1芝麻街与NLP模型
我們接下來要講的主題呢叫做Self-Supervised Learning,在講self-supervised learning之前呢,就不能不介紹一下芝麻街,為什麼呢因為不知道為什麼self-supervised learning的模型都是以芝麻街的人物命名。
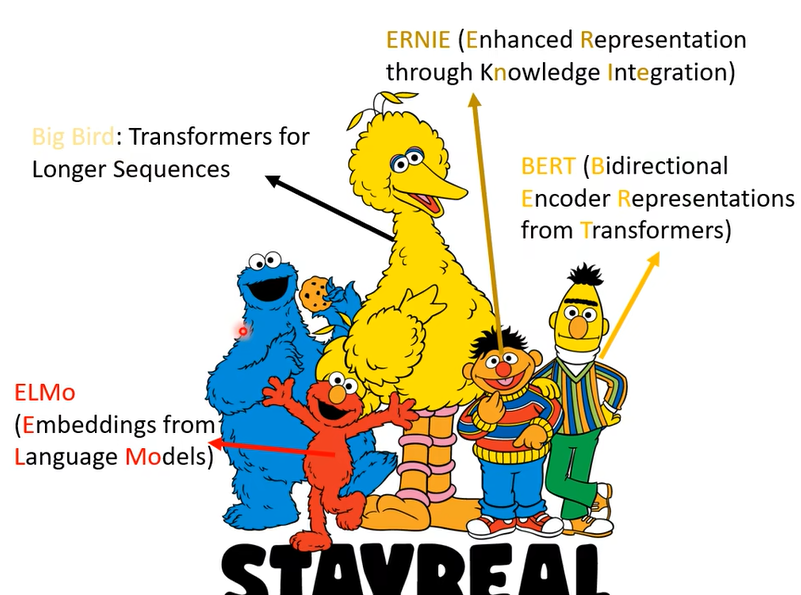
因為Bert是一個非常巨大的模型,有多大 它有340個million的參數, B E R T b a s e BERT_{base} BERTbase也有110M

但是其實你可能覺得Bert已經很大了
但是還有更多更巨大的模型

這個時代就像是被發動的地名一樣,有很多超巨大的巨人從地底湧出
最早的是ELMO,ELMO也有94個million,這邊用這些角色的身高來代表它的參數量,Bert大了一點 340個million,遠比你在作業裡面做的大了一千倍以上,但是它還不算是特別大的,GPT-2它有一千五百個million的參數

但就算是GPT-2它也不算是太大的,這個Megatron有8個billion的參數,GPT-2的8倍左右

後來又有T5,T5就是有一款福特汽車叫T5,雖然T5是Google做的跟車子也沒有什麼關係,那這邊就放一個福特汽車,T5有11個billion,但這也不算什麼,Turing NLG有17個billion,那這也不算什麼,GPT-3有Turing NLG的10倍那麼大,它有10倍那麼大,到底GPT-3有多大呢,如果我們把它具象化的話,它有這麼大

2BERT简介
那在等一下的課程裡面我們會講兩個東西,我們會講Bert跟GPT

首先解释自监督
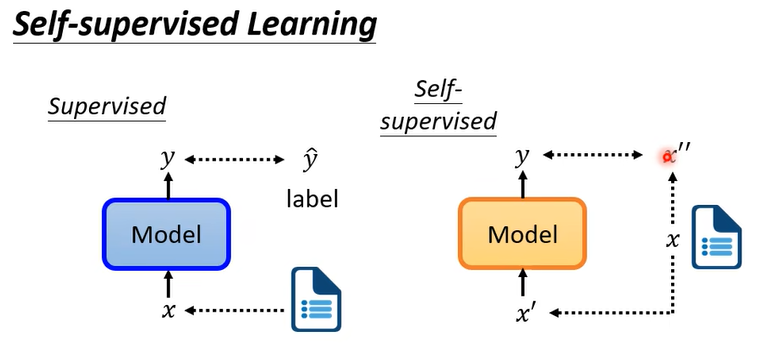
一大堆无标签的x,分为两部分, x ′ , x ′ ′ x',x'' x′,x′′。输入 x ′ x' x′ ,让输出的y与 x ′ ′ x'' x′′越接近越好。
bert其实就是transformer的encoder
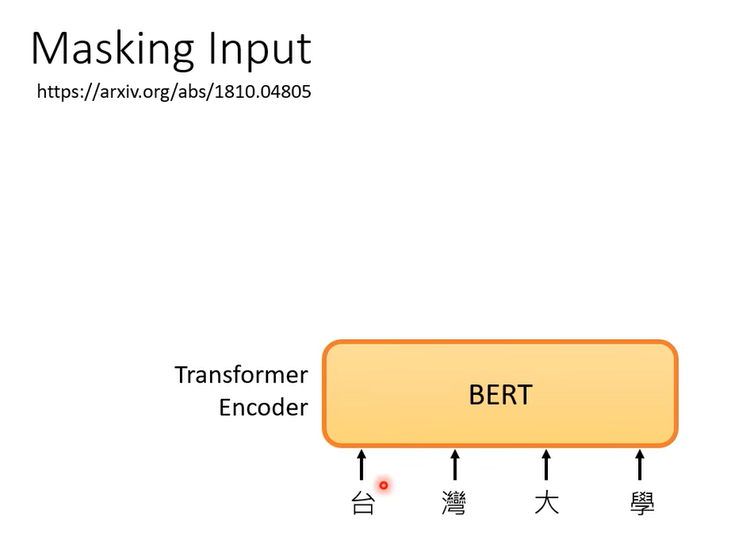
这里的输入是一个序列,不只可以是文字,可以是语音,甚至是图像。
随机遮盖一些输入的文字,比如输入100个token (token就是你在处理一段文字的时候的单位)token的大小是你自己决定的,处理中文的时候,token通常是一个方块字。
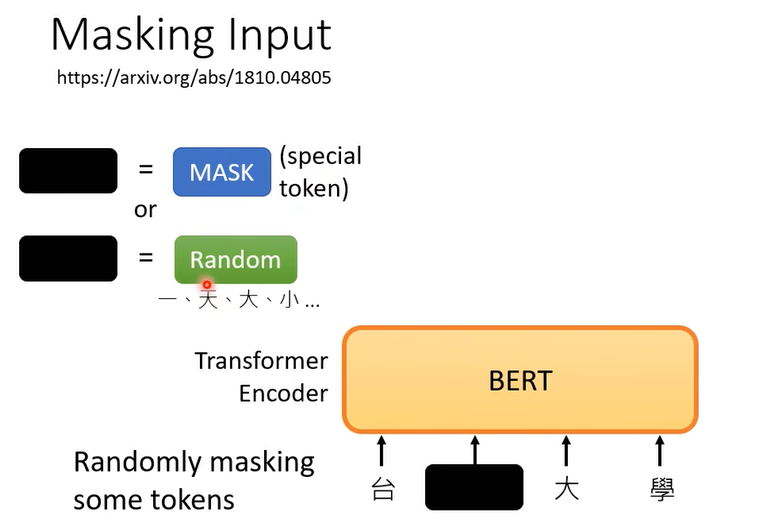
随机的mask就是,有一个特殊的token ,或者随机换成一个其他词

论文附录有给例子。
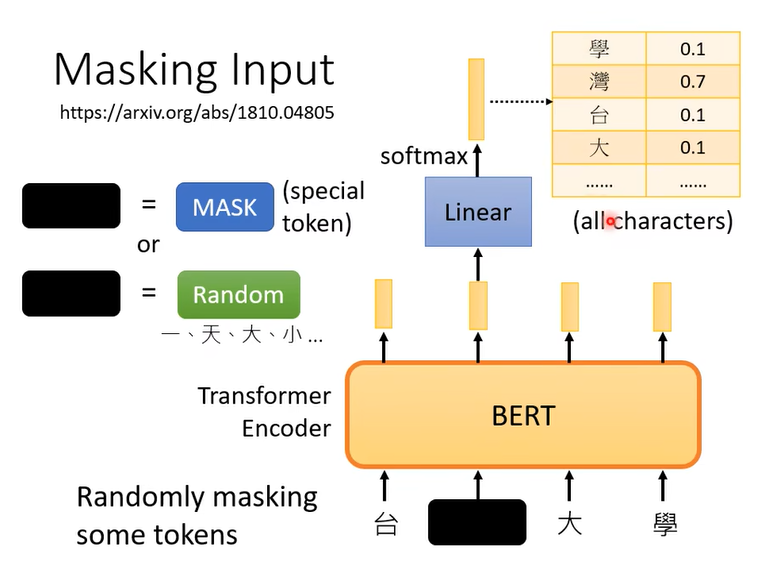
那我们希望遮住部分的输出湾的概率越大越好
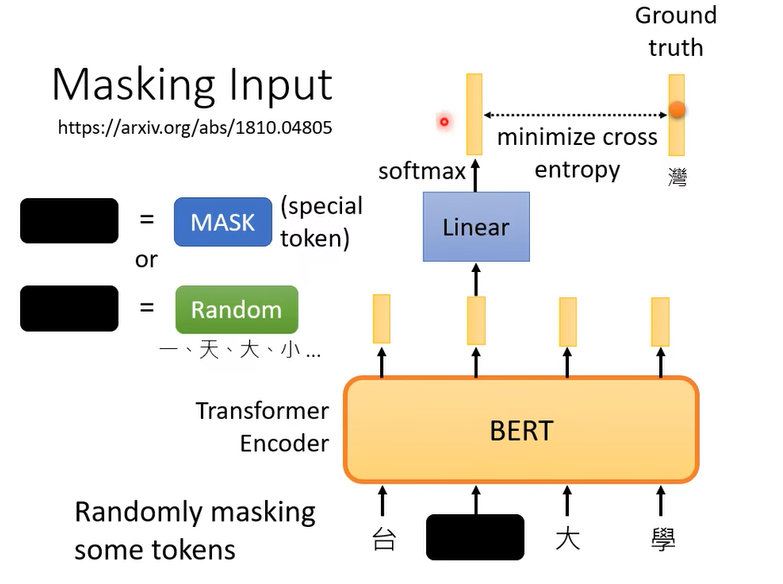
训练的时候,就最小化交叉熵。Bert训练同时还会做另一方法

