本篇会加入个人的所谓鱼式疯言
❤️❤️❤️鱼式疯言:❤️❤️❤️此疯言非彼疯言
而是理解过并总结出来通俗易懂的大白话,
小编会尽可能的在每个概念后插入鱼式疯言,帮助大家理解的.
🤭🤭🤭可能说的不是那么严谨.但小编初心是能让更多人能接受我们这个概念 !!!

引言
当我们谈论 Java 时,JVM 原理就像是一扇神秘的大门,通向程序运行的深层世界。在这扇门后,隐藏着无数的奥秘和惊喜,等待着我们去探索。让我们一起推开这扇门,揭开 JVM 原理的神秘面纱吧!
目录
-
JVM 内存区域划分
-
JVM 类加载的过程
-
双亲委派模型
一. 内存区域划分
1. 内存区域的引入

让一个
Java程序跑起来, 就会 分配进程 , 我们知道进程是 资源分配的基本单位 。
在 JVM 中为了更好的 管理内存单元 , 于是就把内存分配成
一段一段的不同的区域,为了更好的 方便管理和利用 。

如上图:
好比在小编的学校中要开发一个校区, 就会把这个 校区用来执行不同的任务的区域 : 教室, 行政楼, 快递站, 食堂等…
这样划分不同的区域不仅可以更好的工作 , 还方便 学校的管理 。
下面让我们看看JVM 内部的内存区域划分吧 💖 💖 💖 💖
2. JVM 内存区域划分

如上图, 在JVM 中主要划分为以下区域:
-
程序计数器 : 记录着需要 执行的下一条指令,注意这里的 程序计数器 执行的 不是CPU的寄存器 , 而是一段
内存空间, 执行的下一条指令是字节码.class文件。 -
栈: 分为两个不同的栈:
本地方法栈: 处在 JVM内 是一些由C++ 实现的函数, 存放着函数之间的调用关系。
虚拟机栈: 处在 JVM外,是存放着Java代码之间的方法调用关系, 局部变量 。 -
堆:存放着 主要用于存放 类的方法 ,字符串常量,成员变量对象的区域 -
元数据区(方法区) :全局变量, 静态变量 ,
普通常量,静态方法, 函数之间的调用关系。
鱼式疯言
补充说明
- 对于JVM 而言, 不是在 操作系统内核上加载进程 , 而是在软件层面上自己实现一套和操作系统相似的读取指令, 加载进程的方式, 处理细节可能不同, 但是执行的思想大体上是相似的。
- 当Java创建进程后, 堆和元数据区 只有一份, 因为进程系统分配的基本单位, 但是 在一个进程下可以创建多个线程 , 就会出现多个
程序计数器和栈, 分别服务 每一个线程 。
3. 题目测试
class Test {private int a;private Test b = new Test();private static Test d = new Test();public static void main(String[] args) {int e = 10;Test f = new Test();}
}
如上面的代码, 问题: 找出变量 a,,b,d,e,f 分别所处的内存区域 。
在判断这些变量所处的内存不分为 是不是内置类型 , 而是看他们所处于的位置和 是否是 static 修饰。
像 a 和 b 处在 类的内部, 方法的外部 就处在 堆 。
像 d 是属于 static 修饰的, 就属于静态方法, 存放在 元数据区(方法区) 。
像 e f 处在 类的内部, 并且处在 方法的内部 , 这样的变量我们就处在 栈 。
鱼式疯言
综上所述 :
-
成员变量和成员方法 的处在
堆上 -
静态变量和静态方法 的处在
元数据区 -
方法内部的局部变量 处在
栈上
二. JVM 类加载的过程
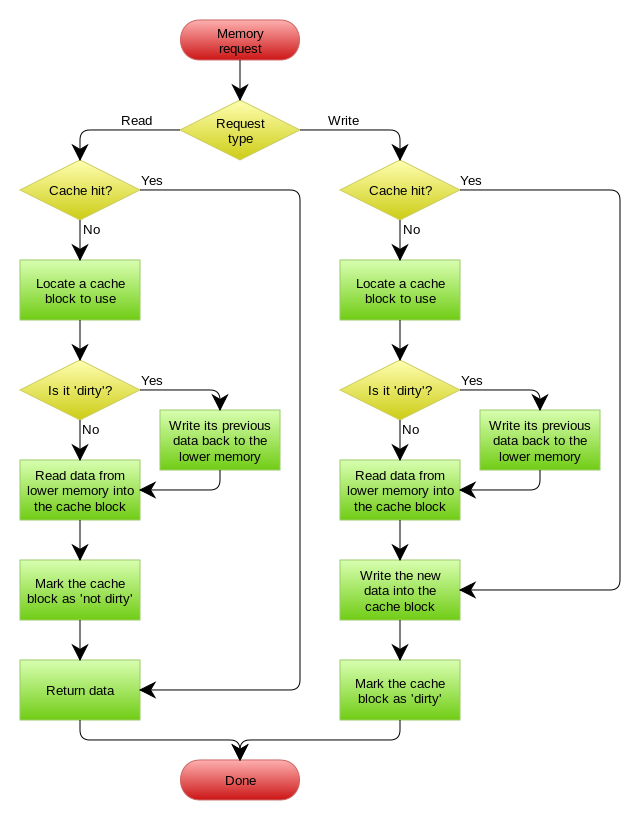
在JVM 内部 , 程序是怎么运行的? 他们在JVM 内部又会经历怎么样的过程呢?
大体上分为五步: 加载, 验证, 准备, 解析,初始化。
1. JVM 的加载流程
<1>. 加载
在JVM 中, 先确定类名, 然后根据类名去查找 字节码文件,涉及到一系列 目录查找的过程 , 找到 .class 文件 之后就 打开并解析文件内容 。
<2>. 验证
打开.class 文件内容后, 验证.class 的文件数据是否合法, 是否正确。

