【STM32开发笔记】移植AI框架TensorFlow【DSP指令加速篇】
- 一、前文回顾
- 二、CMSIS-NN简介
- 2.1 为什么介绍CMSIS-NN?
- 2.2 CMSIS-NN是什么?
- 2.3 CMSIS-NN核心特性
- 2.4 CMSIS-NN算子支持
- 三、TFLM+CMSIS-NN集成
- 3.1 包含TFLM的STM32项目
- 3.2 理解TFLM中CMSIS-NN相关构建规则
- 3.3 理解TFLM中CMSIS-NN相关算子实现
- 3.4 集成CMSIS-NN方式1——作为TFLM的一部分
- 3.5 集成CMSIS-NN方式2——作为独立的三方库
- 四、TFLM+CMSIS-NN测试
- 4.1 编译源代码
- 4.2 下载Boot代码
- 4.3 下载Appli代码
- 4.4 运行TFLM基准测试
- 五、问题解决
- 5.1 specialize_files.py 输入不支持CMake列表参数问题
- 5.2 specialize_files.py 输出的路径分隔符不一致问题
- 5.3 specialize_files.py 输出和CMake列表格式不一致问题
- 5.4 specialize_files.py 输出的最后一个文件无法找到
- 六、项目源码
- 七、参考链接
本文介绍了如何通过移植CMSIS-NN库并调整TensorFlow Lite for Microcontrollers (TFLM) 的构建配置,实现在STM32微控制器上利用DSP指令集加速TensorFlow Lite模型的推理过程。通过这一方法,我们能够有效地提升基于ARM Cortex-M系列MCU上运行深度学习模型的性能。文章首先介绍了CMSIS-NN库的基本概念及其在神经网络加速中的作用,随后详细阐述了移植库到STM32平台的步骤。接着,文章深入讲解了如何修改TFLM的构建规则,实现调用CMSIS-NN库实现TensorFlow算子。最后,通过实验验证了该方法在提高模型推理速度方面的显著效果,使用CMSIS-NN实现DSP加速后的人脸检测模型推理速度接近原来的3.5倍。
一、前文回顾
此系列前面已经发布了两篇:
-
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【上篇】
-
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【下篇】_
【上篇】介绍了TensorFlow、TensorFlow Lite、TensorFlow Lite for Microcontrollers(TFLM)是什么,如何下载TFLM源码,如何在个人电脑(PC)上体验运行TFLM基准测试。同时,分析了TFLM的部分Makefile源码分析。最后,介绍了如何移植TFLM的主体代码。
【下篇】介绍了如何准备STM32 CubeMX项目(以便于后续的TFLM可以顺利移植),如何将TFLM源码集成到STM32 CubeMX生成的项目中去,以及如何在STM32项目中运行TFLM基准测试。同时,介绍了过程中遇到的问题,以及解决方法。最后,给出了整个项目的完整可运行源代码。
二、CMSIS-NN简介
2.1 为什么介绍CMSIS-NN?
因为TFLM源码中有针对CMSIS-NN的算子适配层,通过该适配层可以实现将TensorFlow Lite模型的推理计算转化为对CMSIS-NN库的调用。
同时,CMSIS-NN底层支持DSP指令和MVE指令,在Cortex-M4、Cortex-M7、Cortex-M33上可以实现DSP指令加速计算,在Cortex-M55、Cortex-M85上可以实现MVE加速计算。
