队列也是一种操作受限的线性数据结构,与栈很相似。

01定义
栈的操作受限表现为只允许在队列的一端进行元素插入操作,在队列的另一端只允许删除操作。这一特性可以总结为先进先出(First In First Out,简称FIFO)。这意味着在队列中第一个加入的元素将第一个被移除。

入****队:向队列中添加新元素的行为叫做入队;
出****队:从队列中移除元素的行为叫做出队;
队头:在队列中允许进行元素移除行为的一端称为队头;
队尾:在队列中运行进行元素添加行为的一端称为队尾;
空****队列:当队列中没有元素时称为空队列。
满****队列:当队列是有限容量,并且容量已用完,则称为满队列。
队列****容量:当队列是有限容量,队列容量表示队列可以容纳的最大元素数量。
队列****大小:表示当前队列中的元素数量。

02分类
队列根据存储方式和功能特性有两种分类方式。
1、根据存储方式分类
队列是逻辑结构,因此以存储方式的不同可以分为顺序队列和链式队列。
顺序队列就是所有的队列元素都存储在连续的地址空间中,因此可以通过数组来实现顺序队列,因为数组的特性也导致顺序队列容量是固定的,不易扩容,这也导致容易浪费空间,同时还要注意元素溢出等问题。
链式队列顾名思义就是采用链式方式存储,可以通过链表实现,因此链式队列可以做到无限扩容,大大的提高了内存利用率。

2、根据功能特性分类
根据功能特性可以分类出很多专有队列,下面我们列举几个简单介绍一下。
阻塞队列:当空队列时会阻塞出队操作,当满队列时会阻塞入队操作。
优先队列:队列中每个元素都有一个优先级别属性,而元素的出队操作取决于这个优先级别属性,即优先级别高则优先出队。
延迟队列:队列中每个元素都标记一个时间记录,元素只有在指定的延时时间后才会触发出队操作。
循环队列:当使用数组实现队列时,可以通过把队头和队尾相连接,即当队尾到达数组的尾端可以“绕回”数组的开头,通过这种巧妙的设计来提高数组空间利用率。
双端队列:是一种两端都可以进行入队和出队操作的数据结构。
根据这些队列特性,在不同的场景中可以起到意想不到的效果。
下面我们将顺序队列和链式队列的实现进行详细讲解。
03实现(顺序队列)
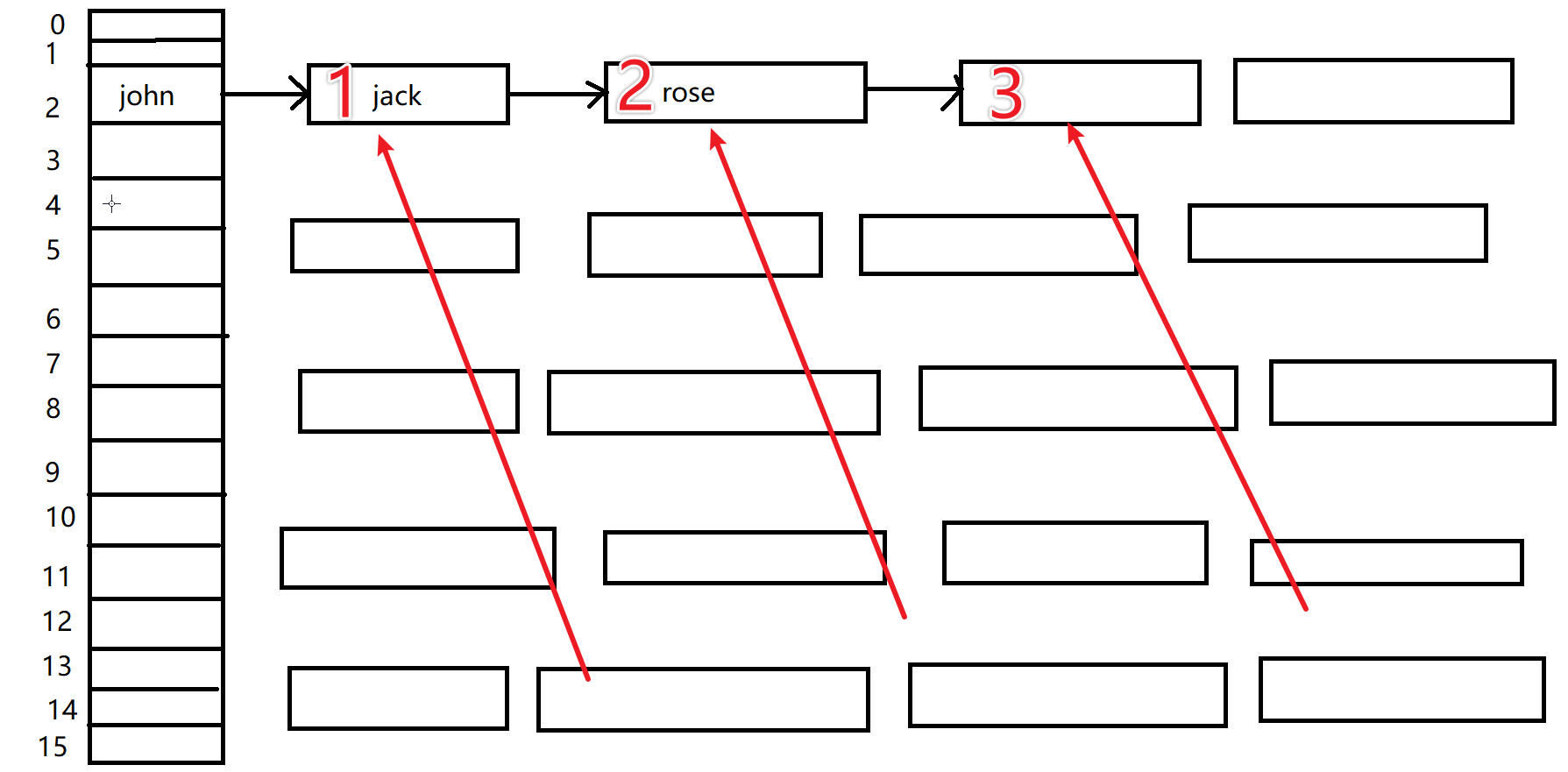
下面我们借助数组来实现顺序队列,其核心思想是把数组的起始位置作为队头,把数组尾方向作为队尾。当发生出队行为时,需要把剩余所有数据向队头方向移动一位,为什么要做这步操作呢?
首先顺序队列内部是数组,假设数组内可以存放7个元素,此时数组已存满,因此不可以再进行添加新元素入队操作了,然后我们对数组头元素进行出队操作,此时数组因为出队会留下一个空位,如下图。

那么此时是否可以进行入队操作呢?直接告诉我们应该可以,因为数组头已经有空位了。但是我们约定了队列只能从数组尾进行入队操作,而此时数组尾并没有空位提供给新入队的元素,因此实际上无法进行入队操作。
那要如何处理呢?最简单的方法就是当发生出队操作时,后面所有的元素都向着队头方向移动一位,把队尾空出一位,这每出一个元素就可以入一个元素。

当然这也不是唯一方案,还是通过循环队列解决这一问题,有兴趣的可以研究一下。
1、ADT定义
我们首先来定义顺序队列的ADT。
ADT Queue{