从语料库sample两个句子,为了分割这两句子,会有一个特殊的符号[SEP],这样Bert才知道这是两个不同的句子。还会在整个sequence的最前面加一个特殊的符号[CLS]
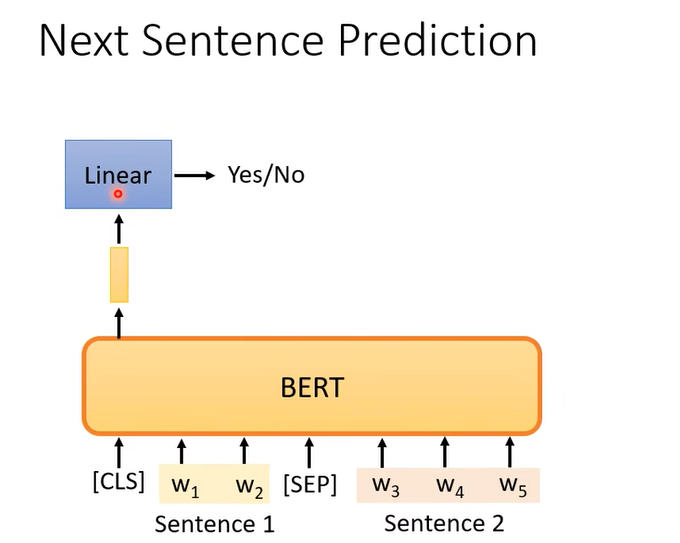
现在我们只看cls对应的输出,其他位置的输出不去管它,
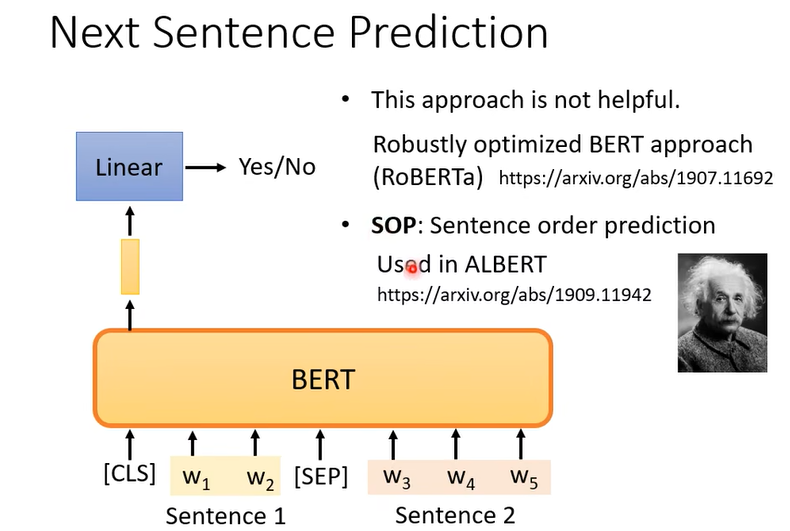
但是后面有人发文章说next sentence prediction并不是很有用。人们发现sentence order prediction比较有用,就是把文章里挨着的两个句子的前后顺序打乱,让model判断哪个在前哪个在后。
那这样训练的模型可以做完形填空有什么用呢,其实Bert的用处在于可以解决很多的下游任务,这些任务和完形填空没有太大的关系。
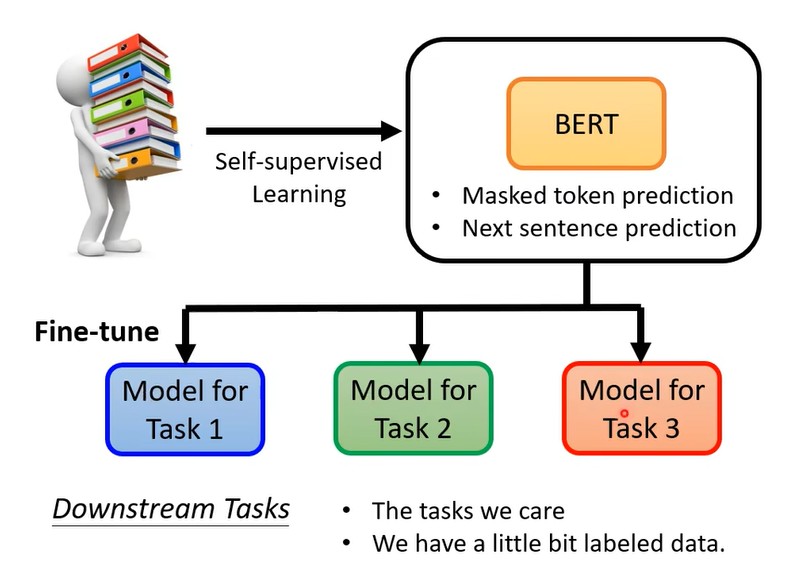
不过拿来做你感兴趣的下游任务时需要一些有标签的数据,对模型进行微调。
今天你要测试一个self supervised learning model的能力,通常会在多个任务上测试,看看在每个任务上的正确率是多少,然后取平均值。任务集里最知名的标杆就是glue

里面有九个任务,你会在九个任务上分别微调,得到九个模型,然后计算平均正确率
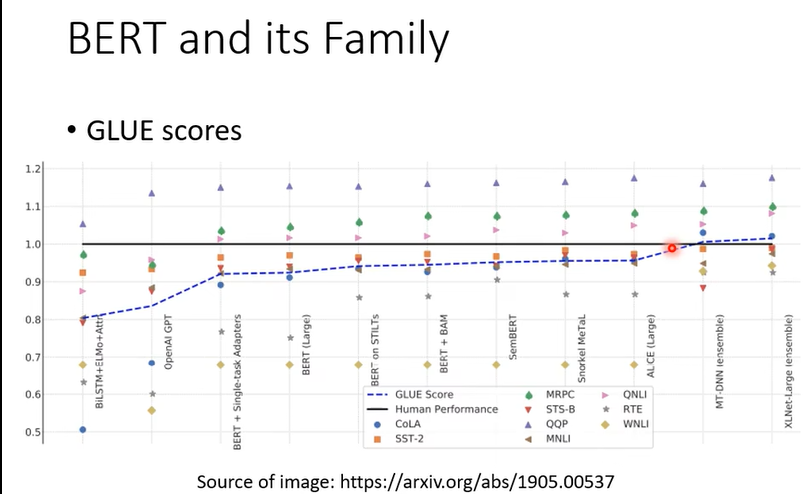
横轴是不同的模型,这些五颜六色的点就是不同的任务。黑线是人类在这个任务上的准确率,因为不同任务的评估标准不同,不能直接放在一起比较,所以是和人类做对比。
那具体要怎么使用Bert
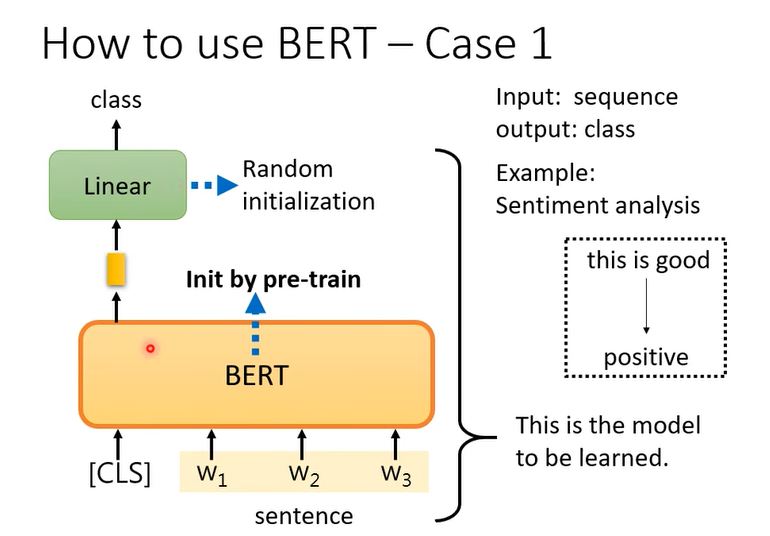
这里是需要有标签的下游任务数据集。为什么要用预训练的参数初始化呢,随机初始化和使用预训练的对比如下
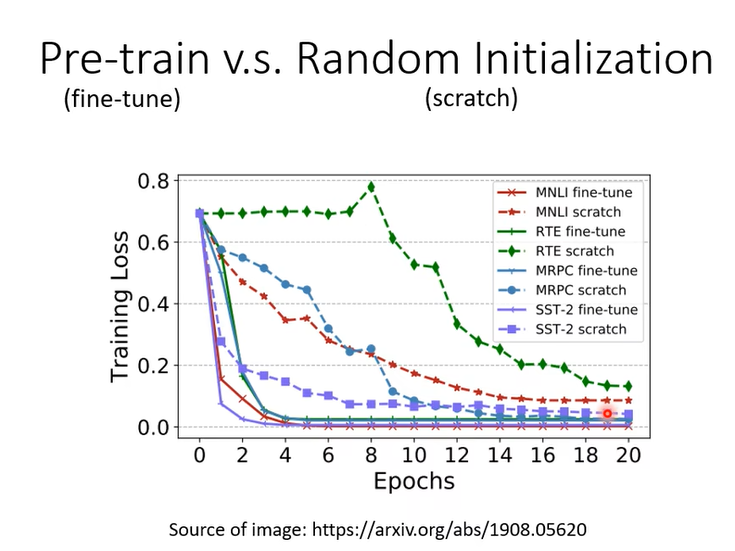
BERT的第二个例子是词性标注
第三个例子
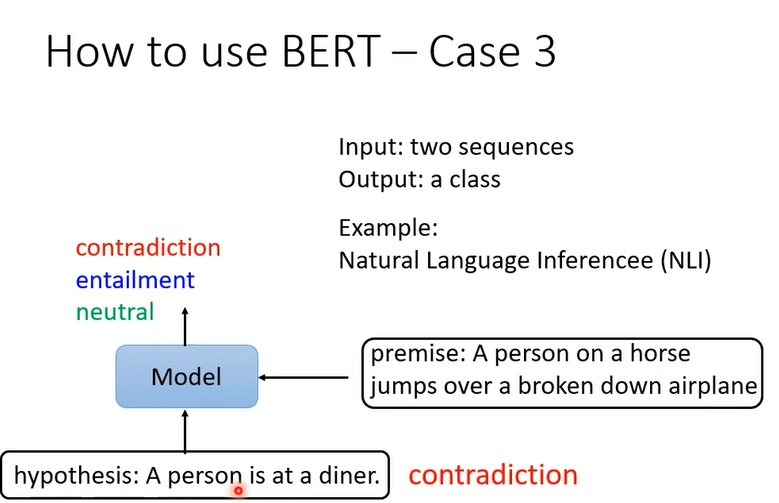
给出前提和推论,判断是不是可以从前提得到推论。 这样的任务可以用在,文章下的评论是反对还是支持,把文章和评论丢给模型。BERT怎么解这个问题呢
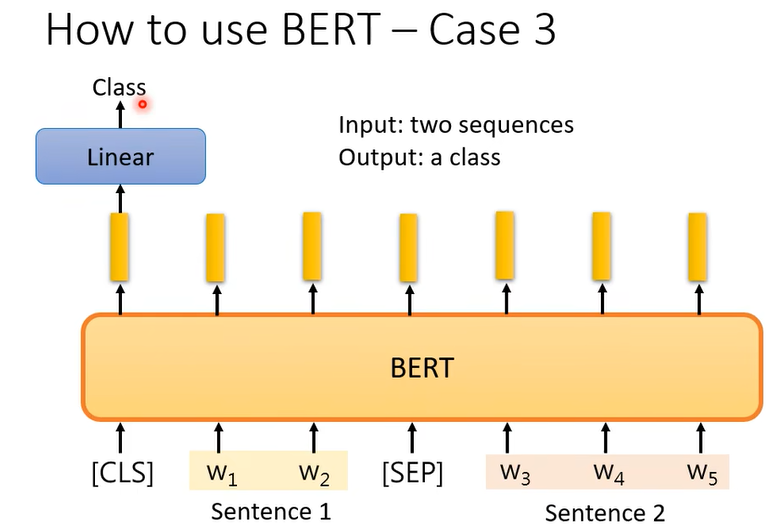
输入两个句子,判断他们的关系,是不是矛盾。这些例子中bert都是用预训练的参数初始化,然后linear是随机初始化,然后在有标签的数据集上进行训练

