本文目录结构
1、背景
2、推荐系统初识
3、通用推荐系统架构
4、经典推荐算法
5、实现一个推荐系统
6、存在问题与展望
1、背景
近期由于公司业务系统需要做一个推荐系统,应该说是实现一个相当简单推荐逻辑。毕竟业务场景相当简单,企业的数据规模也比较小,各种用户数据、交易数据、订单数据、行为数据等加在一起100多TB量级,这点数据量在巨大的平台商面前都谈不数据规模。数据级量小,业务场景也简单,实现起比较的容易,但原理基本上大同小异。
本文尝试从最简单的推荐入手,我们暂不去讨论大规模数据分析和算法。更多从软件工程角度思考问题,那些高大上算法留给读者去思考。
下面就来谈谈整个推荐的设计实现过程。
2、推荐系统介绍
2.1、为什么需要推荐系统?
首先推荐系统作用是很大的。推荐系统在很多业务场景有广泛使用和发挥的空间,它的应用和影子无处不在,在多媒体内容、广告平台和电商平台尤为常见。大多平台商或企业都是基于大数据算法分析做推荐系统。推荐算法也是层出不穷,比如相似度计算、近邻推荐、概率矩阵分解、概率图等,当然也有综合多种算法融合使用。
互联网时代,数据呈爆炸式增长,前所未有的数据量远远超过受众的接收和处理能力,因此,从海量复杂数据中有效获取关键性有用信息成为必须解决的问题。
面对信息过载问题,人们迫切需要一种高效的信息过滤系统,“推荐系统”应运而生。
20世纪90年代以来,尽管推荐系统在理论、方法和应用方面取得了系列重要进展,但数据的稀疏性与长尾性、用户行为模式挖掘、可解释性、社会化推荐等问题仍然是其面临的重要挑战。
进一步地,伴随互联网及信息技术的持续飞速发展,用户规模与项目数量急剧增长,相应地,用户行为数据的稀疏性、长尾性问题更加凸显。也就是说目前各大平台虽然已经推荐系统,但是实际应用当中还是面临很多问题,仍然有很大的提升空间。这是技术挑战也机会,当然这也是我们这些从业者可以发挥的地方。
2.2、推荐系统解决什么问题?
推荐系统从20世纪90年代就被提出来了,但是真正进入大众视野以及在各大互联网公司中流行起来,还是最近几年的事情。
随着移动互联网的发展,越来越多的信息开始在互联网上传播,产生了严重的信息过载。因此,如何从众多信息中找到用户感兴趣的信息,这个便是推荐系统的价值。精准推荐解决了用户痛点,提升了用户体验,最终便能留住用户。
推荐系统本质上就是一个信息过滤系统,通常分为:召回、排序、重排序这3个环节,每个环节逐层过滤,最终从海量的物料库中筛选出几十个用户可能感兴趣的物品推荐给用户。
推荐系统的分阶段过滤流程如下图所示:

2.3、推荐系统应用场景
哪里有海量信息,哪里就有推荐系统,我们每天最常用的APP都涉及到推荐功能:
- 资讯类:今日头条、腾讯新闻等
- 电商类:淘宝、京东、拼多多、亚马逊等
- 娱乐类:抖音、快手、爱奇艺等
- 生活服务类:美团、大众点评、携程等
- 社交类:微信、陌陌、脉脉等
实际例子还有很多,稍微上一点规模的平台或APP都有这一个推荐模块。
推荐系统的应用场景通常分为以下两类:
- 基于用户维度的推荐:根据用户的历史行为和兴趣进行推荐,比如淘宝首页的猜你喜欢、抖音的首页推荐等。
- 基于物品维度的推荐:根据用户当前浏览的标的物进行推荐,比如打开京东APP的商品详情页,会推荐和主商品相关的商品给你。
2.4、搜索、推荐、广告三者的异同
