1. 背景分析
分词是将输入和输出文本拆分成更小单位的过程,使得大模型能够处理。token可以是单词、字符、子词或符号,取决于模型的类型和大小。分词可以帮助模型处理不同的语言、词汇和格式,并降低计算和内存成本。分词还可以通过影响token的含义和上下文,影响生成文本的质量和多样性。
我们在前述文章《BPE原理及代码示例》、《WordPiece原理及代码示例》、《Unigram原理及代码示例》三篇文章讨论了在预训练模型中最常用的三种tokenizer算法:BPE、WordPiece、Unigram。
对这几类技术再做下简述,详细的可以点击链接看我们的文章:
BPE(字节对编码)
BPE的核心概念是从字母开始,反复合并频率最高且相邻的两个token,直到达到目标词数。
BBPE
BBPE的基本思想是将BPE从字符级别扩展到字节(Byte)级别。BPE在处理unicode编码时可能会导致基础字符集过大,而BBPE将每个字节视为一个“字符”,不论实际字符集用多少字节表示。这样,基础字符集的大小就固定为256(2^8),从而实现跨语言共享词表,并显著缩减词表大小。然而,对于像中文这样的语言,文本序列长度会显著增加,这可能使得BBPE模型的性能优于BPE模型,但其序列长度较长也会导致训练和推理时间增加。BBPE的实现与BPE类似,主要差别在于基础词表使用256的字节集。
WordPiece
WordPiece算法可视为BPE的变种。不同之处在于,WordPiece通过概率生成新的subword,而不是简单地选择频率最高的字节对。WordPiece每次从词表中选出两个子词合并成一个新子词,但选择的是能最大化语言模型概率的相邻子词。
Unigram
Unigram与BPE和WordPiece在本质上有明显区别。前两者从小词表开始,逐步增加到设定的词汇量,而Unigram则先初始化一个大词表,通过语言模型评估逐步减少词表,直到达到目标词汇量。
2. 分词粒度的讨论
技术有这么多,那该如何选择?首先我们来看下不同粒度的token有哪些影响?
2.1 针对小的token的分析
优势:
1.较小的token使得模型能够生成和理解更广泛的单词,包括通过组合较小的部分来处理从未见过的单词。
2.由于token较小,词汇大小通常较小,从而在某些方面节省内存和计算资源。
3.较小的token一般也更适合处理多种语言或代码,尤其是当这些语言具有不同的句法或语法结构时。
4.较小的token可能更好地处理拼写错误。
缺点:
1.较小的token意味着给定文本会被拆分成更多的词元,从而增加处理文本的计算成本。
2.另外由于固定的最大token限制,使用较小的token可能导致模型能够考虑的实际内容的“上下文”减少。
3.较小的token可能导致表达存在一定的模糊度,使模型在没有足够上下文的情况下更难理解token序列的含义。
2.2 针对大的token的分析
优点:
1.较大的token减少表示文本所需的token数量,从而在计算上提高了处理效率。
2.在固定的最大token数限制下,较大的token允许模型考虑更长的文本,从而可能提高理解和生成能力。
3.较大的token可能直接捕捉到更多细致的含义,减少因将单词拆分成更小部分而产生的模糊性。
缺点:
1.较大的token通常需要更大的词汇来捕捉相同范围的文本,这可能会带来占用大量内存的现象。
