C语言和C++对比
⭐
关联知识点:C和C语言区别
(1)C 语言的特点
简洁与高效:C 语言被设计为一种系统级的编程语言,它提供了对硬件的直接访问能力,并且编译后的代码通常非常紧凑,运行效率高。
全局数据:在 C 中,全局变量是一种常见的做法,尤其是在小型项目中,因为它们可以简化变量的共享和函数间的数据传递。
程序性编程:C 主要支持过程式编程,这意味着它的代码组织围绕着函数或过程,而不是对象。
(2)C++ 语言的特点
面向对象:C++ 引入了类(class)的概念,允许开发者定义抽象数据类型(ADT),并通过继承、多态等特性来构建复杂的类层次结构。
数据封装:通过将数据成员和操作这些数据的方法封装在一起,C++ 提供了一种保护内部状态不被外部直接修改的方式,这有助于提高代码的安全性和可维护性。
模板:C++ 模板提供了一种泛型编程的能力,使得我们可以编写能够处理多种数据类型的代码,比如容器类或者算法,而不需要针对每种类型都写一套特定的实现。
对于那些需要迅速完成并且要求极高执行效率的应用程序来说,C 语言可能是一个更好的选择。因为它更接近底层,程序员可以直接控制内存管理,没有像 C++ 那样的额外开销。如果考虑一个长期的项目,可能会经历多次迭代更新,那么 C++ 提供的面向对象特性和强大的模板功能可以帮助构建更加健壮、易于维护和扩展的软件架构。
加上封装后的布局成本
⭐
关联知识点:内存布局
(1)数据成员
空间成本:如果只包含简单的数据成员,那么这些数据成员会直接存储在每个对象实例中,就像C中的struct一样。类不会比等效的C struct更耗费内存。
访问成本:对于非虚成员函数和内联函数,访问数据成员的时间开销通常是微不足道的,因为编译器可以优化这些调用,类似于直接访问结构体成员。
(2)成员函数
空间成本:成员函数并不存储在每个对象实例中。它们存储在代码段,并且每个函数只有一个副本,无论创建了多少个类的对象。这意味着成员函数的存在并不会增加每个对象的大小。
执行期绑定:当使用非虚拟成员函数时,函数调用可以在编译时确定,与普通函数调用没有区别。但如果成员函数被声明为virtual,则会引入运行时多态性,需要额外的间接跳转来决定具体调用哪个派生类的函数。这涉及到一个虚函数表(vtable)和指向这个表的指针,导致一定的性能开销。
内联函数:如果成员函数被定义为inline,编译器可以选择将其展开到调用点,以减少函数调用开销。但是如果该内联函数在一个模块中有多个定义,可能会导致每个模块都生成一份拷贝,增加了代码体积但不增加运行时开销。
(3)虚拟基类与多重继承
虚拟基类:当基类在继承层次中多次出现,并且你希望确保只有一个共享实例时,可以使用虚拟基类。这会在子类对象中引入一些额外的数据结构来支持单一实例共享,从而可能略微增加对象的大小。
多重继承:在多重继承的情况下,特别是当有复杂的转换发生时(比如从派生类向其中一个基类进行类型转换),编译器需要维护一些额外的信息来正确处理这种情况,这也可能导致一定程度的性能损失。
C++对象模式
C++中,有两种class data members: static和nonstatic,以及三种class member functions: static、nonstatic和 virtual。
模型的基本思想是将类的每个成员(无论是数据成员还是函数成员)都分配一个槽位(slot),并且这些槽位按照成员在类中声明的顺序排列。槽位可以看作是指向成员的一个指针或者索引。槽位按照成员在类定义中的声明顺序依次排列。