搜索和推荐是AI算法最常见的两个应用场景,在技术上有相通的地方。
- 搜索:有明确的搜索意图,搜索出来的结果和用户的搜索词相关。
- 推荐:不具有目的性,依赖用户的历史行为和画像数据进行个性化推荐。
- 广告:借助搜索和推荐技术实现广告的精准投放,可以将广告理解成搜索推荐的一种应用场景,技术方案更复杂,涉及到智能预算控制、广告竞价等。
3、推荐系统通用框架
推荐系统涉及周边和自己模块还是比较多,这里主要从最简单推荐系统自身功能去构思设计简单结构。

上面这个图基本把推荐处理过程画出来,结构比较清晰,看图理想即可。
从分层架构设计视角来说可以分成多层架构形式
分层:排序层、过滤层、召回层、数据存储层、计算平台、数据源。
可以说市面上推荐系统设计都是差不多是这个样子,只是里面使用技术或组件不同而已。

上面是推荐系统的整体架构图,自下而上分成了多层,各层的主要作用如下:
- 数据源:推荐算法所依赖的各种数据源,包括物品数据、用户数据、行为日志、其他可利用的业务数据、甚至公司外部的数据。
- 计算平台:负责对底层的各种异构数据进行清洗、加工,离线计算和实时计算。
- 数据存储层:存储计算平台处理后的数据,根据需要可落地到不同的存储系统中,比如Redis中可以存储用户特征和用户画像数据,ES中可以用来索引物品数据,Faiss中可以存储用户或者物品的embedding向量等。
- 召回层:包括各种推荐策略或者算法,比如经典的协同过滤,基于内容的召回,基于向量的召回,用于托底的热门推荐等。为了应对线上高并发的流量,召回结果通常会预计算好,建立好倒排索引后存入缓存中。
- 融合过滤层:触发多路召回,由于召回层的每个召回源都会返回一个候选集,因此这一层需要进行融合和过滤。
- 排序层:利用机器学习或者深度学习模型,以及更丰富的特征进行重排序,筛选出更小、更精准的推荐集合返回给上层业务。
从数据存储层到召回层、再到融合过滤层和排序层,候选集逐层减少,但是精准性要求越来越高,因此也带来了计算复杂度的逐层增加,这个便是推荐系统的最大挑战。
其实对于推荐引擎来说,最核心的部分主要是两块:特征和算法。

这些工具和技术框架都是比较成熟稳定的,是众多厂商在实际业务场景中选择应用的。所以也没有太多特殊的地方。
特征计算由于数据量大,通常采用大数据的离线和实时处理技术,像Spark、Flink等,然后将计算结果保存在Redis或者其他存储系统中(比如HBase、MongoDB或者ES),供召回和排序模块使用。
召回算法的作用是:从海量数据中快速获取一批候选数据,要求是快和尽可能的准。这一层通常有丰富的策略和算法,用来确保多样性,为了更好的推荐效果,某些算法也会做成近实时的。
排序算法的作用是:对多路召回的候选集进行精细化排序。它会利用物品、用户以及它们之间的交叉特征,然后通过复杂的机器学习或者深度学习模型进行打分排序,这一层的特点是计算复杂但是结果更精准。
4、经典算法
了解了推荐系统的整体架构和技术方案后,下面带大家深入一下算法细节。这里选择图解的是推荐系统中的明星算法:协同过滤(Collaborative Filtering,CF)。
对于很多同学来说,可能觉得 AI 算法晦涩难懂,门槛太高,确实很多深度学习算法的确是这样,但是协同过滤却是一个简单同时效果很好的算法,只要你有初中数学的基础就能看懂。
4.1、协同过滤是什么?
