写在前面
我觉得,工作中最有价值的就是及遇到的问题了,特别时线上这种容易让人血压升高的环境中遇到的问题,本文就是记录这些血压升高时刻。
如果你遇到什么真实环境的问题,也欢迎评论或者私信分享给我!!!
1:CPU飙升
CPU飙升的问题,我们一般都需要先定位导致CPU飙升的代码位置,一般按照如下步骤(具体可以参考这里 ):
- 定位导致CPU彪高的线程
使用top,然后P按照CPU占用量排序,如下:
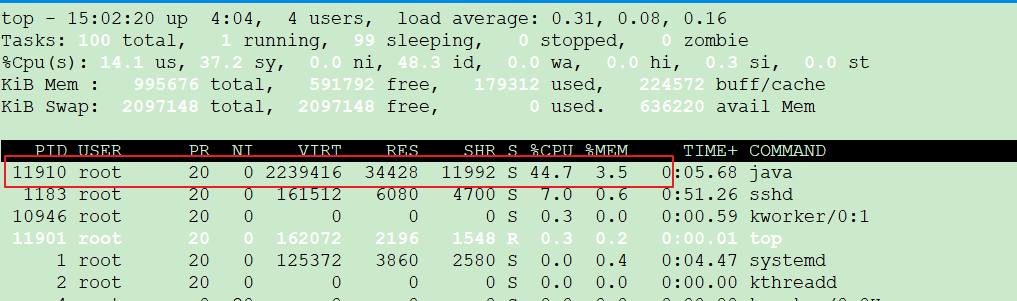
这里我们定位到的进程号是11910。
- 根据进程定位线程
命令top -hP PID,如下:
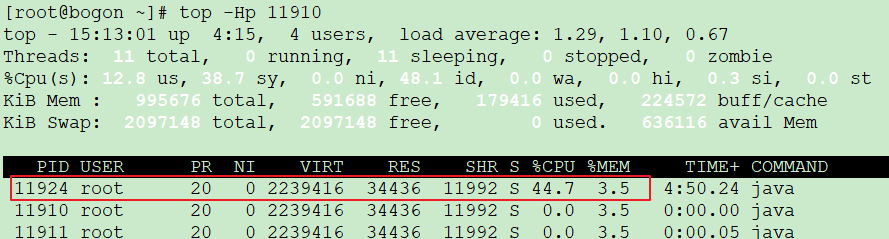
想要定位具体代码还需要将其转换为16进制,如下:
[root@bogon ~]# printf '%x\n' 11924
2e94
- 定位代码
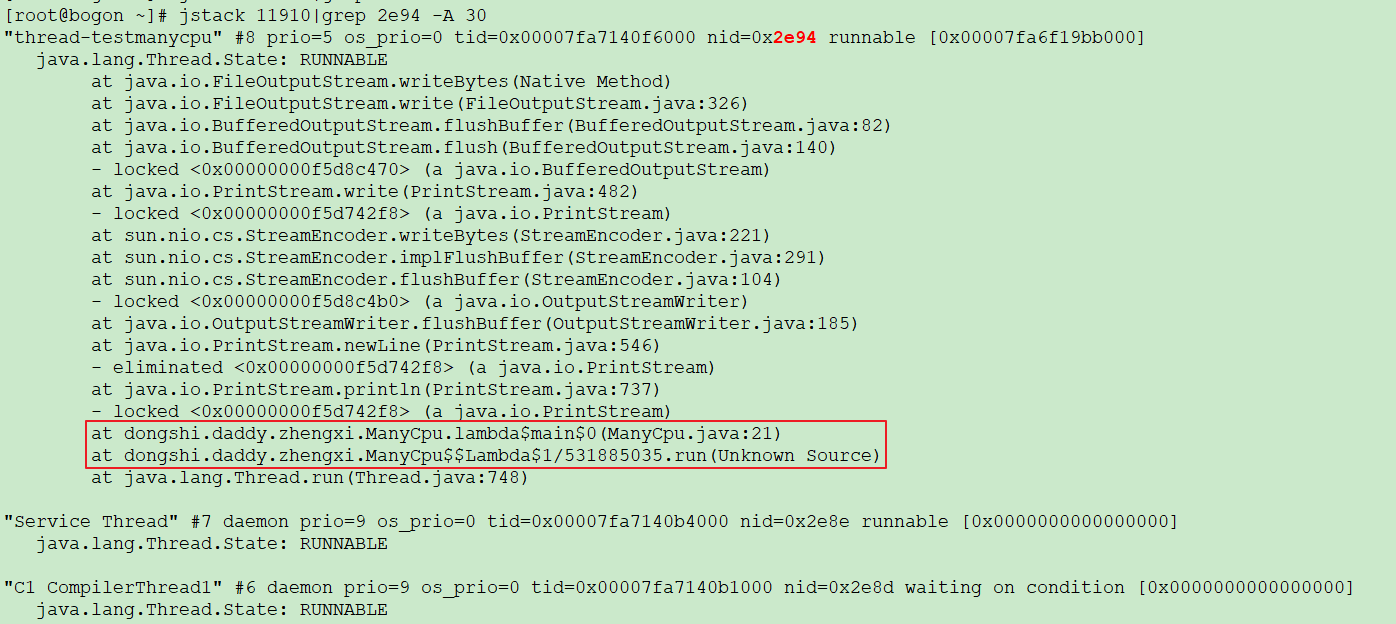
红框就是具体的代码位置,接着我们就可以来排查具体的问题了,接着看下线上环境遇到的实际问题。
1.1:Word导出导致的CPU飙升
我司表单业务中有一个导出功能,某表单有大量的图片,在导出时会将图片写到Word中然后导出,这个写图片到Word的过程耗费了大量CPU资源。临时解决方案是限制业务使用,避免网站整体不可用,终极解决方案是Word导出拆分到单独的组件中,并限制导出的数据量。
1.2:大量邮件发送导致CPU飙升
系统中有一个查询某(为了方便表述,我们叫做表A吧)表数据,来发送邮件的功能,该功能上线后的很长一段时间内,因为相关功能无人使用,导致发送邮件所查询表无数据,突然,功能开始有人使用,就导致表A中当天产生了2千多条数据。同时开发的程序在for每次发送邮件后会立即发送下一封,就导致出现问题了,最终解决方案是,增加人工休眠,释放CPU,避免CPU被打满。