简言之,TFLM默认的算子实现为纯CPU计算,而CMSIS-NN可以作为TFLM的后端,实现部分处理器上的DSP和MVE加速计算。
2.2 CMSIS-NN是什么?
CMSIS-NN是什么?官方的解释是:
CMSIS NN 软件库是一组高效的神经网络核(函数),旨在最大限度地提高 Arm Cortex-M 处理器上神经网络的性能并最大限度地减少内存占用。
CMSIS-NN是一个计算库,它向上提供了神经网络(NN)计算接口,实现了神经网络计算的硬件加速。它内部实现了纯CPU计算、DSP计算、MVE计算,屏蔽了底层硬件的具体细节,降低了编程难度。
2.3 CMSIS-NN核心特性
总结一下官方的介绍,可以知道CMSIS-NN库的核心特性:
-
专为Cortex-M处理器开发;
-
神经网络计算函数;
-
最大化性能;
-
最小化内存占用;
-
CMSIS-NN的硬件和软件支持
2.4 CMSIS-NN算子支持
在CMSIS-NN源码仓首页,可以看到CMSIS-NN库提供了三种算子实现,分别为:
- 纯C,CMSIS-NN提供了所有算子的纯C实现,用于像Cortex-M0和Cortex-M3这样的处理器;
- DSP扩展,在支持DSP扩展的处理器上,可以使用DSP指令加速计算,例如Cortex-M4或Cortex-M7;
- MVE扩展,在支持ARM Helium技术的处理器上,可以使用MVE指令加速计算,例如 Cortex-M55 或 Cortex-M85;
三、TFLM+CMSIS-NN集成
接下来,我将介绍如何将TFLM和CMSIS-NN集成到STM32项目中。
3.1 包含TFLM的STM32项目
前面的文章中,我们已经知道了如何将TFLM集成到STM32项目中,本文将以上一篇文章的代码为基础,继续进行CMSIS-NN的集成和测试。
基础项目代码仓链接:
https://gitcode.com/xusiwei1236/STM32H7S78-DK-TFLM
这个代码仓就是——已经包含了TFLM的STM32项目。
3.2 理解TFLM中CMSIS-NN相关构建规则
TFLM的构建规则Makefile文件中,和CMSIS-NN相关的主要代码片段为:
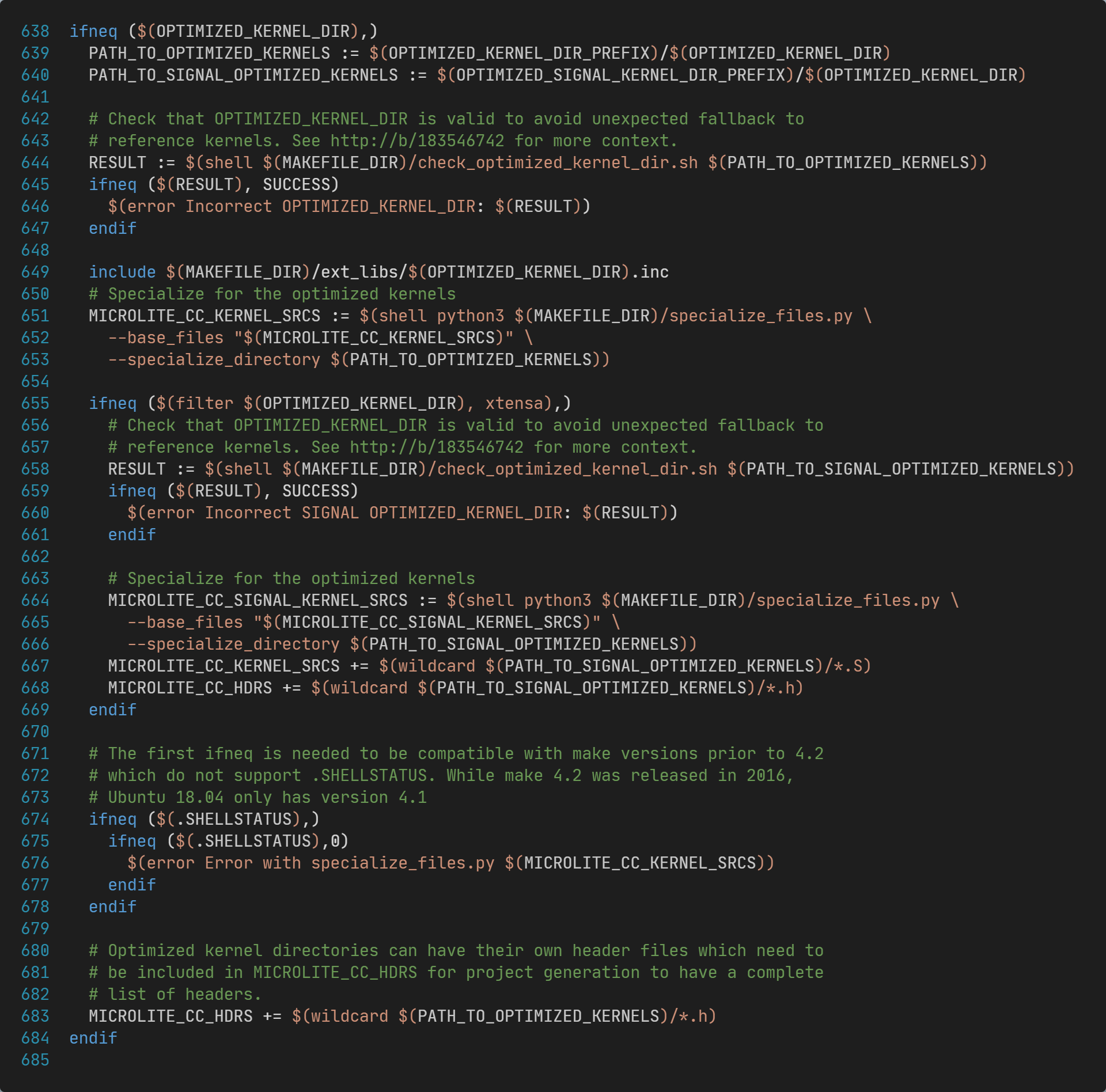
这段代码中,比较重要的有两处,分别为:
- 649行,CMSIS-NN对应的
OPTIMIZED_KERNEL_DIR变量值为cmsis_nn,此时会包含cmsis_nn.inc构建规则文件; - 651到653行,调用
specialize_files.py脚本,用于将算子实现源文件列表MICROLITE_CC_KERNEL_SRCS中的部分文件替换为CMSIS-NN适配源文件列表;
cmsis_nn.inc文件内容如下:
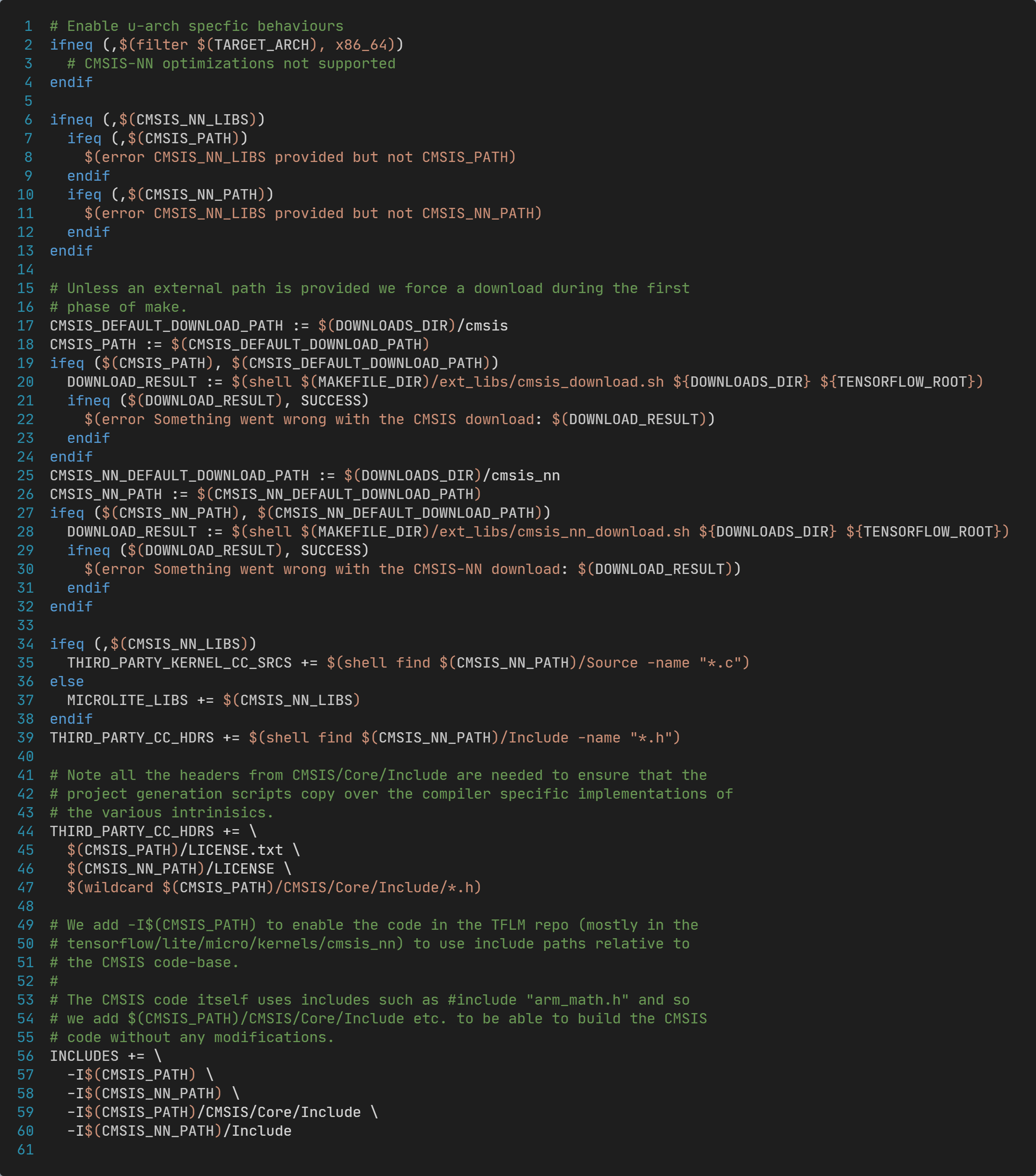
这段代码中,可以看到TFLM支持两种方式和CMSIS-NN集成:
- CMSIS-NN作为独立的三方库,链接到一起;
- CMSIS-NN作为TFLM的一部分,编译到一起;
specialize_files.py文件源码如下:
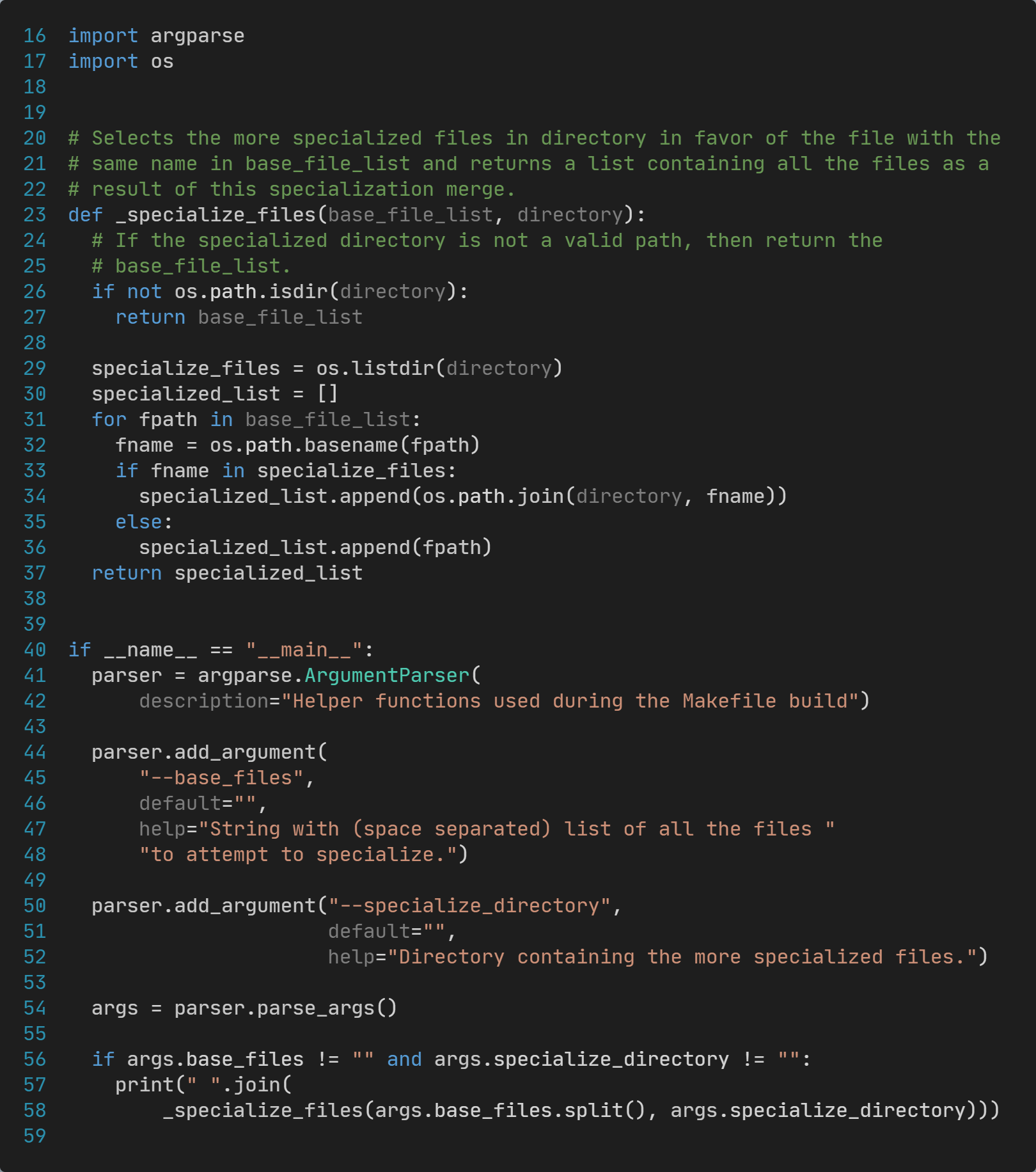
该文件实现了:
- 遍历
base_files列表中的条目,检查在specialized_directory目录下是否存在和它的基础文件名(basename)相同的文件; - 如果存在,则使用
specialized_directory目录下的替换掉base_files中的这一条; - 否则,保持原来位于
base_files中的这一条不变!