协同过滤算法的核心就是「找相似」,它基于用户的历史行为(浏览、收藏、评论等),去发现用户对物品的喜好,并对喜好进行度量和打分,最终筛选出推荐集合。它又包括两个分支:
- 基于用户的协同过滤:User-CF,核心是找相似的人。比如下图中,用户 A 和用户 C 都购买过物品 a 和物品 b,那么可以认为 A 和 C 是相似的,因为他们共同喜欢的物品多。这样,就可以将用户 A 购买过的物品 d 推荐给用户 C。
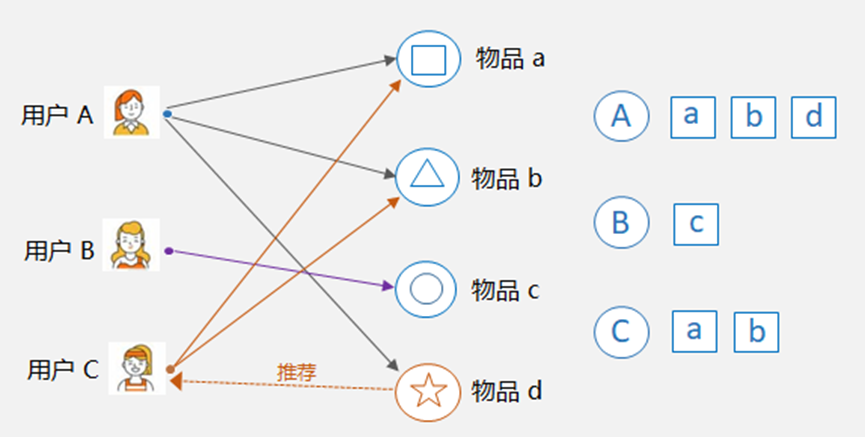
基于用户的协同过滤示例
- 基于物品的协同过滤:Item-CF,核心是找相似的物品。比如下图中,物品 a 和物品 b 同时被用户 A,B,C 购买了,那么物品a 和物品 b 被认为是相似的,因为它们的共现次数很高。这样,如果用户 D 购买了物品 a,则可以将和物品 a 最相似的物品 b 推荐给用户 D。
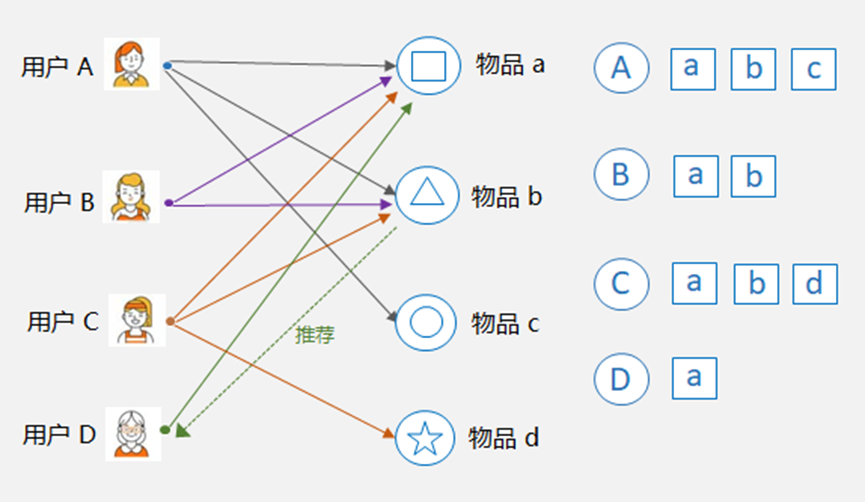
4.2、如何找相似?
协同过滤的核心就是找相似,User-CF是找用户之间的相似,Item-CF是找物品之间的相似,那到底如何衡量两个用户或者物品之间的相似性呢?
我们都知道,对于坐标中的两个点,如果它们之间的夹角越小,这两个点越相似。
这就是初中学过的余弦距离,它的计算公式如下:

举个例子,A坐标是(0,3,1),B坐标是(4,3,0),那么这两个点的余弦距离是0.569,余弦距离越接近1,表示它们越相似。

除了余弦距离,衡量相似性的方法还有很多种,比如:欧式距离、皮尔逊相关系数、Jaccard 相似系数等等,这里不做展开,只是计算公式上的差异而已。
4.3、Item-CF的算法流程
清楚了相似性的定义后,下面以Item-CF为例,详细说下这个算法到底是如何选出推荐物品的?