因为在 Java标准库 中, 明确规定了 .class 文件 的格式是怎么样的~
<3>. 准备
给需要的 类对象分配内存空间(需要内存) , 根据刚才读到的内容, 确定类对象需要的内存空间, 分配好内存空间, 并 ==把内存空间的所有内容都初始化为 0 == 。
class Test {static int a = 10;
}
如上图 , 准备过程就是确定a 的内存空间大小为 4 个字节, 然后 给 a 分配4个字节的内存空间 , 并且 初始化a为0 , 但是要注意一点的是, 准备工作是还没有把 10 赋值给a 的(后面的过程才会出现赋值)。
<4>. 解析
主要是把常量字符串通过偏移量解析到文件中。

在内存中一个存放常量的位置称为
地址, 但在文件中我们就用偏移量的概念来表示。 偏移量就是相对于起始位置的距离, 我们就称之为偏移量。
如上图:
所以上图就是把内存中的
常量abc的内存地址解析到 文件中的偏移量 的过程。
举个栗子理解下解析的过程吧, 假如小编的学校要 进行春游。
然后在一次看电影的环节, 辅导员叫我们按照学号排好位置来看电影。

于是排好位置, 我的偏移量就相对于 起始位置小张 就为3 , 当我们都坐下后, 也就确定了每一个人 相对于起始位置的偏移量 , 从而确定自身的位置。
<5>. 初始化
针对类对象进行最终的 初始化操作 ,把所有的静态变量都进行 赋值。
鱼式疯言
补充说明
在执行
静态代码块时, 如果 有父类就会对父类进行, 会对父类先进行加载。 (按照父-> 子顺序加载)
三. 双亲委派模型
1. 双亲委派模型的引入
在类加载过程中有另一个重要的面试题: 双亲委派模型
这是上述类加载过程五个步骤的 第一个步骤的其中一个环节 , 通过类的全限定名,找到 .class 文件 的位置。
在JVM 内部内置一些内加载器, 完成 “类加载”的过程(JVM的功能模块)
其中就有三个默认的加载器:
BooystrapClassLoader: 负责加载标准库中的类 (标准库中的类, 有一个专门存放的位置)
ExtensionClassLoader: 负责加载一些扩展类(JVM 厂商希望对标准库的类做进一步的扩展)
ApplicationClassLoader: 负责加载一些第三方库的类和开发人员自己写的类。
上述三个加载器虽然没有继承关系, 但是有parent 这样的引用会指向上一个类:
儿子: ApplicationClassLoader ->父亲: ExtensionClassLoader -> 爷爷: BooystrapClassLoader 这样的关系。
所以上面的三个加载器, 并不能说是 双亲委派模型(英文翻译的) , 更应该说是 单亲委派模型 / 父亲委派模型, 但是竟然这样翻译, 我们就这样称呼吧。
2. 双亲委派模型的流程

如上图
如果我们要寻找 java.lang.String 这个类。
首先从儿子出发, 儿子这边不会先查找, 而是先交给父亲, 当交到父亲手上也不会先查找, 而是再交给爷爷。
由爷爷先查找标准库中是否有
String这个类, 如果找到了就 直接进行类加载的2,3, 4,5 的步骤 。
如果 爷爷没找到就就会返回给父亲找 , 找到就和上面一个继续进行下面类加载的步骤, 如果没有就交给儿子来寻找。
儿子也是如此, 但是 儿子如果没有找到就会抛出异常
ClassNotFoundException这个异常, 告诉开发人员这个类没有找到。
鱼式疯言
栗子理解 :
好比像在公司平常的工作任务一样。
当小编一个小员工, 接收到一个任务时, 就需要 请示领导 该怎么样去做, 然后领导
这边也要继续请示大领导。 当大领导觉得这件事情很重要时,就会自己留下来处理。
当大领导觉得 这件事不是那么重要 , 就会交回给我的领导去做, 我的领导看了看觉得 没有那么重要的话, 就会交给我去做, 否则就会留下自己去做。
3. 双亲委派模型的优点
之所以想上面的流程一样, 需要先不断向上传递优先查找, 就是要保证优先级顺序: 标准库 》 扩展库 》 第三方库。
保证 标准库的优先级是最高的, 其次是
扩展库, 最后是 第三方库 。
这样做的好处就在于, 可以保证
标准库的代码先执行到, 以免因为 第三方库自己写的代码和标准库重名 , 而造成 意想不到的BUG 出现 。
总结
-
JVM 内存区域划分: 对于JVM 内存主要划分为: 程序计数器, 栈, 堆 , 元数据区(方法区) , 理解他们的不同区域的含义以及不同位置上的变量所处于区域划分。
-
JVM 类加载的过程: 加载 ——》 验证——》准备——》 解析——》初始化 , 按照这样的流程来
加载 .class 文件。 -
双亲委派模型 : JVM 类加载五个步骤中的第一个步骤的一个环节, 了解JVM 中默认的三个加载器,
ApplicationClassLoader,ExtensionClassLoader,BooystrapClassLoader分别对应着: 标准库, 扩展库, 第三方库。 并且从双亲委派模型中确认优先级 标准库 》 扩展库》 第三方库 , 保证标准库优先被执行到, 以免出现 BUG。
如果觉得小编写的还不错的咱可支持 三连 下 (定有回访哦) , 不妥当的咱请评论区 指正
希望我的文章能给各位宝子们带来哪怕一点点的收获就是 小编创作 的最大 动力 💖 💖 💖

















![[MyBatis-Plus]扩展功能详解](https://img-blog.csdnimg.cn/img_convert/6323b1b67cad92f3eba8e26b8402ca07.png)
