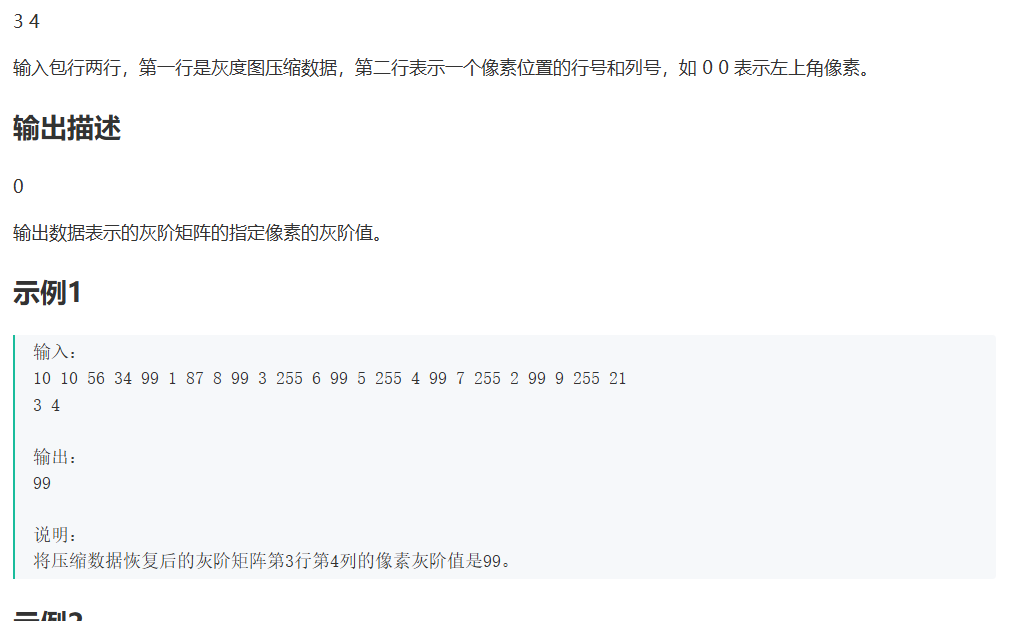
1. BFS 的两种方式
如下图, 是一个二叉树. 我们需要按照层的方式来遍历这棵树.


1.1 使用 JDK 自带的类实现(链表实现, 经典 BFS)
- 首先我们实现一个队列, 这个队列从头进, 从尾出.
- 然后将根节点放入其中,
- 然后将放入的节点弹出,
- 然后继续验证弹出的节点有没有左孩子, 若是有, 将左孩子压入队列中.
- 然后继续验证弹出的节点有没有右孩子, 若是有, 将右孩子压入队列中.
- 因为我们需要案按照层的顺序收集节点, 所以我们需要设置一个
hash表用来记录对应的节点和所在的层数, 还需要一个双层的List结构, 用来记录每一层的树节点. - 然后继续实现上述的流程, 只要是当前节点的左孩子和右孩子, 那对应的层数肯定就是当前节点的下一层.
1.2 代码实例
public static List<List<Integer>> levelOrder1(TreeNode root) { List<List<Integer>> ans = new ArrayList<>(); if (root != null) { Queue<TreeNode> queue = new LinkedList<>(); // 用链表来模拟队列. HashMap<TreeNode, Integer> levels = new HashMap<>(); // 用哈希表表示节点在第几层. queue.add(root); // 将“根节点”放入队列中. levels.put(root, 0); // 然后利用哈希表获取当前节点:根节点的层数. while (!queue.isEmpty()) { // 队列中只要不是null, 这个循环就不停止. TreeNode cur = queue.poll(); // 将弹出的节点设置为 cur. int level = levels.get(cur); // 通过这个key(节点), 获得对应的value(层数). if (ans.size() == level) { // 若是ans的大小 == 层数, 说明此时我没有对应下标的数组. ans.add(new ArrayList<>()); // 此时在其中新建一个数组 } ans.get(level).add(cur.val); // 此时找到ans下标为层数的数组, 然后在其中加入对应的值. if (cur.left != null) { // 若是弹出节点的左孩子不是null, queue.add(cur.left); // 将弹出节点的左孩子加入到队列中, levels.put(cur.left, level + 1); // 将这个左孩子加入到hash表中的key, 层数加入到value. } if (cur.right != null) { // 和上面是一样的, 只是将左孩子换成了右孩子了. queue.add(cur.right); levels.put(cur.right, level + 1); } } } return ans; // 最后返回ans.