4.3.1 、整理物品的共现矩阵
假设有 A、B、C、D、E 5个用户,其中用户 A 喜欢物品 a、b、c,用户 B 喜欢物品 a、b等等。

所谓共现,即:两个物品被同一个用户喜欢了。比如物品 a 和 b,由于他们同时被用户 A、B、C 喜欢,所以 a 和 b 的共现次数是3,采用这种统计方法就可以快速构建出共现矩阵。
4.3.2、 计算物品的相似度矩阵
对于 Item-CF 算法来说,一般不采用前面提到的余弦距离来衡量物品的相似度,而是采用下面的公式:

其中,N(u) 表示喜欢物品 u 的用户数,N(v) 表示喜欢物品 v 的用户数,两者的交集表示同时喜欢物品 u 和物品 v 的用户数。
很显然,如果两个物品同时被很多人喜欢,那么这两个物品越相似。
基于第1步计算出来的共现矩阵以及每个物品的喜欢人数,便可以构造出物品的相似度矩阵:

4.3.2、 推荐物品
最后一步,便可以基于相似度矩阵推荐物品了,公式如下:

其中,Puj 表示用户 u 对物品 j 的感兴趣程度,值越大,越值得被推荐。
N(u) 表示用户 u 感兴趣的物品集合,S(j,N) 表示和物品 j 最相似的前 N 个物品,Wij 表示物品 i 和物品 j 的相似度,Rui 表示用户 u 对物品 i 的兴趣度。
上面的公式有点抽象,直接看例子更容易理解,假设我要给用户 E 推荐物品,前面我们已经知道用户 E 喜欢物品 b 和物品 c,喜欢程度假设分别为 0.6 和 0.4。
那么,利用上面的公式计算出来的推荐结果如下:
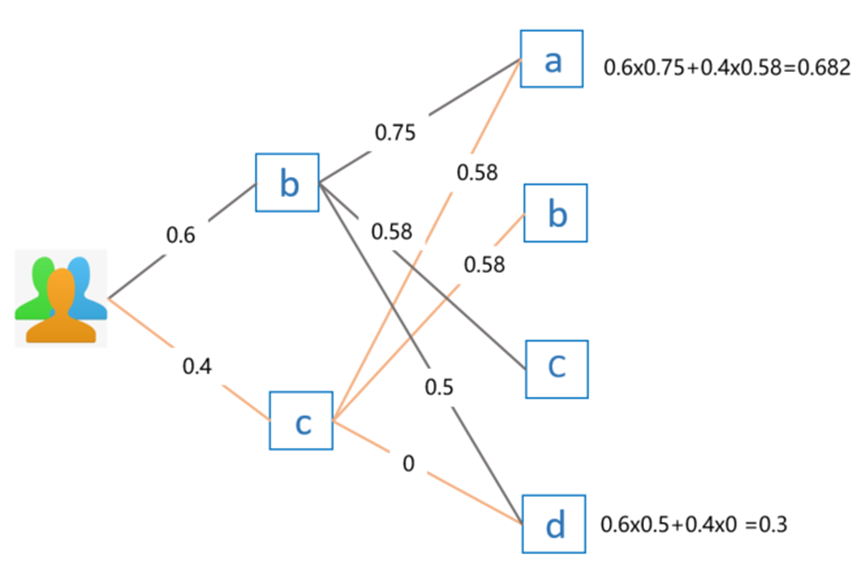
因为物品 b 和物品 c 已经被用户 E 喜欢过了,所以不再重复推荐。最终对比用户 E 对物品 a 和物品 d 的感兴趣程度,因为 0.682 > 0.3,因此选择推荐物品 a。
5、如何实现推荐系统
5.1、选择数据集
这里采用的是推荐领域非常经典的 MovieLens 数据集,它是一个关于电影评分的数据集,官网上提供了多个不同大小的版本,下面以 ml-1m 数据集(大约100万条用户评分记录)为例。
下载解压后,文件夹中包含:ratings.dat、movies.dat、users.dat 3个文件,共6040个用户,3900部电影,1000209条评分记录。各个文件的格式都是一样的,每行表示一条记录,字段之间采用 :: 进行分割。
以ratings.dat为例,每一行包括4个属性:UserID, MovieID, Rating, Timestamp。
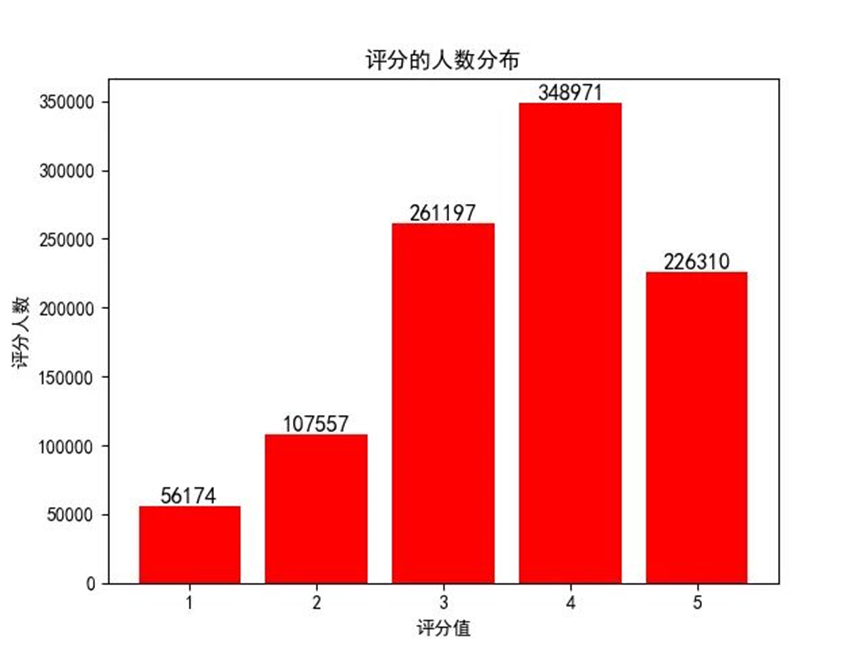
通过脚本可以统计出不同评分的人数分布:
5.2、读取原始数据
程序主要使用数据集中的 ratings.dat 这个文件,通过解析该文件,抽取出 user_id、movie_id、rating 3个字段,最终构造出算法依赖的数据,并保存在变量 dataset 中,它的格式为:dict[user_id][movie_id] = rate
5.3、构造物品的相似度矩阵
基于第 2 步的 dataset,可以进一步统计出每部电影的评分次数以及电影的共生矩阵,然后再生成相似度矩阵。
5.4、基于相似度矩阵推荐物品
最后,可以基于相似度矩阵进行推荐了,输入一个用户id,先针对该用户评分过的电影,依次选出 top 10 最相似的电影,然后加权求和后计算出每个候选电影的最终评分,最后再选择得分前 5 的电影进行推荐。
5.5、调用推荐系统
下面选择 UserId=1 这个用户,看下程序的执行结果。由于推荐程序输出的是 movieId 列表,为了更直观的了解推荐结果,这里转换成电影的标题进行输出。
Java代码示例