3.3 理解TFLM中CMSIS-NN相关算子实现
对于CMSIS-NN,实际运行时的specialized_directory指定的参数值是tensorflow/lite/micro/kernels/cmsis_nn子目录。
该目录下包含的文件如下:
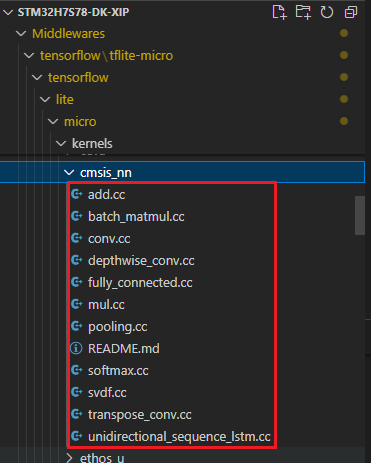
实际执行specialize_files.py脚本时,实际的替换文件的对应关系如下:
| 默认算子文件 | CMSIS-NN算子文件 |
|---|---|
| tensorflow/lite/micro/kernels/add.cc | tensorflow/lite/micro/kernels/cmsis_nn/add.cc |
| tensorflow/lite/micro/kernels/batch_matmul.cc | tensorflow/lite/micro/kernels/cmsis_nn/batch_matmul.cc |
| tensorflow/lite/micro/kernels/conv.cc | tensorflow/lite/micro/kernels/cmsis_nn/conv.cc |
| tensorflow/lite/micro/kernels/depthwise_conv.cc | tensorflow/lite/micro/kernels/cmsis_nn/depthwise_conv.cc |
| tensorflow/lite/micro/kernels/fully_connected.cc | tensorflow/lite/micro/kernels/cmsis_nn/fully_connected.cc |
| tensorflow/lite/micro/kernels/mul.cc | tensorflow/lite/micro/kernels/cmsis_nn/mul.cc |
| tensorflow/lite/micro/kernels/pooling.cc | tensorflow/lite/micro/kernels/cmsis_nn/pooling.cc |