2:OOM
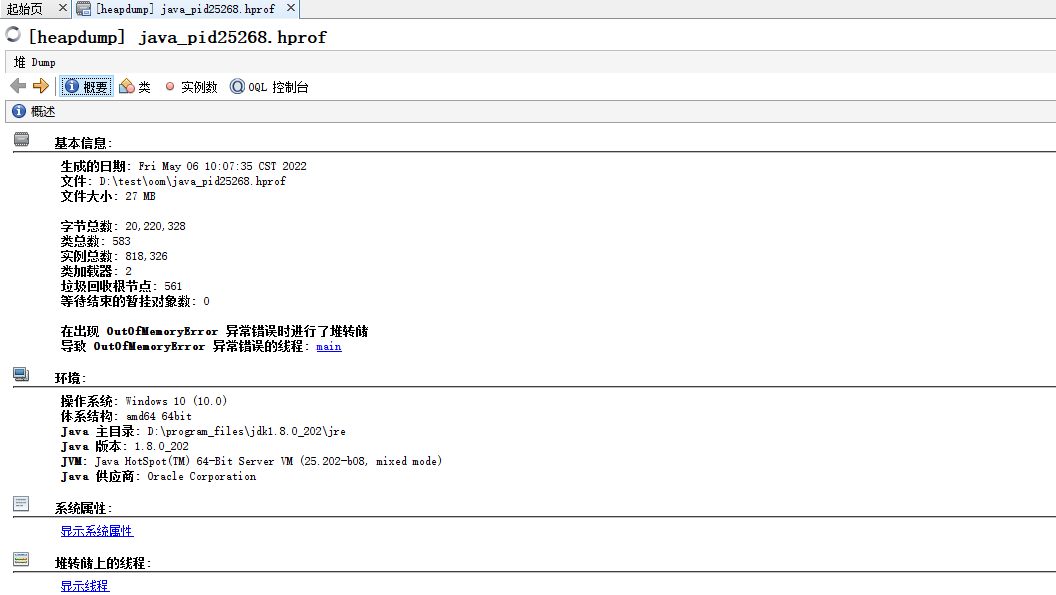
OOM全称是就out of memory,一般是堆内存溢出导致,而堆是来存储对象实例数据的,所以该问题一般都是因为创建了过多的对象导致,因此我们需要先来找到这个过多的对象都是谁。为了保留当时的现场,我们一般会配置-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=d:\\test\\oom来生成堆转储文件,以便后续排查问题,此时我们可以将堆转储文件拷贝出来后,使用jvirtualvm工具查看(具体可以查看这里 ),如下:

另外还有一种就是允许我们直接线上查看的,此时可以按照如下步骤操作定位对象(具体可以查看这里 ):
- jps获取程序进程号
C:\WINDOWS\system32>jps -l | findstr "java8"
23028 java8instrument-1.0-SNAPSHOT.jar
- jmap -histo PID获取类的个数和大小
$ jmap -histo 26396num #instances #bytes class name
----------------------------------------------1: 99999 1599984 dongshi.daddy.zhengxi.People2: 950 479976 [Ljava.lang.Object;3: 5138 479224 [C4: 455 136400 [B5: 4989 119736 java.lang.String6: 899 102840 java.lang.Class7: 791 31640 java.util.TreeMap$Entry...