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;public class CFRecommendation {// 使用MovieLens数据集private static final String RATINGS_FILE = "ratings.csv";// 用户ID-电影ID-打分private static Map<Integer, Map<Integer, Double>> ratings;// 加载ratings.csv文件private static void loadRatings() throws IOException {File file = new File(RATINGS_FILE);Scanner scanner = new Scanner(file);ratings = new HashMap<>();while (scanner.hasNextLine()) {String line = scanner.nextLine();String[] data = line.split(",");int userId = Integer.parseInt(data[0]);int movieId = Integer.parseInt(data[1]);double rating = Double.parseDouble(data[2]);// 用户-电影-打分Map<Integer, Double> movieRatings = ratings.get(userId);if (movieRatings == null) {movieRatings = new HashMap<>();ratings.put(userId, movieRatings);}movieRatings.put(movieId, rating);}}// 计算两个用户的相似度private static double calculateSimilarity(int user1, int user2) {Map<Integer, Double> rating1 = ratings.get(user1);Map<Integer, Double> rating2 = ratings.get(user2);if (rating1 == null || rating2 == null) {return 0;}double sum1 = 0;double sum2 = 0;double sumProduct = 0;for (int movieId : rating1.keySet()) {if (rating2.containsKey(movieId)) {double rating1Value = rating1.get(movieId);double rating2Value = rating2.get(movieId);sum1 += rating1Value * rating1Value;sum2 += rating2Value * rating2Value;sumProduct += rating1Value * rating2Value;}}return sumProduct / (Math.sqrt(sum1) * Math.sqrt(sum2));}// 计算余弦相似度public static double cosineSim(Map<String, Integer> user1, Map<String, Integer> user2){double result = 0;double denominator1 = 0;double denominator2 = 0;double numerator = 0;for(String key : user1.keySet()){numerator += user1.get(key) * user2.get(key);denominator1 += Math.pow(user1.get(key), 2);denominator2 += Math.pow(user2.get(key), 2);}result = numerator / (Math.sqrt(denominator1) * Math.sqrt(denominator2));return result;}// 