}
1.3 自己用数组实现队列一次处理一层, 逻辑实现
可以自己用数组实现一个队列, 然后设置 l 和 r , 将 r 设置为将数字加入的位置, l 设置为数字出去的位置,
- 将当前节点加入到数组(队列)中, 得到此时队列的长度是
size, 重复下面的行为size遍. - 先弹出当前节点, 然后有左孩子就加入左孩子, 有右孩子就加入右孩子.
- 然后将弹出来的所有节点都加入到对应的数组中去. (当然, 现在只弹出了一个节点, 后续加入了一层很多节点之后, 我们直接将所有的节点都加入到其中), 这样会非常高效.
1.4 代码实例
public static List<List<Integer>> levelOrder2(TreeNode root) { List<List<Integer>> ans = new ArrayList<>(); if (root != null) { // 保证这个树不是null. l = r = 0; // 开始的时候, 没有任何东西加入到这个数组中. queue[r++] = root; // 直接将这个二叉树的根节点加入到数组中. while (l < r) { // 队列里还有东西 int size = r - l; // size表示队列的大小. ArrayList<Integer> list = new ArrayList<Integer>(); // list 保存此时的层数的节点. for (int i = 0; i < size; i++) { // 如下操作执行 size 遍. 经过完整的for循环之后, 会将所有的节点都加入当list中. TreeNode cur = queue[l++]; // 将弹出的节点设置为当前节点. list.add(cur.val); // 将这个弹出了的节点放到list中. if (cur.left != null) { // 判断当前节点的左孩子是不是null queue[r++] = cur.left; // 若不是null, 将其加入到队列中. } if (cur.right != null) { // 判断当前节点的左孩子是不是null queue[r++] = cur.right; // 若不是null, 将其加入到队列中. } } ans.add(list); // 最后将这一层的节点都处理好了, 最后直接加入到ans中. } } return ans; // 最后直接返回ans就行.
}
2. 题目二:锯齿状遍历

2.1 逻辑实现
还是利用了上面优化了之后的 BFS, 唯一有点不一样的就是对应的遍历的顺序是不同的.
- 我们设置一个
bool类型的变量, 这样方便我们进行不同顺序的遍历, - 根据不同的
reverse 是 false 和 true将树节点按照不同的顺序放入到队列中, - 将一层的所有树节点放入到队列中后, 然后依次弹出队列, 然后将下一层的节点放到队列中.
- 然后继续将
list加入到ans中, 然后反转reverse的状态.
2.2 代码实例
我们单独将这段代码拿出来说明一下, 这段代码的功能是将这一层的节点按照要求的顺序收集
当 reverse == true 的时候, 我们收集的顺序是:从右往左收集, 所以此时 i == r - 1, j == -1, 因为我们需要的是从右往左收集, 所以我们需要从右边开始收集, 只需要执行 size 次就能收集好这一层的所有树节点了,
这个 for循环 设计的非常精妙, i 表示从队列的哪里开始收集, 而 j 表示是回退还是前进, k 表示次数, i += j 这个设计同时满足了前进回退的需要, 毕竟 i 和 j 是同时满足的, i 在左边开始收集的时候, j肯定前进是 所以 j == 1, i 在右边开始收集的时候, j肯定是回退, 所以 j == -1.
for (int i = reverse ? r - 1 : l, j = reverse ? -1 : 1, k = 0; k < size; i += j, k++) { TreeNode cur = queue[i]; list.add(cur.val);
}
但是需要注意的是:所有的树节点进入队列的方式已经确定了, 我们只是通过上面的 for循环 实现了将不同的树节点从左往右还是从右往左放入 list 中的操作.