第四个例子是问答,但是这个问答是有限制的,答案一定在文章里

输入是两个序列,如果是中文,{d1,d2,d3…}每一个d就是一个中文字,{q1,q2…}每个q代表一个中文字。D和Q丢入模型,输出两个正整数,s,e ,从文字中截取s到e的部分就是答案。
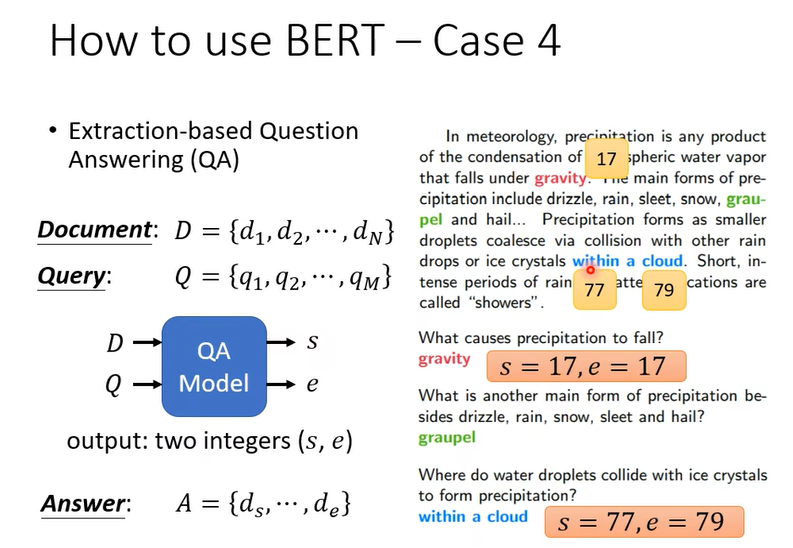
怎么训练呢
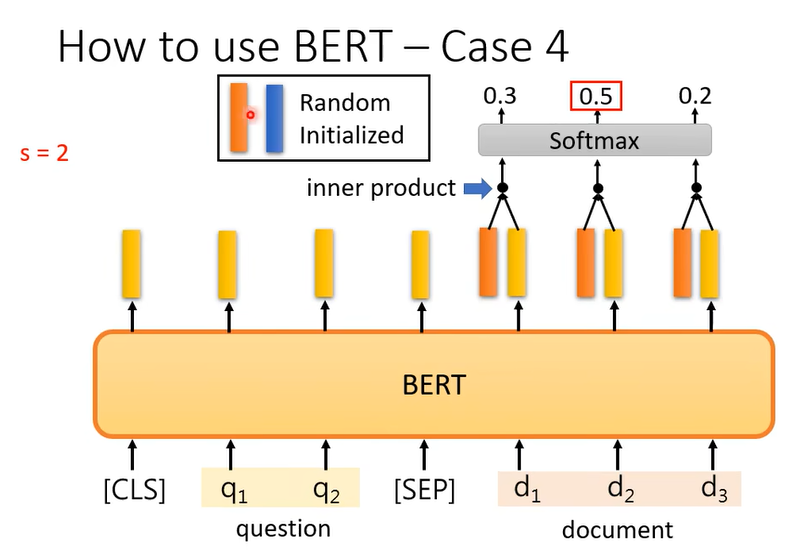
把橙色的部分和document的输出做inner product,接下来通过softmax得到三个值,这部分和self-attention很像,把橙色部分想成query,黄色部分想成key,那这就是做一个attention。
蓝色的部分也做一样的事情,蓝色的部分代表答案结束的位置
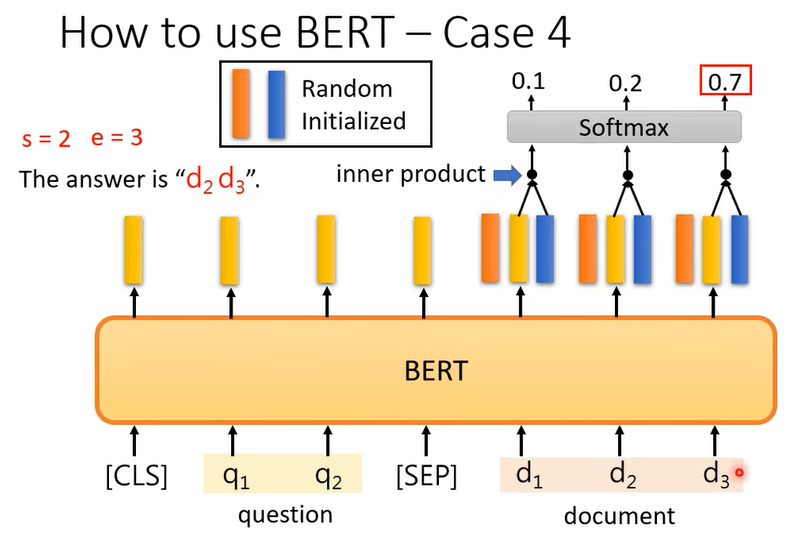
所以这个时候答案就d2到d3,
实际上由于硬件的限制(运算量)bert的输入长度会限制,训练的时候一篇文章往往很长,我们会把文章截成一小段一小段的,每次只拿一个段出来训练
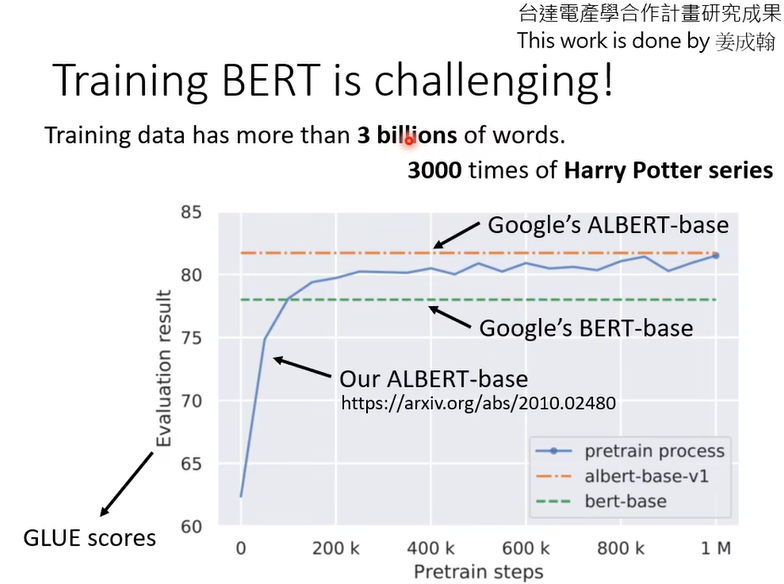
那么bert的厉害之处在哪里,自己也可以训练一个做完形填空的model,厉害之处就在你没法自己做,你自己训练不起来。我们实验室(李宏毅)试着训练bert看能不能得到和google一样的结果。3billion的资料看起来很多,但是是unlabel的,可以从网上爬,不是很难,难的是训练过程。横轴就是训练过程的参数update1000000次。用TPU跑了8天,你用conlab可能200天都不一定
那么google已经训练了bert,而且这些pre-training model都是公开的,为什么还要训练一个和谷歌结果差不多的bert,这里想要做的事情是建立bert胚胎学,因为bert的训练非常的花费计算资源,那有没有可能加速训练,想知道怎么训练的更快也许就要从观察训练过程开始,过去是没有人观察bert的训练过程,因为google的paper直接说这个bert在各个任务上都很好,但实际上在训练bert这个学填空题的过程中到底bert学到了什么,他什么时候会填动词,什么时候会填名词,什么时候会填代名词,没有人去研究过这件事。所以自己train一个bert就可以观察bert在什么时候学会填什么样的词汇,他填空的能力 是怎么增进的
结果可能和你想的不太一样。
再补充一个事情,前面讲的任务都没包括seq2seq的model,我们要解seq2seq的问题怎么办?BERT只有Encoder,有没有办法pre-traing seq2seq model的Decoder呢,可以的,
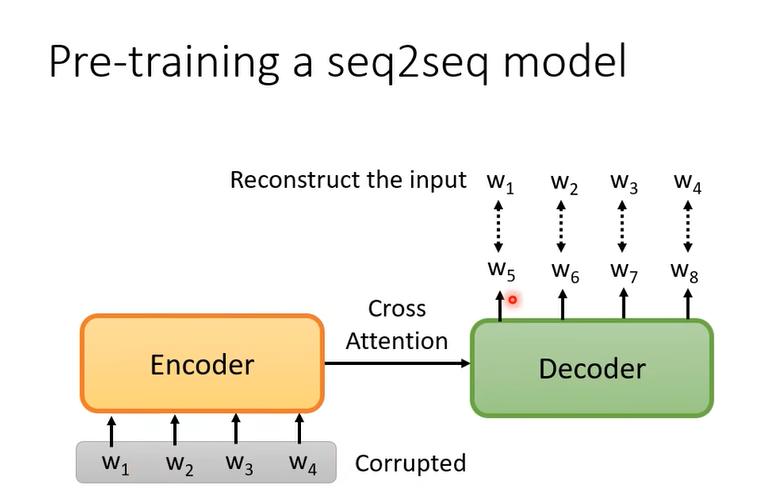
你有个transformer,输入是一串句子,输出是一串句子。
给encoder输入故意做一些扰动,把输入弄坏,Decoder输出的就是弄坏前的结果。encoder看到弄坏的结果,decoder要输出,还原弄还前的结果,train下去就是pre-train一个seq2seq的model。