(1)统一处理:不论是数据成员还是函数成员,都采用相同的处理方式,通过槽位来访问。简化了编译器的设计,因为不需要区分不同类型的成员。
(2)间接访问:由于每个成员都有自己的槽位,因此访问成员时需要通过槽位进行间接访问。对于数据成员来说,需要额外的一层指针解引用;对于函数成员来说,调用函数时也需要通过一个中间步骤来查找实际的函数地址。
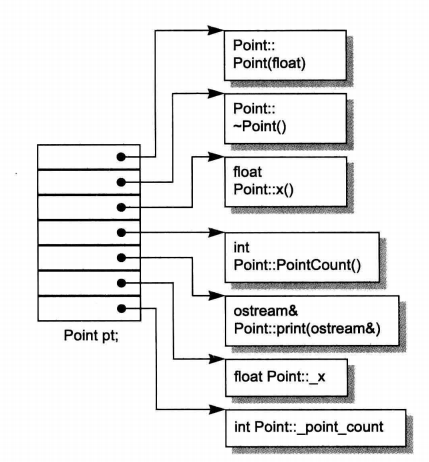
表格驱动对象模型
在这种模型中,所有与成员相关的信息被提取出来,并且存储在两个独立的表中:
一个是数据成员表(data member table),另一个是成员函数表(member function table)。每个类对象则包含指向这两个表的指针。
数据成员表直接持有类的所有数据成员的实际值。数据成员按照它们在类中声明的顺序排列在这个表中。当程序需要访问某个数据成员时,它会通过类对象中的指针找到对应的数据成员表,然后根据成员的位置索引直接读取或写入数据。
成员函数表是一系列的槽位(slots),每个槽位包含一个指向实际成员函数的指针。这些槽位同样按照成员函数在类中声明的顺序排列。当调用一个成员函数时,程序会通过类对象中的指针找到对应的成员函数表,然后根据函数的位置索引找到正确的函数指针并执行该函数。
类对象本身主要包含两个指针,分别指向数据成员表和成员函数表。类对象只包含两个指针,因此它的大小固定,不会随着成员数量的变化而变化。无论类有多少个成员,所有的类对象都有一致的结构,即都是两个指针。
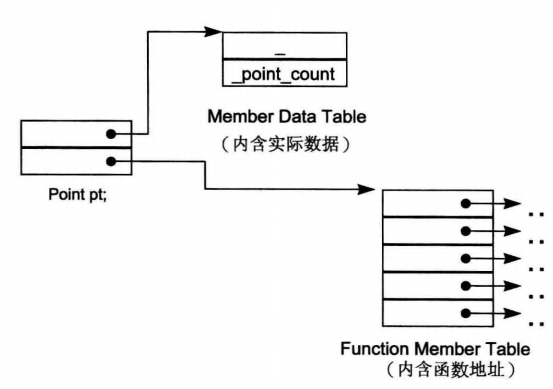
C++ 对象模型
⭐
关联知识点:static关键字
(1)数据成员
非静态数据成员直接存储在每个类对象(class object)内部。这意味着当创建一个类的对象时,这些数据成员会作为对象的一部分分配在内存中。由于这些数据成员直接位于对象内部,因此可以直接通过对象指针或引用访问它们,这提供了高效的访问速度。
静态数据成员被存储在所有类对象之外的一个单独区域。无论创建了多少个类对象,静态数据成员只有一个实例,并且所有对象共享这个实例。静态数据成员可以通过类名或对象名来访问,但它并不属于单个对象,而是整个类的一部分。
(2)成员函数
无论是静态还是非静态成员函数,都不存储在类对象内部。
成员函数代码通常存放在程序的代码段中,每个函数只有一个副本。成员函数通过对象调用时,编译器会生成相应的调用指令。对于非虚拟成员函数,调用是直接的;对于虚拟成员函数,则需要通过虚函数表(vtable)进行间接调用。
(3)虚函数
虚函数表 (vtable):每个包含虚拟函数的类都会有一个对应的虚函数表。虚函数表是一个指针数组,其中每个元素指向一个具体的虚函数实现。
虚函数指针 (vptr):每个含有虚函数的对象都有一个隐藏的指针(通常称为vptr),指向其类的虚函数表。这样,在运行时可以动态地决定调用哪个版本的虚函数。
RTTI :虚函数表的第一个槽位通常用于存放类型信息(type_info),以支持运行时类型识别(RTTI)。

加上继承
C++的继承可以是单继承,多重继承或者虚拟继承,以及这些机制对对象布局和访问效率的影响。
单继承:C++允许一个派生类(derived class)继承自一个基类(base class)。
class Library_materials { ... };
