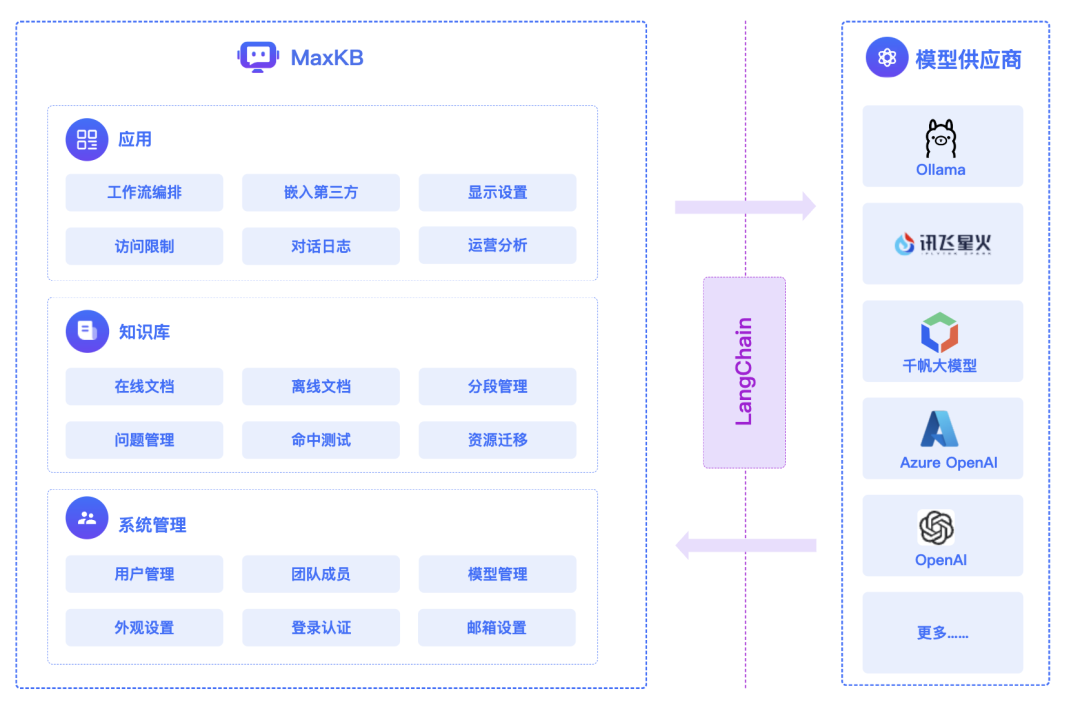
概念
RDD是一种抽象,是Spark对于分布式数据集的抽象,它用于囊括所有内存中和磁盘中的分布式数据实体
RDD 与 数组对比
| 对比项 | 数组 | RDD |
|---|---|---|
| 概念类型 | 数据结构实体 | 数据模型抽象 |
| 数据跨度 | 单机进程内 | 跨进程、跨计算节点 |
| 数据构成 | 数组元素 | 数据分片(Partitions) |
| 数据定位 | 数组下标、索引 | 数据分片索引 |
RDD 4大属性
partitions 数据分片: 数据属性
partitioner 分片切割规则: 定义了把原始数据集切割成数据分片的切割规则
dependencies RDD依赖: 每个RDD都会通过dependencies属性来记录它所依赖的前一个、或是多个RDD,简称“父RDD”
compute 转换函数: 与此同时,RDD使用compute属性,来记录从父RDD到当前RDD的转换操作
例子

不同的食材形态,如带泥土豆、土豆片、即食薯片等等,对应的就是RDD概念
同一种食材形态在不同流水线上的具体实物,就是 RDD 的 partitions 属性
食材按照什么规则被分配到哪条流水线,对应的就是 RDD 的 partitioner 属性
每一种食材形态都会依赖上一种形态,这种依赖关系对应的是 RDD 中的 dependencies 属性
不同环节的加工方法对应 RDD的 compute 属性
RDD 编程模型
在RDD的编程模型中,一共有两种算子,Transformations 类算子和Actions类算子
开发者需要使用Transformations 类算子,定义并描述数据形态的转换过程,然后调用Actions类算子,将计算结果收集起来、或是物化到磁盘
延迟计算
RDD编程模型下,Spark在运行时的计算被划分为两个环节
- 基于不同数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph)
- 通过Actions类算子,以回溯的方式去触发执行这个计算流图
换句话说,开发者调用的各类Transformations算子,并不立即执行计算
当且仅当开发者调用Actions算子时,之前调用的转换算子才会付诸执行
常用算子
| 算子类型 | 适用范围 | 算子用途 | 算子集合 |
|---|---|---|---|
| Transformations | 任意RDD | RDD内数据转换 | map、mapPartitons、mapPartitonsWithIndex、flatMap、 filter |
| Paired RDD | RDD内数据耦合 | groupByKey、sortByKey、reduceByKey、aggregateByKey | |
| 任意RDD | RDD间数据整合 | union、intersection、join、cogroup、cartesian | |
| 任意RDD | 数据整理 | sample、distinct | |
| Actions | 任意RDD | 数据收集 | collect、first、take、takeSample、takeOrdered、count |
| 任意RDD | 数据持久化 | saveAsTextFile、saveAsSequenceFile、saveAsObjectFile | |
| 任意RDD | 数据遍历 | foreach |
map: 元素为粒度对RDD做数据转换
val rdd: RDD[Int] = sc.parallelize(Seq(1, 2, 3, 4, 5))
val result: RDD[Int] = rdd.map(x => x + 1)
result.collect() // 返回 Array(2, 3, 4, 5, 6)在这个例子中,我们使用 parallelize 方法创建一个包含整数的 RDD
