一、工作流
1. 工作流的定义
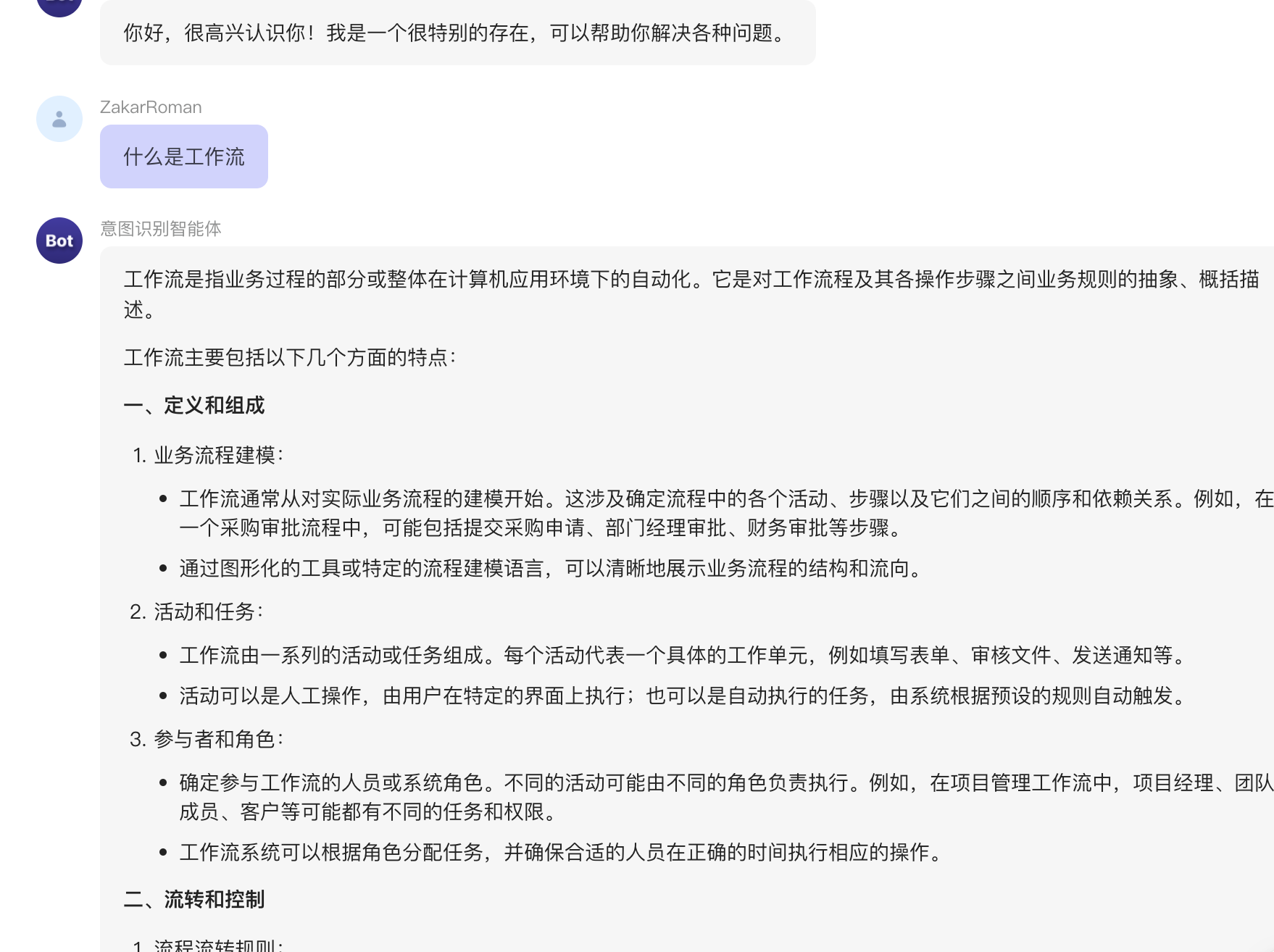
工作流由多个节点组成,这些节点可以包括大语言模型(LLM)、代码模块、逻辑判断工具、插件等。每个节点需要不同的信息来执行其功能。工作流的核心含义是:对工作流程及其操作步骤之间的业务规则进行抽象与描述,即如何将工作有序地组织起来。每个节点有两种信息来源,一种是引用前面节点给出的信息,另一种是开发者自己设定的信息,因此需要根据自身诉求在画布中将不同节点进行连接(即工作流搭建),才能让工作流进行运作,最终输出你要的结果。
工作流是一个将业务过程部分或整体自动化的过程,它将复杂任务分解为定义明确的子任务或角色,并按照既定规则和顺序执行,从而降低系统的复杂性。通过优化工作流,可以减少模型对Prompt技术和LLM推理能力的依赖,提升性能与效果,并增强应用的可靠性、稳定性、可解释性和容错性。
2.工作流的作用
工作流允许用户精细控制每一步的逻辑和输出,这一能力提高了AI应用的稳定性和可复现性。通过工作流的搭建,可以让智能体更高质量的处理复杂任务。换句话说,工作流技术明确指引LLM在何时执行哪些任务,从而让它做得更好。
3. 为什么要将任务进行拆解?
