原文标题:Source-Free Domain Adaptation for YOLO Object Detection
中文标题:基于 YOLO 目标检测的无源域自适应
论文地址: https://arxiv.org/abs/2409.16538
代码地址: GitHub - vs-cv/sf-yolo

1、Abstract
无源域自适应(source -free domain adaptation, SFDA)是目标检测领域中一个具有挑战性的问题,即在不使用任何源域数据的情况下,将预训练好的源模型适应于新的目标域,以达到保护隐私和提高效率的目的。大多数最先进的 SFDA 目标检测方法都是针对 Faster-RCNN 提出的,Faster-RCNN 是一种已知具有高计算复杂度的检测器。本文重点介绍现实世界视觉系统的域适应技术,特别是以其快速基线和实际应用而闻名的 YOLO 系列单次检测器。本文提出的SFDA方法-无源YOLO (SF-YOLO) 依赖于教师-学生框架,在该框架中,学生接收可学习的、目标域特定增强的图像,允许模型仅使用未标记的目标域数据进行训练,而不需要特征对齐。在没有标签的情况下,使用 mean-teacher 架构进行自训练的一个挑战是,由于噪声或漂移的伪标签,模型准确性会迅速下降。为了解决这个问题,引入了一种师生交流机制(teacher-to-student communication),以帮助稳定训练并减少模型对带注释目标数据的依赖。尽管它很简单,但我们的方法在几个具有挑战性的基准数据集上与最先进的检测器竞争,有时甚至优于使用源数据进行适应的方法。
2、Introduction
2.1、目标检测实际应用面临的挑战
用于目标检测 (OD) 的深度学习模型通过利用大量标记数据显示出令人印象深刻的性能。然而在现实世界的应用中,由于相机捕捉条件(姿势、照明、分辨率、天气)的变化,通常会在源(实验室)和目标(操作)域之间产生数据偏移,从而降低精度。针对目标域微调 OD 模型是有效的,但由于需要收集和注释数据,成本往往太高。
2.2、无监督域自适应技术
1)无监督域自适应(Unsupervised domain adaptation, UDA)是一种利用未标记的目标数据,使在源域上训练好的模型在目标域上表现良好的方法。该方法在不需要对目标数据进行标注的情况下,减轻了域移位引起的精度下降。传统的UDA方法假定可以访问已标记的源数据和未标记的目标数据,但隐私、机密性和后勤方面的挑战可能会阻止对源数据的访问。为了解决这个问题,已经出现了用于OD的无源域自适应(SFDA)方法,允许在没有源域数据的情况下进行自适应,尽管这使得对齐源域和目标域分布更具挑战性。
2)第一种针对OD的UDA方法是针对两级检测器Faster-RCNN提出的。与之前的工作相比,大多数方法都遵循了这一开创性的工作,并且仍然依赖于Faster-RCNN。随着新型检测器的普及,一些工作侧重于开发单级检测器的UDA方法,如FCOS和YOLOv5。然而,较新的SFDA方法仍然使用Faster-RCNN,这可能不再是理想的。尽管一些SFDA策略可能适用于其他检测器,但单阶段模型中缺乏有助于对齐实例级特征的区域提议网络 (RPN),可能会使 UDA 复杂化。此外,UDA的进展往往与OD方法和设计的进展同步。然而,Faster-RCNN有些过时,计算密集且不太适合实时应用。下表显示,没有应用 SFDA,在 Cityscapes 上训练 source only 模型,然后在 Foggy Cityscapes 测试集上进行测试的 mAP 准确性。即使没有UDA,YOLOv5l的速度也要快10倍,性能更好,而YOLOv5s的性能相似,但速度要快15倍。

