原来的代码
@Override
@Transactional(rollbackFor = Exception.class)
public void batchAddQuestionsToBank(List<Long> questionIdList, Long questionBankId, User loginUser) {// 参数校验ThrowUtils.throwIf(CollUtil.isEmpty(questionIdList), ErrorCode.PARAMS_ERROR, "题目列表为空");ThrowUtils.throwIf(questionBankId == null || questionBankId <= 0, ErrorCode.PARAMS_ERROR, "题库非法");ThrowUtils.throwIf(loginUser == null, ErrorCode.NOT_LOGIN_ERROR);// 检查题目 id 是否存在List<Question> questionList = questionService.listByIds(questionIdList);// 合法的题目 idList<Long> validQuestionIdList = questionList.stream().map(Question::getId).collect(Collectors.toList());ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "合法的题目列表为空");// 检查题库 id 是否存在QuestionBank questionBank = questionBankService.getById(questionBankId);ThrowUtils.throwIf(questionBank == null, ErrorCode.NOT_FOUND_ERROR, "题库不存在");// 执行插入for (Long questionId : validQuestionIdList) {QuestionBankQuestion questionBankQuestion = new QuestionBankQuestion();questionBankQuestion.setQuestionBankId(questionBankId);questionBankQuestion.setQuestionId(questionId);questionBankQuestion.setUserId(loginUser.getId());boolean result = this.save(questionBankQuestion);if (!result) {throw new BusinessException(ErrorCode.OPERATION_ERROR, "向题库添加题目失败");}}
}
批处理操作优化
一般情况下,我们可以从以下多个角度对批处理任务进行优化。
- 健壮性
- 稳定性
- 性能
- 数据一致性
- 可观测性
健壮性
健壮性是指系统在面对 异常情况或不合法输入 时仍能表现出合理的行为。一个健壮的系统能够 预见和处理异常,并且即使发生错误,也不会崩溃或产生不可预期的行为。
1、参数校验提前
可以在调用数据库之前就对参数进行校验,这样可以减少不必要的数据库操作开销,不用等到数据库操作时再抛出异常。
在现有的添加题目到题库的代码中,我们已经提前对参数进行了非空校验,并且会提前检查题目和题库是否存在,这是很好的。但是我们还没有校验哪些题目已经添加到题库中,对于这些题目,不必再执行插入关联记录的数据库操作。
需要补充的代码如下:
// 检查题库 id 是否存在
// ...// 检查哪些题目还不存在于题库中,避免重复插入
LambdaQueryWrapper<QuestionBankQuestion> lambdaQueryWrapper = Wrappers.lambdaQuery(QuestionBankQuestion.class).eq(QuestionBankQuestion::getQuestionBankId, questionBankId).in(QuestionBankQuestion::getQuestionId, validQuestionIdList);
List<QuestionBankQuestion> existQuestionList = this.list(lambdaQueryWrapper);
// 已存在于题库中的题目 id
Set<Long> existQuestionIdSet = existQuestionList.stream().map(QuestionBankQuestion::getId).collect(Collectors.toSet());
// 已存在于题库中的题目 id,不需要再次添加
validQuestionIdList = validQuestionIdList.stream().filter(questionId -> {return !existQuestionIdSet.contains(questionId);
}).collect(Collectors.toList());
ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "所有题目都已存在于题库中");// 执行插入
// ...