| tensorflow/lite/micro/kernels/softmax.cc | tensorflow/lite/micro/kernels/cmsis_nn/softmax.cc |
| tensorflow/lite/micro/kernels/svdf.cc | tensorflow/lite/micro/kernels/cmsis_nn/svdf.cc |
| tensorflow/lite/micro/kernels/transpose_conv.cc | tensorflow/lite/micro/kernels/cmsis_nn/transpose_conv.cc |
| tensorflow/lite/micro/kernels/unidirectional_sequence_lstm.cc | tensorflow/lite/micro/kernels/cmsis_nn/unidirectional_sequence_lstm.cc |
这里以第一行add.cc为例,默认的算子实现主体代码为:

CMSIS-NN版本的add.cc代码主体代码为:
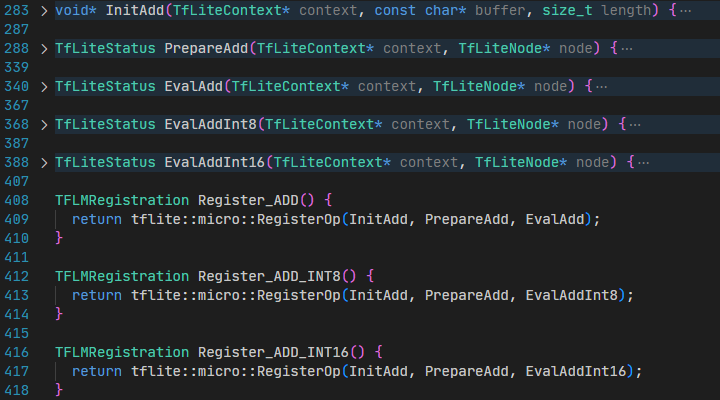
都提供了Register_ADD()函数,用于注册ADD算子。
3.4 集成CMSIS-NN方式1——作为TFLM的一部分
理解了前面的Makefile代码,就可以编写CMake构建规则,从而实现在STM32项目中集成TFLM和CMSIS-NN。
前文提到,STM32项目集成CMSIS-NN有两种方式,分别为:
- CMSIS-NN作为TFLM的一部分,编译到TFLM的静态库(libtflite-micro.a)文件中;
- CMSIS-NN作为独立的三方库,链接到STM32的可执行程序(.elf)文件中;
首先,介绍第一种方式,也就是CMSIS-NN作为TFLM的一部分;这种方式Appli子项目不直接依赖CMSIS-NN库,无需修改,更易于理解。
基于对Makefile源码的理解,修改tflite-micro目录的CMakeLists.txt文件内容:
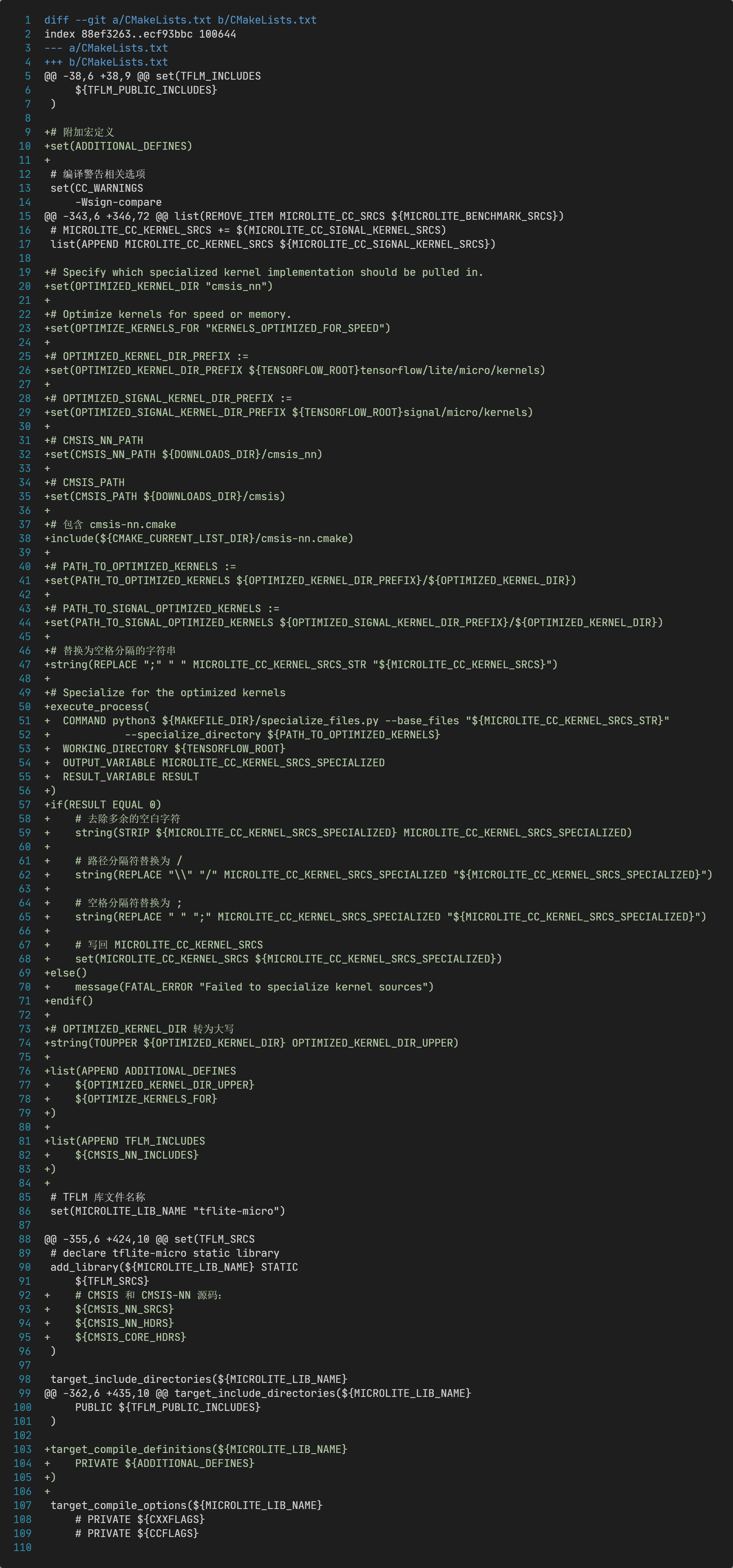
这段修改中包含了cmsis-nn.cmake,cmsis-nn.cmake文件的内容为:
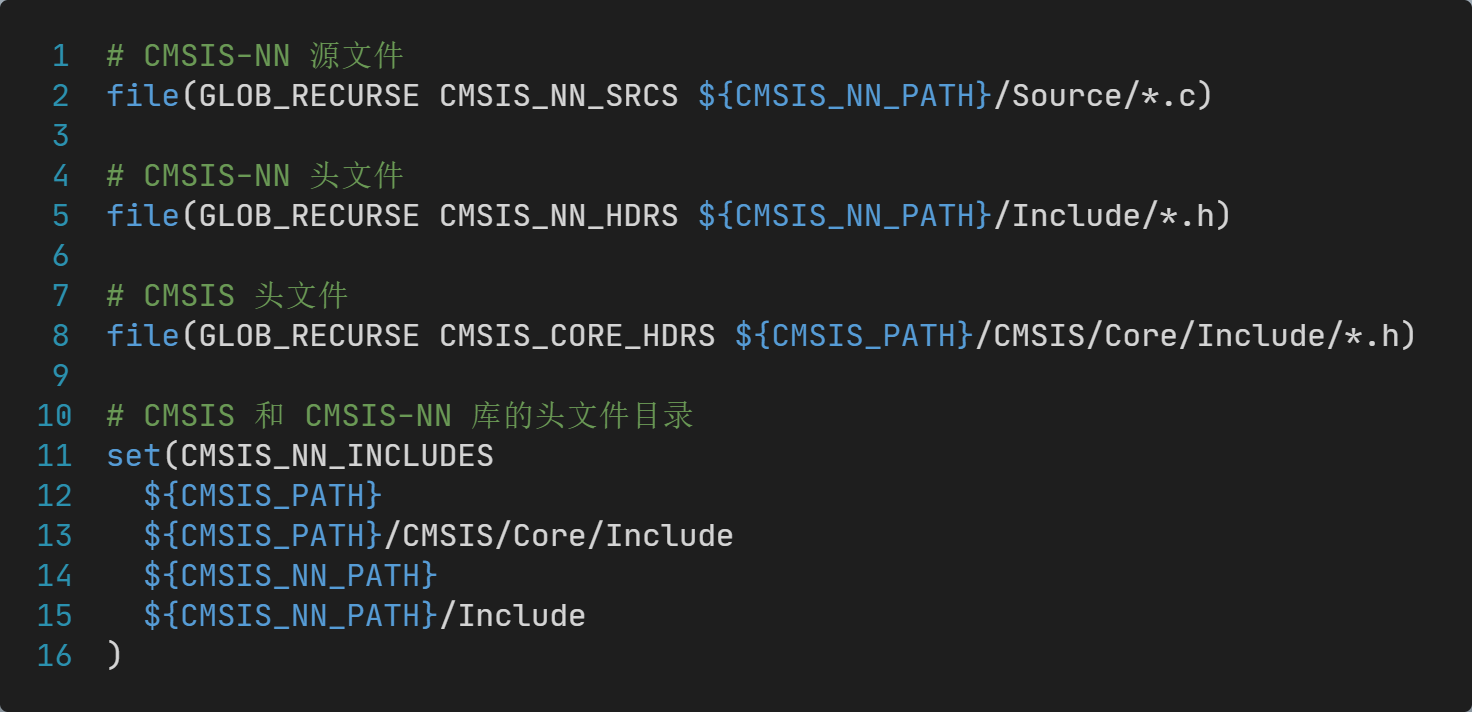
整个修改实现了:
- 调用
specialize_files.py脚本,将MICROLITE_KERNEL_CC_SRCS中的部分算子文件路径替换为cmsis_nn目录内的,实现了CMSIS-NN适配层的编译; - 将
cmsis-nn.cmake中匹配到的CMSIS-NN源文件,添加到TFLM库的源文件列表中,实现了CMSIS-NN代码的编译,并作为TFLM库的一部分;
这样修改之后,重新编译生成的libtflite-micro.a中就包含了CMSIS-NN的代码,以及基于CMSIS-NN的TensorFlow算子实现。
3.5 集成CMSIS-NN方式2——作为独立的三方库
另外一种集成CMSIS-NN的方式是,CMSIS-NN作为独立的三方库,最终连接到整个项目的可执行文件(.elf)中。
要实现这种继承方式,需要在刚修改的TFLM的CMakeLists.txt的基础上进行修改:
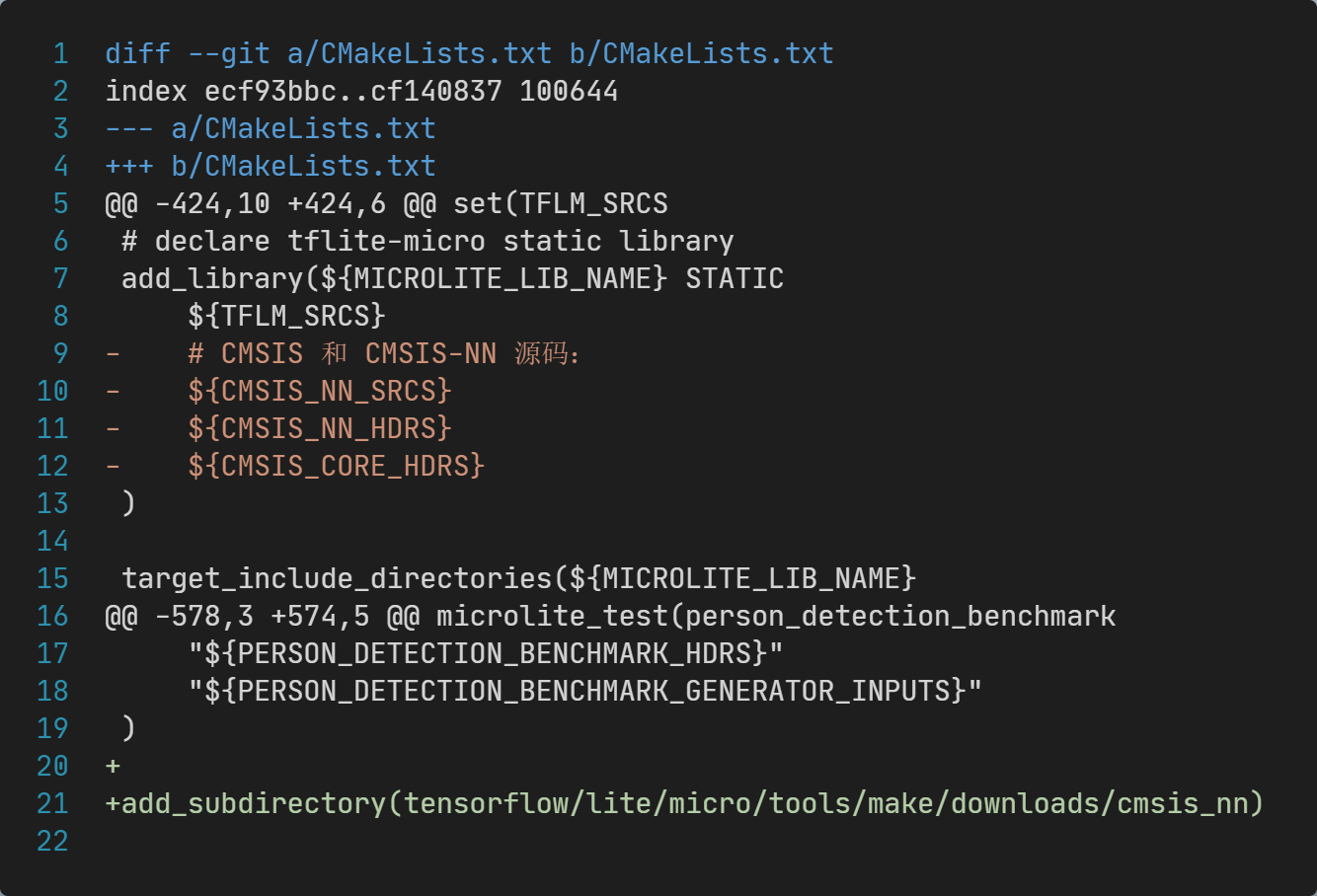
一共修改两处:
add_library代码片段,删除CMSIS-NN相关的代码文件;- 文件末尾添加
add_subdirectory(tensorflow/lite/micro/tools/make/downloads/cmsis_nn),让CMSIS-NN的CMakeLists.txt被包含到整个项目中;
除此之外,还需要修改Appli目录的CMakeLists.txt文件,具体修改内容如下图:
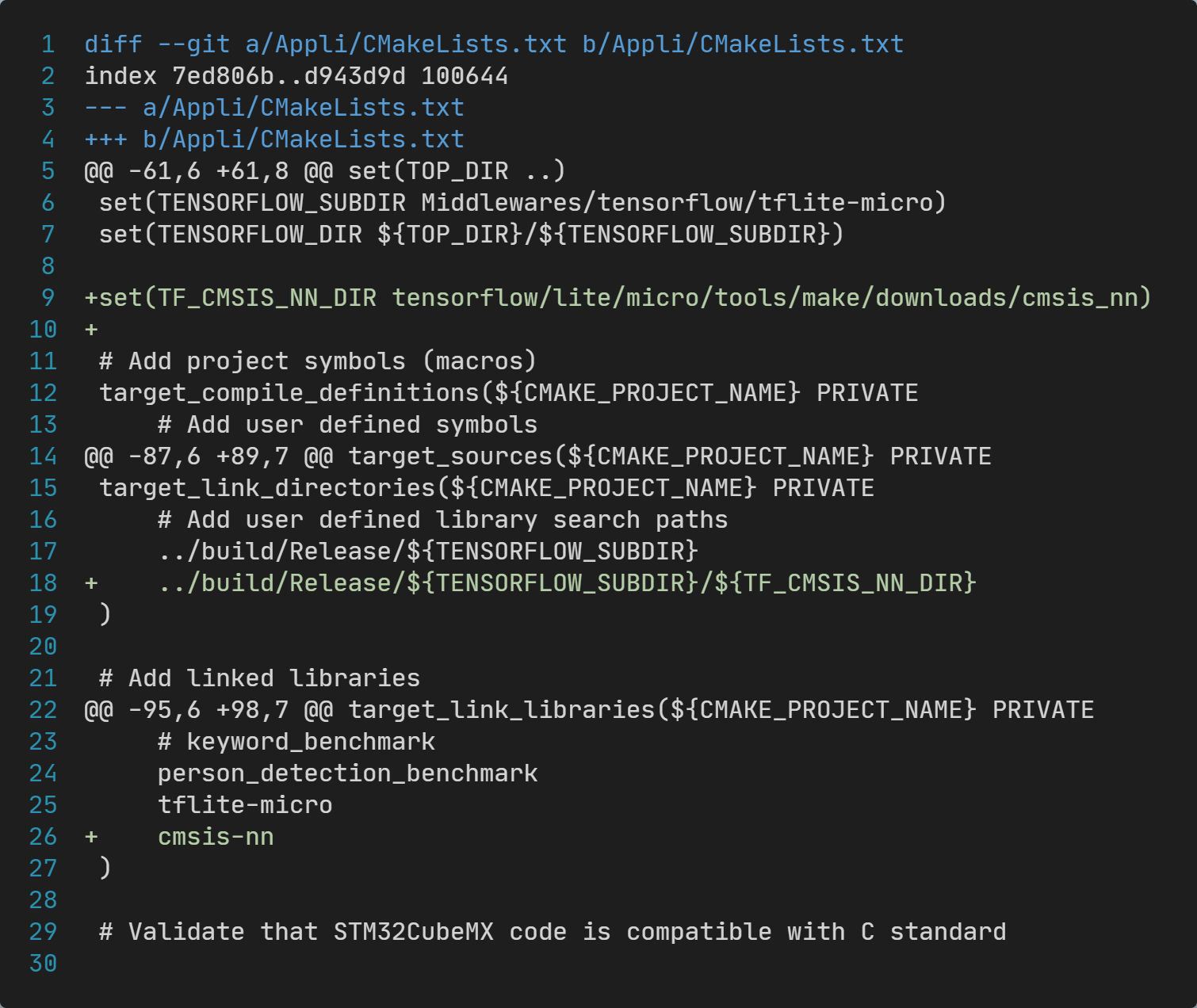
一共修改了三处:
- 新增了
TF_CMSIS_NN_DIR变量定义,用于记录cmsis_nn源码所在子目录; target_link_directories下,增加一行,指定CMSIS-NN库文件生成的目录;target_link_libraries下,增加一行,指定链接cmsis-nn库;
以上这种修改方式,也可以实现将TFLM和CMSIS-NN集成到STM32项目中。
四、TFLM+CMSIS-NN测试
4.1 编译源代码
第一种方式集成CMSIS-NN,由于上层代码不依赖CMSIS-NN库,即不新增库依赖;因此,其编译方式和此前的文章方式一样,这里不在介绍。