3)mean-teacher(MT)框架是OD中SFDA的一个突出方法,使用自蒸馏和自我训练。学生和教师模型从相同的初始模型开始,学生通过教师产生的伪标签更新,教师通过过去学生的指数移动平均线(EMA)更新。MT框架假设教师模型可以随着训练的进行而不断改进,学生可以逐渐接近教师的表现。然而由于领域移位,源预训练的教师在应用于目标领域时引入了固有的偏差。这种偏差加上学生的误差积累,往往会导致不稳定,降低两个模型的性能。调整 EMA 超参数以实现学生和教师之间更加渐进和稳定的知识传递有助于稳定训练。由于现实世界的 SFDA 应用通常具有非常有限的测试集,因此理想的方法应该对超参数具有鲁棒性,并且需要最少的调整。
2.3、本文提出针对YOLO的SFDA方法
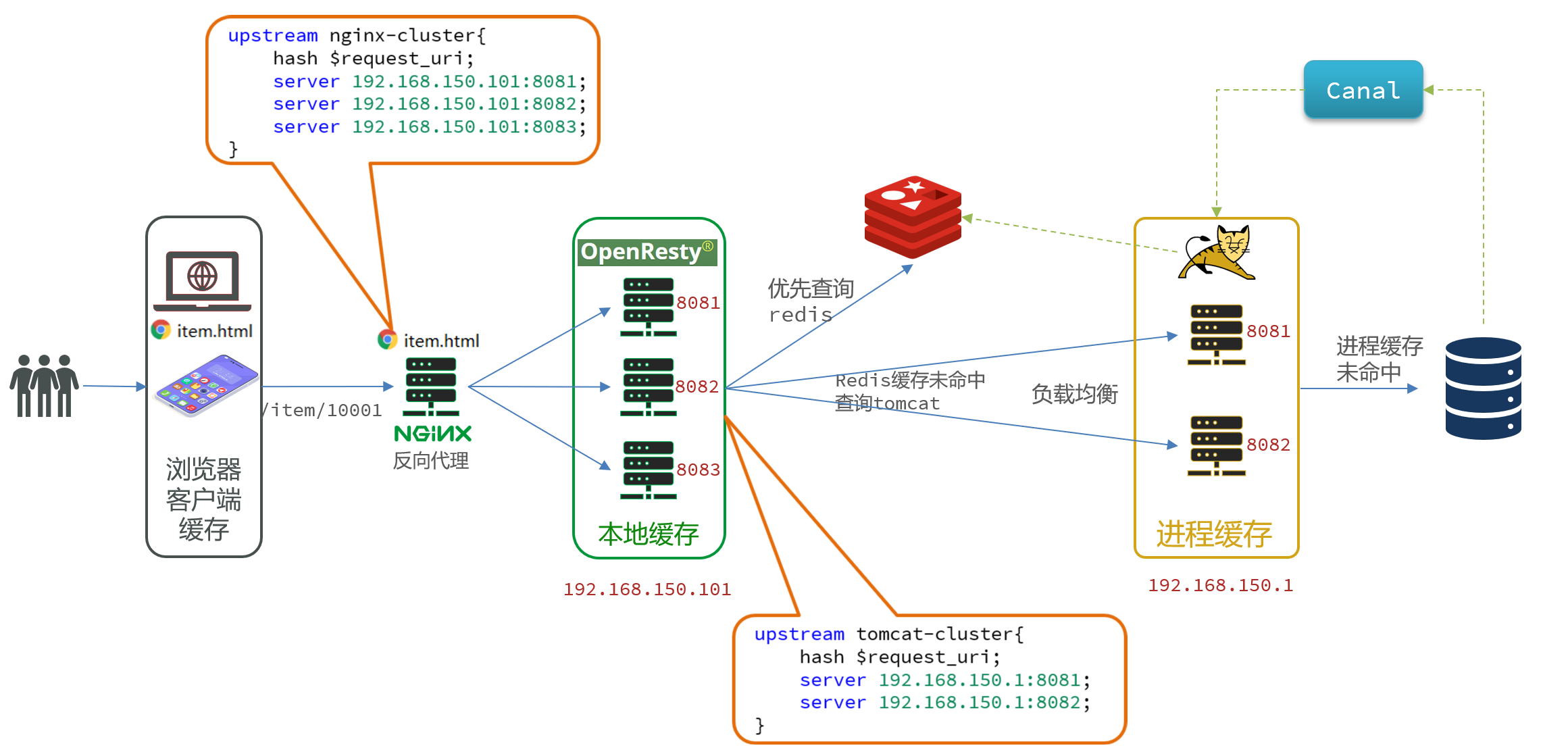
在本文中,我们探索了一个与现有SFDA方法不同的方向。受关于使用YOLO的UDA方法的工作的启发,我们将重点放在Faster-RCNN之外的SFDA上,因为Faster-RCNN很复杂,不适合实时视频监控等实际场景。针对YOLO提出了一种不依赖于特征对齐的SFDA方法,该方法基于具有学习目标领域特定数据增强的MT框架。据我们所知,SFDA 尚未提出针对 YOLO 等单级检测器的方法,其中大多数都集中在 Faster-RCNN。此外我们提出了一种新颖的学生稳定模块(Student Stabilisation Module,SSM)来改进 MT 框架的自我训练范例。如下图 1 所示,SSM 在教师和学生模型之间建立了双向通信通道。与以前的方法(仅通过学生模型更新教师)不同,我们提出的方法定期用教师的移动平均值替换学生。