2.1:导出大量数据数据无限制
有个导出功能,是给客服部门用的,客服部门因为某些功能需求需要在每周五下班前导出文件并这里整理相关内容,而因为当时导出功能无任何使用上的限制,就导致客服人员感觉导出太慢就频繁点击,最终导致OOM,解决办法是限制导出的导出频率以及引入缓存机制增加导出速度,提升用户体验。
3:栈溢出
栈溢出对应的错误时java.lang.StackOverflow,一般是由于方法的调用栈深度过深,导致栈内存空间不足导致,这种错误不需要我们定位具体的代码位置,因为在报错中会清晰的告知我们位置,如下:
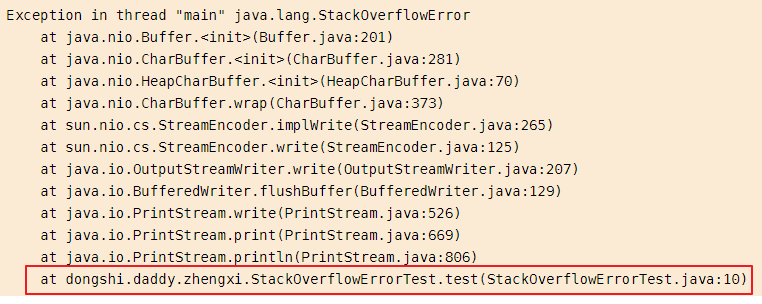
3.1:非常用业务场景导致递归结束条件一直为true
线上的一个业务使用了递归来处理,因为出现了一种新的场景,导致修改递归结束条件的代码不能执行到,就导致递归一直执行,最终栈溢出,解决方法是兼容新场景。
4:MySQL升级到8导致的数据顺序错乱bug
一次一线同事突然反馈说,某个业务功能的展示的数据错乱了,通过review代码获取到用来查询对应数据的sql,在正式数据库果然复现问题,测试环境却如何都复现不了,最终定位的原因是,正式环境数据库从5.7升级到了8.0(升级的原因是rds5.7版本磁盘容量为3T无法继续扩容,而8没有限制!),而使得5.7中的groupby 的隐式转换问题暴露了出来,接下来我们简单看下MySQL的隐式转换。
4.1:准备测试数据
mysql> show create table a\G
*************************** 1. row ***************************Table: a
Create Table: CREATE TABLE `a` (`name` varchar(36) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
1 row in set (0.00 sec)
ogon:~ xb$ mysqldump -h127.0.0.1 -P3306 -uroot -p --add-locks=0 --no-create-info --single-transaction --set-gtid-purged=OFF test --tables a --where="1=1"
Enter password:
-- MySQL dump 10.13 Distrib 5.7.28, for macos10.14 (x86_64)
......
INSERT INTO `a` VALUES ('a'),('a'),('b'),('b'),('c'),('c'),('z'),('z'),('f'),('f'),('e'),('e');
4.2:mysql5.7查询
mysql> select version();
+------------+
| version() |
+------------+
| 5.7.28-log |
+------------+
1 row in set (0.01 sec)mysql> select * from a group by name;
+------+
| name |
+------+
| a |
| b |
| c |
| e |
| f |
| z |
+------+
6 rows in set (0.00 sec)
可以看到默认按照升序排序了,相当于是执行了:
mysql> select * from a group by name asc;
+------+
| name |
+------+
| a |
| b |
| c |
| e |
| f |
| z |
+------+
6 rows in set, 1 warning (0.00 sec)
当然你也可以选择降序显示:
mysql> select * from a group by name desc;
+------+
| name |
+------+
| z |
| f |
| e |
| c |
| b |
| a |
+------+
6 rows in set, 1 warning (0.01 sec)
不想排序的话可以这样:
mysql> select * from a group by name order by null;
+------+
| name |
+------+
| a |
| b |
| c |
| z |
| f |
| e |
+------+
6 rows in set (0.01 sec)
项目中使用的语句就是类似select * from a group by name;这种只有group by的语句。如果是使用8.0查询的话,结果如下:
mysql> select * from a group by name;
+------+
| name |
+------+
| a |
| b |
| c |
| z |
| f |
| e |
+------+
6 rows in set (0.01 sec)
所以就导致问题发生了。
4.3:mysql5.7为什么要默认排序?