数据对象:D 是一个非空的元素集合,D = {a1, a2, ..., an},其中 ai 表示队列中的第i个元素,n是队列的长度。数据关系:D中的元素通过它们的索引(位置)进行组织,索引是从0到n-1的整数,并且遵循元素先进先出的原则。基本操作:[Init(n) :初始化一个指定容量的空队列。Capacity:返回队列容量。Length:返回队列长度。Head:返回队头元素,当为空队列则报异常。Tail:返回队尾元素,当为空队列则报异常。IsEmpty():返回是否为空队列。IsFull():返回是否为满队列。Enqueue():入队即添加元素,当为满队列则报异常。Dequeue():出队即返回队头元素并把其从队列中移除,当为空队列则报异常。
]
}
定义好队列ADT,下面我们就可以开始自己实现的队列。
2、初始化 Init
首先定义3个变量用于存放队列元素数组、队列容量以及队尾索引,而没有定义队头索引是因为队头索引永远等于0。
初始化结构主要做几件事。
-
初始化队列的容量;
-
初始化存放队列元素数组;
-
初始化队尾索引;
具体实现代码如下:
//存放队列元素
private T[] _array;
//队列容量
private int _capacity;
//队尾索引,为-1表示空队列
private int _tail;
//初始化队列为指定容量
public MyselfQueueArray<T> Init(int capacity)
{//初始化队列容量为capacity_capacity = capacity;//初始化指定长度数组用于存放队列元素_array = new T[_capacity];_tail = -1;//返回队列return this;
}
3、获取队列容量 Capacity
这个比较简单直接把队列容量私有字段返回即可。
//队列容量
public int Capacity
{get{return _capacity;}
}
4、获取队列长度 Length
我们并没有定义队列长度的私有字段,因为队尾索引即表示数组最后一个元素索引,即可以代表队列长度,因此只需用队尾索引加1即可得到队列长度,同时需要注意判断队列是否为空,如果为空则报错。
//队列长度
public int Length
{get{if (IsEmpty()){return 0;}//队列长度等于队尾索引加1return _tail + 1;}
}
5、获取队头元素 Head
基于我们上面的约定,队头元素永远对应数组的第一个元素,因此可以直接获取索引为0的数组元素。空队列则报错。具体代码如下:
//获取队头元素
public T Head
{get{if (IsEmpty()){//空队列,不可以进行获取队头元素操作throw new InvalidOperationException("空队列");}return _array[0];}
}
6、获取队尾元素 Tail
因为我们定义了队尾索引私有变量,因此可以直接通过队尾索引获取。具体代码如下:
//获取队尾元素
public T Tail
{get{if (IsEmpty()){//空队列,不可以进行获取队头元素操作throw new InvalidOperationException("空队列");}return _array[_tail];}
}
7、获取是否空队列 IsEmpty
是否空队列只需判断队尾索引是否小于0即可。
//是否空队列public bool IsEmpty(){//队尾索引小于0表示空队列return _tail < 0;}
8、获取是否满队列 IsFull
是否满队列只需判断队尾索引是否与队列容量减1相等,代码如下:
//是否满队列
public bool IsFull()