图 1:提出的 SF-YOLO 训练架构。首先,使用训练集中的所有目标域图像来训练 TAM;然后,这些学习到的增强图像将用作学生的数据增强,而教师则接收未修改的目标域图像。学生检测器通过反向传播进行学习,如4节的公式一所示,然后使用 EMA 更新每个批次的教师检测器。最后,以较低的频率,每个 epoch 一次,老师用 SSM 更新学生以稳定训练。
2.4、本文贡献
(1) 我们引入了 Source-Free YOLO (SF-YOLO),这是第一个专门针对单级 YOLO 检测器的 SFDA 方法,为未来针对实际实时应用的研究建立了基线。我们提出的 SF-YOLO 方法利用了一个师生框架,该框架具有可学习的目标域特定增强模块,该模块允许仅使用未标记的目标域数据进行训练,而不需要特征对齐。
(2) 提出了学生稳定模块(SSM),以减轻使用平均教师范式时由于缺乏标记数据而导致的训练不稳定和相关准确性下降。它提供了从教师到学生的新沟通渠道,增强了训练稳定性,从而减少了模型对带注释的目标数据的依赖。
(3) 大量实验表明,我们提出的YOLO SFDA方法在 Cityscapes、Foggy Cityscapes、Sim10k和KITTI数据集的几个具有挑战性的领域适应基准上是有效的。 我们使用YOLOv5模型的两个变体来评估我们的方法(一个更精确但更大的模型和一个更小的效率模型)。我们的方法优于最先进的检测器,并且只需较少的计算资源,可以与需要源数据进行适应的UDA方法取得竞争性能。
3、Related Work
3.1、Unsupervised Domain Adaptation(无监督域适应)
UDA 旨在使用标记的源数据和未标记的目标数据来调整源模型,使其在目标(操作)域中表现良好。用于 OD 的 UDA 方法涵盖分类和定位任务,通常分为对抗性特征学习、领域翻译或自我训练。
1)对抗方法使用域鉴别器和对抗训练来混淆源域和目标域之间的模型,从而产生域不变的表示。有研究首先介绍了图像和实例级对抗性特征对齐。有研究通过强局部和弱全局特征对齐来完善这一点,两者都采用对抗性技术。基于这些想法,一些作品专注于实例级对齐,强调包含感兴趣对象的区域。与对抗性图像或实例级对齐方法相比,有人提出了一种使用FCOS检测器的中心感知特征对齐方法。
2)领域翻译方法通常使用图像到图像的翻译方法,如 CycleGAN、AdaiN、FDA 或 CUT 通过生成类似目标域的源图像或类似源域的目标图像来学习领域不变表示。
3)自训练方法通常使用伪标签策略对目标域中的模型进行监督微调,但不正确的伪标签会降低性能。因此有研究建议使用弱自训练方法来缓解这种情况,有研究使用附加分类器调整带有噪声的注释。为了防止师生崩溃,有研究添加了额外的域对齐损失来区分学生和教师模型。然而上述方法均无法满足日益增长的数据隐私保护需求,SFDA 已成为 UDA 的一个新分支。
3.2、Source-Free Domain Adaptation(无源域适应)
1)SFDA 仅使用未标记的目标数据来调整在已标记源数据上预训练的源模型,通过传输模型而不是广泛的源域数据来解决隐私问题。SFDA 的 OD 方法主要使用 MT 和伪标记策略。SFDA 微调方法的一个关键挑战是它们对嘈杂的伪标签的依赖,由于不准确的伪标签会降低模型的准确性,有研究首先通过使用自适应熵最小化方法确定一个可以消除不可靠伪标签的阈值来解决这个问题。有研究通过调整每个类的阈值和提高伪标签的定位质量对其进行了改进。A2SFOD通过检测方差划分目标域来处理噪声标签。有研究使用自监督学习通过历史模型和对比学习来学习特征表示。还有研究采用实例关系图网络和对比损失来增强目标表示。有研究认为现有的 SFDA 方法没有充分利用目标域数据,限制了其有效性。为了解决这个问题,有人提出了 LODS,通过增强目标域图像的风格并使用原始图像和增强图像之间的风格差异作为自适应的自监督信号来减少模型对领域风格的关注。大多数方法依赖于机器翻译架构,该架构容易不稳定,限制了它们所能达到的性能。
2)与本文的方法密切相关的是,有人引入了PETS,它在每个时期交换教师和学生模型,同时保持一个额外的EMA教师。然而PETS 需要额外的模型并依赖于加权融合,这增加了复杂性。总的来说,虽然提到的方法使用 Faster R-CNN,但我们引入了一种新的 YOLO SFDA 方法以及我们的 SSM,为实际应用提供更稳定的训练和改进的性能。在本文中,我们关注机器翻译架构,并使用前人提出的可学习数据增强方法,该方法利用目标域数据,而不是典型的强弱增强对。此外,我们通过引入教师与学生的沟通机制来稳定训练,解决了MT在缺乏标记数据的情况下的训练不稳定性,这在缺乏验证数据的SFDA中至关重要。通过我们的消融表明,我们提出的方法显着提高了MT框架的准确性,同时保持简单和直接。