class Book : public Library_materials { ... };
class Rental_book : public Book { ... };book继承自Library_materials,而Rental_book继承自Book。
多重继承:C++也支持多重继承,即一个类可以继承自多个基类。
class iostream : public istream, public ostream { ... };虚拟继承
虚拟继承用于解决多重继承中可能出现的“菱形继承问题”,即当多个基类继承自同一个祖先类时,派生类最终可能会包含多个相同的基类实例。
菱形继承的坏处:
class A {public:int value;};
class B:public A{};
class C:public A{};
class D:public B,public C{};如果派生类同时继承自多个基类,而这些基类都直接或间接继承自同一个祖先类,派生类就会包含多个该祖先类的实例。
类D包含两个A的实例,一个通过B,一个通过C,导致了数据冗余。当需要访问祖先类的成员时,会出现不确定性。如果我们在派生类D中访问value,编译器将无法确定应该使用哪个A的实例。
由于每个相同的基类实例都占用内存,菱形继承会导致内存使用效率降低。例如,如果A类很大,D类将会消耗更多内存。
D d;
d.value=10;//编译错误:不明确在虚拟继承中,基类只会有一个实例,派生类共享这个实例。
如果在多个基类中重定义了相同的方法,派生类在调用这些方法时会引发二义性。
class A {
public:void display() { std::cout << "A" << std::endl; }
};
class B : public A {
public:void display() { std::cout << "B" << std::endl; }
};
class C : public A {
public:void display() { std::cout << "C" << std::endl; }
};
class D : public B, public C { };
D d;
d.display(); // 编译错误:不明确D不知道是应该调用 B 的 A::display() 还是 C 的 A::display()。D 有两个A的实例,所以它不明确地知道应该调用哪个 display()。
解决方法是使用虚拟继承
class A{
public:void display(){std::cout<<"A"<<std::endl;}
};
class B:virtual public A
{
public:void display(){std::cout << "B" << std::endl;}
};
class C:virtual public A
{
public:void display(){ std::cout << "C" << std::endl;}
};
class D:public B,public C {
};
int main(){D d;d.display();
// B和C虚继承自A。D类从B和C派生,并且B和C都重写了A中的display方法。
// 当尝试通过D的对象调用display时,编译器不知道应该使用B的display还是C的display,这就导致二义性
// 正确的是使用D.B::display...