{//队头索引等于容量大小减1表示满队列return _tail == _capacity - 1;
}
9、入队 Enqueue
入队只需向队列内部数组尾添加一个新元素即可,因此先把队尾索引先后移动一位,然后再把新元素赋值给队尾元素,同时还需要检查是否为满队列,如果是满队列则报错,具体实现代码如下:
//入队
public void Enqueue(T value)
{if (IsFull()){//满队列,不可以进行入队列操作throw new InvalidOperationException("满队列");}//队尾索引向后移动1位_tail++;//给队尾元素赋值新值_array[_tail] = value;
}
10、出队 Dequeue
出队则大致分为以下几步:
-
判断是否为空队列,空队列则报错;
-
取出队头元素暂存,重置队头元素为默认值;
-
把队头后面所有元素向队头方向移动一位;
-
重置队尾元素为默认值;
-
队尾索引向队头方向移动一位,即队尾索引减1;
-
返回暂存的队头元素;
具体实现代码如下:
//出队
public T Dequeue()
{if (IsEmpty()){//空队列,不可以进行出队列操作throw new InvalidOperationException("空队列");}//取出队头元素var value = _array[0];//对头元素重置为默认值_array[0] = default;//队头元素后面所有元素都向队头移动一位for (int i = 0; i < _tail; i++){_array[i] = _array[i + 1];}//队尾元素重置为默认值_array[_tail] = default;//队尾索引向队头方向移动一位_tail--;//返回队头元素return value;
}
04实现(链式队列)
我们借助链表来实现链式队列,其核心思想是把链表尾节点作为队尾,把链表首元节点作为队头。
1、ADT定义
相对于顺序队列的ADT来说,链式队列的ADT少了两个方法即获取队列容量和是否满队列,这也是链表特性带来的好处。
2、初始化 Init
首先需要定义链表节点类,包含两个属性数据域和指针域。
然后需要定义3个变量用于存放队头节点、队尾节点以及队列长度。
而初始化结构主要初始化3个变量初始值,具体实现如下:
public class MyselfQueueNode<T>
{//数据域public T Data;//指针域,即下一个节点public MyselfQueueNode<T> Next;public MyselfQueueNode(T data){Data = data;Next = null;}
}
public class MyselfQueueLinkedList<T>
{//队头节点即首元节点private MyselfQueueNode<T> _head;//队尾节点即尾节点private MyselfQueueNode<T> _tail;//队列长度private int _length;//初始化队列public MyselfQueueLinkedList<T> Init(){//初始化队头节点为空_head = null;//初始化队尾节点为空_tail = null;//初始化队列长度为0_length = 0;//返回队列return this;}
}
3、获取队列长度 Length
这个比较简单直接把队列长度私有字段返回即可。