group by就是要对一组数据进行分组,而分组的对象如果是一组有序数据的话则进行分组的复杂将会大大降低,具体有两种,第一种是如果是group by的字段是索引的话可以直接使用到B+树索引,如果是不是索引的话,则会将数据查询到内存中在sort buffer排序,也可以获取到一组有序的数据。但是实际上,group by的隐式排序是一个很大的坑,总会带来一些问题,所以mysql8就去掉隐式排序了,甚至不支持group by desc/asc这种语法,如下:
mysql> SELECT pid,appName from T group by appName DESC;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'DESC' at line 1
如果想要排序的话就显式的使用order by来完成。
5:服务刚启动时出现接口超时
公司有一个系统在刚启动的一段时间内总是会出现一些接口超时,开始怀疑可能是GC,程序中存在锁,系统资源紧张,数据库慢,等原因的导致,但是经过排查都不是,但程序肯定还是在干什么了,所以决定使用arthas的火焰图来分析,使用脚本,收集系统刚启动时10秒钟的CPU信息:
function flamegraph_sample(){# 保证系统启动了while sleep 1; do curl -sS --connect-timeout 3 -m3 http://127.0.0.1:8080/health | grep ok && break; done# 获取进程的进程号pid=`pgrep -n java`# 连续生成3个采样的html文件,每个文件执行10秒钟for i in {1..3}; dojava -jar arthas-boot.jar -c "profiler start --alluser" "$pid";sleep 10s;java -jar arthas-boot.jar -c "profiler stop --file /tmp/flamegraph_cpu_%t.html " "$pid";done# 停止arthasjava -jar arthas-boot.jar -c "stop" "$pid";
}
生成的3个采样html中的前两个如下图:

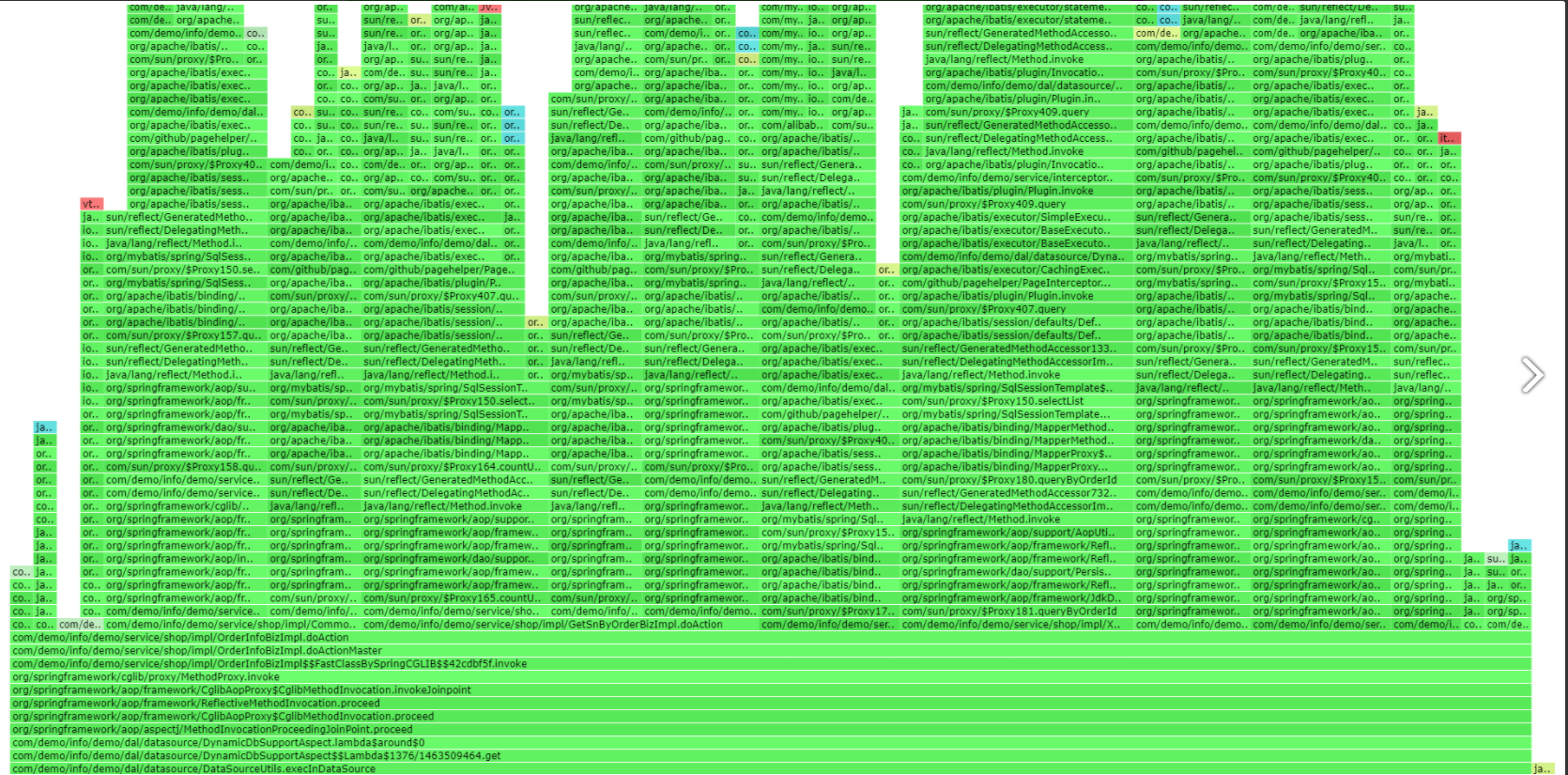
对比可以可以看到第二个图比第一个图少了很多的,红色区域,其实红色区域是在做类加载的工作,所以就怀疑是因为加载了很多的类导致接口超时了,所以尝试在系统启动时执行类加载的工作,如下:
private static final String[] CLASS_PREFIX_ARR = new String[] {"org.apache", "com.thoughtworks", "io.netty", "com.google", "io.grpc","com.alibaba", "org.springframework", "cn.hutool", "com.fasterxml", "org.hibernate", "io.opencensus", "org.redisson", "io.micrometer", "io.prometheus",};PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
for (String classPrefix : CLASS_PREFIX_ARR) {Resource[] resources;try {resources = resolver.getResources("classpath*:" + StringUtils.replaceChars(classPrefix, '.', '/') + "/**/*.class");} catch (IOException e) {ExceptionUtils.rethrow(e);return;}for (Resource resource : resources) {String className = null;try (InputStream is = resource.getInputStream()) {ClassReader cr = new ClassReader(is);className = StringUtils.replaceChars(cr.getClassName(), '/', '.');Class<?> clz = Class.forName(className);log.info("preLoadClass success: " + className + ", classLoader: " + clz.getClassLoader());} catch (Throwable e) { log.warn("preLoadClass failed: " + className);}}
}
上线观察,未再出现系统启动时的接口超时问题,至此,问题解决。
6:young GC时间长
现象是GC stw时长特别长,400多毫秒,长的达到了540多毫秒,怀疑是发生了full GC,但通过查看GC日志,并没有,因此确定是因为发生了young GC,因为当时使用的是jdk8,配置参数如下:
-Xmx4g -Xms4g
而jdk8默认的GC策略 是并行GC,并行GC是一种吞吐量优先的GC算法,所以我们就怀疑是垃圾收集器为了维持吞吐量而牺牲掉了stw时长,而G1在jdk8已经成熟,所以就考虑使用G1垃圾收集器,修改为G1后配置参数为:
-Xmx4g -Xms4g -XX:+UseG1GC -XX:MaxGCPauseMillis=50
接着重启服务,运行观察,表现优秀,GC时长基本上维持在50ms以下,但程序运行了一天多之后,突然出现了一次超长时间的GC stw,时间达到了1.2s,相当残暴,有些不知所措,没有什么好办法,就是上网各种查G1的坑,也都没解决,那就看日志吧,修改参数如下打印GC日志:
-Xmx4g -Xms4g -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:+PrintGCDetails -XX:+PrintGCStamps -Xloggc:/var/log/gc.log
,终于在日志中找到了如下的可疑信息:
[Parallel Time: 1861.0 ms, GC Workers: 48]
提示GC线程48个,这就奇怪了,因为我们的机器是4核的,GC线程怎么可能会这么高,虽然不知道为什么这么高,但严重怀疑这就是导致GC STW时长超长的真凶了,这么多的线程争抢4核势必造成非常严重的资源争抢,导致频繁上线文切换,所以先增加如下参数,限制GC线程数:
-XX:ParallelGCThreads=4
再重启,观察,问题解决,但为什么GC线程数会是48,之后经过和运维工程师的沟通,发现,是因为应用部署在k8s的环境中,k8s限制了pod只能使用4g的内存,只能使用4核cpu,但是物理机是72核的,而G1启动的工作线程数量的策略是这样的:
1:当核数小于等于8时,取核数
2:当核数大于8是,取(核数*(5/8)+3)
所以我们这里就是(72*(5/8)+3)=48,所以根本原因是JVM看到了物理机的72核,所以本质上,造成问题的原因是k8s的资源隔离不彻底,只是限制了pod使用4核,但是却让pod中的jvm看到了72核(其实是不应该看到的))。
7:young GC过于频繁
现象是这样子的,young GC很频繁,每秒1次,有时候每秒2次,每次GC 60ms 左右,不算长,通过jstat -gcutil ${pid} 1000 1000每秒打印1次,打印1000次,如下图:
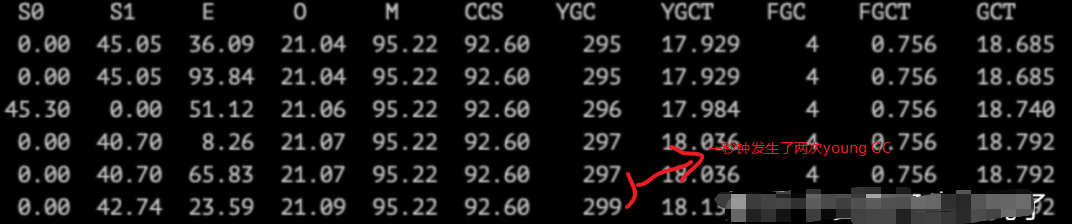
为了进一步的印证young GC 过于频繁,我们将GC日志上传到gceasy.io , 发现其吞吐量只有93%。线上当前的配置如下:
-Xmx8g -Xms8g -Xmn2g -XX:+UseConcMarkSweepGC
很明显,young GC发生频繁,而且几乎没有full GC,所以是不存在内存泄漏问题,问题的原因是young区的内存大小太小了,所以就需要调大-Xmn,即增加年轻代的大小,以将young GC每4秒钟到5秒钟发生一次,作为优化目标来调整该参数,最终调整参数为-Xmn2.9g,但又发现gc 时长增加到了80ms左右,虽然时间也可以接受,但还是继续尝试优化这个时间,jvm使用的GC是CMS,而cms在年轻代使用的垃圾收集器是ParNew,ParNew采用的垃圾收集算法是复制算法,所以我们就希望能够减少在s0,s1之间复制对象的量来降低young gc的时间,想要实现这个效果,就需要调整参数-XX:MaxTenturingThreshold={age},这里age的默认值15,即15次young gc之后才会被提升到老年代,降低这个参数值,可以让对象提早提升到老年代就可以实现我们的目标了,但如何确定合适的年龄也是个问题,太小了,可能会导致会导致full GC,为了确定这个年轻,增加了参数-XX:PrintTenuringDistribution,配置如下:
-Xmx8g -Xms8g -Xmn2.9g -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:d:\\test\\gc1423.log -XX:+PrintTenuringDistribution -Dfile.encoding=UTF-8
打印出不同分代对象的个数和大小信息,如下图(来自gceasy.io 分析结果):
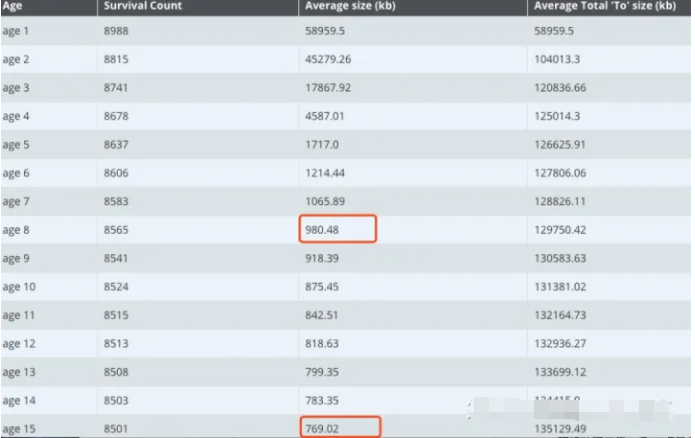
可以看到存活区15岁的对象个数是8501,8岁的对象个数是8565,比例为8501/8565=99.2%,可以看到只要存活区到8岁的对象,存活到15岁的比例达到了99.2%,也就是达到8岁的对象就可以直接让其晋升到老年代了,因此调整参数-XX:MaxTenturingThreshold=7,这样就节省了8次大量存活对象从一个survivor区复制到另一个survivor区的成本,优化后,gc时间维持在了71ms左右,吞吐量也提高到了97%左右。
8:parallelStream丢数据问题
线上突然出现列表数据有时候有时候小的问题,测试环境,无法复现,确认数据库无问题,服务部署的程序也都是同一个版本,后来怀疑是数据量的问题,就将正式环境环境数据复制到测试环境,成功复现问题,通过debug发现是parallelStream的锅,修改为stream解决,程序如下:
// 过滤当前存在自己办理任务的
List<Task> nowTodoTaskList = taskService.createTaskQuery().taskAssignee(taskUserId).list();
Set<String> nowTodoInstanceSet = new HashSet<>();
nowTodoTaskList.parallelStream().forEach(v -> nowTodoInstanceSet.add(v.getProcessInstanceId()));
nowTodoTaskList有n条数据,有时会出现nowTodoTaskList结果小于n的的情况,但大部分时候都是等于n的,怀疑是底层JUC多线程程序有bug,将nowTodoTaskList.parallelStream().forEach...改为nowTodoTaskList.stream().forEach解决问题。
9:shardingsphere 输出了delete但数据没删掉
一次突然接到一线人员反馈,说某报表统计数据,近端时间数据统计量出现不符合业务的大量增长,通过排查数据库发现是因为老数据没有删除掉导致问题。然后就是测试环境各种复现,各种正常,最后直接拿delete语句直接在正式环境执行,报错如下:
ERROR 1175 (HY000): You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column.
意思是打开了更新安全模式,即如下:
mysql> show variables like 'sql_safe_updates';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| sql_safe_updates | ON |
+------------------+-------+
1 row in set (0.00 sec)
经过和运维沟通,确实修改了sql_safe_update 参数,给出的解释是为了数据误删除,倒也合理。知道了问题,晚上修改程序,带上where条件,再冲泡程序,解决问题。
10:一次系统内存被占满问题排查
突然接到系统告警,某线上机器16G的内存目前已经被某应用占用已经超过了80%,并且还在不断的上升中,事情还是蛮严重的,于是紧急开始了问题的排查。
首先怀疑是不是发生了内存泄露,于是先检查了配置,如下:
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m
这里最大堆内存设置为4G,所有问题肯定不是出在堆,那么还有谁如此大的可能占用如此多的内存,我相信大多数人都会和我一样,想到堆外内存。到这里其实还是不知道从哪里下手,于是就和业务方做沟通是否做了什么不同于往日的操作,果然,他们使用了一个任务导入功能,该功能用来将话务系统的通话信息同步到下游系统。所以基本就可以怀疑是因为这个操作了。那么到底是否是因为这个操作呢,还需要一番测试,所以我就紧急在测试环境一台空闲的机器部署了环境来复现问题。不出所料,问题成功被复现出来。
所以,接下来就是来定位问题了,首先直接将测试环境的堆内存通过命令jmap -dump:live,format=b,file=xxxx.hprof pid,然后通过MAT分析堆内存,倒是发现了一些bytebuffer相关的类,但是呢不多,所以无法直接确定就是因为堆外内存造成的问题。接着是review代码,发现用了一个中间件部门开发的一个RPC框架,怀疑触发了该中间件某个bug,所以和相关同事沟通,他们表示愿意进行压测协助复现,第二天给出结果,没有问题,所以有事无果。
继续,查询资料发下参数-XX:MaxDirectMemorySize可以限制堆外内存的大小,既然怀疑是因为堆外内存问题造成,那么限制大小不就行了,所以参数修改为:
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:MaxDirectMemorySize=2g
不出所料啊,还是不行,我的godden啊,到底在回事,再次陷入僵局。没办法,继续硬刚堆外内存,查询资料,NativeMemoryTracking,即NMT可以记录堆外内存的详细信息,所以再次使用NMT生成相关信息,依然无果,未找到有效信息。
这个时候,想到了初学编程时老师常说的一句话,JVM问题基本都是因为配置不当造成的,所以将目光再次聚焦到了配置上,当前我们的配置是:
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:MaxDirectMemorySize=2g
但是很多默认的配置是看不到的,所以使用命令jmap -heap pid查看当前使用的配置:
C:\Windows\system32>jmap -heap 43192
Attaching to process ID 43192, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08using thread-local object allocation.