2、异常处理
目前虽然已经对每一次插入操作的结果都进行了判断,并且抛出自定义异常,但是有些特殊的异常并没有被捕获。
可以进一步细化异常处理策略,考虑更细粒度的异常分类,不同的异常类型可以通过不同的方式处理,例如:
- 数据唯一键重复插入问题,会抛出
DataIntegrityViolationException。 - 数据库连接问题、事务问题等导致操作失败时抛出
DataAccessException。 - 其他的异常可以通过日志记录详细错误信息,便于后期追踪(全局异常处理器也有这个能力)。
示例代码如下:
try {boolean result = this.save(questionBankQuestion);if (!result) {throw new BusinessException(ErrorCode.OPERATION_ERROR, "向题库添加题目失败");}
} catch (DataIntegrityViolationException e) {log.error("数据库唯一键冲突或违反其他完整性约束,题目 id: {}, 题库 id: {}, 错误信息: {}",questionId, questionBankId, e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "题目已存在于该题库,无法重复添加");
} catch (DataAccessException e) {log.error("数据库连接问题、事务问题等导致操作失败,题目 id: {}, 题库 id: {}, 错误信息: {}",questionId, questionBankId, e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "数据库操作失败");
} catch (Exception e) {// 捕获其他异常,做通用处理log.error("添加题目到题库时发生未知错误,题目 id: {}, 题库 id: {}, 错误信息: {}",questionId, questionBankId, e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "向题库添加题目失败");
}
稳定性
1、避免长事务问题
批量操作中,一次性处理过多数据会导致事务过长,影响数据库性能。可以通过 分批处理 来避免长事务问题,确保部分数据异常不会影响整个批次的数据保存。
假设操作 10w 条数据,其中有 1 条数据操作异常,如果是长事务,那么修改的 10w 条数据都需要回滚,而分批事务仅需回滚一批既可,降低长事务带来的资源消耗,同时也提升了稳定性。
编写一个新的方法,用于对某一批操作进行事务管理:
@Override
@Transactional(rollbackFor = Exception.class)
public void batchAddQuestionsToBankInner(List<QuestionBankQuestion> questionBankQuestions) {for (QuestionBankQuestion questionBankQuestion : questionBankQuestions) {long questionId = questionBankQuestion.getQuestionId();long questionBankId = questionBankQuestion.getQuestionBankId();try {boolean result = this.save(questionBankQuestion);ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR, "向题库添加题目失败");} catch (DataIntegrityViolationException e) {log.error("数据库唯一键冲突或违反其他完整性约束,题目 id: {}, 题库 id: {}, 错误信息: {}",questionId, questionBankId, e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "题目已存在于该题库,无法重复添加");} catch (DataAccessException e) {log.error("数据库连接问题、事务问题等导致操作失败,题目 id: {}, 题库 id: {}, 错误信息: {}",questionId, questionBankId, e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "数据库操作失败");} catch (Exception e) {// 捕获其他异常,做通用处理log.error("添加题目到题库时发生未知错误,题目 id: {}, 题库 id: {}, 错误信息: {}",questionId, questionBankId, e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "向题库添加题目失败");}}
}
在原方法中批量生成题目,并且调用上述事务方法:
// 分批处理避免长事务,假设每次处理 1000 条数据
int batchSize = 1000;
int totalQuestionListSize = validQuestionIdList.size();