怎么把输入弄坏,就有各种不同的方法
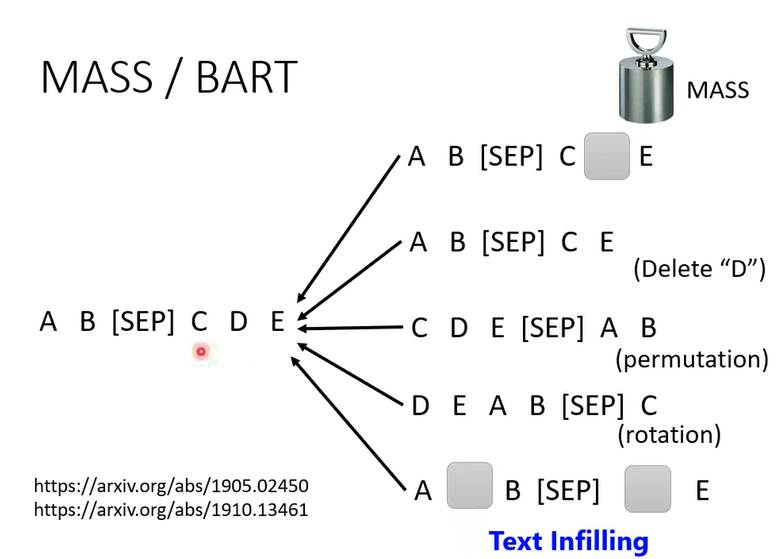
把一些地方mask,或者删掉一下词汇,把词汇顺序弄乱,词汇顺序旋转,或者即插入mask有删掉一些词汇
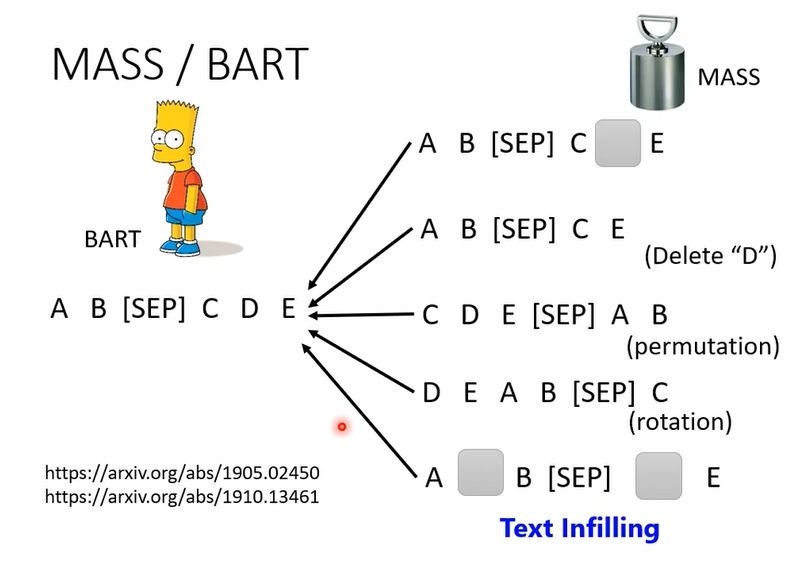
有一篇paper叫BART使用了所有方法
你可能会问,这么多种方法,哪种比较好,可能需要做一些实验尝试一下,google已经帮你做了
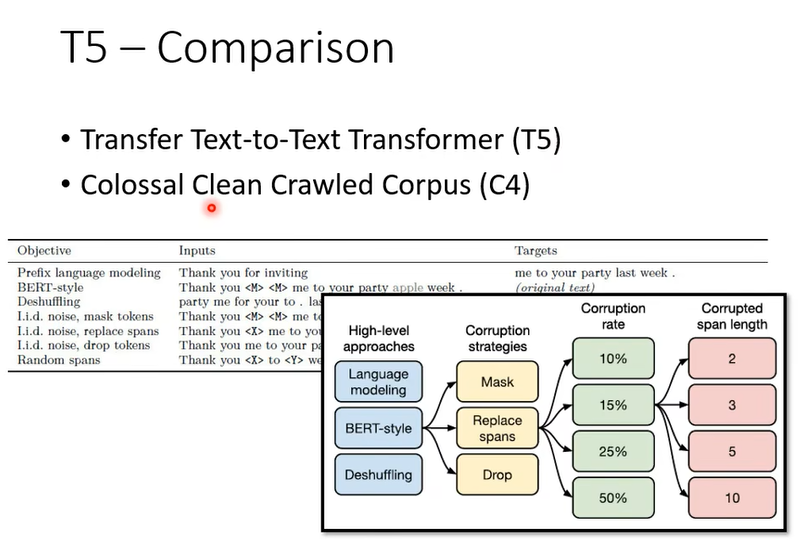
T5是在C4上训练的,C4数据集是公开的,但是有7T,你可能很难下载下来,下载下来也不知放在哪里,而且网站有提示前处理用一张GPU要花355天
3BERT的奇闻轶事
为什么BERT有用,先提供一个最常见的解释
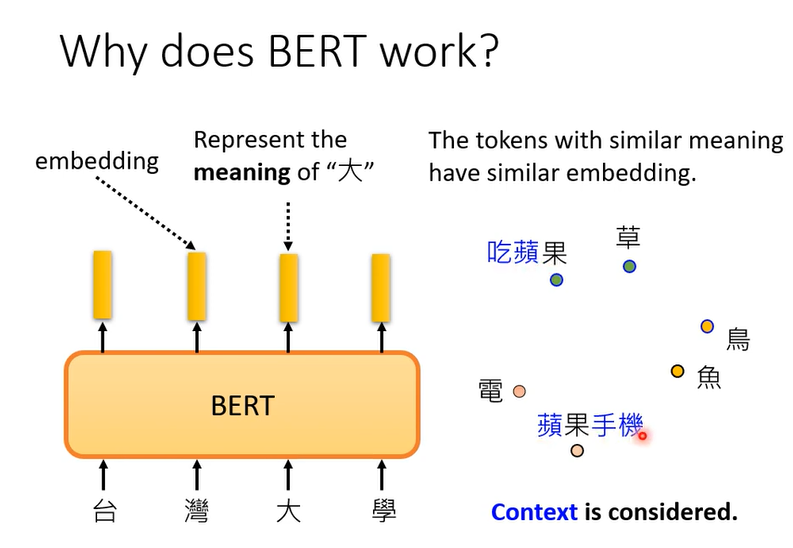
输出的embeding代表这个词的意思
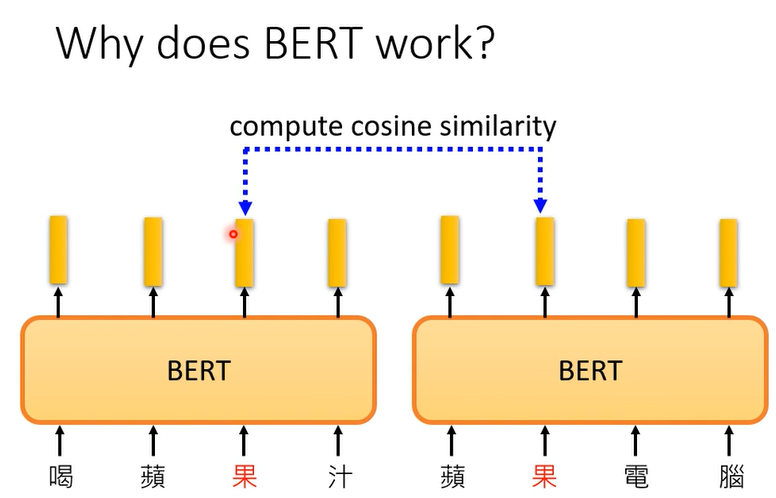
BERT考虑了上下文,计算它们的相似度
这边选了10个句子
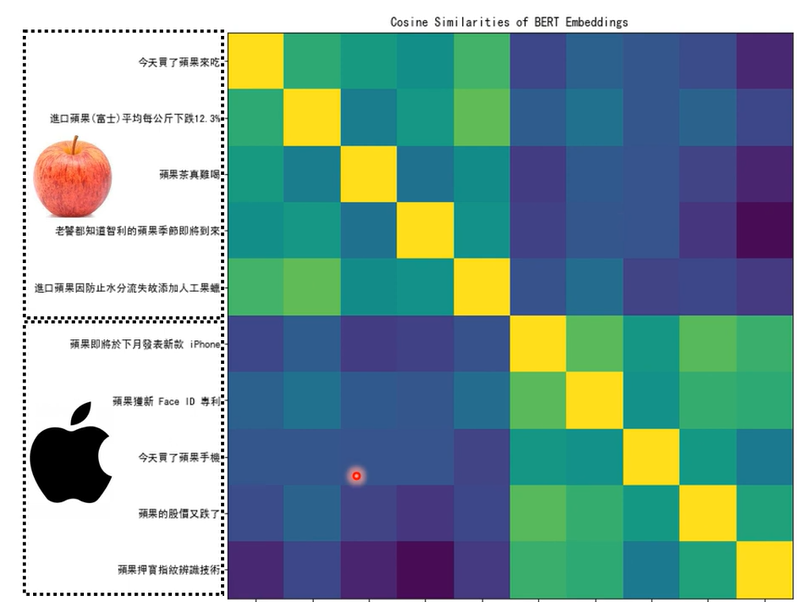
所以我们可以说,BERT在训练做填空的时候,学会了每个中文词的意思,所以可以在接下来的任务做的更好
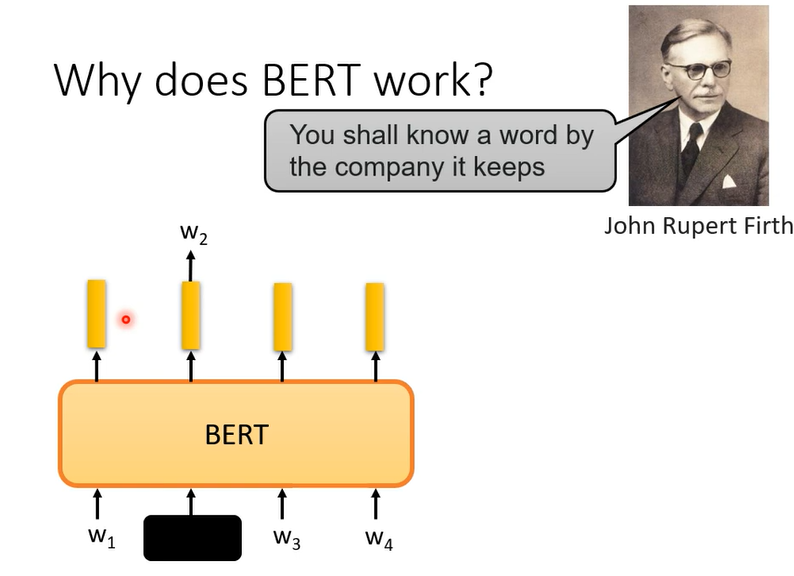
那BERT为什么会有这样的能力呢,为什么他输出的向量就代表那个词的意思。
基于一个语言学假设,一个词的意思要看常常和他一起出现的词汇,也就是上下文。苹果的果上下文常常是树,吃等等,而苹果手机的果常常跟的是专利,电。所以一个词汇的意思可以从他的上下文看出来。
而bert在做完形填空的时候也许学的就是从上下文抽取资讯
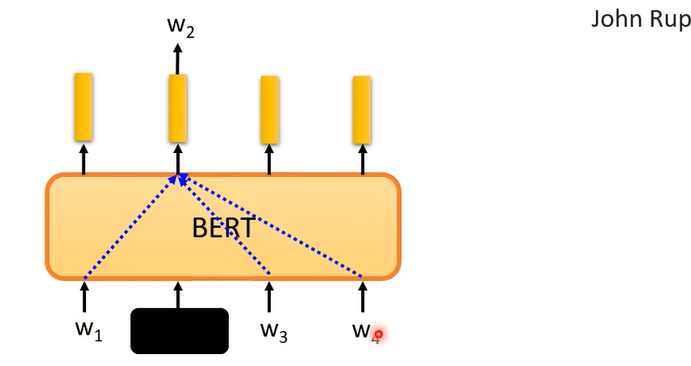
因为训练的时候只给w1,w3,w4预测w2,怎么预测w2,他就是看上下文。其实这样的想法在bert前就有了,word embedding的CBOW
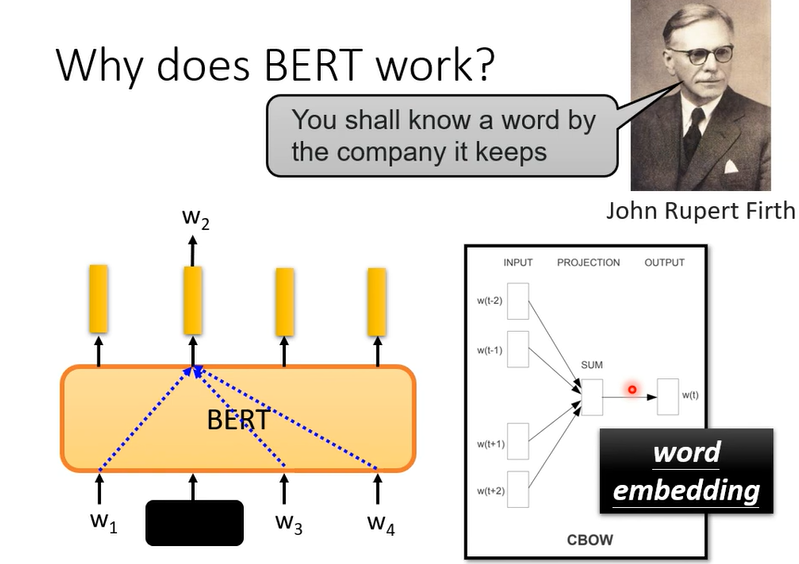
CBOW是个很简单的模型。
BERT其实相当于deep版的CBOW,BERT可以做到同一个词汇,根据不同的上下文,Embeding不一样
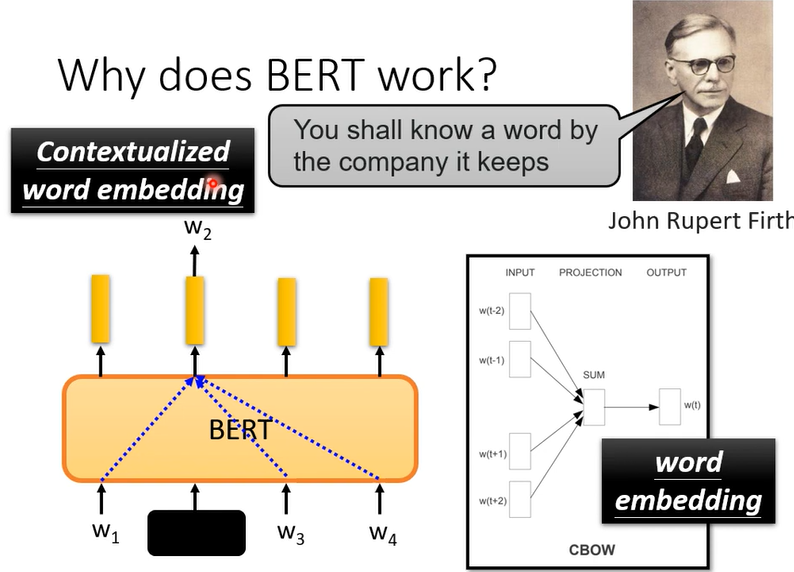
所以BERT抽出的这些向量就叫Contextualized word embedding
这是你最常见的BERT有效的解释,但是真的是这样吗
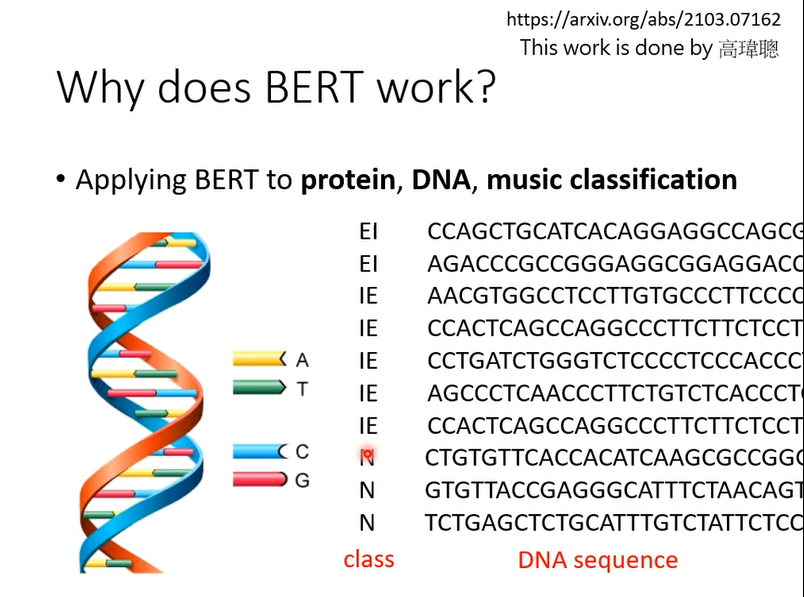
做个实验
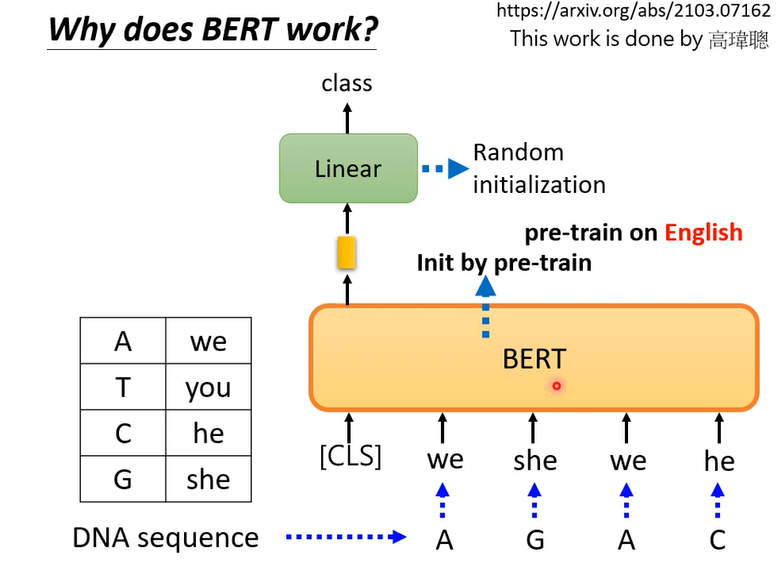
A T C G对应一个word,对应什么不重要,随便对应什么,然后训练,你可能觉得怪怪的,不知道这样有什么意思