}在构造D对象时,构造函数的调用顺序:
虚基类:调用最底层的虚基类构造函数(A)。
非虚基类:按照它们在派生列表中的顺序调用非虚基类的构造函数。在这个例子中,B和C是非虚基类。
派生类:最后调用派生类D的构造函数。
class istream : virtual public ios { ... };
class ostream : virtual public ios { ... };iostream类从istream和ostream继承,而这两个类都虚拟继承了ios类。因此,即使iostream间接继承了ios两次(通过istream和ostream),它在内部只会包含一个ios的实例。这种情况下,称为虚拟基类(virtual base class)。
继承模型:
简单的继承模型:
在C++最初的继承模型中,基类的成员直接被放置在派生类对象中。这意味着派生类可以直接访问基类的数据成员,不需要任何间接性。这种方式的好处是访问效率高,因为没有额外的指针或查找过程。
直接将基类成员嵌入到派生类对象中,使得内存布局紧凑,并且对基类成员的访问非常快。编译器可以很容易地生成这样的代码,它不涉及复杂的间接寻址。
如果基类有任何变化(如添加、删除或修改成员),所有使用该基类或其派生类的对象都需要重新编译。这是因为基类的变化会直接影响派生类对象的内存布局。
指针复制的方法:
在每个派生类中复制一个指向每一个相关基类的指针,这可以提供恒定时间的访问,但需要额外的内存来存放这些指针。
固定访问时间:无论继承层次多深,访问基类成员的时间都是固定的。
额外空间开销:每个派生类对象需要额外的空间来存放指向基类的指针。
虚继承
虚继承引入了间接性,以确保一个公共基类在派生类层次结构中只有一个实例。这通常通过为每个虚拟基类引入一个指向其位置的指针来实现。这些指针可能存储在一个虚函数表(vtable)中,或者作为单独的指针存在于每个派生类对象中。
优点:
(1)单一实例:保证了一个公共基类在派生类层次中只有一个实例,这对于某些设计模式(如组合/聚合)是非常有用的。
(2)减少冗余:避免了由于多次继承而导致的数据冗余。
缺点:
(1)增加了间接性:访问虚基类的成员需要通过指针间接完成,这可能会导致性能下降。
(2)复杂性增加:编译器需要处理更多的细节来维护虚基类的位置,这可能会使内存布局和运行时行为更加复杂。
(3)额外空间开销:为了跟踪虚基类的位置,每个派生类对象可能需要额外的空间来存储指针。
虚继承的内存模型在3.4节有详细讲,之后回来补充。
关键词所带来的差异
与C语言的兼容性(函数指针为例):
C++被设计为对C语言的一种扩展,C++必须能够编译大部分有效的C代码。由于C++保留了C的声明语法,有时会导致编译器难以区分某些语句是函数声明还是函数调用。这需要编译器进行“向前预览”来解决歧义,增加了语言解析的复杂度。
在C++中,一个典型的例子是函数指针的声明与函数调用之间的歧义。考虑以下C++语句:
int(*pf)(1024);这个语句既可以解释为一个函数指针pf的声明,也可以解释为一个名为pf的函数调用。
函数指针声明:int(*pf)(1024); 声明了一个指向函数的指针pf,该函数接受一个整数参数并返回一个整数。
函数调用:如果pf已经被定义为一个函数,那么int(*pf)(1024); 可能会被误解为对pf函数的调用,并且将结果赋值给一个整型变量。
编译器如何解决歧义
为了解决这种歧义,编译器需要进行“向前预览”(lookahead),即提前查看更多的上下文信息来确定正确的解析方式。在这个例子中,编译器会检查1024是否是一个有效的函数调用参数。如果1024是一个常量或表达式而不是标识符,那么它更可能是一个函数指针的声明,因为函数调用通常不会直接使用数字作为参数名。编译器必须执行更多的工作来解析这些复杂的声明,这可能会导致编译时间的增加。
代码可读性降低:对于人类程序员来说,这样的声明也可能难以阅读和理解,增加了维护代码的难度。
(这个问题没有搞懂)
为了避免这种歧义,C++11引入了新的语法,允许使用auto关键字和类型推导来简化函数指针的声明。
auto pf = [](int x) -> int { return x; }; // 使用lambda表达式初始化函数指针或者使用std::function:
#include <functional>
std::function<int(int)> pf = [](int x) { return x; };这减少了编写和解析复杂声明时的错误。虽然C++保留了C的语法以保持兼容性,但这确实带来了一些额外复杂,现代C++通过引入新的特性和语法试图减轻这些问题。
struct和class的使用
在C++中,struct和class关键字几乎可以互换使用,但它们的历史背景不同。struct源自C语言,主要用于定义数据结构;class则是C++引入的,用于实现面向对象编程中的封装、继承等特性。尽管如此,在实际使用中,两者都可以用来定义具有相同特性的用户自定义类型。
struct和class的实际区别:从语言的角度来看,struct默认成员访问级别为public,而class则默认为private。但是,这个默认行为可以通过显式指定访问控制符来改变,因此两者的功能上并没有本质的区别。
模板参数列表中的关键字:在早期的C++版本中,模板参数列表里只能使用class关键字,而不能使用struct。后来这个问题得到了修正,使得两种关键字都能被接受。
虽然从技术角度讲,C++只需要保留struct或引入新的class关键字之一即可,但实际上保留struct是为了方便C程序员过渡到C++,同时引入class则是为了表达C++特有的面向对象编程理念。
(标准答案:看个人喜好)
策略性正确的 struct
在C语言中,有时会使用一种技巧来创建可变大小的结构体。
struct mumble {/* stuff */char pc[1];
};//从文件或标准输入装置中取得一个字符串.