大模型并不是万能的,想通过修改prompt来提升大模型的回复效果,是在把大模型当成"人"一样去指导它们完成任务,不同的人去完成任务,其完成效果必然会受到人能力强弱的影响。所以如果大模型的能力较弱,我们应当考虑将复杂任务拆解为一个个简单的子任务,通过人为设计中间环节,让LLM先输出一些中间步骤的结果,这些中间结果可以作为后续环节的输入,然后再去解决最终的复杂问题。
二、动手实践
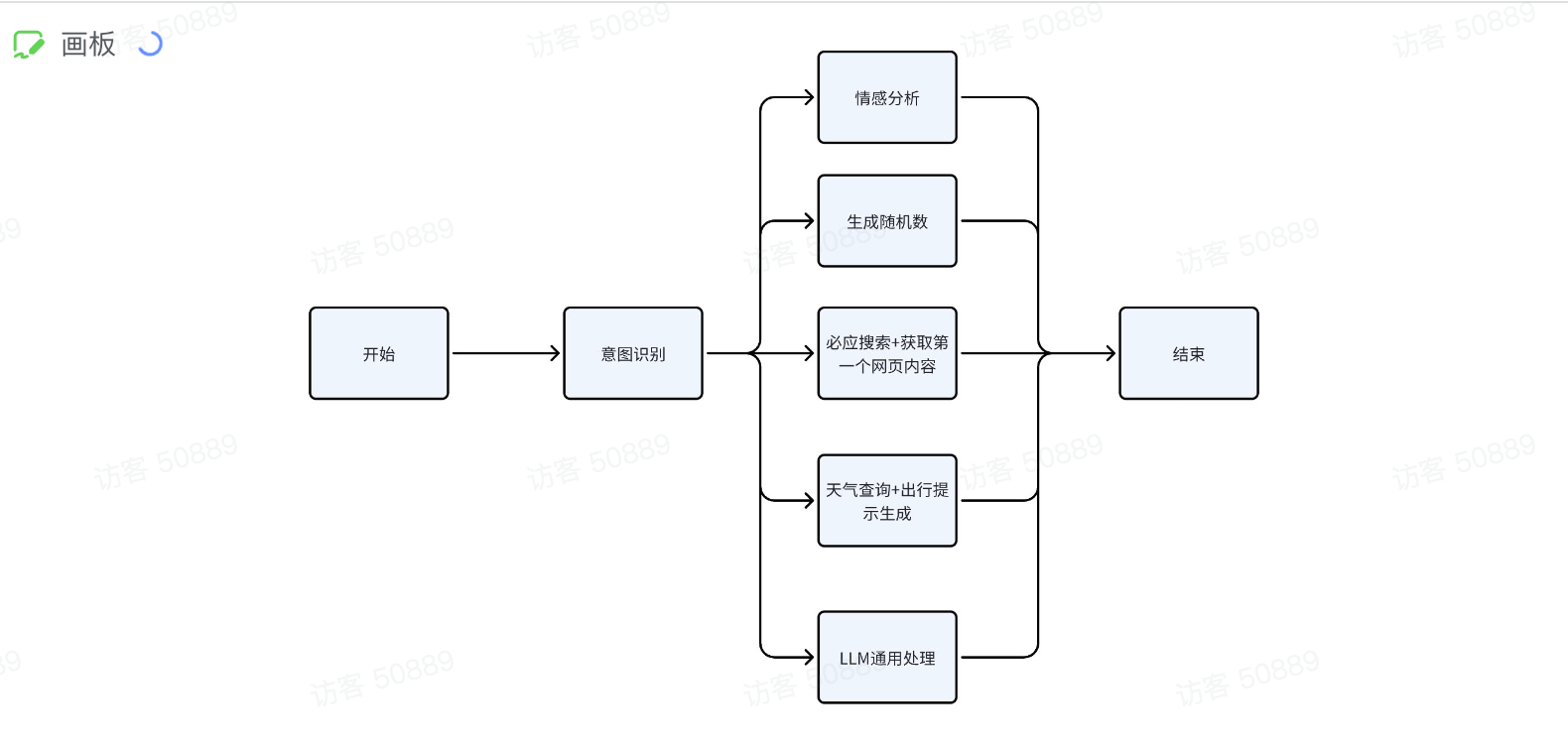
教程中提到了让我们构建一个如图所示的意图识别智能体Bot,任务包含了4个需求,让我们做出一个可解决四个任务的工作流。这四个任务分别是:
- 情感分析
- 生成随机数
- 必应搜索并获取搜索到的第一个网页的内容
- 查询目标地区天气并为用户生成出行提示
- LLM的通用处理
工作流的构建分为两种形式:
- 简单工作流:除了开始和结束,仅添加了一个节点所构成的工作流
- 复杂工作流:通过多节点组合所构建的逻辑较复杂的工作流
1.情感分析工作流
该工作流由开始节点,结束节点,以及一个大模型节点组成。
在大模型节点中,通过加入Prompt的形式,来对用户的输入进行处理。Prompt如下:
DEFINE ROLE AS "NLP专家":知识领域 = ["语言学", "互联网", "人工智能"]技能 = ["自然语言理解", "信息提取", "情感分析", "意图识别", "知识推理", "上下文关联学习", "实体识别"]经验 = "资深"任务 = "对文本进行情感分类,将其分类至对应的情感类别"# 定义情感类别
sentiment_category_infos = [{"category": "积极", "description": "文本内容表达正面情绪或态度,如快乐、满意、希望等。通常包含赞扬、鼓励或对未来的乐观预期等内容。"},{"category": "消极", "description": "文本内容体现负面情绪或态度,如悲伤、愤怒、失望等。通常反映批评、不满或对现状或未来的悲观看法等内容。"},{"category": "中性", "description": "文本内容既不表达明显的正面情绪,也不体现明显的负面情绪。通常包含客观陈述、信息传递或对事物的中立评价等内容。"}
]# 判断文本表达的情感是否符合给定的情感类别描述
def match_description(context, description):"""Step1: 一步步思考,仔细分析并理解${context}的特征和含义,判断是否和${description}的描述一致。Step2: 给出你判断的思考路径${thought},在思考路径下给出你将${context}分类为${category}的理由。Step3:根据你Step1的判断结果和Step2的分类理由,给出此次分类的置信度${confidence},置信度的取值范围为:0 <= confidence <= 1。"""return confidence# 根据文本表达的情感分类,并返回对应的情感类别