for (int i = 0; i < totalQuestionListSize; i += batchSize) {// 生成每批次的数据List<Long> subList = validQuestionIdList.subList(i, Math.min(i + batchSize, totalQuestionListSize));List<QuestionBankQuestion> questionBankQuestions = subList.stream().map(questionId -> {QuestionBankQuestion questionBankQuestion = new QuestionBankQuestion();questionBankQuestion.setQuestionBankId(questionBankId);questionBankQuestion.setQuestionId(questionId);questionBankQuestion.setUserId(loginUser.getId());return questionBankQuestion;}).collect(Collectors.toList());// 使用事务处理每批数据QuestionBankQuestionService questionBankQuestionService = (QuestionBankQuestionServiceImpl) AopContext.currentProxy();questionBankQuestionService.batchAddQuestionsToBankInner(questionBankQuestions);
}
需要注意的是,上述代码中,我们通过 AopContext.currentProxy() 方法获取到了当前实现类的代理对象,来调用事务方法。
为什么要这么做呢? 因为 Spring 事务依赖于代理机制,而内部调用通过 this 直接调用方法,不会通过 Spring 的代理,因此不会触发事务。
注意,使用 AopContext.currentProxy() 方法时必须要在启动类添加下面的注解开启切面自动代理:
@EnableAspectJAutoProxy(proxyTargetClass = true, exposeProxy = true)
2、重试
对于可能由于网络不稳定等临时原因偶发失败的操作,可以设计 重试机制 提高系统的稳定性,适用于执行时间很长的任务。
注意,重试的过程中要记录日志,并且重试次数要有一个上限 。示例代码如下:
int retryCount = 3;
for (int i = 0; i < retryCount; i++) {try {// 执行插入操作// 成功则跳出重试循环break; } catch (Exception e) {log.warn("插入失败,重试次数: {}", i + 1);if (i == retryCount - 1) {throw new BusinessException(ErrorCode.OPERATION_ERROR, "多次重试后操作仍然失败");}}
}
💡当然,除了手动编写重试代码外,我会更推荐 Guava Retrying 库,可以看 学习。
但对于我们目前的题目管理功能,执行时间不会特别长,增加重试反而一定程度上增加了系统的不确定性和复杂度,可以不用添加。
3、中断恢复
如果在批量插入过程中由于某种原因(如数据库宕机、服务器重启)导致批处理中断,建议设计一种机制来进行 增量恢复。比如可以为每次操作打上批次标记,在操作未完成时记录操作状态(如部分题目成功添加),并在恢复时继续执行未完成的操作。
可以设计一个数据库表存储批次的状态:
create table question_batch_status (batch_id bigint primary key,question_bank_id bigint,total_questions int,processed_questions int,status varchar(20) -- running, completed, failed
);
通过该表可以跟踪每次批处理的进度,并在失败时根据批次继续处理。其实就是保存上下文环境以便及时恢复。
性能优化
1、批量操作
当前代码中,每个题目是单独插入数据库的,这会产生频繁的数据库交互。
大多数 ORM 框架和数据库驱动都支持批量插入,可以通过批量插入来优化性能,比如 MyBatis Plus 提供了 saveBatch 方法。
优化后的代码如下:
@Override
@Transactional(rollbackFor = Exception.class)