//然后为struct本身和该字符串配置足够的内存.
struct mumble *pmumble = (struct mumble*)malloc(sizeof(struct mumble) + strlen(string) + 1);
strcpy(pmumble->pc, string);这里char pc[1]实际上是一个占位符,用于动态分配额外的内存。通过这种方式,可以分配足够的内存来存储一个字符串。
这种方法依赖于结构体成员在内存中的布局是连续的,并且可以扩展最后一个成员的大小。
在C++中,如果将上述技巧应用于类,可能会遇到以下问题:
访问控制:C++类可以有多个访问控制部分(public, protected, private),这些部分的数据成员在内存中的排列顺序是不确定的。
class stumble {
public:// operations ...
protected:// protected stuff
private:/* private stuff */char pc[1];
};char pc[1]的位置可能因为不同的编译器优化而变化,导致无法保证与C语言中相同的内存布局。如果类是从其他类派生的,基类和派生类的数据成员的布局也是不确定的。这会影响内存布局的一致性。如果类中有虚函数,编译器会在每个对象中插入一个指向虚函数表的指针(vtable pointer),这也会影响内存布局。
对象的差异
C++程序设计模型支持的三种编程范式
过程式编程范式 :
类似于C语言,使用函数和全局变量。
char boy[] = "Danny";
char *p_son;
p_son = new char[strlen(boy) + 1];
strcpy(p_son, boy);
if (!strcmp(p_son, boy)) {take_to_disneyland(boy);
}抽象数据类型模型 (ADT)
提供一组公开接口,内部实现细节隐藏。
String girl = "Anna";
String daughter = girl;
if (girl == daughter) {take_to_disneyland(girl);
}面向对象编程范式
通过继承和多态来封装和扩展功能。
class Library_materials {
public:virtual bool late() const = 0;virtual void fine() = 0;virtual void check_in() = 0;virtual Lender* reserved() const = 0;virtual void notify(Lender* plend) = 0;
};
class Book : public Library_materials {
public:// 实现基类的纯虚函数
};
void check_in(Library_materials* pmat) {if (pmat->late()) {pmat->fine();}pmat->check_in();if (Lender* plend = pmat->reserved()) {pmat->notify(plend);}
}多态和切片问题
多态通过基类指针或引用调用派生类的方法。通过虚函数机制在运行时动态绑定具体的方法。
切片问题
将派生类对象赋值给基类对象时,派生类特有的部分会被“切掉”。
Library_materials thing1;
Book book;
thing1 = book; // 切片问题
thing1.check_in(); // 调用的是 Library_materials::check_in()解决方案:使用基类指针或引用。
Library_materials& thing2 = book;
thing2.check_in(); // 调用的是 Book::check_in()类对象的内存布局
一个类对象所需的内存大小包括:
非静态数据成员的总和大小。
由于对齐需求而填充的空间(可能存在于成员之间或集合体边界)。
支持虚函数的额外开销(通常是虚函数表指针)。
指针的类型
32位机器上指针都是32位,从内存角度来看,并没有什么区别。
跟编译器如何解释指针指向内存内容有关。转换(cast)其实是一种编译器指令。大部分情况下它并不改变一个指针所含的真正地址,只影响“被指出之内存的大小和其内容"。