def classify(context, sentiment_category_infos):# 初始化最高置信度max_confidence = 0# 遍历所有的类别及其描述for sentiment_category_info in sentiment_category_infos:# 获取当前类别的置信度confidence = match_description(context, sentiment_category_info["description"])# 如果当前置信度高于之前的最高置信度,更新分类结果if confidence > max_confidence:max_confidence = confidencecategory = sentiment_category_info["category"]return {"classify_result": category}MAIN PROCESS:# 初始化文本变量,作为输入数据context = 读取("""{{input}}""")# 执行分类任务,输出分类结果classify(context, sentiment_category_infos)执行工作流程,严格按照json格式输出MAIN PROCESS的分类结果,禁止附加任何的解释和文字描述:
我个人对这段Prompt的理解如下:
-
角色定义 (DEFINE ROLE AS “NLP专家”):
- 角色被设定为“自然语言处理(NLP)专家”,在语言学、互联网和人工智能等领域具有资深经验,具备处理文本任务的能力,包括自然语言理解、信息提取、情感分析等。
-
情感类别定义 (sentiment_category_infos):
- 系统预先定义了三种情感类别:
- 积极:包括正面的情感,如快乐、满意、希望等。
- 消极:体现负面情绪,如悲伤、愤怒等。
- 中性:不明显表现正面或负面的情感,通常为客观陈述。
- 系统预先定义了三种情感类别:
-
情感匹配函数 (match_description):
- 该函数负责比较输入文本与某个情感类别的描述之间的匹配度。通过以下步骤进行分析:
- Step1:逐步思考和理解文本的特征,判断是否符合情感类别的描述。
- Step2:在给出判断理由的基础上,解释将文本分类至某个类别的思路。
- Step3:根据前两个步骤的分析,给出一个置信度,范围从0到1,用来量化分类的信心。
- 该函数负责比较输入文本与某个情感类别的描述之间的匹配度。通过以下步骤进行分析:
-
文本情感分类函数 (classify):
- 该函数是核心分类器,通过遍历每个情感类别的描述,调用