public void batchAddQuestionsToBankInner(List<QuestionBankQuestion> questionBankQuestions) {try {boolean result = this.saveBatch(questionBankQuestions);ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR, "向题库添加题目失败");} catch (DataIntegrityViolationException e) {log.error("数据库唯一键冲突或违反其他完整性约束, 错误信息: {}", e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "题目已存在于该题库,无法重复添加");} catch (DataAccessException e) {log.error("数据库连接问题、事务问题等导致操作失败, 错误信息: {}", e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "数据库操作失败");} catch (Exception e) {// 捕获其他异常,做通用处理log.error("添加题目到题库时发生未知错误,错误信息: {}", e.getMessage());throw new BusinessException(ErrorCode.OPERATION_ERROR, "向题库添加题目失败");}
}
批量操作的好处:
- 降低了数据库连接和提交的频率。
- 避免频繁的数据库交互,减少 I/O 操作,显著提高性能。
💡类似的,Redis 也提供了批处理方法,比如 Pipeline。
2、SQL 优化
我们在操作数据库时,可以使用一些 SQL 优化的技巧。
其中,有一个最基本的 SQL 优化原则,不要使用 select * 来查询数据,只查出需要的字段即可。由于框架封装地太好了,可能大多数同学都不会注意这点,其实我们上述的代码就需要对此进行优化,来减少查询的数据量。
比如:
// 检查题目 id 是否存在
LambdaQueryWrapper<Question> questionLambdaQueryWrapper = Wrappers.lambdaQuery(Question.class).select(Question::getId).in(Question::getId, questionIdList);
List<Question> questionList = questionService.list(questionLambdaQueryWrapper);
由于返回的值只有 id 一列,还可以直接转为 Long 列表,不需要让框架封装结果为 Question 对象了,减少内存占用:
// 合法的题目 id
List<Long> validQuestionIdList = questionService.listObjs(questionLambdaQueryWrapper, obj -> (Long) obj);
ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "合法的题目列表为空");
3、并发编程
由于我们已经将操作分批处理,在操作较多、追求处理时间的情况下,可以通过并发编程让每批操作同时执行,而不是一批处理完再执行下一批,能够大幅提升性能。
Java 中,可以利用并发包中的 CompletableFuture + 线程池 来并发处理多个任务。
CompletableFuture 是 Java 8 中引入的一个类,用于表示异步操作的结果。它是 Future 的增强版本,不仅可以表示一个异步计算,还可以对异步计算的结果进行组合、转换和处理,实现异步任务的编排。
比如下列代码,将任务拆分为多个子任务,并发执行,最后通过 CompletableFuture.allOf 方法阻塞等待,只有所有的子任务都完成,才会执行后续代码:
List<CompletableFuture<Void>> futures = new ArrayList<>();for (List<Long> subList : splitList(validQuestionIdList, 1000)) {CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {processBatch(subList, questionBankId, loginUser);});futures.add(future);
}// 等待所有任务完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
CompletableFuture 默认使用 Java 7 引入的 ForkJoinPool 线程池来并发执行任务。该线程池特别适合需要分治法来处理的大量并发任务,支持递归任务拆分。Java 8 中的并行流默认也是使用了 ForkJoinPool 进行并发处理
ForkJoinPool 的主要特性:
- 工作窃取算法(Work-Stealing):线程可以从其他线程的工作队列中“窃取”任务,以提高 CPU 的使用率和程序的并行性。
- 递归任务处理:支持将大任务拆分为多个小任务并行执行,然后再将结果合并。
💡 但是要注意,CompletableFuture 默认使用的是 ForkJoinPool.commonPool() 方法得到的线程池,这是一个全局共享的线程池,如果有多种不同的任务都依赖该线程池进行处理,可能会导致资源争抢、代码阻塞等不确定的问题。所以建议针对每种任务,自定义线程池来处理,实现线程池资源的隔离。
Java 内置了很多种不同的线程池,比如单线程的线程池、固定线程的线程池、自定义线程池等等,一般情况下我们会根据业务和资源情况 自定义线程池。
此处画个重点,大家只要记住一个公式:
- 对于计算密集型任务(消耗 CPU 资源), 设置核心线程数为