3.3、UDA for YOLO(针对YOLO的无监督域适应)
Faster-RCNN 是一个两阶段目标检测模型,具有用于分类和定位的单独分支。这对于 UDA 来说很方便,特别是对于特征对齐。 然而由于其计算复杂度较高,它很少用于需要实时处理的工业应用中。为了创建更适合实时任务的 UDA 方法,一些工作专注于 YOLO 检测器。SFDA 的 YOLO 方法可分为特征对齐方法和基于数据的方法。
1)在特征对齐方法中,MS-DAYOLO使用多尺度图像级自适应但不进行局部对齐,这是有效的。DA-YOLO通过利用图像级和实例级特征对齐来解决这个问题,使用 YOLO 三尺度特征图上的检测层来替换 RPN。有人使用注意力机制来识别应该执行自适应的前景区域,以此取代 RPN。CAST-YOLO 也采用了注意力机制,但只用于在 MT 架构中对齐源特征和目标特征。SSDA-YOLO 使用 MT 框架将图像到图像的转换和特征对齐相结合,利用 CUT 生成类似源的目标图像,反之亦然。来自教师模型的伪标签支持实例级对齐,并且一致性损失可以跨域对齐预测。然而在我们的 SFDA 范式中,由于缺乏源数据,依赖于源域和目标域之间特征对齐的方法(例如对抗性学习)并不直接适用。
2)基于数据的方法,更多地关注数据增强。ConfMix 引入了一种样本混合策略,以最高的检测置信度将一个源图像与目标图像的裁剪相结合;他们还在训练过程中使用具有可变阈值的伪标签策略。SimROD 引入了DomainMix,它将标记的源图像与未标记的目标图像及其伪标签混合在一起,由大型教师模型生成。
据我们所知,目前还没有针对SFDA提出基于yolo的方法。因此我们提出了一种方法,该方法也使用数据增强来适应而不是特征对齐,并且不依赖于特定的体系结构,使其更加通用。
4、Proposed Method
令 Ds = (Xs, Ys) 表示源域中的标记数据,其中 Xs = {xis}Nsi=1 表示源域的图像集,Ys = {yis}Nsi=1 是相应的标签集,包含每个图像的目标位置和类别分配的集合。 Ns 表示源图像的总数。Dt = (Xt) 表示目标域中的未标记数据,Xt = {xit}Nti=1 表示该域的 Nt 个图像。在SFDA中,源预训练模型表示为hs: Xs→Ys,最初可用于对未标记的目标域进行自适应。然而考虑到源域和目标域之间的域转移,当源预训练模型hs直接应用于目标域时,映射会降低性能。因此,SFDA的主要目标是通过仅使用未标记的目标数据Xt来适应预训练的源模型hs,从而学习新的映射ht: Xt→Yt。
使用 mean-teacher 范式,教师(定义为hθ)和学生(定义为hϕ)模型都是从源模型(一个预训练的YOLOv5架构)实例化的。训练损失如下表示:
![]()
其中,Lbox和Lcls分别表示分类和边界框回归的损失,而Lobj对应客观性损失,与目标存在的置信度有关。λb、λc、λd 项是加权超参数,用于控制总体检测损失中每个损失分量的相对重要性。
我们的框架分为两个步骤。首先,训练目标增强模块学习针对目标域的特定领域的数据增强。然后,使用已增强的图像来训练具有平均教师范式的学生模型。学生模型 hφ 逐渐将其获得的知识提炼给教师模型 hθ,教师模型 hθ 通过指数移动平均线(EMA)进行学习。我们还引入了学生稳定模块(SSM),可以有效稳定训练过程,从而提高整体表现。该框架不会增加基本检测器在推理过程中的复杂性,这对于许多实时应用程序来说是一个重要因素。整个 SF-YOLO 训练架构如2.3节中的图 1 所示,并在算法 1 中详细说明。
4.1、Target Augmentation Module(目标增强模块)
在经典的师生框架自我训练中,教师和学生模型将不同的图像视图作为输入,以一种不平凡的方式最大化相互信息。具体来说,教师模型接收弱增强图像作为输入,而学生模型则输入强增强图像。在这里,我们不是生成随机的强弱增强图像对,而是使用一个名为“目标增强模块”(TAM)的网络来学习适当的增强。这个增强模块与LODS方法中的风格增强模块类似,主要区别在于动机。我们使用增强模块来丰富目标域,而在LODS中使用样式增强模块来学习忽略目标域的样式。这里我们简要概述TAM的主要体系结构。
假设我们有来自目标域的图像(用 x 表示)和风格图像 y,它可以是目标域所有图像的平均值(如果背景相似),或者是目标域中的一张随即图像。
TAM的作用是将目标域图像 x 根据风格图像 y 的统计特征进行转换,以生成新的增强图像。风格迁移公式如下:

其中,ex和ey分别是图像 x 和 y 通过VGG-16网络编码得到的特征。µ(ex)和σ(ex)表示ex的通道均值和通道方差,ey也是如此。F1 和 F2 是两个神经网络,它们结合了 x 和 y 的均值和方差信息。TAM通过最小化风格一致性和重建损失来进行训练,以确保转换后的图像既保持了原始图像的内容,又融入了风格图像 y 的风格特征。
4.2、Consistency Learning With Teacher Knowledge(教师知识的一致性学习)
对于目标域 Dt 中的每个数据点 x,我们从教师模型中获取目标分类分数 hclsθ(x)、边界框回归 hboxθ(x) 和是否存在目标的置信度 hobjθ(x),并将其用作伪标签通过反向传播训练学生模型。然而,直接从 hθ(x) 学习可能会导致对教师模型的过度拟合。为了解决这个问题,我们引入了由三个步骤组成的一致性损失。首先,我们通过设置分类置信度阈值δ来过滤掉教师模型的低置信度预测,这样可以防止后续过程受到噪声标签的干扰。接下来,我们使用 TAM 增强目标域图像 x 并训练学生模型,使其与增强样本的硬标签 p(由教师模型生成的伪标签)一致。第三,学生逐渐将其获得的知识提炼到教师模型中,教师模型通过指数移动平均线(EMA)进行学习:
![]()
其中,θ 表示教师模型的参数,ϕ 表示学生模型的参数,α 是EMA动量参数,它控制着教师模型参数更新的速度。
4.3、Student Stabilisation Module(学生稳定模块)
请注意,教师从不直接观察增强图像,它只处理真实的目标图像。到目前为止,我们的方法类似于Mean Teacher and Noisy Student 范式。然而,由于学生模型学习速度更快,因此更容易出错。学生更新教师后,这些错误又会反映在教师模型的伪标签生成中,导致伪标签噪音更大,从而降低之后训练的性能。为了减轻这些错误的影响,引入了学生稳定模块 (SSM)。正如我们在下图2中使用TAM模块的mean-teacher框架初始实验所示,尽管EMA和学习增强有助于提高学生模型的性能,但结果迅速恶化,以至于在epoch 60时,学生模型的性能几乎就像一个随机检测器。可以发现,SSM可以有效防止MT快速恶化并达到更好的最终性能。