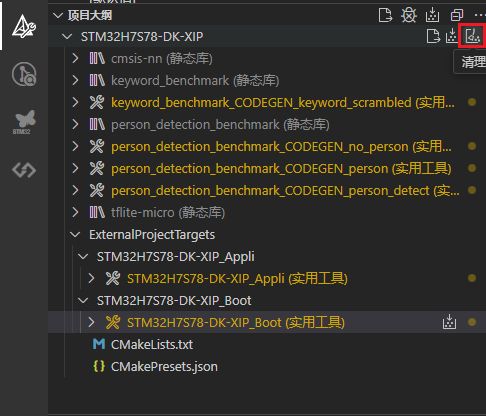
这里仅介绍第二种方式集成CMSIS-NN的编译方法,分为如下几步:
-
清理输出目录,如下图操作:
-
编译
tflite-micro库,如下图操作: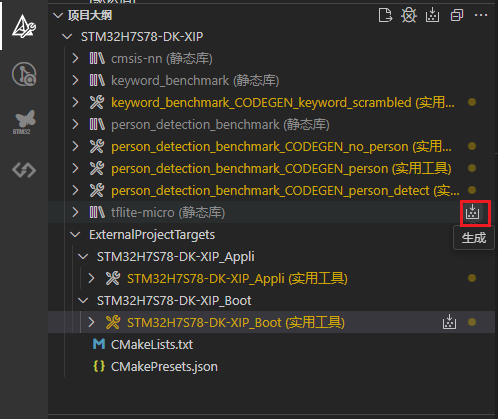
-
编译
xxx_benchmark库,如下图操作: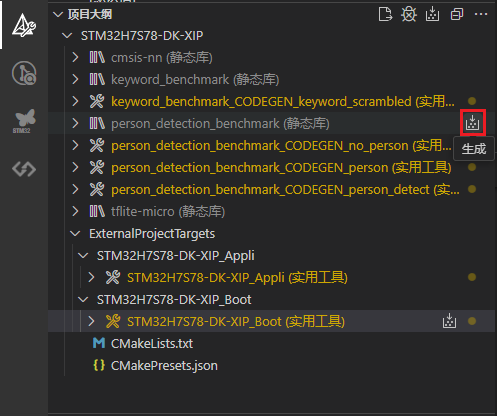
-
编译
cmsis-nn库,如下图操作: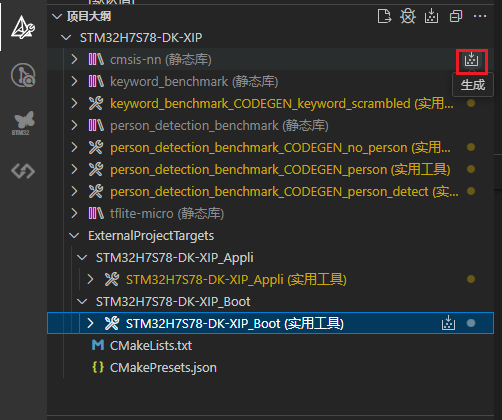
-
编译
Appli目标,如下图操作: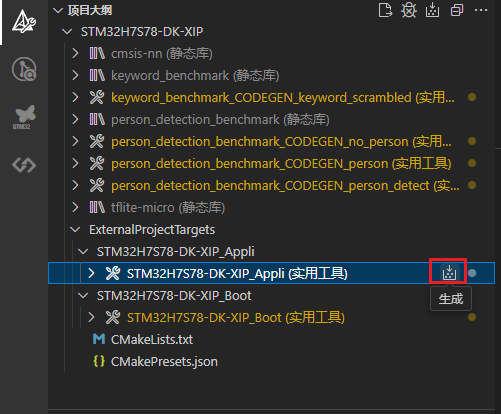
-
编译
Boot代码,如下图所示: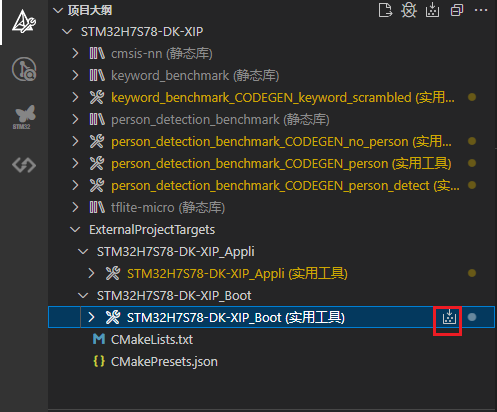
4.2 下载Boot代码
由于Appli代码需要使用Boot代码进行跳转,因此,下载Appli代码之前,需要先将Boot代码下载到开发板上。
下载之前,先将STM32H7S78-DK开发板和PC通过USB线连接好,板子由三个USB口,注意连接到标有STLK的。
下载Boot代码,按照如下图所示操作:
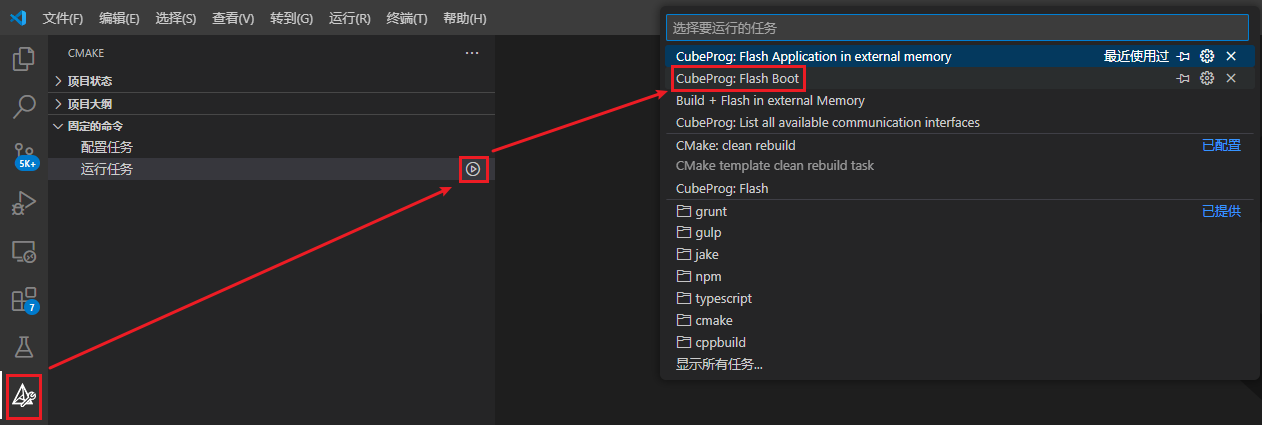
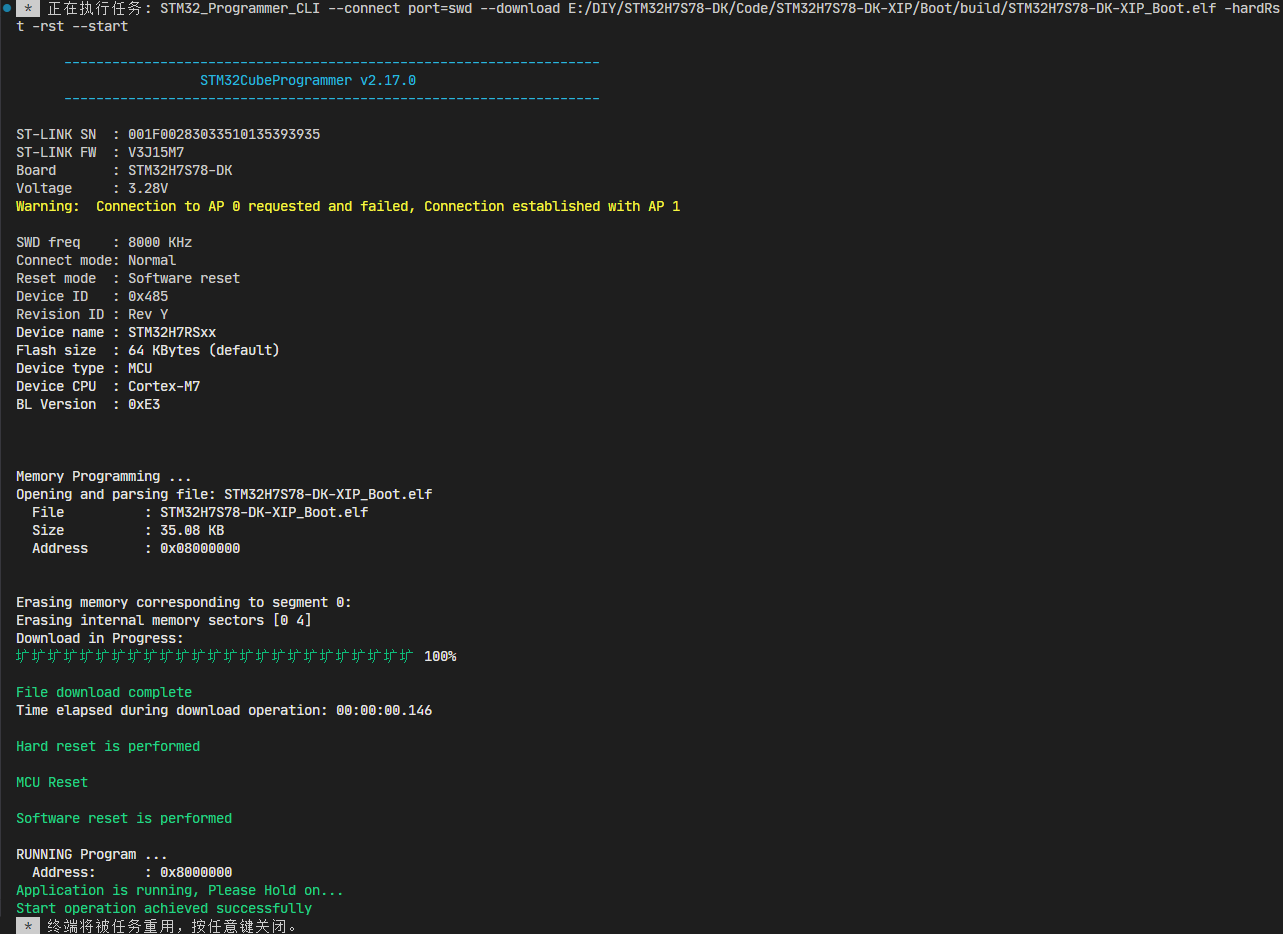
执行过程中终端子窗口会输出进度等信息:
4.3 下载Appli代码
下载Appli代码,按照如下图操作:
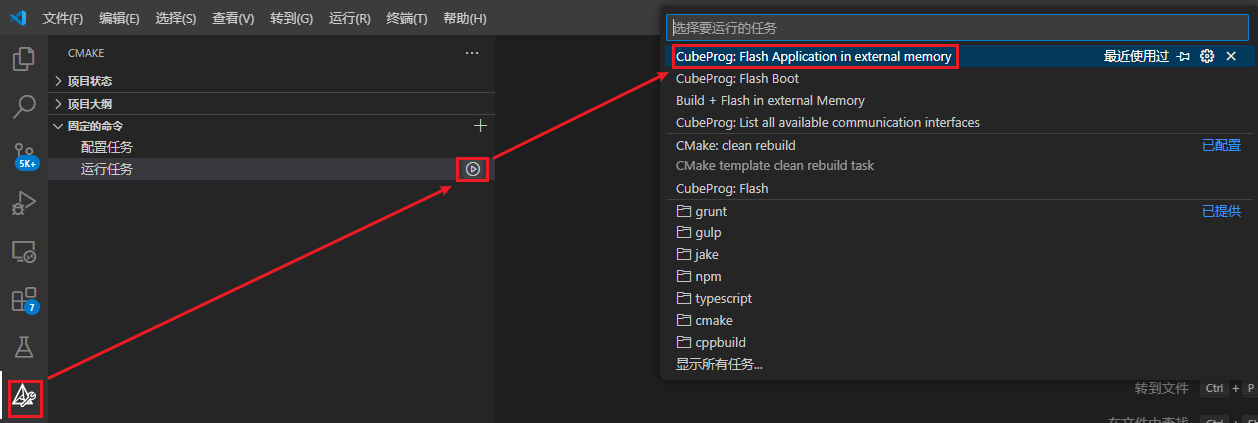
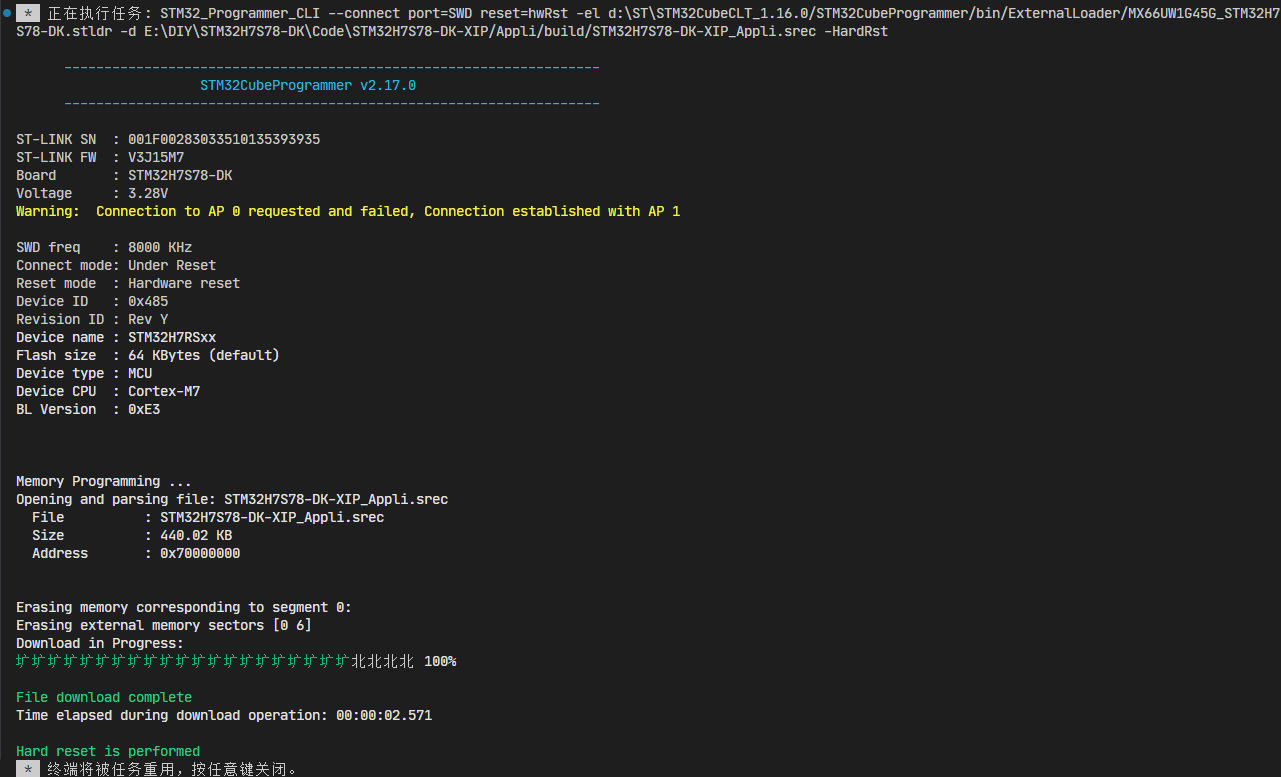
执行过程中终端子窗口会输出进度等信息:
4.4 运行TFLM基准测试
打开MobaXterm,添加会话,选择STLink的虚拟串口设备,参数如下:
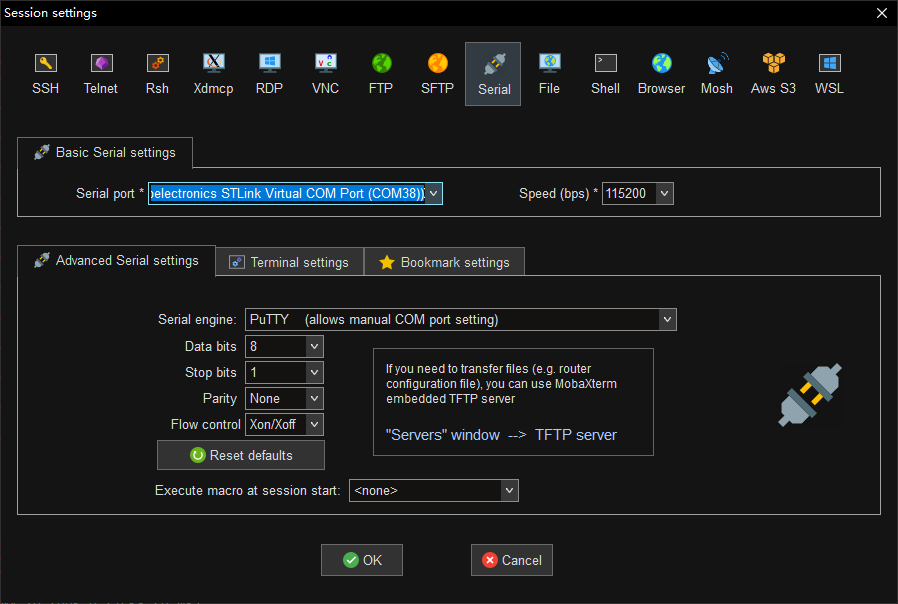
连接设备之后,按下开发板上的NRST按钮,重启设备,可以看到串口输出如下:
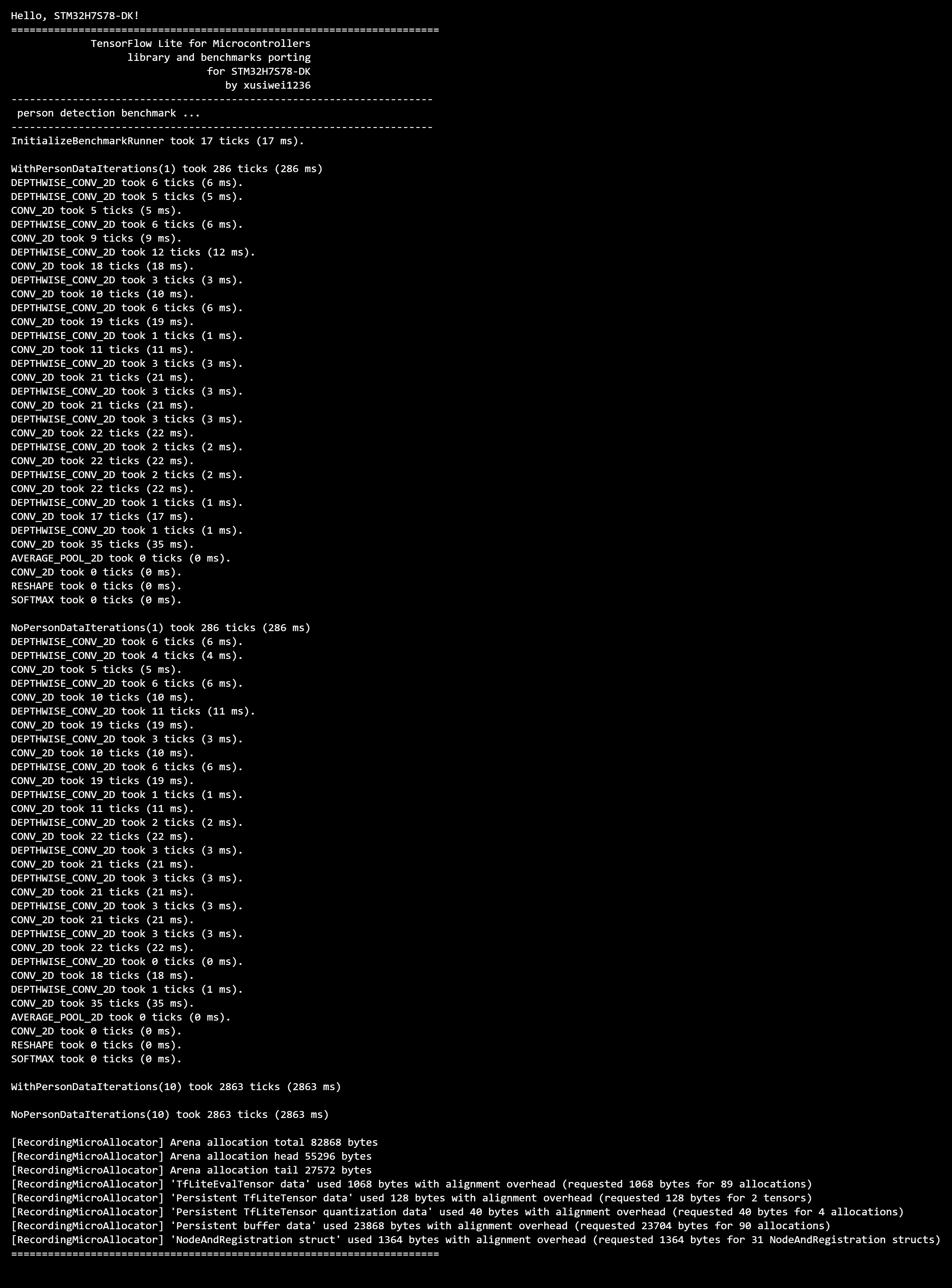