n+1或者n(n 是 CPU 核心数),可以充分利用 CPU, 多一个线程是为了可以在某些线程短暂阻塞或执行调度时,确保有足够的线程保持 CPU 繁忙,最大化 CPU 的利用率。 - 对于 IO 密集型任务(消耗 IO 资源),可以增大核心线程数为 CPU 核心数的 2 - 4 倍,可以提升并发执行任务的数量。
对于批量添加题目功能,和数据库交互频繁,属于 IO 密集型任务,可以给自定义线程池更大的核心线程数。引入并发编程后的代码:
// 自定义线程池
ThreadPoolExecutor customExecutor = new ThreadPoolExecutor(20, // 核心线程数50, // 最大线程数60L, // 线程空闲存活时间TimeUnit.SECONDS, // 存活时间单位new LinkedBlockingQueue<>(10000), // 阻塞队列容量new ThreadPoolExecutor.CallerRunsPolicy() // 拒绝策略:由调用线程处理任务
);// 用于保存所有批次的 CompletableFuture
List<CompletableFuture<Void>> futures = new ArrayList<>();// 分批处理避免长事务,假设每次处理 1000 条数据
int batchSize = 1000;
int totalQuestionListSize = validQuestionIdList.size();
for (int i = 0; i < totalQuestionListSize; i += batchSize) {// 生成每批次的数据List<Long> subList = validQuestionIdList.subList(i, Math.min(i + batchSize, totalQuestionListSize));List<QuestionBankQuestion> questionBankQuestions = subList.stream().map(questionId -> {QuestionBankQuestion questionBankQuestion = new QuestionBankQuestion();questionBankQuestion.setQuestionBankId(questionBankId);questionBankQuestion.setQuestionId(questionId);questionBankQuestion.setUserId(loginUser.getId());return questionBankQuestion;}).collect(Collectors.toList());QuestionBankQuestionService questionBankQuestionService = (QuestionBankQuestionServiceImpl) AopContext.currentProxy();// 异步处理每批数据并添加到 futures 列表CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {questionBankQuestionService.batchAddQuestionsToBankInner(questionBankQuestions);}, customExecutor);futures.add(future);
}// 等待所有批次操作完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();// 关闭线程池
customExecutor.shutdown();
5、数据库连接池调优
数据库连接池是用于管理与数据库之间连接的资源池,它能够 复用 现有的数据库连接,而不是在每次请求时都新建和销毁连接,从而提升系统的性能和响应速度。
常见的数据库连接池有 2 种:
1)HikariCP:被认为是市场上最快的数据库连接池之一,具有非常低的延迟和高效的性能。它以其轻量级和简洁的设计闻名,占用较少的内存和 CPU 资源。
Spring Boot 2.x 版本及以上默认使用 HikariCP 作为数据库连接池。
2)Druid:由阿里巴巴开发的开源数据库连接池,提供了丰富的监控和管理功能,包括 SQL 分析、性能监控和慢查询日志等。适合需要深度定制和监控的企业级应用。
在使用 Spring Boot 2.x 的情况下,默认 HikariCP 连接池大小是 10,当前请求量大起来之后,如果数据库执行的不够快,那么请求都会被阻塞等待获取连接池的连接上。
比如鱼皮自己业务中出现的情况,获取数据库连接等待时间花了 17.43s,这就是典型的数据库连接不够用。如果项目的数据库连接池较小,此时应该调大数据库连接池的大小:
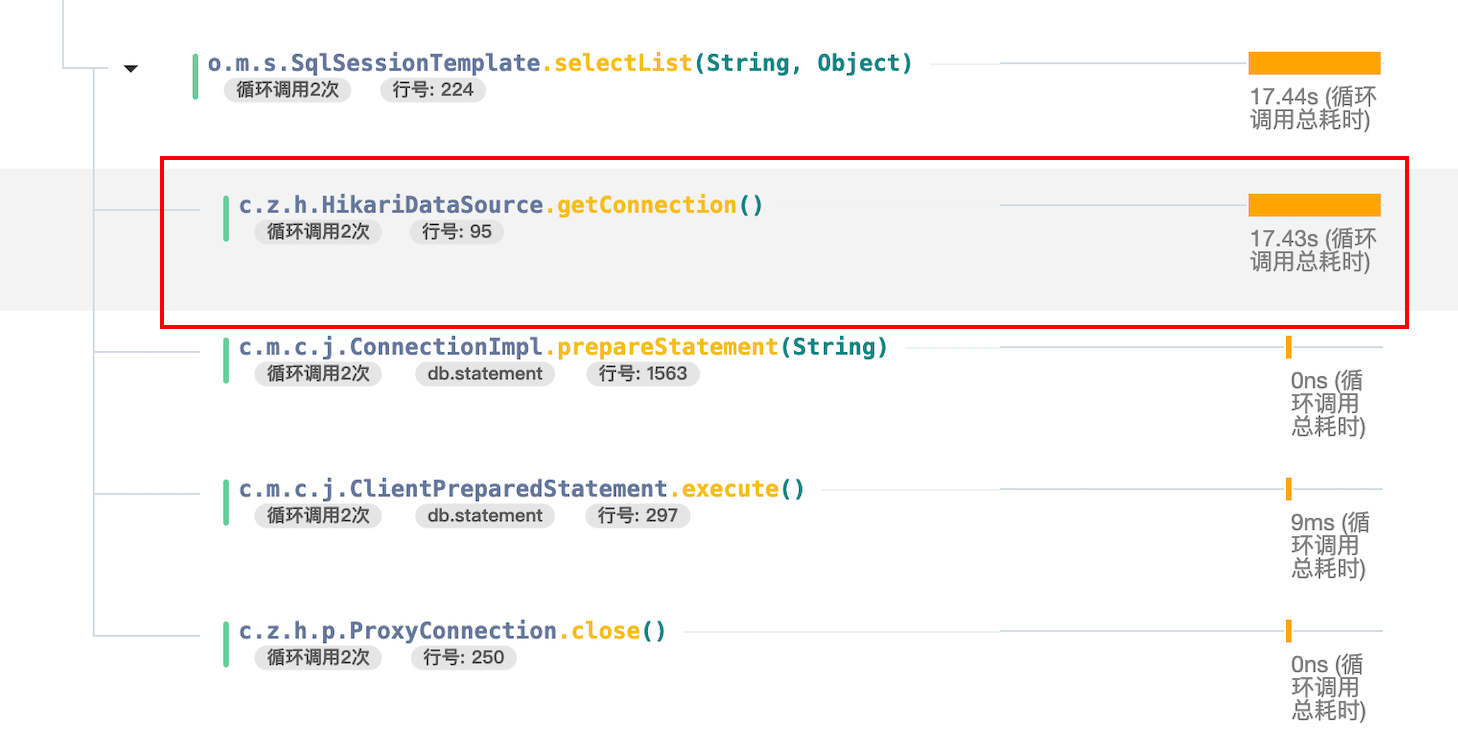
如何进行数据库连接池调优呢?肯定不是凭感觉猜测,而是要通过监控或测试进行分析。
所以本项目会带大家使用 Druid 来做数据库连接池,因为它提供了丰富的监控和管理功能,更适合学习上手数据库连接池调优。
引入 Druid 连接池
可以参考 官方文档 引入(虽然也没什么好参考的)。
1)通过 Maven 引入 Druid,并且排除默认引入的 HikariCP:
<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.2.23</version>
</dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>2.2.2</version><exclusions><!-- 排除默认的 HikariCP --><exclusion><groupId>com.zaxxer</groupId><artifactId>HikariCP</artifactId></exclusion></exclusions>
</dependency>
2)修改 application.yml 文件配置。
由于参数较多,建议直接拷贝以下配置即可,部分参数可以根据注释自行调整:
spring:# 数据源配置datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/mianshiyausername: rootpassword: 123456# 指定数据源类型type: com.alibaba.druid.pool.DruidDataSource# Druid 配置druid:# 配置初始化大小、最小、最大initial-size: 10minIdle: 10max-active: 10# 配置获取连接等待超时的时间(单位:毫秒)max-wait: 60000# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒time-between-eviction-runs-millis: 2000# 配置一个连接在池中最小生存的时间,单位是毫秒min-evictable-idle-time-millis: 600000max-evictable-idle-time-millis: 900000# 用来测试连接是否可用的SQL语句,默认值每种数据库都不相同,这是mysqlvalidationQuery: select 1# 应用向连接池申请连接,并且testOnBorrow为false时,连接池将会判断连接是否处于空闲状态,如果是,则验证这条连接是否可用testWhileIdle: true# 如果为true,默认是false,应用向连接池申请连接时,连接池会判断这条连接是否是可用的testOnBorrow: false# 如果为true(默认false),当应用使用完连接,连接池回收连接的时候会判断该连接是否还可用testOnReturn: false# 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oraclepoolPreparedStatements: true# 要启用PSCache,必须配置大于0,当大于0时, poolPreparedStatements自动触发修改为true,# 在Druid中,不会存在Oracle下PSCache占用内存过多的问题,# 可以把这个数值配置大一些,比如说100maxOpenPreparedStatements: 20# 连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作keepAlive: true# Spring 监控,利用aop 对指定接口的执行时间,jdbc数进行记录aop-patterns: "com.springboot.template.dao.*"########### 启用内置过滤器(第一个 stat 必须,否则监控不到SQL)##########filters: stat,wall,log4j2# 自己配置监控统计拦截的filterfilter:# 开启druiddatasource的状态监控stat:enabled: truedb-type: mysql# 开启慢sql监控,超过2s 就认为是慢sql,记录到日志中log-slow-sql: trueslow-sql-millis: 2000# 日志监控,使用slf4j 进行日志输出slf4j:enabled: truestatement-log-error-enabled: truestatement-create-after-log-enabled: falsestatement-close-after-log-enabled: falseresult-set-open-after-log-enabled: falseresult-set-close-after-log-enabled: false########## 配置WebStatFilter,用于采集web关联监控的数据 ##########web-stat-filter:enabled: true # 启动 StatFilterurl-pattern: /* # 过滤所有urlexclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" # 排除一些不必要的urlsession-stat-enable: true # 开启session统计功能session-stat-max-count: 1000 # session的最大个数,默认100########## 配置StatViewServlet(监控页面),用于展示Druid的统计信息 ##########stat-view-servlet:enabled: true # 启用StatViewServleturl-pattern: /druid/* # 访问内置监控页面的路径,内置监控页面的首页是/druid/index.htmlreset-enable: false # 不允许清空统计数据,重新计算login-username: root # 配置监控页面访问密码login-password: 123allow: 127.0.0.1 # 允许访问的地址,如果allow没有配置或者为空,则允许所有访问deny: # 拒绝访问的地址,deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝
3)启动后访问监控面板:http://localhost:8101/api/druid/index.html
输入上述配置中的用户名和密码登录:
💡扩展知识:想去除底部广告,可以在项目中添加下面的代码:
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure;
import com.alibaba.druid.spring.boot.autoconfigure.properties.DruidStatProperties;
import com.alibaba.druid.util.Utils;
import org.springframework.boot.autoconfigure.AutoConfigureAfter;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.boot.autoconfigure.condition.ConditionalOnWebApplication;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.servlet.*;
import java.io.IOException;@Configuration
@ConditionalOnWebApplication
@AutoConfigureAfter(DruidDataSourceAutoConfigure.class)
@ConditionalOnProperty(name = "spring.datasource.druid.stat-view-servlet.enabled",havingValue = "true", matchIfMissing = true)
public class RemoveDruidAdConfig {/*** 方法名: removeDruidAdFilterRegistrationBean* 方法描述 除去页面底部的广告* @param properties com.alibaba.druid.spring.boot.autoconfigure.properties.DruidStatProperties* @return org.springframework.boot.web.servlet.FilterRegistrationBean*/@Beanpublic FilterRegistrationBean removeDruidAdFilterRegistrationBean(DruidStatProperties properties) {// 获取web监控页面的参数DruidStatProperties.StatViewServlet config = properties.getStatViewServlet();// 提取common.js的配置路径String pattern = config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*";String commonJsPattern = pattern.replaceAll("\\*", "js/common.js");final String filePath = "support/http/resources/js/common.js";//创建filter进行过滤Filter filter = new Filter() {@Overridepublic void init(FilterConfig filterConfig) throws ServletException {}@Overridepublic void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {chain.doFilter(request, response);// 重置缓冲区,响应头不会被重置response.resetBuffer();// 获取common.jsString text = Utils.readFromResource(filePath);// 正则替换banner, 除去底部的广告信息text = text.replaceAll("<a.*?banner\"></a><br/>", "");text = text.replaceAll("powered.*?shrek.wang</a>", "");response.getWriter().write(text);}@Overridepublic void destroy() {}};FilterRegistrationBean registrationBean = new FilterRegistrationBean();registrationBean.setFilter(filter);registrationBean.addUrlPatterns(commonJsPattern);return registrationBean;}
}
💡 Druid 的 URI 监控是怎么实现的?