图2:使用 YOLOv5l 在不同学习率的 C2F 场景上使用和不使用 SSM 的目标增强平均教师的训练曲线。
我们假设,由于学生模型在每批之后使用SGD快速更新,因此更有可能出错。虽然一位更新了ema的教师最初可以防止学生过度拟合,但这可能不足以稳定训练。于是作为在每个epoch结束时的补救措施,我们还使用教师模型的EMA更新学生权重,使用以下公式:
![]()
其中,其中γ为SSM动量参数。这种方法将学生模型限制在接近教师模型的范围内,保持了伪标签的质量,并防止有过多的偏差。
4.4、Training and Inference(训练与推理)
SF-YOLO的整体学习过程如图1所示。经过调整优化的教师模型hθ用于推理,教师模型学习到的特征表示比学生模型(hϕ)更为鲁棒,这是因为学生模型在训练过程中没有直接接触到未经修改的目标域图像(原始目标域图像),而教师模型则通过指数移动平均(EMA)和学生模型的更新来不断调整自己的参数,以更好地适应目标域数据。 最终模型保持了原始YOLO架构的速度和兼容性优势。
4.5、训练流程
输入:目标域 Dt、教师模型 hθ、学生模型 hϕ、目标增强模块 TAM、EMA 动量 α、SSM 动量 γ、置信度阈值 δ、学习率 η、总迭代次数 E。
输出:训练完成的教师模型 hθ,用于目标域的推理。
一、外层循环:遍历所有的训练周期(从 t=0 到 E-1),对于每个周期,执行以下步骤:
二、内层循环:遍历目标域数据集 Dt 中的每个小批量数据 x,对 Dt 中的每个小批量 x
1)p = hobjθ(x) ≥ δ,计算教师模型对当前小批量数据 x 的置信度 hobjθ(x),并与阈值 δ 比较,生成过滤后的伪标签 p。
2)xˆ = TAM(x),使用目标增强模块 TAM 对当前小批量数据 x 进行增强,得到增强后的图像xˆ;。
3)ϕ ← ϕ − η∇ϕLdet(xˆ, p, ϕ),使用增强后的图像xˆ 和伪标签 p 训练学生模型 hϕ,通过反向传播更新学生模型的参数 ϕ;。
4)θ ← αθ + (1 − α)ϕ,结合当前教师模型的参数和学生模型的参数,使用EMA更新教师模型的参数 θ。
三、ϕ ← γϕ + (1 - γ)θ,处理完一个周期内所有小批量数据后,使用学生模型稳定模块(SSM)来更新学生模型的参数 ϕ,以保持学生模型和教师模型之间的一致性。
5、Results and Discussion(结果与讨论)
5.1、Experimental Methodology(实验方法)
5.1.1数据集
使用了以下四个数据集:Cityscape、Fog Cityscape、KITTI和Sim10k。
5.1.2适应场景
继之前的工作之后,对三种不同的基准场景进行了实验:
城市景观→有雾的城市景观(C2F)用于正常天气到恶劣天气的适应,
KITTI→城市景观(K2C)来解决跨摄像机适应问题,
Sim10K→ Cityscapes (S2C) 来评估合成到真实的适应能力。
由于在Sim10k数据集中只有汽车被注释,我们只考虑S2C和K2C场景的汽车AP,而对于C2F场景,我们使用完整的 8 个类。
5.1.3实现细节
我们优先考虑一个现实的设置,使用YOLOv5,一个广泛采用和高效的一级检测器。我们与同样使用YOLOv5的基线UDA方法进行了初步比较。首先,我们使用与 LODS 作者提出的相同参数训练TAM,使用Adam优化器,学习率为0.0001和冻结预训练的VGG16编码器。该模块被冻结并用于转换目标图像,作为学生检测模型的数据增强,冻结意味着VGG16编码器的参数在训练过程中不会更新。对于源模型训练,我们使用默认的 YOLOv5l 设置并训练最多 200 个 epoch。对于我们的 SF-YOLO 适应,我们将批量大小设置为 16 并训练 60 个 epoch,图像大小调整为960×960,伪标签生成NMS IoU阈值设置为0.3,这意味着在生成伪标签时,只有当预测框和真实框的IoU大于0.3时,预测框才会被保留。教师伪标签置信度阈值 δ = 0.4,这意味着只有当教师模型对其预测的置信度高于40%时,这些预测才会被用作学生模型训练的伪标签。EMAϕ→θ 的 α 设置为 0.999,SSM 模块使用的 γ 设置为 0.5。其他超参数是YOLOv5使用的默认超参数。 这包括使用 SGD 和动量优化器设置为 0.01 的学习率。 我们使用目标域数据集的验证集,报告 IoU 阈值设置为 0.5 的平均精度 (mAP)。
5.2、Comparison with State-of-the-Art Methods(与最先进方法的比较)
下表 2 和表 3 中的结果显示了基于 Faster-RCNN 的最先进的 SFDA 方法的性能。然而,由于我们是第一个针对 YOLO 提出 SFDA 范式并旨在为未来研究建立基线的人,因此将 SF-YOLO 与基于 YOLOv5 的经典 UDA 方法进行了比较。请注意,这些 UDA 方法同时访问标记的源数据和未标记的目标数据,而我们的方法仅使用未标记的目标数据。尽管这种设置更具挑战性,但我们通过 UDA 方法实现了具有竞争力的性能,这表明源数据可能没有得到充分利用。我们还与 PETS 进行比较,PETS 是一种最初基于 Faster RCNN 的 SFDA 方法,我们重新实现了它(因为我们找不到公共代码)。我们在无源列中指出了适应过程中源数据的使用。Source Only 和 Oracle(上限)分别使用带标签的源数据和目标数据进行训练。