Parallel GC with 8 thread(s)Heap Configuration:MinHeapFreeRatio = 0MaxHeapFreeRatio = 100MaxHeapSize = 4271898624 (4074.0MB)NewSize = 89128960 (85.0MB)MaxNewSize = 1423966208 (1358.0MB)OldSize = 179306496 (171.0MB)NewRatio = 2SurvivorRatio = 8MetaspaceSize = 21807104 (20.796875MB)CompressedClassSpaceSize = 1073741824 (1024.0MB)MaxMetaspaceSize = 17592186044415 MBG1HeapRegionSize = 0 (0.0MB)Heap Usage:
PS Young Generation
Eden Space:capacity = 49807360 (47.5MB)used = 4973568 (4.7431640625MB)free = 44833792 (42.7568359375MB)9.985608552631579% used
From Space:capacity = 17301504 (16.5MB)used = 14145440 (13.490142822265625MB)free = 3156064 (3.009857177734375MB)81.75844134706439% used
To Space:capacity = 18874368 (18.0MB)used = 0 (0.0MB)free = 18874368 (18.0MB)0.0% used
PS Old Generationcapacity = 108527616 (103.5MB)used = 43776384 (41.7484130859375MB)free = 64751232 (61.7515869140625MB)40.3366310009058% used1958 interned Strings occupying 177072 bytes.
这一行MaxMetaspaceSize = 17592186044415 MB引起了我们的注意,元空间是一个天文数字,所以将目光从堆外内存移到了元空间,当时不认为问题出在这里,只是当作了一个潜在的问题来处理,所以也配置进行了限制,但没想到带来了意外之喜,此时配置如下:
-Xms4g -Xmx4g -Xmn2g -Xss1024K -XX:PermSize=256m -XX:MaxPermSize=512m -XX:MaxDirectMemorySize=2g
这个是项目使用1.7时使用的配置,其中-XX:PermSize=256m -XX:MaxPermSize=512m是设置永久代的,但在1.8,已经取消了永久代了,所以这个2个参数已经无效了,但是并没有新增针对1.8元空间的限制配置,所以尝试增加配置-XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m,此时配置如下:
-Xms4g -Xmx4g -Xmn1g -Xss1024K -XX:MetaspaceSize=100m -XX:MaxMetaspaceSize=110m
jdk1.7相关的配置permsize,maxpermsize使用metaspacesize,maxmetaspacesize代替
再次运行,查看配置:
C:\Windows\system32>jmap -heap 42712
Attaching to process ID 42712, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.202-b08using thread-local object allocation.
Parallel GC with 8 thread(s)Heap Configuration:MinHeapFreeRatio = 0MaxHeapFreeRatio = 100MaxHeapSize = 4294967296 (4096.0MB)NewSize = 1073741824 (1024.0MB)MaxNewSize = 1073741824 (1024.0MB)OldSize = 3221225472 (3072.0MB)NewRatio = 2SurvivorRatio = 8MetaspaceSize = 104857600 (100.0MB)CompressedClassSpaceSize = 106954752 (102.0MB)MaxMetaspaceSize = 115343360 (110.0MB)G1HeapRegionSize = 0 (0.0MB)...