match_description来判断文本的情感类型。 - 过程中保存最高的置信度,并将其对应的类别作为最终分类结果。
- 该函数是核心分类器,通过遍历每个情感类别的描述,调用
-
主流程 (MAIN PROCESS):
- 在主流程中,首先读取输入的文本内容。
- 接着调用分类函数,将文本分类到最适合的情感类别。
- 输出结果时,要求严格按照JSON格式输出分类结果,而禁止附加任何解释性文字。
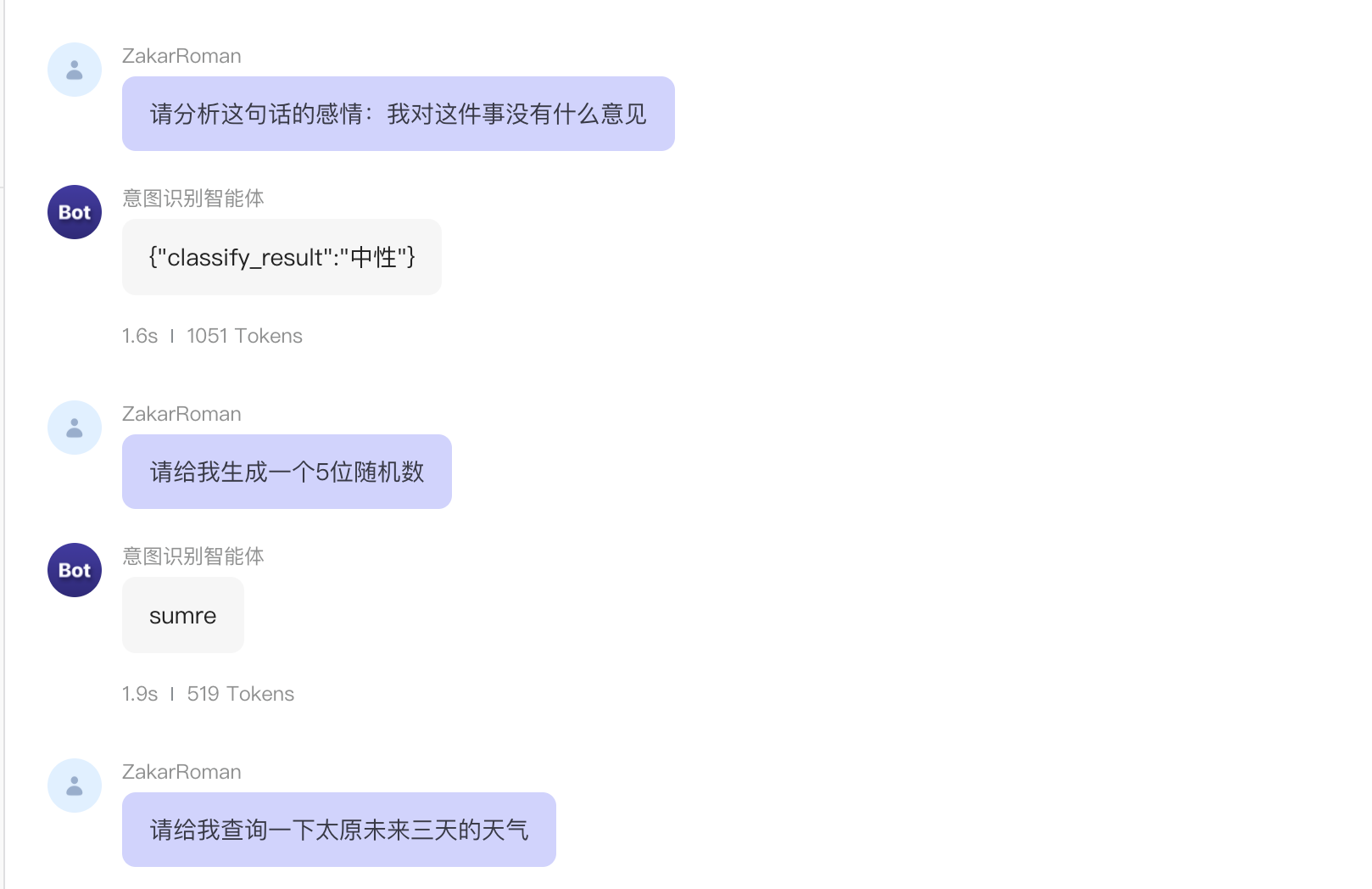
对这个工作流进行了测试,测试内容和结果如下,发现还是比较准确的。


2.随机数生成
这个工作流除输入输出节点外,由一个大模型节点(获取随机位数),两个代码节点(解析随机位数,生成随机位数)。
大模型节点的Prompt如下:
DEFINE ROLE AS "信息提取专家":任务 = "提取出用户随机数需求中的随机数长度"complete_user_input: str = 补全用户输入({{input}})
input_length: int = 提取随机位数(complete_user_input) if 提取随机位数(complete_user_input) != None else Default(8) 识别用户的输入,严格按照json格输出input_length的结果,禁止输出任何附加的解释和文字描述:
```json
{"input_length": input_length}
```
这个prompt定义了一个信息提取任务,主要目的是从用户的输入中提取随机数的长度,并输出结果为JSON格式。下面是对prompt的逐步解析:
-
角色定义 (DEFINE ROLE AS “信息提取专家”):
- 角色被定义为“信息提取专家”,主要任务是从用户输入的需求中提取随机数长度。
-
用户输入补全 (complete_user_input):
- 这里通过
补全用户输入函数,将用户输入的内容进一步补全,确保用户输入的信息完整。这可能是为了处理一些输入不完整的情况,如语句未完或含糊不清的输入。
- 这里通过
-
随机数长度提取 (input_length):
- 系统通过函数
提取随机位数(complete_user_input)从补全后的输入中提取随机数的长度。 - 如果提取函数返回的值为
None(即未能提取出随机数长度),则系统默认将随机数长度设为8(Default(8))。
- 系统通过函数
-
结果输出:
- 结果要求严格按照JSON格式输出提取的
input_length,并且禁止附加任何解释性文字或说明。
- 结果要求严格按照JSON格式输出提取的
解析随机位数代码:
import json