但是你就这样去做,BERT竟然比不使用BERT(蓝色)要好,这样实验说明,BERT为什么要好还有很多需要研究的地方。
这里并不是否认BERT学到语义,从embeding来看,BERT确实学到了语义,知道哪些词汇比较像,这里想要表达的意思是你就算给他一些乱七八糟的句子,竟然也可以分类的不错,所以他的能力不完全来自于他看的懂文章这件事,可能有其他理由。比如说bert本身是一个初始化比较好的参数,不见得和语义有关,这种初始化好的参数就是适合拿来做大型模型的训练。是不是这样还尚待商榷。
之所以告诉你这个实验的结果只是想说,今天这些模型都是非常新的模型,他们为什么能够成功还有很大的研究空间

接下来要将多语言的BERT,你在训练的时候会拿各种各样的语言,中英法等拿去做完形填空
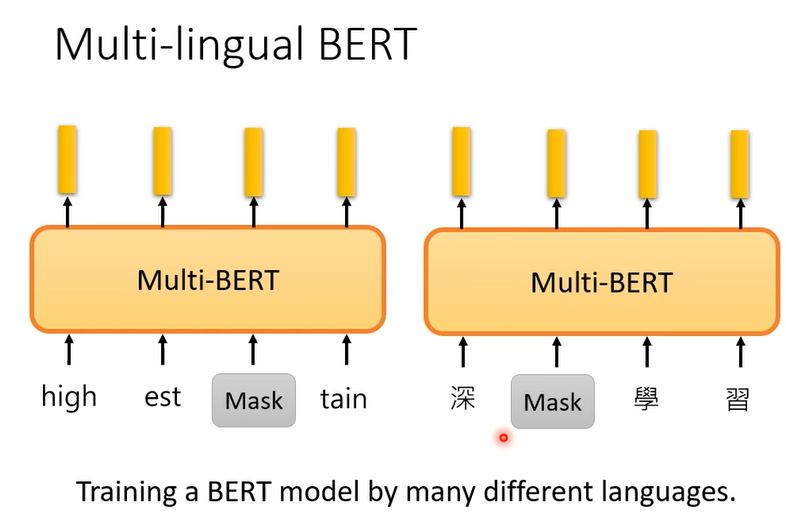
multi -lingual BERT的优点在于
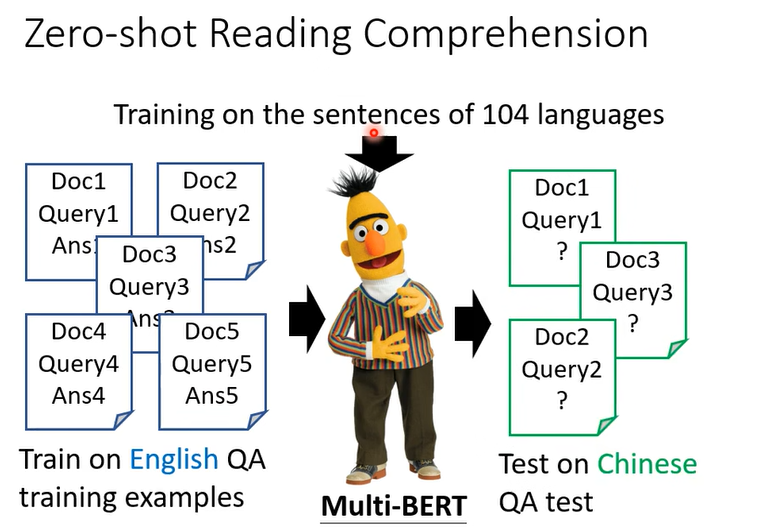
拿英文训练,自动就会学习中文的QA问题
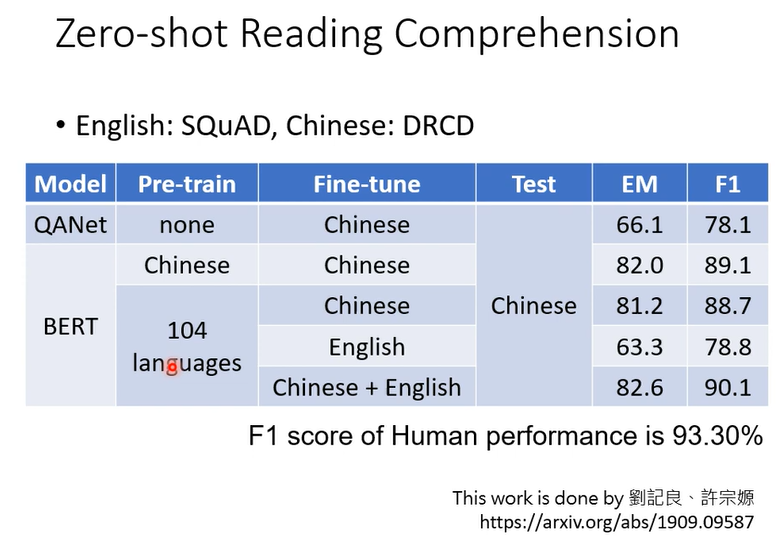
在104个语言预训练填空,在English资料训练问答,然后直接在中文测试问答,它竟然可以回答中文问题,虽然预训练的104种语言有中文,但是只训练了填空,在英文资料训练(fine-tune)问答,它没有见过中文问答,竟然可以直接回答中文问答。
为什么会这样,一种解释是,也许对multi -lingual BERT不同语音间没有什么差异,不管中文还是英文,最终这些词汇的embedding只有意思是一样的,都会很近
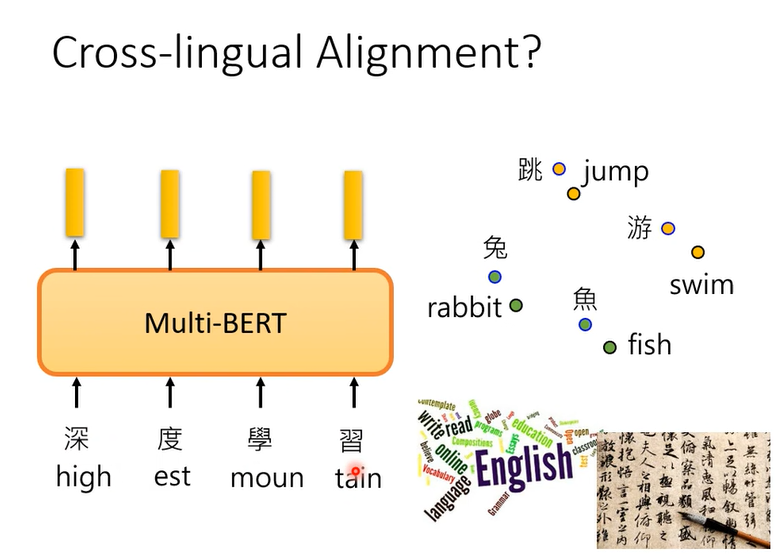
这不只是猜测,其实是有验证的,MRR越高说明同样意思不同语言的词汇的向量越接近
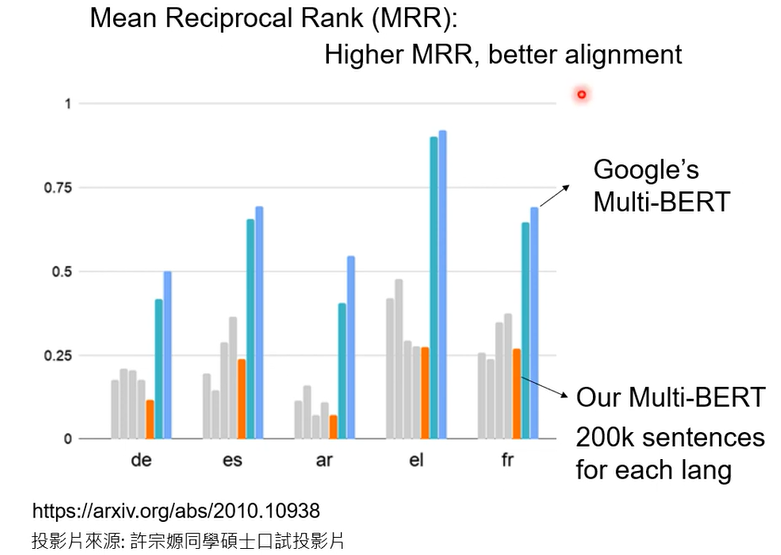
200k的时候效果没有达到Google效果,加大数据呢,1000k,how about 1000K?
不同资料量真的有用
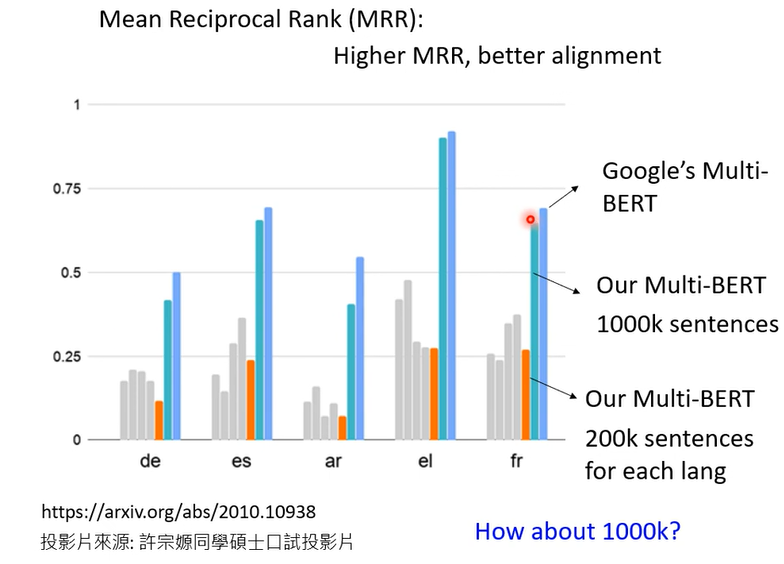
The amount of training data is critical for alignment
最后还有一个神奇的实验,你说bert可以把不同语言同样意思的符号,让他们的向量很近,但是训练multi - BERT时是给他英文做英文填空,给中文做中文填空,它不会混在一起啊