可以看到,开发板上,运行有人图像的人体检测耗时为286毫秒,没有人的耗时为286毫秒;连续运行10次的耗时分别为2863毫秒和2863毫秒,速度有点慢。
和上一篇文章的数据对比如下:
| 测试项目 | TFLM | TFLM+CMSIS-NN |
|---|---|---|
| WithPersonDataIterations(1) | 993 | 286 |
| NoPersonDataIterations(1) | 994 | 286 |
| NoPersonDataIterations(10) | 9938 | 2863 |
| NoPersonDataIterations(10) | 9940 | 2863 |
五、问题解决
第三章、第四章实际过程中遇到了一些问题,为了保持前文逻辑连贯,没有在前面记录,本章将记录具体问题及解决方法。
5.1 specialize_files.py 输入不支持CMake列表参数问题
【问题现象】specialize_files.py脚本输出和输入参数base_files的值完全一样。
【问题原因】specialize_files.py脚本使用Python的string.split对参数base_files的值进行分隔,要求值是空白字符(空格、TAB、换行等)分隔的。而CMake的列表字符串是分号分隔的。
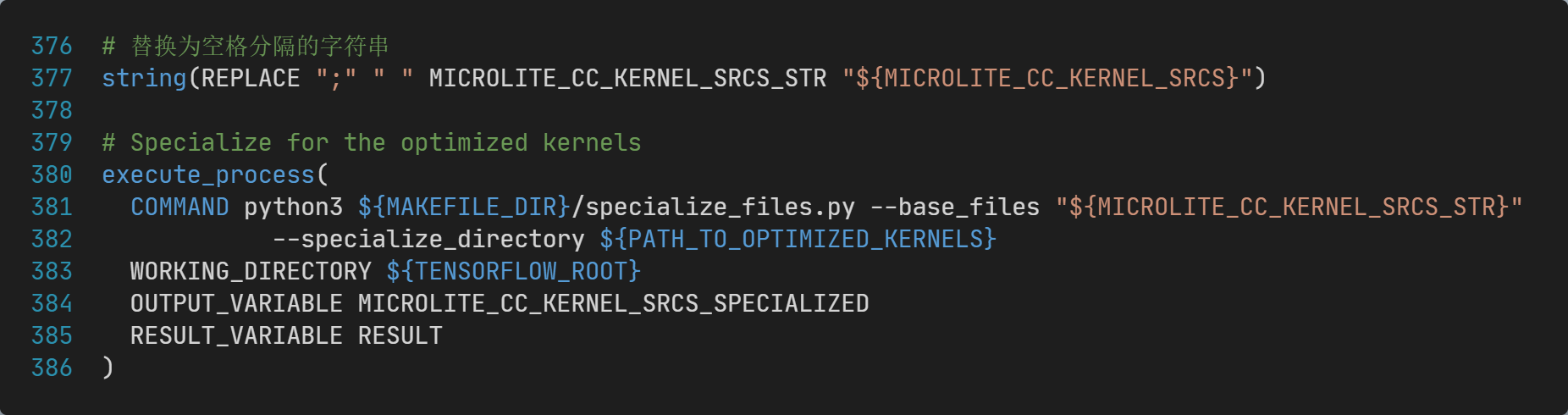
【解决方法】将MICROLITE_CC_KERNEL_SRCS中的分隔符替换为空格,再将其传给specialize_files.py脚本,具体代码为:
5.2 specialize_files.py 输出的路径分隔符不一致问题
【问题现象】specialize_files.py 输出的路径分隔符不一致,有正斜杠也有反斜杠,导致后续报错——文件找不到。
【问题原因】CMake代码使用的路径分隔符是正斜杠,specialize_files.py代码里面使用的是os.path.sep,在Windows上是反斜杠。
【解决方法】将反斜杠全部替换为正斜杠。

5.3 specialize_files.py 输出和CMake列表格式不一致问题
【问题现象】specialize_files.py 输出的文件列表是空格分隔的,和CMake列表格式不一致。