public static int MAXN = 2001; public static TreeNode[] queue = new TreeNode[MAXN]; public static int l, r;public static List<List<Integer>> zigzagLevelOrder(TreeNode root) { List<List<Integer>> ans = new ArrayList<>(); if (root != null) { l = r = 0; queue[r++] = root; // false 代表从左往右 // true 代表从右往左 boolean reverse = false; while (l < r) { int size = r - l; ArrayList<Integer> list = new ArrayList<Integer>(); // reverse == false, 左 -> 右, l....r-1, 收集size个 // reverse == true, 右 -> 左, r-1....l, 收集size个 // 左 -> 右, i = i + 1 // 右 -> 左, i = i - 1 for (int i = reverse ? r - 1 : l, j = reverse ? -1 : 1, k = 0; k < size; i += j, k++) { TreeNode cur = queue[i]; list.add(cur.val); } for (int i = 0; i < size; i++) { TreeNode cur = queue[l++]; if (cur.left != null) { queue[r++] = cur.left; } if (cur.right != null) { queue[r++] = cur.right; } } ans.add(list); reverse = !reverse; } } return ans;
}
3. 题目三:最大特殊宽度

3.1 逻辑实现
这里需要我们对“堆结构”有一些了解, 我们这里有一些巧思.
- 我们首先对树节点进行编号, 假设
root(根节点)的编号是:1, 然后那对应的左孩子的编号是:1 * 2, 右孩子编号是:1 * 2 + 1, 这个方式和堆结构很相似, 而且将root设置为0也是可以的, 这样就和堆结构完全一样了, 所以就直接看自己就行了. - 这样的好处是, 可以省去层的麻烦, 我只要编号就行了, 也不用管是不是
null, 我只需要直到队列中最左边的编号和最右边的编号的差值就行了. 我只要每一层都遍历完了之后, 最大的那一个差值.
3.2 代码实例
public static int MAXN = 3001; public static TreeNode[] nq = new TreeNode[MAXN]; // nodeQueue 用来存储树节点. public static int[] iq = new int[MAXN]; // idQueue 用来存储节点的编号 public static int l, r; public static int widthOfBinaryTree(TreeNode root) { int ans = 1; l = r = 0; nq[r] = root; // 先将根节点放入到 节点队列中. iq[r++] = 1; // 并且同时将对应的编号放入到 编号队列中. 我们给根节点设置的编号是:1. while (l < r) { int size = r - l; ans = Math.max(ans, iq[r - 1] - iq[l] + 1); // 哪一层的最大深度要大一点. for (int i = 0; i < size; i++) { TreeNode node = nq[l]; int id = iq[l++]; if (node.left != null) { nq[r] = node.left; iq[r++] = id * 2; } if (node.right != null) { nq[r] = node.right; iq[r++] = id * 2 + 1; } } } return ans;
}
4. 题目四:最大深度和最小深度
4.1 最大深度

4.1.1 代码实例
这个不难理解, 直接给代码实例解释
我们在执行下面的代码的时候, 有不理解的地方, 可以直接画一下递归决策图, 这样就非常好理解了.
比如下图的树, 我们要找这个二叉树的最大深度, 我们只需要画一下递归决策图就能完全理解了.


public static int maxDepth(TreeNode root) { return root == null ? 0 : Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
4.2 最小深度
注意:这里的最小深度是必须要到达叶节点, 比如从根节点 root 开始, root.left == null, root.right != null, 那么这个二叉树的最小深度只能是右边的树节点了.
4.2.1 代码实例
这个同样的不难的, 我们还是直接上代码
首先规定两个特殊情况, 一种是当前根节点为 null, 直接返回 0, 因为这棵树都不存在.
另一种是当前只有一个根节点 root, 返回 1, 因为此时 root 这个节点是根节点的也是叶节点.
为了规避在上面“注意”中情况, 我们需要在开始遍历二叉树之前, 将左右两边的深度分别都设置为:Integer.MAX_VALUE.
然后执行后面的代码, 将树左右两边的叶节点都遍历一遍, 然后进行对比, 拿出其中的最小值. 最后返回.
这个行为还是一个递归实现, 只要画一下递归决策图就能更好理解了.