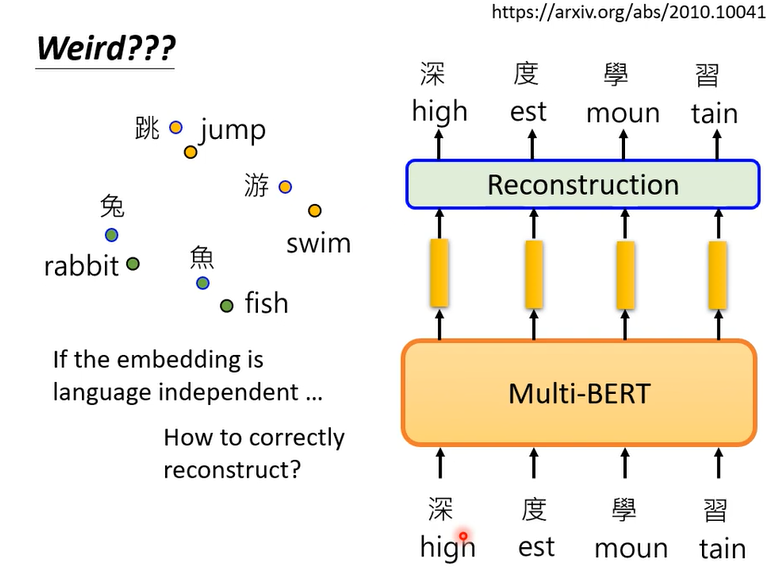
如果对他来说不同语言没有差别,给他英文的句子和填空,它可能填中文进去,但是它没有这样做,代表它知道语言的资讯对他来说同样不同,来自不同语言的那些符号终究还是不一样,它并没有完全抹掉语言的资讯。There must be language
information.
那我们来找一下语言的资讯到底在哪里,后来发现语言的资讯没有藏得很深
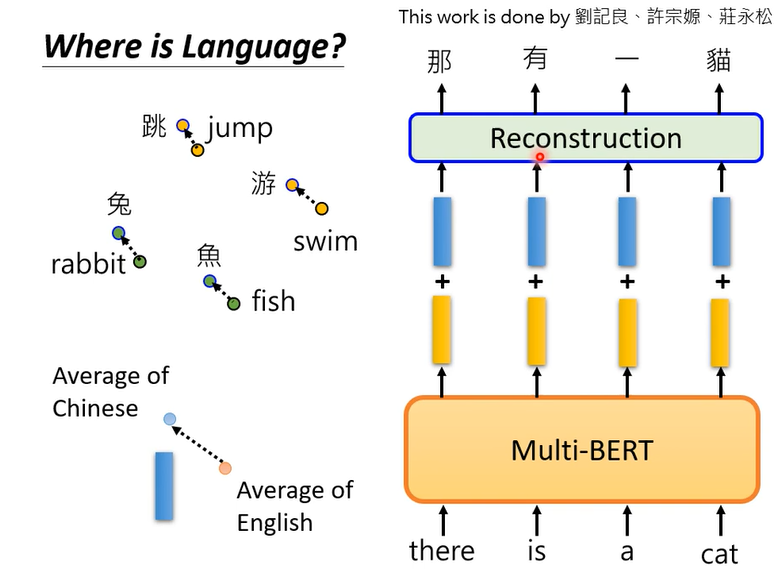
把所有英文的embedding,把所有英文词汇丢到multi-BERT里,把所有的embedding平均,把所有中文的embedding平均起来,两者相减就是中文和英文之间的差距。
你可以做的什么神奇的事情呢,你限制给multi-BERT一句英文,得到embedding,加上蓝色的向量(中英文之间的差距)这些向量就变成了中文。你再叫他去做填空题的时候就会填中文的答案了。
下面是真实的例子
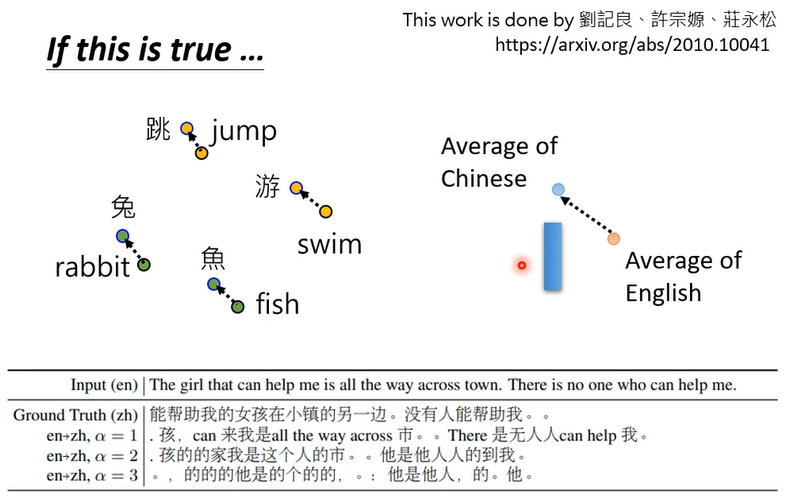
bert读进去的句子是The girl that can help me is all the way across town. There is no one who can help me.变成embedding后加上蓝色的向量,bert就会觉得它读到的是中文的句子。然后你叫他做填空题,把embedding变回句子以后得到的结果就是孩,can 来我是all the way across 市。。There 是无人人can help 我·
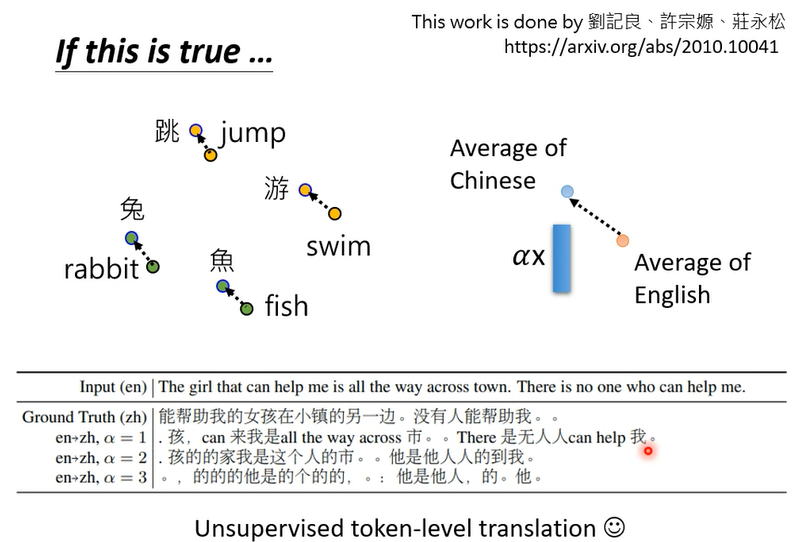
虽然表面上不同语言同样意思的词汇拉的很近,但是语言的资讯还是藏在multi-lingual BERT里面的
4GPT的野望

Bert是做填空,GPT做的是什么呢,GPT做的任务是预测接下来的token是什么
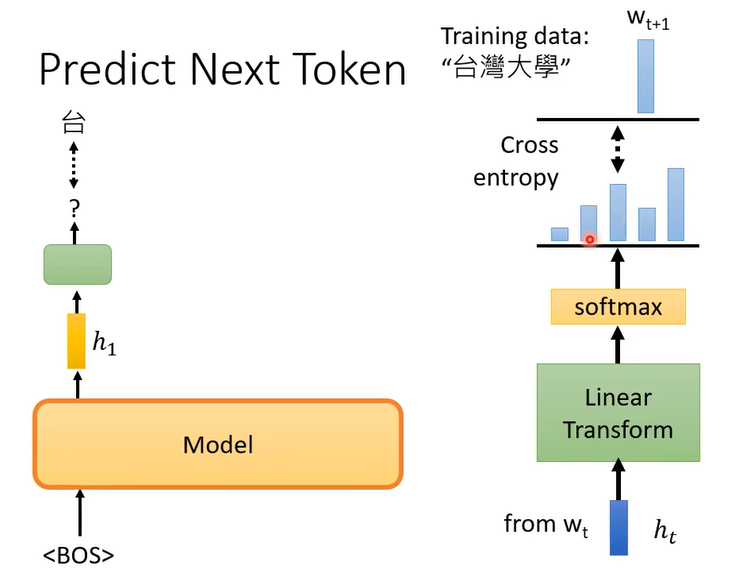
BOS即句子开始标记(Begin of Sentence)
h t h_t ht就是你的embedding
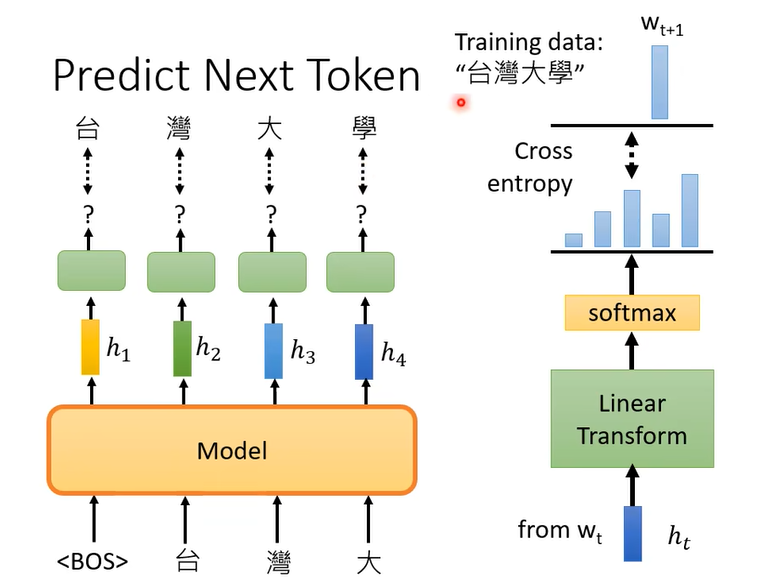
然后用成千上万个句子来训练这个模型。GPT的模型就像transformer的Decoder,不过拿掉了cross attention这部分
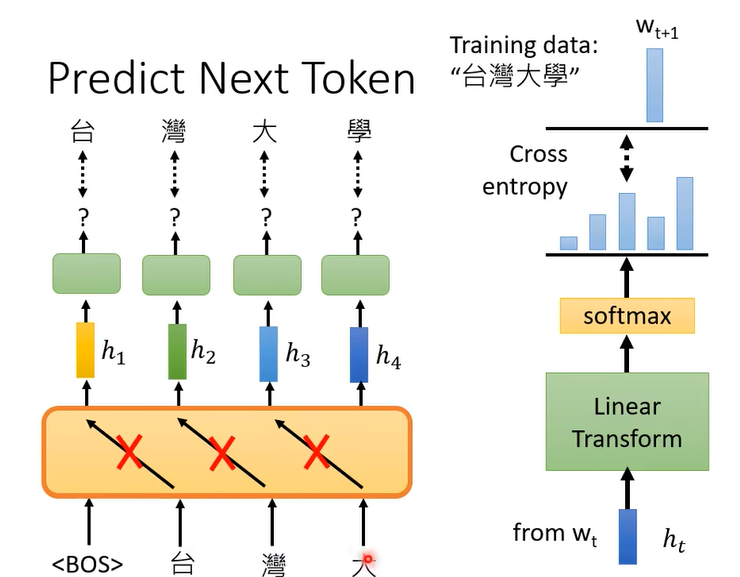
你做的也是mask的attention