使用协同过滤算法获取用户的推荐列表private static Map<Integer, Double> recommend(int userId) {Map<Integer, Double> recommendList = new HashMap<>();// 遍历所有用户for (int otherUserId : ratings.keySet()) {if (otherUserId != userId) {double similarity = calculateSimilarity(userId, otherUserId);Map<Integer, Double> otherRating = ratings.get(otherUserId);// 遍历其他用户的评分,如果当前用户没有评分,则将其推荐给当前用户for (int movieId : otherRating.keySet()) {if (!ratings.get(userId).containsKey(movieId)) {double recommendScore = otherRating.get(movieId) * similarity;recommendList.put(movieId, recommendScore);}}}}return recommendList;}public static void main(String[] args) throws IOException {loadRatings();// 测试用例:计算用户1与用户2的相似度int user1 = 1;int user2 = 2;double similarity = calculateSimilarity(user1, user2);System.out.println("用户1与用户2的相似度:" + similarity);// 测试用例:为用户1推荐电影int userId = 1;Map<Integer, Double> recommendList = recommend(userId);System.out.println("为用户1推荐的电影:");for (int movieId : recommendList.keySet()) {System.out.println("电影ID:" + movieId + ",推荐分数:" + recommendList.get(movieId));}}
}5、问题与展望
通过上面的介绍,大家对推荐系统的基本构成应该有了一个初步认识,但是真正运用到线上真实环境时,还会遇到很多算法和工程上的挑战,绝对不是几十行代码可以搞定的。
问题:
-
- 上面的示例使用了标准化的数据集,而线上环境的数据是非标准化的,因此涉及到海量数据的收集、清洗和加工,最终构造出模型可使用的数据集。
- 复杂且繁琐的特征工程,都说算法模型的上限由数据和特征决定。对于线上环境,需要从业务角度选择出可用的特征,然后对数据进行清洗、标准化、归一化、离散化,并通过实验效果进一步验证特征的有效性。
- 算法复杂度如何降低?比如上面介绍的Item-CF算法,时间和空间复杂度都是O(N×N),而线上环境的数据都是千万甚至上亿级别的,如果不做算法优化,可能几天都跑不出数据,或者内存中根本放不下如此大的矩阵数据。
- 实时性如何满足?因为用户的兴趣随着他们最新的行为在实时变化的,如果模型只是基于历史数据进行推荐,可能结果不够精准。因此,如何满足实时性要求,以及对于新加入的物品或者用户该如何推荐,都是要解决的问题。
- 算法效果和性能的权衡。从算法角度追求多样性和准确性,从工程角度追求性能,这两者之间必须找到一个平衡点。
- 推荐系统的稳定性和效果追踪。需要有一套完善的数据监控和应用监控体系,同时有 ABTest 平台进行灰度实验,进行效果对比。
展望:
AI时代,算法会更加复杂和完善,推荐的效果也会越来越好,特别是随着OpenAI ChatGPT横空出现,推荐系统最有条件和最适合GPT模型去结合使用,当然也会更加高效和智能。期待我们智能版推荐系统早日面世。