表2:SF-YOLO 在 C2F 场景中与最先进的 UDA 和 SFDA 方法的比较。我们报告每个类别的 AP50 和 mAP。适应过程中源数据的使用由Source-free列表示。粗体和下划线的结果代表最好和第二好的结果。我们在所有场景中使用默认的 SSM 动量 γ,并且还包括具有优化 γ 的 SF-YOLO†。对于 PETS,我们使用了 YOLO 上的实现,因为我们找不到公开的实现。

表3:我们的 SF-YOLO 和最先进的 SFDA 方法在 K2C 和 S2C 场景下的 AP 准确性。
下图显示了source only模型、CAST-YOLO 和 SF-YOLO 的视觉检测结果。每种颜色代表一个类别,我们的方法在定性上表现出与 CAST-YOLO 相当的性能,但我们在适应阶段没有使用标记的源数据。我们的 SF-YOLO 方法更好地适应特定领域,检测小而模糊的物体。

5.3、Ablation Studies(消融实验)
本节通过YOLOv5l分析TAM和SSM在C2F场景中的重要性。它表明,与随机数据增强相比,学习增强提供了更大的好处。它还表明,SSM 的行为与其他用于控制学生和教师之间权重一致性的正则化技术不同。 此外,在我们的设置中发现对齐是不必要的,并且 SSM 与其他架构兼容,例如 Faster R-CNN。 有关 YOLOv5 的类似消融,请参阅补充材料。 材料。
5.3.1、Learned Augmentation vs Random Augmentation(学习增强vs随机增强)
我们将TAM与弱-强随机增强进行比较。对教师模型处理的图像进行弱增强(图像翻转、几何变换),对输送给学生模型的图像进行强增强(如颜色抖动、随机化灰度、模糊),提高整体泛化能力。从表4中我们可以看到,虽然两种技术都提高了性能,但学习增强提供了更高的收益,因为它是特定于目标数据集的。

5.3.2、SSM vs Learning Rate(SSM vs学习率)
控制师生分歧的一种直观方法是限制学生的学习速度。在下图a中,我们在一定的学习率范围内展示了我们的方法在没有SSM的训练迭代中的模型性能。正如我们所看到的,优化学习率确实会影响最好的可能结果。 然而在达到最佳表现后,准确率迅速下降,这表明单独的学习率无法控制学生和教师模型之间的漂移。

5.3.3、SSM vs L2 between student and teacher(SSM vs 学生和老师之间的L2)
灾难性遗忘是我们可以分析学生模型和教师模型之间漂移的另一个角度。在持续学习或域适应的场景中,当模型学习新任务时,可能会迅速忘记先前任务的知识,这种现象被称为“灾难性遗忘”。在域适应的背景下,这可能导致学生模型在适应目标域数据时,失去了源域数据上学习到的有用信息。弹性权重巩固(EWC)是持续学习中克服灾难性遗忘的一种流行方法,其中基于某些权重对先前见过的任务的重要性,对某些权重的学习速度较慢。最初的EWC要求根据源域的数据创建Fisher信息矩阵,以确定哪些权重对先前任务更重要;然而在无源域自适应(SFDA)场景中,源域数据是不可用的,因此无法直接使用传统的EWC方法。我们使用简化的 EWC 版本,将 Fisher 信息矩阵近似为一个对角高斯先验分布来简化计算,其中均值等于教师模型的参数,方差为1/λ。这种方法不需要源域数据,而是依赖于教师模型的参数来估计权重的重要性。在简化版的EWC中,会引入一个惩罚项来控制权重更新的速度,公式如下:
![]()
其中,λ是一个调节参数,控制着惩罚项的强度;ϕ是学生模型的参数,θ是教师模型的参数。这个惩罚项的作用是减缓那些对教师模型(即先前任务)重要的权重参数的更新速度。
下图b显示了我们在不同λ值下的实验。首先,我们可以看到,最佳性能对λ的选择非常敏感,在某些情况下,错误的值可能会大大降低性能。其次,考虑到表现最佳的λ, SSM和L2具有互补效应,其中整体最佳模型是两者的组合。然而,表2和表3所采用的方法并没有将L2和SSM结合起来。尽管这种组合产生了最佳性能,但它需要大量的超参数调优。在实际的SFDA场景中,对目标数据中的标签的访问是有限的,进行这样的调优是不切实际的。 因此,我们选择排除这种组合,而采用更适合实际部署的免调优SSM方法。