查看MaxMetaspaceSize = 115343360 (110.0MB)已经生效了,这个时候也不会无限的消耗系统内存了,但报错了/(ㄒoㄒ)/~~:
Exception in thread "main" java.lang.OutOfMemoryError: Metaspaceat java.lang.ClassLoader.defineClass1(Native Method)at java.lang.ClassLoader.defineClass(ClassLoader.java:763)at java.lang.ClassLoader.defineClass(ClassLoader.java:642)at org.example.HelloWorld111.main(HelloWorld111.java:24)Process finished with exit code 1
你可能会说把MaxMetaspaceSize调大点不就好了,但是我要说,默认元空间大小是没有限制的,没有限制都不够用,都能把系统内存耗尽,你能给多大???所以,到这里依然不是终点,因为程序不能用了,还要继续排查,现在方向就很明确了,因为元空间主要存储类信息的,所以只需要查出来加载了哪些类就行了,可以通过增加参数-verbose:class来做到这点:
-Xms4g -Xmx4g -Xmn1g -Xss1024K -XX:MetaspaceSize=1000m -XX:MaxMetaspaceSize=1100m -verbose:class
运行:
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
[Loaded com.alibaba.fastjson.serializer.ASMSerializer_1_WlkCustomerDto from file:/C:/Users/yangzhendong01/.m2/repository/com/alibaba/fastjson/1.2.71/fastjson-1.2.71.jar]
可以看到fastjson生成了大量的类,而程序中确实是使用到了fastjson,用来完成json的某些转换工作:
public static String buildData(Object bean) {try {SerializeConfig CONFIG = new SerializeConfig();CONFIG.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;return jsonString = JSON.toJSONString(bean, CONFIG);} catch (Exception e) {return null;}
}
通过进一步定位,定位到是SerializeConfig默认会使用ASM创建一个代理类来完成相关的转换工作,而每次代码都是new一个SerializeConfig,所以每次都会生成一个新的代理类,也就导致了问题的发生,修改也很简单,将SerializeConfig设置为全局的静态变量,使用同一个就行了:
private static SerializeConfig CONFIG = new SerializeConfig();
public static String buildData(Object bean) {try {// SerializeConfig CONFIG = new SerializeConfig();CONFIG.propertyNamingStrategy = PropertyNamingStrategy.SnakeCase;return jsonString = JSON.toJSONString(bean, CONFIG);} catch (Exception e) {return null;}
}
以上的过程我也准备了一个模拟程序来供你测试:
package org.example;import org.objectweb.asm.ClassWriter;
import org.objectweb.asm.MethodVisitor;
import org.objectweb.asm.Opcodes;import javax.swing.plaf.synth.SynthTextAreaUI;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.List;public class HelloWorld111 extends ClassLoader {private static List<Class> list = new ArrayList<>();public static void main(String[] args) throws Exception {for (;;) {// 生成二进制字节码String suffix = System.currentTimeMillis() + "";byte[] bytes = generate(suffix);// 输出字节码
// outputClazz(bytes, suffix);// 加载AsmHelloWorldClass<?> clazz = new HelloWorld111().defineClass("com.dahuyou.asm.AsmHelloWorld" + suffix, bytes, 0, bytes.length);list.add(clazz);Thread.sleep(200);}}private static byte[] generate(String suffix) {ClassWriter classWriter = new ClassWriter(0);// 定义对象头;版本号、修饰符、全类名、签名、父类、实现的接口classWriter.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "com/dahuyou/asm/AsmHelloWorld" + suffix, null, "java/lang/Object", null);// 添加方法;修饰符、方法名、描述符、签名、异常MethodVisitor methodVisitor = classWriter.visitMethod(Opcodes.ACC_PUBLIC + Opcodes.ACC_STATIC, "main", "([Ljava/lang/String;)V", null, null);// 执行指令;获取静态属性methodVisitor.visitFieldInsn(Opcodes.GETSTATIC, "java/lang/System", "out", "Ljava/io/PrintStream;");// 加载常量 load constantmethodVisitor.visitLdcInsn("Hello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASMHello World ASM!");// 调用方法methodVisitor.visitMethodInsn(Opcodes.INVOKEVIRTUAL, "java/io/PrintStream", "println", "(Ljava/lang/String;)V", false);// 返回methodVisitor.visitInsn(Opcodes.RETURN);// 设置操作数栈的深度和局部变量的大小methodVisitor.visitMaxs(2, 1);// 方法结束methodVisitor.visitEnd();// 类完成classWriter.visitEnd();// 生成字节数组return classWriter.toByteArray();}private static void outputClazz(byte[] bytes) {// 输出类字节码FileOutputStream out = null;try {String pathName = HelloWorld111.class.getResource("/").getPath() + "AsmHelloWorld.class";out = new FileOutputStream(new File(pathName));
// System.out.println("ASM类输出路径:" + pathName);out.write(bytes);} catch (Exception e) {e.printStackTrace();} finally {if (null != out) try {out.close();} catch (IOException e) {e.printStackTrace();}}}}
对应的完整配置参数为-Xms4g -Xmx4g -Xmn1g -Xss1024K -XX:MetaspaceSize=64m -XX:MaxMetaspaceSize=128m -verbose:class,你可自行修改配置参数来模拟上述的整个排查过程,希望能够帮助到你。
写在后面
参考文章列表
6款工具助力分析JVM问题 。
深入浅出JVM实战调优 。
Group by隐式排序,一个优美的BUG 。
Java服务刚启动时,一小波接口超时排查全过程 。
一次完整的JVM堆外内存泄漏java故障排查记录 。











![[linux]软件安装](https://img-blog.csdnimg.cn/img_convert/1a66c72edeec7b671bdccdad6d12377a.png)