2.较大的token可能限制模型对未见或稀有单词的泛化能力,因为整个token必须与模型的词汇中的某个内容匹配。
3.较大的token可能在处理复杂形态或句法的语言时效果不佳,或在需要理解多种语言的任务中。
4.较大的token对拼写错误、拼写变体及其他文本中的小变化敏感。
3. 主流大模型的分词器选择
| 模型 | 分词器 |
| GPT-4o | BPE(BBPE)【2】 |
| GPT3 | BPE(BBPE)【3】 |
| GPT2 | BPE(BBPE)【4】 |
| GPT | BPE【5】 |
| Llama3 | BPE(BBPE)【6,8】 |
| Llama2 | BPE(BBPE)【7,8】 |
| Qwen2 | BPE(BBPE)【9,10】 |
| Qwen | BPE(BBPE)【11】 |
| ChatGLM | BBPE【12】 |
| Baichuan | BPE【13】 |
| RoBERTa | BPE【5】 |
| BART | BPE【5】 |
| DeBERTa | BPE【5】 |
| MPNET | WordPiece【14】 |
| Funnel Transformers | WordPiece【14】 |
| MobileBERT | WordPiece【14】 |
| DistilBERT | WordPiece【14】 |
| BERT | WordPiece【14】 |
| T5 | Unigram【15】 |
| AlBERT | Unigram【15】 |
| mBART | Unigram【15】 |
| XLNet | Unigram【15】 |
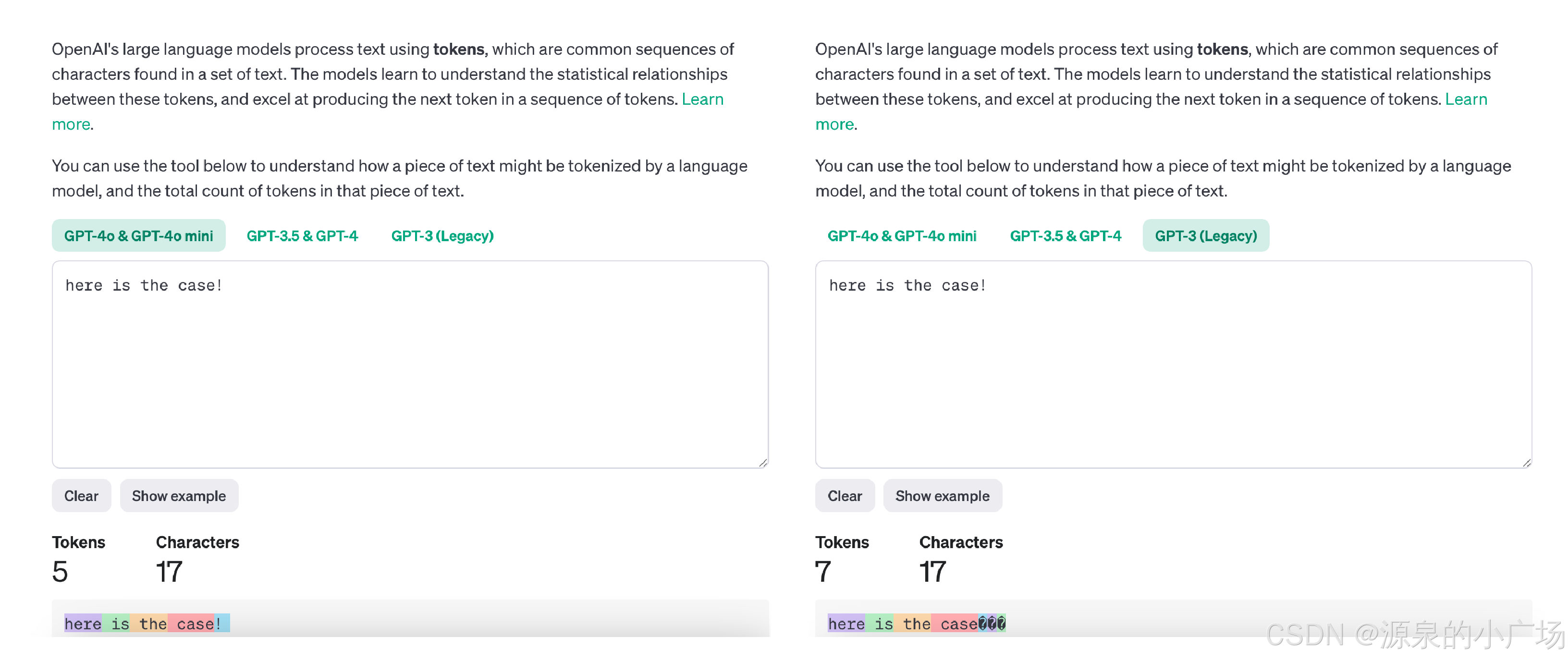
当然虽然说GPT系列或者其他大模型用的都是BPE(BBPE),但在处理上还会有一些细微的差异。可以试用下openai提供的在线tokenizer工具:https://platform.openai.com/tokenizer
此外, OpenAI、Google、huggingface分别都提供了开源的tokenizer工具:tiktoken、sentencepiece、tokenizers,支持主流的分词算法。
扩展阅读:
《全方位解读大模型:多样知识点的深度探讨与技术分享小结》
4. 参考材料
【1】Understanding “tokens” and tokenization in large language models
【2】openai/tiktoken
【3】gpt-tokenizer
【4】Language Models are Unsupervised Multitask Learners
【5】Byte-Pair Encoding tokenization
【6】Llama3
【7】Llama2
【8】Llama (LLM)
【9】qwen2-concepts
【10】tokenization_qwen2
【11】qwen/tokenization_note
【12】tokenization_chatglm
【13】Baichuan-7B
【14】WordPiece tokenization
【15】Unigram tokenization