注意:if (root == null) { return 0; }, 这个情况的判断只会在最开始的时候判断, 后续是永远不会重新判断的, 因为我们后续进入递归的条件就是该节点的左孩子不是 null, 或者该节点的右孩子不是 null, 这也就导致 2 <- 1 -> null 这种情况下, ldeep == 1, rdeep == Integer.MAX_VALUE. 所以 1 这个节点最后的返回值是:2.
public int minDepth(TreeNode root) { // 最小深度肯定不是 1, 因为要到叶子节点上. if (root == null) { // 当前的树是空树 return 0; } if (root.left == null && root.right == null) { // 当前root是叶节点 (又是根节点) return 1; } int ldeep = Integer.MAX_VALUE; // 为了防止一边是null, 导致最后的结果是 1, 因为要到叶子节点上. int rdeep = Integer.MAX_VALUE; if (root.left != null) { ldeep = minDepth(root.left); } if (root.right != null) { rdeep = minDepth(root.right); } return Math.min(ldeep, rdeep) + 1;
}
5. 题目五:二叉树的序列化和反序列化
序列化就是将这个二叉树转为字符串的形式, 反序列化就是将这个字符串转为二叉树的形式,
比如下面这棵树转为字符串的就是按照先序的方式序列化的过程, 反序列化就是通过右边转为左边二叉树的过程. null 用 # 代替, 中间用 , 分隔开.

序列化和反序列化有先序和后序两种方式, 没有中序的方式, 因为中序有可能将两个不同的二叉树混淆.
// 二叉树可以通过先序、后序或者按层遍历的方式序列化和反序列化
// 但是,二叉树无法通过中序遍历的方式实现序列化和反序列化
// 因为不同的两棵树,可能得到同样的中序序列,即便补了空位置也可能一样。
// 比如如下两棵树
// __2
// /
// 1
// 和
// 1__
// \
// 2
// 补足空位置的中序遍历结果都是{ null, 1, null, 2, null}
5.1 逻辑实现
5.1.1 序列化的逻辑实现
这个的逻辑实现很好想, 遍历整个二叉树, 然后若是遇见 null 就将字符串中加入 #,, 若是遇见非 null 的时候, 就向字符串中加入对应的 val.
5.1.2 反序列化的逻辑实现
将字符串用 , 进行分割, 然后根据字符找到对应的值, 最后从顶部到底部建立好二叉树.
5.2 代码实现
5.2.1 序列化的代码实例
这里我们利用了“先序遍历”的“递归”方式, 遍历了整个二叉树, 然后利用 StringBuilder 类, 将二叉树序列化了.
public String serialize(TreeNode root) { StringBuilder builder = new StringBuilder(); f(root, builder); return builder.toString();
} void f(TreeNode root, StringBuilder builder) { if (root == null) { builder.append("#,"); } else { builder.append(root.val + ","); f(root.left, builder); f(root.right, builder); }
}
5.2.2 反序列化的代码实例
这里需要注意的是:我们需要一个变量 cnt 记录字符串消费到哪里了, 这样就和序列化的过程相反了, 将 String数组中 所有的字符都对应好一个二叉树节点进行建立.
public TreeNode deserialize(String data) { String[] vals = data.split(","); cnt = 0; return g(vals);
} // 当前数组消费到哪了
public static int cnt; TreeNode g(String[] vals) { String cur = vals[cnt++]; if (cur.equals("#")) { return null; } else { TreeNode head = new TreeNode(Integer.parseInt(cur)); head.left = g(vals); head.right = g(vals); return head; }
}
6. 题目六:按照层的方式进行序列化和反序列化
这个方式也是很好理解的, 具体的说明我们直接看代码实例
6.1 序列化
public static int MAXN = 10001; public static TreeNode[] queue = new TreeNode[MAXN]; public static int l, r; public String serialize(TreeNode root) { StringBuilder builder = new StringBuilder(); if (root != null) { builder.append(root.val + ","); // 将根节点的值放入 builder 中.实现序列化过程.l = 0; r = 0; queue[r++] = root; while (l < r) { TreeNode cur = queue[l++]; // 将节点弹出.if (cur.left != null) { builder.append(cur.left.val + ","); // 将弹出节点的左边节点序列化queue[r++] = cur.left; // 然后将左边节点放入到队列中.} else { builder.append("#,"); // 左边节点为null, 不加入队列, 直接序列化} if (cur.right != null) { builder.append(cur.right.val + ","); // 这里和上面是一样的.queue[r++] = cur.right; } else { builder.append("#,"); } } } return builder.toString();
}
6.2 反序列化
public TreeNode deserialize(String data) { if (data.isEmpty()) { // 先判断是不是null, 若是, 直接返回nullreturn null; } String[] nodes = data.split(","); // 将字符串分割int index = 0; TreeNode root = generate(nodes[index++]); // 直接建立好根节点.l = 0; r = 0; queue[r++] = root; // 将根节点加入到队列中,while (l < r) { TreeNode cur = queue[l++]; cur.left = generate(nodes[index++]); // 这里判断左孩子是不是nullcur.right = generate(nodes[index++]); // 这里判断右孩子是不是nullif (cur.left != null) { queue[r++] = cur.left; } if (cur.right != null) { queue[r++] = cur.right; } } return root;
} private TreeNode generate(String val) { // 这个函数用来创建二叉树节点, 或者直接返回一个null的二叉树节点.return val.equals("#") ? null : new TreeNode(Integer.parseInt(val));
}
7. 题目七:先序和中序结构重构二叉树
7.1 逻辑实现

我们假设需要上图中的两个数组, 实现一个二叉树, 我们可以利用递归的方式建立一个二叉树.