因为GPT可以预测下一个词汇,所有他有生成的能力,你可以让他不断的预测下一个token,产生完整的文章。
GPT可以把话补全,怎么怎么使用在问答,或者其他语言处理问题上
GPT也可以和BERT一样,BERT是怎么做的,把BERT model拿过来,后面接一个简单的linear的classifier,那你就可以做很多事情,你也可以把GPT拿出來,接一個簡單的classifier我相信也是有效,但是在GPT的論文中它沒有這樣做

它有一個更狂的想法,為什麼會有更狂的想法呢,因為首先就是BERT那一招,BERT用過了嘛,所以總不能再用一樣的東西,這樣寫paper就沒有人覺得厲害了,然後再來就是GPT這個模型
也許真的太大了,大到連fine tune可能都有困難,你想想看我們在用BERT的時候,你要把BERT模型後面接一個linear classifier,然後BERT也是你的要train的model的一部分,所以它的參數也是要調的,所以在剛才助教公告的BERT相關的作業裡面你還是需要花一點時間來training,雖然助教說你大概20分鐘就可以train完了,因為你並不是要train一個完整的BERT的模型,BERT的模型在之前在做這個填空題的時候已經訓練得差不多了,你只需要微調它就好了。
但是微調還是要花時間的,也許GPT實在是太過巨大,巨大到要微調它,要train一個η可能都有困難,所以GPT系列有一個更狂的使用方式。

這個更狂的使用方式和人類更接近,你想想看假設你去考,譬如說托福的聽力測驗,你是怎麼去考托福的聽力測驗的呢,這個托福聽力測驗的敘述是長什麼樣子的呢,首先你會看到一個題目的說明告訴你說現在要考選擇題,請從ABCD四個選項裡面選出正確的答案等等,然後給你一個範例告訴你說這是題目然後正確的答案是多少,然後你看到新的問題期待你就可以舉一反三開始作答,GPT系列要做的事情就是這個模型能不能夠做一樣的事情呢。
舉例來說假設要GPT這個模型做翻譯,你就先打Translate English to French,就先給它這個句子,這個句子代表問題的描述,然後給它幾個範例,跟它說sea otter然後=>後面就應該長這個樣子,或者是這個什麼plush girafe,plush girafe後面就應該長這個樣子等等,然後接下來你問它說cheese=>叫它把後面的補完,希望它就可以產生翻譯的結果

不知道大家能不能夠了解這一個想法是多麼地狂,在training的時候GPT並沒有教它做翻譯這件事,它唯一學到的就是給一段文字的前半段把後半段補完,
就像我們剛才給大家示範的例子一樣,現在我們直接給它前半段的文字就長這個樣子,告訴它說你要做翻譯了,給你幾個例子告訴你說翻譯是怎麼回事,接下來給它cheese這個英文單字後面能不能就直接接出法文的翻譯結果呢,這個在GPT的文獻裡面叫做Few-shot Learning,但是它跟一般的Few-shot Learning又不一樣,所謂Few Shot的意思是說確實只給了它一點例子所以叫做Few Shot,但是它不是一般的learning,這裡面完全沒有什麼gradient descent ,training的時候就是要跑gradient descent嘛,這邊完全沒有gradient descent,完全沒有要去調GPT那個模型參數的意思。
所以在GPT的文獻裡面把這種訓練給了一個特殊的名字,它們叫做In-context Learning,代表說它不是一種一般的learning,它連gradient descent都沒有做

當然你也可以給GPT更大的挑戰,我們在考托福聽力測驗的時候都只給一個例子而已,那GPT可不可以只看一個例子就知道它要做翻譯這件事,這個叫One-shot Learning,還有更狂的是Zero-shot Learning,直接給它一個敘述說我們現在要做翻譯了,GPT能不能夠自己就看得懂,就自動知道說要來做翻譯這件事情呢,那如果能夠做到的話那真的就非常地驚人了
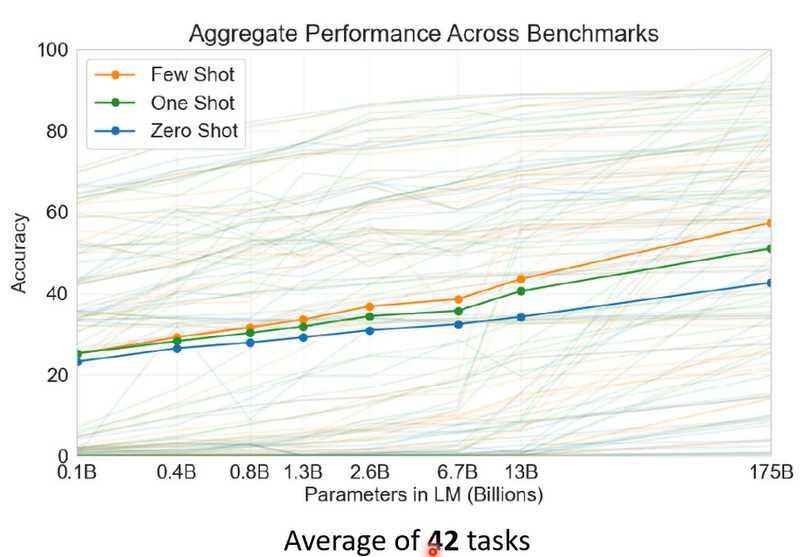
那GPT系列到底有沒有達成這個目標呢,這個是一個見仁見智的問題啦,它不是完全不可能答對,但是正確率有點低,相較於你可以微調模型正確率是有點低的,那細節你就再看看GPT那篇文章,第三代的GPT它測試了42個任務,這個縱軸是正確率,這些實線 這三條實線是42個任務的平均正確率,那這邊包括了Few Shot One Shot跟Zero Shot。
從20幾%的 平均正確率一直做到50幾%的平均正確率,那至於50幾%的平均正確率算是有做起來 還是沒有做起來,那這個就是見仁見智的問題啦,目前看起來狀況是有些任務它還真的學會了,舉例來說2這個加減法你給它一個數字加另外一個數字它真的可以得到正確的兩個數字加起來的結果,但是有些任務它可能怎麼學都學不會,譬如說一些跟邏輯推理有關的任務它的結果就非常非常地慘,好 那有關GPT3的細節這個就留給大家再自己研究