核心实现方法如下:
- 通过基于 Servlet 的过滤器
WebStatFilter来拦截请求,该过滤器会收集关于请求的相关信息,比如请求的 URI、执行时长、请求期间执行的 SQL 语句数等。 - 统计 URI 和 SQL 执行情况是怎么关联起来的呢? 每次执行 SQL 时,Druid 会在内部统计该 SQL 的执行情况,而
WebStatFilter会把 SQL 执行信息与当前的 HTTP 请求 URI 关联起来。
数据一致性
1、事务管理
我们目前已经使用了 @Transactional(rollbackFor = Exception.class) 来保证数据一致性。如果任意一步操作失败,整个事务会回滚,确保数据一致性。
2、并发管理
在高并发场景下,如果多个管理员同时向同一个题库添加题目,可能会导致冲突或性能问题。为了解决并发问题,确保数据一致性和稳定性,可以有 2 种常见的策略:
1)增加 分布式锁 来防止同一个接口(或方法)在同一时间被多个管理员同时操作,比如使用 Redis + Redisson 实现分布式锁。
2)如果要精细地对某个数据进行并发控制,可以选用 乐观锁。比如通过给 QuestionBank 表增加一个 version 字段,在更新时检查版本号是否一致,确保对同一个题库的并发操作不会相互干扰。
伪代码示例:
// 更新题库前,先查询版本号
QuestionBank questionBank = questionBankService.getById(questionBankId);
Long currentVersion = questionBank.getVersion();// 更新时,检查版本号是否一致
int rowsAffected = questionBankService.updateVersionById(questionBankId, currentVersion);
if (rowsAffected == 0) {throw new BusinessException(ErrorCode.CONCURRENT_MODIFICATION, "数据已被其他用户修改");
}
💡 在 MySQL 中,还可以采用 SELECT ... FOR UPDATE 来强行锁定某一行数据,直到当前事务提交或回滚之前,防止其他事务对这行数据进行修改。
可观测性
可观测性的关键在于以下三个方面:
- 可见性:系统需要能够报告它的内部状态。这个优化方案通过返回
BatchAddResult提供了丰富的状态反馈。 - 追踪性:通过详细的错误原因和具体失败项,可以轻松地追踪问题源头。
- 诊断性:明确的反馈信息有助于快速诊断问题,而不仅仅是提供一个简单的 "成功" 或 "失败"。
1、日志记录
在高并发场景下,批量操作可能会出现一些难以预料的问题,建议多记录操作日志:包括成功、失败的题目,便于排查问题。
比如:
log.error("数据库唯一键冲突或违反其他完整性约束, 错误信息: {}", e.getMessage());
2、监控
监控是实现可观测性的主流手段,你可以对服务器、JVM、请求、以及项目中引入的各种组件进行监控。
常用的监控工具有 Grafana,如果你给项目引入了某个技术组件,一般都会自带监控,比如项目调用数据库的情况可以通过 Druid 监控、Elasticsearch 可以通过 Kibana 监控等等、Spring Boot 内置了 Spring Boot Actuator 来监控应用运行状态等。
💡 如果你使用的是第三方云服务,比如 XX 云的云数据库,一般都会自带成熟的监控面板,有时间建议大家多去逛逛云服务平台,能看到很多业界成熟的监控方案。
3、返回值优化
目前我们的方法返回的是 void,这意味着在执行过程中没有明确反馈操作的结果。为了提升可观测性,我们可以根据任务的执行状态返回更加详细的结果,帮助调用者了解任务的执行情况。
可以定义一个返回结果对象,包含每个题目的处理状态、成功和失败的数量,以及失败的原因。
public class BatchAddResult {private int total;private int successCount;private int failureCount;private List<String> failureReasons;
}