这棵二叉树的先序数组和中序数组一定是相互对应的, 按照上图为例子, 在 f 函数中, [0, 4]范围上的数组上是整棵树. 从这两个数组中建立好整棵树的头结点.
所以我们设计的函数 f(先序数组, 0, 4, 中序数组, 0, 4). 通过这个函数建立好根结点 a, 然后继续通过 f 函数建立 a 的左孩子:f(先序数组, 1, 2, 中序数组, 0, 1), 右孩子也是一样.
假设先序数组中范围是:[l1, r1], 中序数组中范围是:[l2, r2]. 先序数组中, 头结点肯定是:l1, 那么中序数组中对应的可能是:k, 然后我们建立左孩子, 左孩子的建立肯定是从 l1 + 1 开始, 中序的范围是 [l2, k - 1], 这样先序数组中对应的范围是:[l1, l1 + k - l2], 建立右孩子的过程也是一样的.
我们主要是通过一个范围, 然后根据对应的数组范围, 创建好对应的节点.
7.2 代码实例
这个方法中, 使用 HashMap 的意义是:先将所有的中序数组中所有的数字放好, 这样后续方便取用. 不用每一次寻找 k 的时候, 都要遍历一遍.
public static TreeNode buildTree(int[] pre, int[] in) { if (pre == null || in == null || pre.length != in.length) { return null; } HashMap<Integer, Integer> map = new HashMap<>(); for (int i = 0; i < in.length; i++) { map.put(in[i], i); } return f(pre, 0, pre.length - 1, in, 0, in.length - 1, map);
} public static TreeNode f(int[] pre, int l1, int r1, int[] in, int l2, int r2, HashMap<Integer, Integer> map) { if (l1 > r1) { return null; } TreeNode head = new TreeNode(pre[l1]); if (l1 == r1) { return head; } int k = map.get(pre[l1]); // pre : l1(........)[.......r1] // in : (l2......)k[........r2] // (...)是左树对应,[...]是右树的对应 head.left = f(pre, l1 + 1, l1 + k - l2, in, l2, k - 1, map); head.right = f(pre, l1 + k - l2 + 1, r1, in, k + 1, r2, map); return head;
}
8. 题目八:判断完全二叉树
判断完全二叉树之前, 我们先确定一个概念:满二叉树,
满二叉树的概念是:一棵二叉树中, 所有的节点都是满的, 需要保证除了叶节点之外的每一个树节点都有左孩子和右孩子. 如下图.

那么完全二叉树就是将这个满二叉树从后往前砍, 如下图. 那怕是最后砍的只剩下 a 这一个根节点了, 也是一个完全二叉树.
或者说:完全二叉树的编号必须的连续的, 不能跳过.

8.1 逻辑实现
我们还是使用 BFS 进行遍历, 但是要一个一个节点地进行判断, 当我们遇见每一个节点的时候, 需要判断以下两个情况:
- 若是一个节点只有右孩子, 没有左孩子. 说明这个树不是完全二叉树.
- 若是发现一个节点的孩子不全, 那么从这个节点开始, 之后的所有节点, 必须全部都是叶节点. 若只要有一个不是叶子节点就说明不是一个完全二叉树.
若是遇见上述两个情况中任意一个情况的二叉树, 不是完全二叉树.