5.3.4、Delaying mean-teacher(推迟更新苛刻的老师)
下图c显示了我们的方法在不同EMAϕ→θ动量值α下的性能。我们的直觉是,如果学生过于频繁地更新老师的信息,那么学生就没有足够的时间来学习目标数据的鲁棒表示,这可能会给老师带来更多的噪音。因此我们选择了一个小的α值。通过每个epoch而不是每批更新一次教师,我们观察到训练变得更加稳定。然而与学习率和L2相似,最佳性能对λ的选择非常敏感。此外,对于表现最佳的λ,我们可以观察到与SSM的互补效应。

5.3.5、Hyper-parameters sensitivity(超参数的敏感性)
根据图5所示的结果,可以观察到SSM在不同数据集的广泛γ值范围内产生相对稳定的结果。正如预期的那样,调整伽马参数可以提高训练的稳定性和整体性能。然而无论使用何种伽马值,SSM都提供了训练稳定性,并且通常优于默认的MT设置。这突出了无调优SSM在SFDA中实现接近最佳性能的重要性。

5.3.6、Feature alignment(特征对齐)
UDA方法通常使用源域和目标域的特征对齐,通过提取域不变特征来提高泛化。尽管由于缺乏源域数据,SFDA不允许直接的特征对齐,但我们的SF-YOLO框架使用了TAM。该模块允许创建伪域Daug = (Xaug) = {TAM(xit)}Nti=1,表示目标域Dt的增强版本。我们的研究结果表明,在我们的SFDA设置中,将目标域特征与其增强的对应物对齐并不能提高性能。因此,我们选择不使用特征对齐来保持我们的方法更简单。
5.3.7、Faster R-CNN
为了显示SSM与YOLO以外的其他架构的兼容性,我们将SSM应用于IRG,这是使用Faster R-CNN架构的SOTA方法之一。下表显示了SSM与Faster-RCNN的兼容性。使用SSM可以在所有场景中显著提高性能。它允许基于Faster-RCNN的SFDA方法在K2C上实现SOTA精度,在C2F和S2C场景下分别达到第二和第三。虽然上述方法可以减少漂移,但SSM在大多数情况下表现更好,并且需要最小的微调,这对SFDA至关重要。此外,我们发现特征对齐在我们的设置中是不必要的,并且我们提出的SSM与其他架构(如Faster R-CNN)兼容。

6、Conclusion
本文提出了首次使用YOLO系列单发探测器的SFDA方法。本文方法采用了一个带有学习的、目标领域特定的增强和一种新的通信机制的师生框架来稳定训练,减少了对模型选择中带注释的目标数据的依赖,这对现实世界的应用至关重要。SF-YOLO 优于所有基于Faster R-CNN的SFDA方法,甚至一些使用源数据的基于UDA yolo的方法。我们提出了SSM,它是 MT 框架的一个简单补充,可以提高性能和稳定性。大量实验表明,SSM与现有的知识保存技术的兼容性。SSM成功背后的主要假设在于学生和教师之间的在线知识蒸馏,这可以防止由噪声伪标签引起的模型漂移。SSM特别适合于无源(无监督)学习场景,与传统的半/弱/无监督学习不同,这些场景既不能访问源数据,也不能访问目标域的标记数据,以确保模型的稳定性,并防止训练过程中出现明显的漂移。












![[计算机网络]第一周](https://i-blog.csdnimg.cn/direct/bf2fa6ded5d843a5985e18ba39521b5e.png#pic_center)