接着,我们使用 map 算子将 RDD 中的每个整数都加上 1,生成一个新的 RDD
最后,我们使用 collect 方法将新的 RDD 中的元素取回到驱动程序中
mapPartitons: 以数据分区为粒度,使用映射函数f对RDD进行数据转换
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 3)
val result = rdd.mapPartitions(partition => {val sum = partition.sumIterator(sum)
}).collect()这个例子中,我们首先创建了一个包含10个元素的RDD,并将其分成3个分区
然后,我们使用mapPartitions算子,以数据分区为粒度进行转换
在这个例子中,我们使用partition.sum计算每个数据分区的和,并将其放入一个新的迭代器中
最后,我们使用collect算子将结果收集到本地
这个例子展示了如何使用mapPartitions算子以数据分区为单位进行操作,从而提高执行效率
flatMap:从元素到集合、再从集合到元素
val sentences: RDD[String] = sc.parallelize(List("Hello world", "How are you", "I am fine"))
val words: RDD[String] = sentences.flatMap(sentence => sentence.split(" "))在上面的代码中,我们首先创建了一个包含多个句子的 RDD,然后使用 flatMap 方法,对每个句子进行拆分操作
具体地,对于 RDD 中的每个元素(即句子),我们都将其分割成单词,然后使用 yield 关键字将每个单词作为一个新的元素返回
最终,我们得到了一个包含所有单词的 RDD
filter:过滤RDD
val numbersRDD = sc.parallelize(Seq(-2, 0, 5, -10, 7, -3, 9))
val positiveNumbersRDD = numbersRDD.filter(x => x >= 0)
positiveNumbersRDD.foreach(println) // RDD[0, 5, 7, 9]我们创建了一个包含数字的RDD,然后使用filter算子过滤掉其中的负数,最终返回一个新的RDD,只包含正数
mapPartitionsWithIndex: 每个元素映射为一个包含索引和单词的元组
val data = List("apple", "banana", "orange", "grape", "pear")
val rdd = sc.parallelize(data, 2)val result = rdd.mapPartitionsWithIndex { (index, partition) =>partition.map(word => (index, word))
}result.foreach(println)这段代码创建了一个包含 5 个元素的列表,并将其转换为一个包含 2 个分区的 RDD
接着,使用 mapPartitionsWithIndex 函数将每个元素映射为一个包含索引和单词的元组,最后打印出结果在这个例子中,mapPartitionsWithIndex 函数的输入函数接受两个参数:分区索引和分区中的元素迭代器
元素迭代器包含了分区中的所有元素,因此我们可以在其中使用 map 函数对所有元素进行操作
最终的输出结果是一个包含索引和单词的元组的 RDD
groupByKey:分组收集
groupByKey的字面意思是“按照Key做分组”,但实际上,groupByKey算子包含两步,即分组和收集



![[0152].第3节:IDEA中工程与模块](https://i-blog.csdnimg.cn/direct/73eba5e307b74839a3339857f3d38f31.png)