import reasync def main(args: Args) -> Output:params = args.params['input']def extracted_json(text):code_pattern = r'{.*}'code_match = re.search(code_pattern, text, re.DOTALL)Extracted_json = code_match.group() if code_match else Nonetry:res = json.loads(Extracted_json)['input_length']except Exception as e:res = Nonereturn resret: Output= {"input_length": extracted_json(params)}return ret
主要功能是从输入文本中提取出一个JSON格式的内容,并解析其中的input_length字段。如果提取和解析过程出现异常(如输入文本中没有有效的JSON),则返回None。
生成随机位数代码:
import random
import stringasync def main(args: Args) -> Output:params = int(args.params['length'])characters = string.ascii_lowercase + string.digitsret: Output = {"random": ''.join(random.choice(characters) for _ in range(params))}return ret
生成一个指定长度的随机字符串,字符串由小写字母和数字组成。
3. 必应搜索
该工作流除开始结束节点外,由一个bing搜索插件节点,一个代码节点,以及一个链接读取节点等。
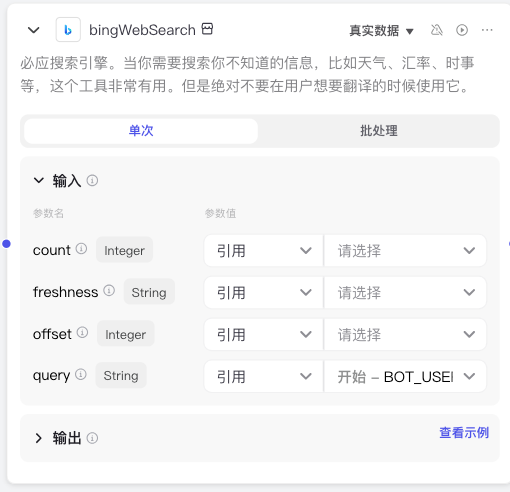
其中query代表要搜索的查询词。
其中代码节点的代码如下:
import json
import reasync def main(args: dict) -> Output:parsed_data = json.loads(args.params['input'])for item in parsed_data:regex = r"link:(http[s]?://[^\s]+)"match = re.search(regex, item)if match:return {"url": match.group(1).replace('\n','')}return {"url": ""}
这段代码的功能是从用户输入的数据中提取出包含链接 (http:// 或 https://) 的URL,并返回该链接。如果没有找到匹配的URL,返回一个空的URL字符串。以下是对代码的逐步解析:
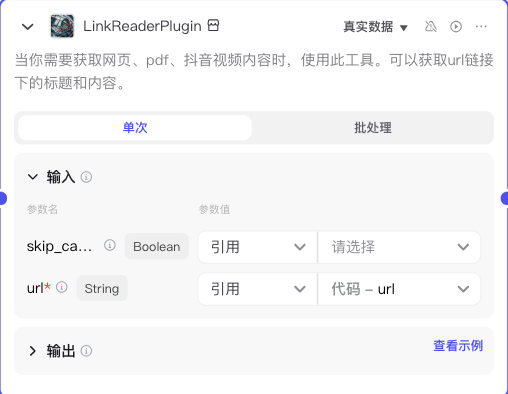
链接读取插件读取的是前一步代码节点提取出的url。
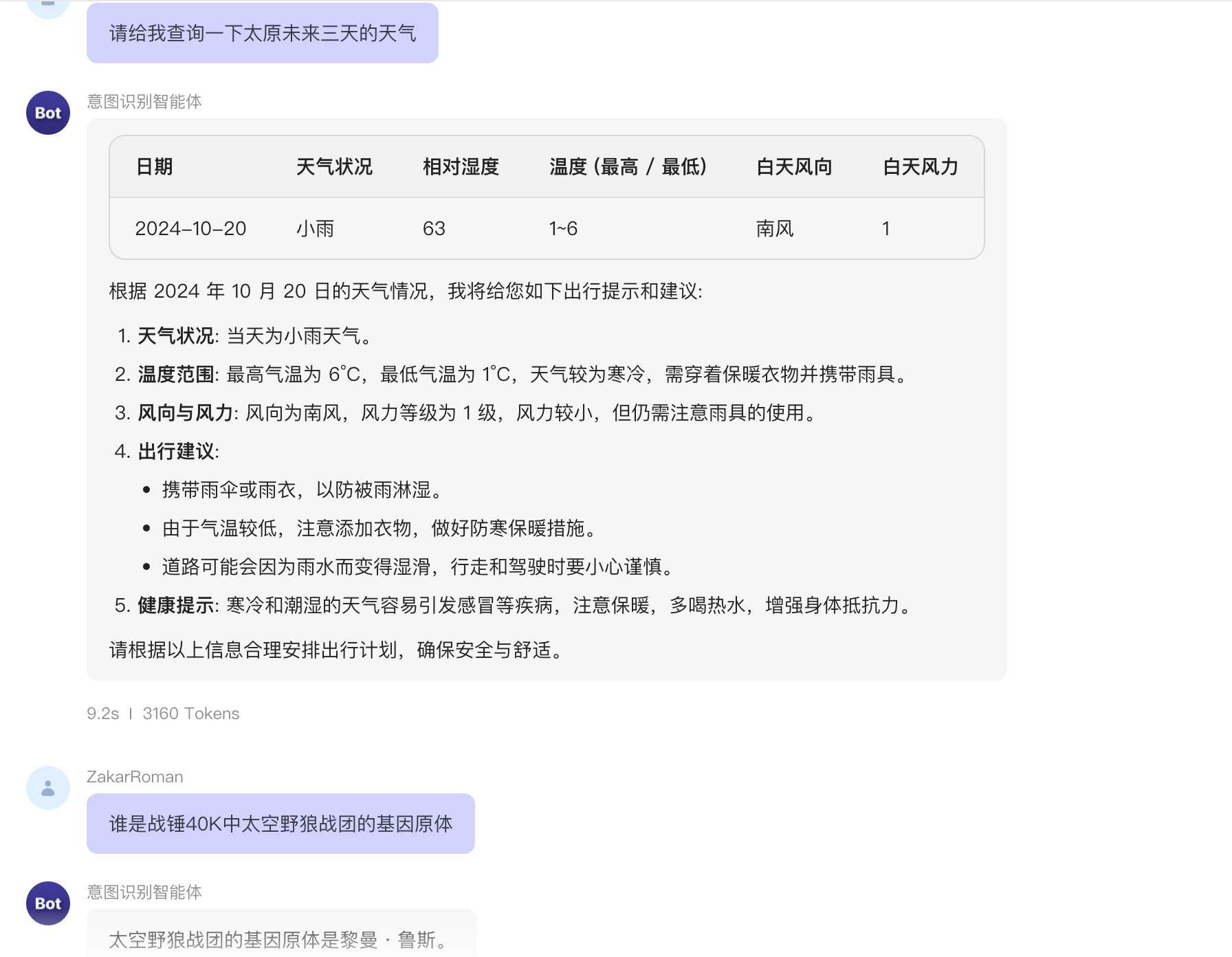
4. 天气查询
该工作流由一个代码节点(获取当前时间),一个大模型节点(获取天气参数),一个天气查询插件节点(查询天气),一个大模型节点(获取出行建议)以及开始、结束节点。
获取当前时间代码:
from datetime import datetimeasync def main(args: dict) -> Output:current_date :Output= {"date": datetime.now().strftime("%Y-%m-%d")}return current_date
获取天气参数的Prompt:
你现在要完成一个信息提取任务,请根据用户输入提取相关天气参数。用户输入: {{input}}待提取的天气参数:
1. city: 从用户输入中提取市名,包括直辖市,比如:北京市、天津市、上海市、重庆市
2. province: 从用户输入中提取省份名(如果有),不要包括直辖市(比如:北京、北京市、北京省、天津市、上海市、重庆市)
3. towns: 从用户输入中提取区/县/镇名(如果有)
4. villages: 从用户输入中提取乡/村名(如果有)
5. start_time: 根据用户输入的时间信息提取开始日期(格式: YYYY-MM-DD)
6. end_time: 根据用户输入的时间信息提取结束日期(格式: YYYY-MM-DD)示例提取:- 输入: "青岛市即墨区的天气如何?"- city: "青岛市"- province: "山东省"- towns: "即墨区"- start_time: "2024-10-7"- end_time: "2024-10-13"用户查询天气的当前时间:{{date}}
获取出行建议的Prompt:
# Role: 出行提示小助手
## Profile:
- author: kie
- version: 0.1
- language: 中文
- description: 根据天气插件返回的天气信息,生成针对用户的出行提示和建议。## Goals:
- 理解天气信息,结合用户可能的活动,生成实用的出行提示和建议。## Constrains:
- 生成的提示和建议需要根据具体的天气情况来定制。## Skills:
- 擅长理解并应用天气信息。
- 精通用户行为分析,能够根据天气情况提出合理的出行建议。## Workflows:
1. 分析天气插件返回的天气信息。
2. 根据天气情况,结合用户可能的活动,生成出行提示和建议。
3. 输出提示和建议。## Example:
- Weather_info:
{"data": [{"condition": "小雨","humidity": 91,"predict_date": "2024-07-18","temp_high": 29.66,"temp_low": 25.98,"weather_day": "小雨","wind_dir_day": "东南风","wind_dir_night": "东南风","wind_level_day": "3","wind_level_night": "3"},{"condition": "小雨","humidity": 91,"predict_date": "2024-07-19","temp_high": 29.95,"temp_low": 25.73,"weather_day": "小雨","wind_dir_day": "东南风","wind_dir_night": "东南风","wind_level_day": "3","wind_level_night": "3"},{"condition": "小雨","humidity": 90,"predict_date": "2024-07-20","temp_high": 29.96,"temp_low": 25.86,"weather_day": "小雨","wind_dir_day": "东南风","wind_dir_night": "东南风","wind_level_day": "3","wind_level_night": "3"}]
}
- OutputFormat:
| 日期 | 天气状况 | 相对湿度 | 温度(最低~最高) | 白天风向 | 白天风力 |
|----------|--------|--------|------------|--------|--------|
| 2024-07-18 | 小雨 | 91 | 25.98~29.66 | 东南风 | 3 |
| 2024-07-19 | 小雨 | 91 | 25.73~29.95 | 东南风 | 3 |
| 2024-07-20 | 小雨 | 90 | 25.86~29.96 | 东南风 | 3 |根据2024年7月18日到2024年7月20日的天气情况,我将给您如下出行提示和建议:1. **天气状况**: 未来三天均为小雨,湿度较高(约90%)。
2. **温度范围**: 最高气温在29.96°C左右,最低气温在25.73°C左右,适合穿着轻便的雨具。
3. **风向与风力**: 风向为东南风,风力等级为3级,出行时注意风力对雨伞的影响。
4. **出行建议**:- 建议携带雨具(雨伞或雨衣),以应对小雨天气。- 注意路面湿滑,行车或步行时请小心。- 如果有户外活动计划,建议选择室内活动或适当调整时间。
5. **健康提示**: 高湿度天气可能导致不适,保持适当的水分摄入,避免长时间在潮湿环境中逗留。请根据以上信息合理安排出行计划,确保安全与舒适。## 天气信息
