续时间段内的干扰,最终得到381个时间点的干扰信号。得到了干扰信号的几个特征点。对于处理的数据,我们将把离群值返回到0,并将它们视为缺失值。对于缺失的值,我们将使用插值来完成它们。
“问题2分析
“通过对本文提出的信号前兆特征的分析,发现本文所强调的前兆特征是在一定时间段内连续出现的周期性数据。因此,前兆特征必须包括连续性和周期性的基本特征。考虑到周期时间序列,在该特征提取模型中,使用sarima分解时间序列模型对原始数据进行分解,提取前兆发生时产生的特征,并预测测试集数据是否为前兆特征数据。因此,在提取时间序列分解模型后,我们对原始数据进行迭代预测,最终获得较为理想的前兆特征时间点。
“问题3分析
“最后一个问题是结合前两个问题的模型。首先,我们使用样条插值算法来完成面对不连续数据的数据。由于数据波动性太强,很容易导致时间序列模型的白噪声失效,因此我们使用滤波算法对其进行平滑,然后将其代入问题2中建立的时间序列分解模型中进行迭代求解。最终结果为0.92,0.51,0,1,0.93。
模型的建立与求解整体论文缩略图

全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:
TF=ismissing(data1);
a=sum(TF,1);
b=sum(TF,2);
% ind=find(b>3);
[x_1,y_1]=find(TF==1) %上面为缺失值寻找
Q1=zeros(14,1);
Q2=zeros(14,1);
tmp1=[14,5433]
ind1=[14,5433]
lb=zeros(14,1);
ub=zeros(14,1);
IQR=zeros(14,1);
% clean=clean.'
% for i=1:14
% Q1(i)=prctile(clean(i,:),25);
% Q2(i)=prctile(clean(i,:),75);
% IQR(i)=Q2(i)-Q1(i);
% lb(i)=Q1(i)-1.5*IQR(i);
% ub(i)=Q2(i)+1.5*IQR(i);
% tmp1=find((clean(:,i)<lb(i))|(clean(:,i)>ub(i)));
% ind1=find(tmp1)
% end %寻找异常值,并赋予nan
对缺失值数据进行填补
V1=mode(data1.VarName9);
V2=mode(data1.VarName10);
V3=mean(data1.VarName18,'omitnan');
V4=mean(data1.VarName21,'omitnan');
V5=mean(data1.VarName22,'omitnan');
fillmissing(data1.VarName9,'constant',V1);
fillmissing(data1.VarName10,'constant',V2);
fillmissing(data1.VarName18,'constant',V3);
fillmissing(data1.VarName21,'constant',V4);
fillmissing(data1.VarName22,'constant',V5);
对数据进行LTC时序分解分析处理,并筛选出重要性较大的部分数据作为该题的选择特征
trainingData=data1;
inputTable = trainingData;
predictorNames = {'VarName1', 'VarName2', 'VarName3', 'VarName4', 'mos', 'VarName6', 'VarName7', 'ARPU', 'VarName9', 'VarName10', 'MB', 'VarName12', 'VarName13', 'VarName14', 'VarName15', 'ARPU1', 'MOU', 'VarName18', 'GPRSKB', 'GPRSKB1', 'VarName21', 'VarName22', 'ARPU2', 'MOU1', 'VarName25', 'VarName26', 'VarName27', 'VarName28', 'VarName29', 'VarName30', 'VarName31', 'VarName32', 'VarName33', 'VarName34', 'VarName35', 'VarName36', 'VarName37', 'VarName38', 'VarName39', 'G', 'VarName41', 'VarName42'};
predictors = inputTable(:, predictorNames);
response = inputTable.VarName43;
[idx,importance]=fscmrmr(predictors,response);
% figure(1);
% bar(importance(importance>0.17))
% importance=importance./sum(importance(:))
% figure(1);
imp_x=find(importance>0.0017);
x_table=categorical(predictorNames(imp_x));
y_table=importance(imp_x);
figure1 = figure('NumberTitle','off','Name','Figure','Color',[1 1 1]);
axes1 = axes('Parent',figure1);
hold(axes1,'on');
bar(x_table,y_table,'FaceColor',[0 0.447058826684952 0.74117648601532],...'EdgeColor',[0 0 1]);
box(axes1,'on');
hold(axes1,'off');
set(axes1,'FontName','Times New Roman','FontSize',12,'FontWeight','bold');