//队列长度
public int Length
{get{return _length;}
}
4、获取队头元素 Head
获取队头元素可以通过队头节点数据域直接返回,但是要注意判断队列是否为空队列,如果为空队列则报异常。具体代码如下:
//获取队头元素
public T Head
{get{if (IsEmpty()){//空队列,不可以进行获取队头元素操作throw new InvalidOperationException("空队列");}//返回队头节点数据域return _head.Data;}
}
5、获取队尾元素 Tail
获取队尾元素可以通过队尾节点数据域直接返回,但是要注意空栈则报异常。具体代码如下:
//获取队尾元素
public T Tail
{get{if (IsEmpty()){//空队列,不可以进行获取队尾元素操作throw new InvalidOperationException("空队列");}//返回队尾节点数据域return _tail.Data;}
}
6、获取是否空队列 IsEmpty
是否空队列只需判断队头节点和队尾节点是否都为空即可。
//是否空队列
public bool IsEmpty()
{//队头节点为null和队尾节点都为空表示空队列return _head == null && _tail == null;
}
7、入队 Enqueue
入队大致分为以下几步:
-
需要先创建一个新节点;
-
如果原队尾节点不为空,则把原队尾节点指针域指向新节点;
-
把原队尾节点更新为新节点;
-
如果队头节点为空,则说明这是第一个元素,所以队头和队尾都是同一个节点,因此要把队尾节点赋值给队头节点;
-
队列长度加1;
具体实现代码如下:
//入队
public void Enqueue(T value)
{//创建新的队尾节点var node = new MyselfQueueNode<T>(value);//如果队尾节点不为空,则把新的队尾节点连接到尾节点后面if (_tail != null){_tail.Next = node;}//队尾节点变更为新的队尾节点_tail = node;//如果队头节点为空,则为其赋值为队尾节点if (_head == null){_head = _tail;}//队列长度加1_length++;
}
8、出队 Dequeue
出队则大致分为以下几步:
-
判断是否空队列,空队列则报错;
-
获取队头节点数据域暂存;
-
更新头节点为原队头节点对应的下一个节点;
-
如果队头节点为空,则说明为空队列,队尾节点也要置空;
-
队列长度减1;
-
返回暂存的队头节点数据;
具体实现代码如下:
//出队
public T Dequeue()
{if (IsEmpty()){//空队列,不可以进行出队列操作throw new InvalidOperationException("空队列");}//获取队头节点数据var data = _head.Data;//把队头节点变更为原队头节点对应的下一个节点_head = _head.Next;//如果队列为空,表明为空队列,同时更新队尾为空if (_head == null){_tail = null; }//队列长度减1_length--;//返回队头节点数据return data;
}
注:测试方法代码以及示例源码都已经上传至代码库,有兴趣的可以看看。https://gitee.com/hugogoos/Planner