8.2 代码实例
// 提交以下的方法
// 如果测试数据量变大了就修改这个值
public static int MAXN = 101; public static TreeNode[] queue = new TreeNode[MAXN]; public static int l, r; public static boolean isCompleteTree(TreeNode root) { if (root == null) { return true; } l = r = 0; queue[r++] = root; // 是否遇到过左右两个孩子不双全的节点 boolean leaf = false; while (l < r) { TreeNode cur = queue[l++]; if ((cur.left == null && cur.right != null) || (leaf && cur.left != null)) { return false; // 这一段代码是用来判断是不是满足上述的两种情况的.} if (cur.left != null) { queue[r++] = cur.left; } if (cur.right != null) { queue[r++] = cur.right; } if (cur.left == null || cur.right == null) { leaf = true; // 判断遇见了两个孩子全不全.} } return true;
}
原来的判断条件是:
if ((cur.left == null && cur.right != null) || (leaf && (cur.left != null || cur.right != null))) { return false;
}上面的代码可以进行简化:
if ((cur.left == null && cur.right != null) || (leaf && cur.left != null)) { return false; // 这一段代码是用来判断是不是满足上述的两种情况的.
} 原理:无论是什么样的情况, 第一个代码执行到(cur.right != null)的时候, 已经判断好了只能是:false, 因为cur.right只有null和非null两种情况, 只要是第一个判断方式没有实现, 那只能说明cur.right 是 null, 这个时候已经不用判断了.
9. 题目九:求完全二叉树的节点个数
要求:需要保证时间复杂度必须低于 O(n).
9.1 逻辑实现
- 首先我们从根节点开始按照最左端的顺序往下遍历, 这样能得到这棵树有几层.
- 然后继续从根节点的右孩子开始遍历, 还是从最左端开始遍历,
- 若是到达了最深层, 说明左边的这棵二叉树一定是满二叉树,
- 此时左树的节点个数是:
2^高度 - 1, 右边我们可以进行递归调用:f(右), - 所以最后的节点个数为:
2^高度 - 1 + 1 + f(右). 最后加一是因为需要加上根节点(对于当前的树来说).
- 此时左树的节点个数是:
- 若是没有到达最深层, 说明右边的这棵二叉树一定是满二叉树, 只是高度不同.
- 说明右树的节点个数位:
2^高度 - 1, 然后我们可以递归调用f(左). - 以最后的节点个数为:
2^高度 - 1 + 1 + f(左). 最后加一是因为需要加上根节点 (对于当前的树来说).
- 说明右树的节点个数位:
当然这里遇见了递归实现, 需要自己去画一下递归逻辑图, 这个是必不可少的.
9.2 代码实例
public static int countNodes(TreeNode head) { if (head == null) { return 0; } return f(head, 1, mostLeft(head, 1));
} // cur : 当前来到的节点
// level : 当前来到的节点在第几层
// h : 整棵树的高度,不是cur这棵子树的高度, h是永远确定了的.
// 求 : cur这棵子树上有多少节点
public static int f(TreeNode cur, int level, int h) { if (level == h) { return 1; } if (mostLeft(cur.right, level + 1) == h) { // cur右树上的最左节点,扎到了最深层 return (1 << (h - level)) + f(cur.right, level + 1, h); } else { // cur右树上的最左节点,没扎到最深层 return (1 << (h - level - 1)) + f(cur.left, level + 1, h); }
} // 当前节点是cur,并且它在level层
// 返回从cur开始不停往左,能扎到几层
public static int mostLeft(TreeNode cur, int level) { while (cur != null) { level++; cur = cur.left; } return level - 1;
}
9.3 时间复杂度分析
这个方法的逻辑实现就是从根节点开始, 选择其中一侧, 遍历这一侧的最左侧的所有节点, 所以假设这棵二叉树的高度为:h, 所以第一次是:h, 第二次是:h - 1 … 最后一次是 0, 所以时间复杂度是:O(h^2), 那么 h = log(n), n为二叉树的节点个数, 所以最后的时间复杂度是:O(log(n)^2), 这个的时间复杂度要比 O(n) 快很多,
比如 n = 2^32, 使用这个方法我们只需要 32^2 = 1024 但是遍历整个二叉树需要 O(2^32), 远远小于 O(n).