% impdate=importance(importance>0.17)
rng(520);
MinLeafSize=1:15;
NumLearningCycles=5:5:50;
num_i=length(MinLeafSize);
num_j=length(NumLearningCycles);
RMSE_Bag=zeros(num_i,num_j);
R2_Bag=zeros(num_i,num_j);%设置可视化进度条
mywaitbar = waitbar(0);
TOTAL_NUM = num_i*num_j;
now_num = 0; for i=1:num_ifor j=1:num_j
template = templateTree(...'MinLeafSize', MinLeafSize(i));
regressionEnsemble = fitrensemble(...predictors, ...response, ...'Method', 'Bag', ...'NumLearningCycles', NumLearningCycles(j), ...'Learners', template);% 使用预测函数创建结果结构体
predictorExtractionFcn = @(t) t(:, predictorNames);
featureSelectionFcn = @(x) x(:,includedPredictorNames);
ensemblePredictFcn = @(x) predict(regressionEnsemble, x);
trainedModel.predictFcn = @(x) ensemblePredictFcn(featureSelectionFcn(predictorExtractionFcn(x)));% 向结果结构体中添加字段
trainedModel.RequiredVariables = {'ARPU', 'ARPU1', 'ARPU2', 'G', 'GPRSKB', 'GPRSKB1', 'MB', 'MOU', 'MOU1', 'VarName1', 'VarName10', 'VarName12', 'VarName13', 'VarName14', 'VarName15', 'VarName18', 'VarName2', 'VarName21', 'VarName22', 'VarName25', 'VarName26', 'VarName27', 'VarName28', 'VarName29', 'VarName3', 'VarName30', 'VarName31', 'VarName32', 'VarName33', 'VarName34', 'VarName35', 'VarName36', 'VarName37', 'VarName38', 'VarName39', 'VarName4', 'VarName41', 'VarName42', 'VarName6', 'VarName7', 'VarName9', 'mos'};
trainedModel.RegressionEnsemble = regressionEnsemble;
trainedModel.About = '此结构体是从回归学习器 R2021a 导出的训练模型。';
trainedModel.HowToPredict = sprintf('要对新表 T 进行预测,请使用: \n yfit = c.predictFcn(T) \n将 ''c'' 替换为作为此结构体的变量的名称,例如 ''trainedModel''。\n \n表 T 必须包含由以下内容返回的变量: \n c.RequiredVariables \n变量格式(例如矩阵/向量、数据类型)必须与原始训练数据匹配。\n忽略其他变量。\n \n有关详细信息,请参阅 <a href="matlab:helpview(fullfile(docroot, ''stats'', ''stats.map''), ''appregression_exportmodeltoworkspace'')">How to predict using an exported model</a>。');% 提取预测变量和响应
% 以下代码将数据处理为合适的形状以训练模型。
%
inputTable = trainingData;
predictorNames = predictors.Properties.VariableNames(:);
predictors = inputTable(:, predictorNames);
response = inputTable.VarName43;% 执行交叉验证
partitionedModel = crossval(trainedModel.RegressionEnsemble, 'KFold', 10);% 计算验证预测
validationPredictions = kfoldPredict(partitionedModel);% 计算验证 RMSE
validationRMSE = sqrt(kfoldLoss(partitionedModel, 'LossFun', 'mse'));%计算R2
BagR2=1-sum(( validationPredictions - response ).^2,'omitnan') / sum((response - mean(response,'omitnan')).^2,'omitnan');%导出数据
RMSE_Bag(i,j)=validationRMSE;
R2_Bag(i,j)=BagR2;%更新进度
now_num = now_num+1;
mystr=['Loading...',num2str(100*now_num/TOTAL_NUM),'%'];
waitbar(now_num/TOTAL_NUM,mywaitbar,mystr);end
end