【问题原因】specialize_files.py 使用空格拼接文件列表为一个字符串之后输出,而CMake列表需要用使用分号分隔。
【解决方法】将字符串中的空格替换为分号。

5.4 specialize_files.py 输出的最后一个文件无法找到
【问题现象】specialize_files.py 输出的文件列表的最后一个文件,后续CMake代码提示该文件找不到。
【问题原因】乍看起来文件路径是对的,能够找到;实际将该文件路径字符串加上双引号输出之后,发现末尾多了一个换行符。
【解决方法】去除末尾的空白字符。

六、项目源码
如需本文修改后项目源码的,请在评论区留言。我将会在留言超过10条,或本文阅读量超过1200之后,将本文修改的最终源码全部开源。
当然,动手能力强的读者,也可以根据文章描述的步骤,一步步修改得到最终版本的源码。
七、参考链接
- TensorFlow Lite for Microcontrollers介绍: TensorFlow Lite for Microcontrollers (google.cn)
- TensorFlow Lite for Microcontrollers入门: 微控制器入门 | TensorFlow (google.cn)
- tflite-micro 源码仓: https://github.com/tensorflow/tflite-micro
- CMake最新文档: CMake Reference Documentation — CMake 3.30.3 Documentation
- CMSIS-NN在线文档: CMSIS-NN: CMSIS NN Software Library (arm-software.github.io)
- CMSIS-NN 源码仓: https://github.com/ARM-software/CMSIS-NN













![[含文档+PPT+源码等]精品基于springboot实现的原生微信小程序小区兼职系统](https://img-blog.csdnimg.cn/img_convert/b54d292b3ed0fadf9f29d4758c0441e4.jpeg)