剛才舉的例子到目前為止我們舉的例子都是只有跟文字有關,但是你不要誤會說這種self-supervised learning的概念只能用在文字上,在語音 ,在CV,CV就是computer vision也就是影像,在語音跟影像的應用上也都可以用。
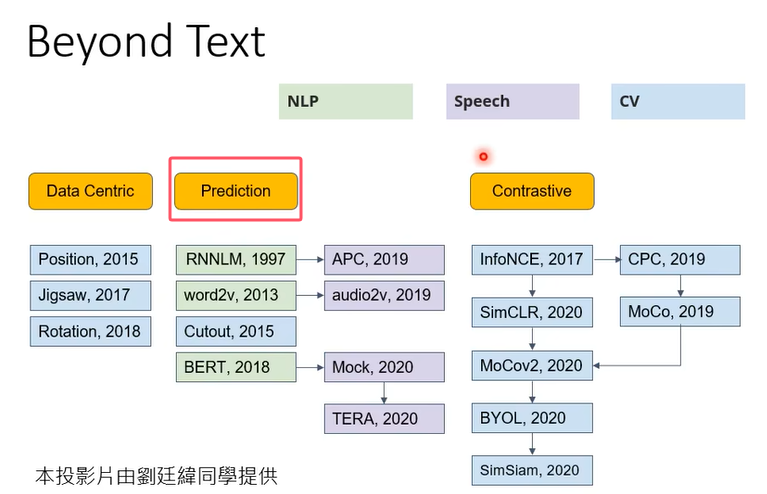
那其實今天self-supervised learning的技術非常非常地多,我們講的BERT跟GPT系列它只是三個類型的的其中一種,它們是屬於prediction那一類,
那接下來的課程你可能會覺得有點流水帳,就是我們每一個主題呢就是告訴你說這個主題裡面有什麼, 但是細節這個更多的知識就留給大家自己來做更進一步的研究
所以這些投影片只是要告訴你說在self-supervised learning這個部分,我們講的只是整個領域的其中一小塊,那還有更多的內容是等待大家去探索的
那有關影像的部分呢,我們就真的不會細講,我這邊就是放兩頁投影片帶過去,告訴你說有一招非常有名的叫做SimCLR,它的概念也不難我相信你自己讀論文應該也有辦法看懂它
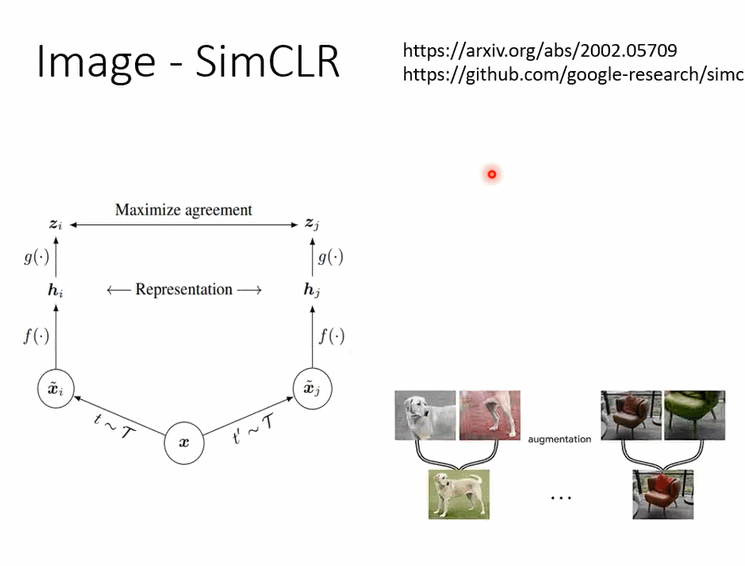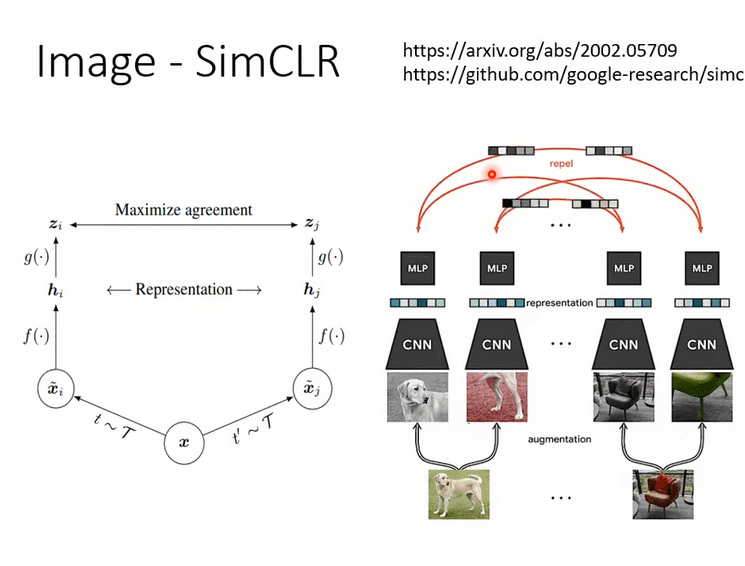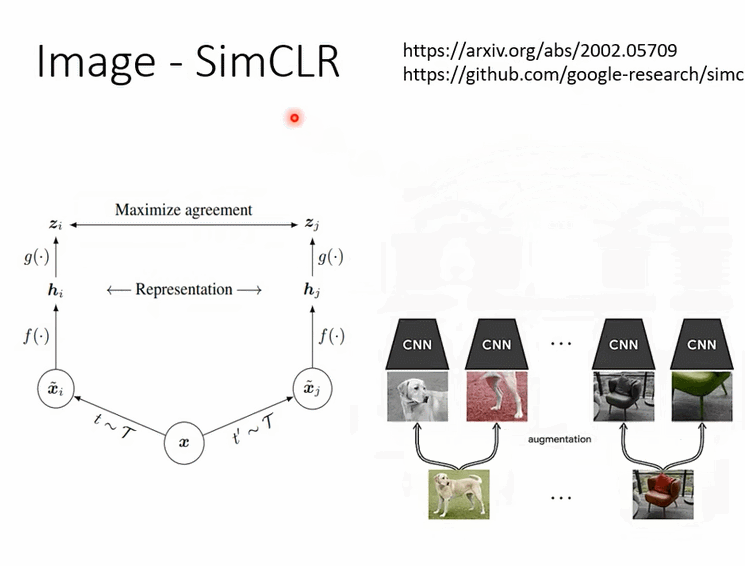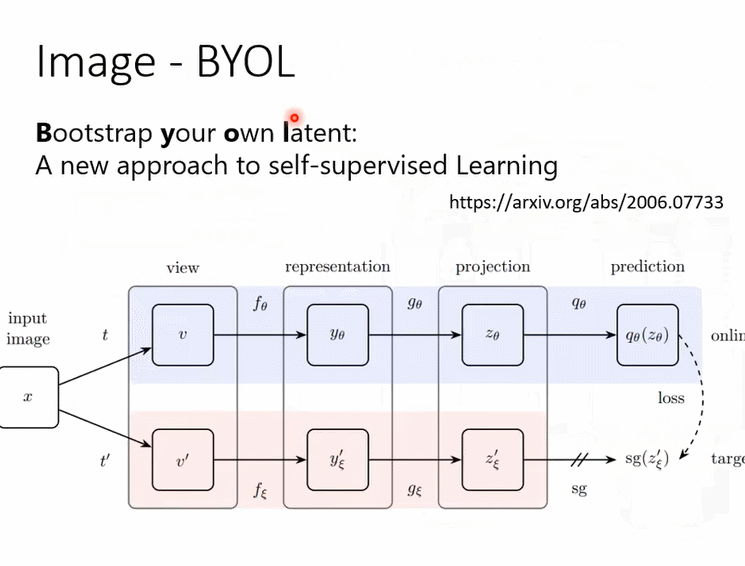
那還有很奇怪的叫做BYOL,BYOL這個東西呢我們是不太可能在上課講它,為什麼呢,因為根本不知道它為什麼會work
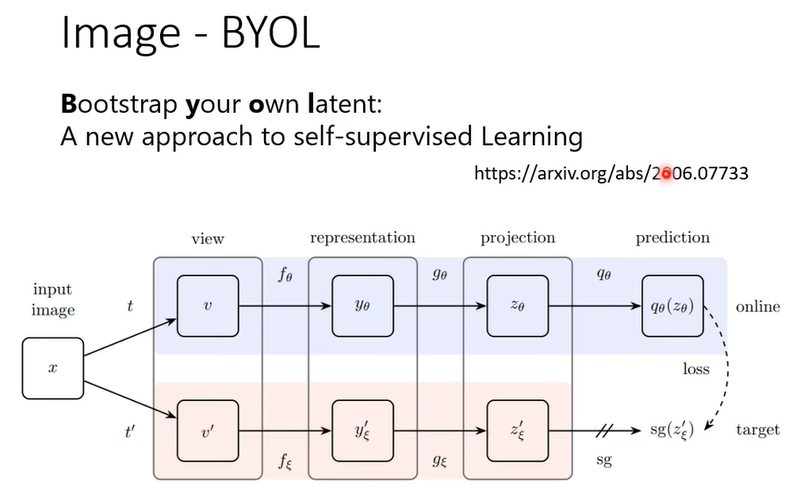
假設它不是已經發表的文章,然後學生來跟我提這個想法我一定就是我一定不會讓他做,這不可能會work的,這是個不可能會實現的想法,不可能會成功的,這個想法感覺有一個巨大的瑕疵,但不知道為什麼它是work的,而且還曾經一度得到state of the art的結果,deep learning就是這麼神奇
所以這個呢我們也就不細講,就跳過去好, 那在語音的部分你也完全可以使用self-supervised learning的概念
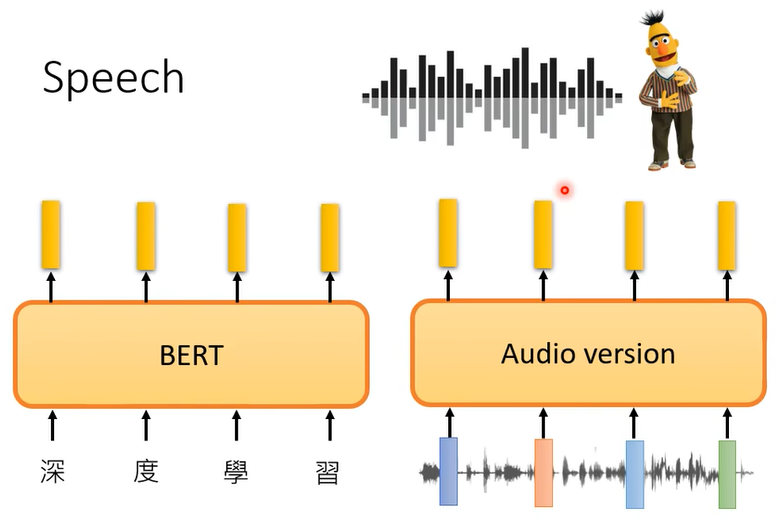
你完全可以試著訓練語音版的BERT,那怎麼訓練語音版的BERT呢,你就看看文字版的BERT是怎麼訓練的,譬如說做填空題,語音也可以做填空題,就把一段聲音訊號蓋起來,叫機器去猜蓋起來的部分是什麼嘛,語音也可以預測接下來會出現的內容
所以你也可以做語音版的GPT,不管是語音版的BERT,語音版的GPT,其實都已經有很多相關的研究成果了

不過其實在語音上相較於文字處理的領域還是有一些比較缺乏的東西,那我認為現在很缺乏的一個東西就是像GLUE這樣子的benchmark corpus,在自然語言處理的領域在文字上有GLUE這個corpus,這個基準的資料庫叫做GLUE,它裡面有九個NLP的任務。今天你要知道BERT做得好不好就讓它去跑那九個任務,在去平均,那代表這個self-supervised learning模型的好壞,但在語音上 到目前為止還沒有類似的基準的資料庫
所以我們實驗室就跟其他的研究團隊共同開發了一個語音版的GLUE,我們叫做SUPERB它是Speech processing Universal PERformance Benchmark的縮寫,你知道今天你做什麼模型都一定要硬湊梗才行啦,所以這邊也是要硬湊一個梗把它叫做SUPERB
在這個基準語料庫裡面包含了十個不同的任務,那語音其實有非常多不同的面向,很多人講到語音相關的技術都只知道語音辨識,把聲音轉成文字,但這並不是語音技術的全貌
語音其實包含了非常豐富的資訊,它除了有內容的資訊,就是你說了什麼,還有其他的資訊,舉例來說這句話是誰說的,舉例這個人說這句話的時候他的語氣是什麼樣,還有這句話背後它到底有什麼樣的語意。
所以我們準備了十個不同的任務這個任務包含了語音不同的面向,包括去檢測一個模型它能夠識別內容的能力,識別誰在說話的能力,識別他是怎麼說的能力,甚至是識別這句話背後語意的能力,從全方位來檢測一個self-supervised learning的模型它在理解人類語言上的能力。
而且我們還有一個Toolkit,這個Toolkit裡面就包含了各式各樣的self-supervised learning的模型。
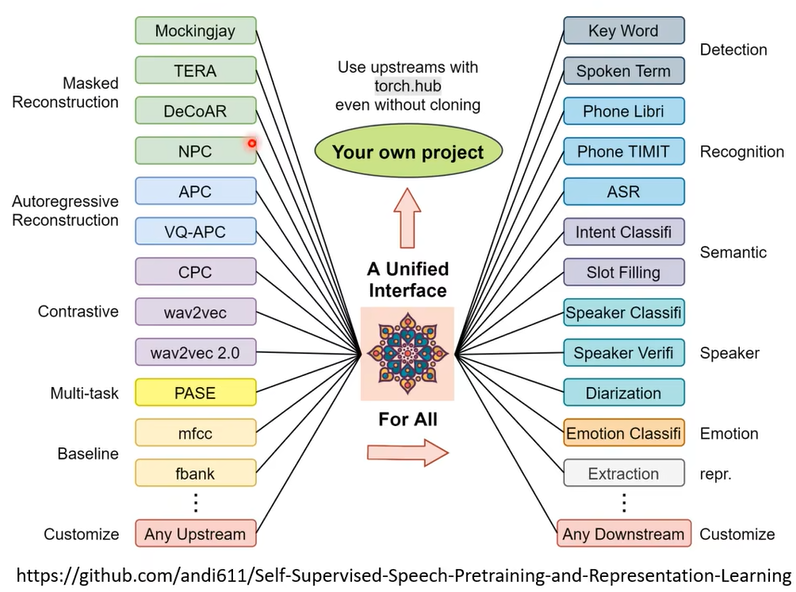
還有這些
self-supervised learning的模型它可以做的各式各樣語音的下游的任務,然後把連結放在這邊給大家參考
講這些只是想告訴大家說self-supervised learning的技術不是只能被用在文字上,在這個影像上 在語音上都仍然有非常大的空間可以使用。