{{input}}## OutputFormat:
| 日期 | 天气状况 | 相对湿度 | 温度(最高/最低) | 白天风向 | 白天风力 |
|----------|--------|--------|------------|--------|--------|
| 日期1 | 天气状况1 | 相对湿度1 | 最低温度1~最高温度1 | 白天风向1 | 白天风力1 |
...
| 日期n | 天气状况n | 相对湿度n | 最低温度n~最高温度n | 白天风向n | 白天风力n |根据{{start_time}}到{{end_time}}的天气情况,我将给您如下出行提示和建议:1. **天气状况**:
2. **温度范围**:
3. **风向与风力**:
4. **出行建议**:
5. **健康提示**:请根据以上信息合理安排出行计划,确保安全与舒适。
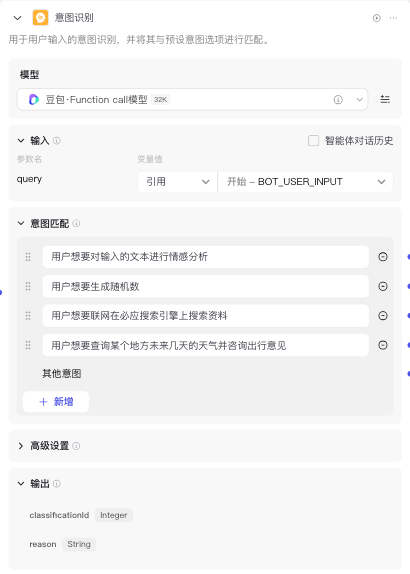
5. 意图识别工作流
将四个工作流进行拼接,并与一个未命中意图——通用处理进行并列,前后再分别加上一个意图识别节点,一个代码节点(解析用户结果)。
意图识别节点:
代码节点中解析用户结果的代码如下:
async def main(args: Args) -> Output:params = args.paramsres = [params[key] for key in params if params[key] and key!="TAKO_BOT_HISTORY" and key!="FLOW:workflow:called_plugin_ids"][0]ret: Output = {"res": res}return ret
这段代码的主要功能是从输入参数 params 中找到第一个满足条件的值,并将其作为结果返回。
res = [params[key] for key in params if params[key] and key!="TAKO_BOT_HISTORY" and key!="FLOW:workflow:called_plugin_ids"][0]
这是一个列表推导式,遍历 params 中的所有键,按照条件过滤并取出第一个符合条件的值。
过滤条件:
params[key]:检查值是否存在或为非空(Python中,空字符串、空列表等被视为False)。key != "TAKO_BOT_HISTORY":过滤掉键名为"TAKO_BOT_HISTORY"的项。key != "FLOW:workflow:called_plugin_ids":过滤掉键名为"FLOW:workflow:called_plugin_ids"的项。
[0]:获取列表中第一个满足条件的值。
测试结果如下: