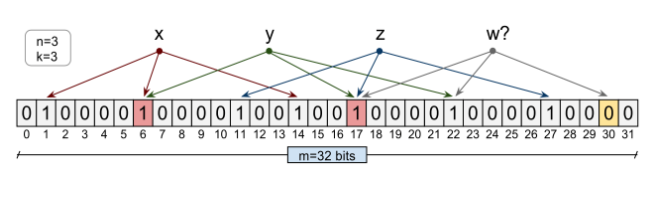
拓展阅读
分词系列专题
jieba-fenci 01 结巴分词原理讲解 segment
jieba-fenci 02 结巴分词原理讲解之数据归一化 segment
jieba-fenci 03 结巴分词与繁简体转换 segment
jieba-fenci 04 结巴分词之词性标注实现思路 speechTagging segment
关键词系列专题
NLP segment-01-聊一聊分词
NLP segment-02-聊一聊关键词提取 keyword
NLP segment-03-基于 TF-IDF 实现关键词提取 java 开源实现
倒排索引原理与实现 reverse-index
TF-IDF 自动生成文章摘要
TF-IDF 自动提取关键词
相似文章算法之语义指纹-文本内容去重
TF-IDF 找出相似文章算法
开源项目
为了便于大家学习,项目开源地址如下,欢迎 fork+star 鼓励一下老马~
nlp-keyword 关键词
pinyin 汉字转拼音
segment 高性能中文分词
opencc4j 中文繁简体转换
nlp-hanzi-similar 汉字相似度
word-checker 拼写检测
sensitive-word 敏感词
NLP 的关键词提取
在自然语言处理(NLP)中,关键词提取是从文本中自动识别出最能代表该文本主题的词或短语的过程。
关键词提取有助于快速理解文档内容,并在信息检索、文本分类、摘要生成等任务中扮演重要角色。
关键词提取的方法可以分为基于统计的方法和基于模型的方法。
1. 基于统计的关键词提取方法
基于统计的方法主要依赖词频、词的位置等统计信息,比较适合无监督的关键词提取场景。
常见方法包括:
1.1 TF-IDF(Term Frequency-Inverse Document Frequency)
- 原理:TF-IDF 通过计算词语在文档中的词频(TF)和逆文档频率(IDF)来衡量词的重要性。TF 反映了词语在当前文档中的出现频率,IDF 则降低在所有文档中频繁出现的词的权重。词的权重为 TF 与 IDF 的乘积。
- 优点:实现简单且效率较高。
- 缺点:仅考虑了词频和文档分布,不适合处理上下文信息,忽略了词语之间的关系。
1.2 TextRank
- 原理:TextRank 是一种基于图的算法,类似于 PageRank。将文档中的词语看作图的节点,如果两个词在一个窗口内共同出现,则在这两个词间建立一条边,边的权重由词的共现频率决定。然后通过迭代计算每个词的重要性得分,并选择得分高的词作为关键词。
- 优点:无监督算法,能够自动提取关键词,适合不依赖训练数据的场景。
- 缺点:忽略了词义相似性,效果依赖于窗口大小的设置。
1.3 RAKE(Rapid Automatic Keyword Extraction)
- 原理:RAKE 通过检测词语在文档中的词组结构来生成关键词。首先分离出停用词,将剩余词语组成候选关键词短语。然后基于这些短语的共现关系,计算候选关键词的得分。
- 优点:简单高效,适合提取多词短语。
- 缺点:仅基于词的邻近关系,对语义信息捕捉有限。
1.4 Mutual Information(互信息)
- 原理:互信息衡量两个词共现的概率与各自独立出现的概率之间的关系。互信息越大,表明两个词之间的联系越紧密。常用于提取二元词组或多元词组作为关键词。
- 优点:适合挖掘组合关键词,便于生成二元或多元关键词。
- 缺点:容易受噪声干扰,且依赖于足够大的语料库。
2. 基于模型的关键词提取方法
随着深度学习的发展,基于模型的方法能够更加智能地结合上下文语义进行关键词提取。常见方法包括:
2.1 BERT-based Extractive Models
- 原理:基于 BERT 等预训练语言模型,通过微调后的模型来提取关键词。BERT 模型通过自注意力机制捕捉了上下文信息,能够识别出与文本主题相关的关键词。
- 优点:可以处理复杂的上下文关系,识别出符合语义的关键词。
- 缺点:计算量较大,需要大量标注数据进行微调。
2.2 Sequence Labeling(序列标注)
- 原理:将关键词提取看作序列标注问题,使用 Bi-LSTM+CRF、Transformer 或 BERT 等模型,将每个词标记为“关键词”或“非关键词”。
- 优点:能灵活地处理句子中的语义信息,适合长文本的关键词提取。
- 缺点:需要大量标注数据进行训练,依赖上下文信息而导致短文本效果有限。
2.3 GCN(Graph Convolutional Networks)
- 原理:构建一个图结构,其中节点代表词语,边代表共现关系。通过 GCN 进行图卷积运算,获取每个词的特征,并通过迭代计算词的重要性得分。
- 优点:适合结构化文本,能有效处理词的共现信息。
- 缺点:构建图的过程复杂,计算成本较高。
2.4 GPT 模型
- 原理:GPT 通过预训练的 Transformer 结构捕捉上下文关系,提取出与主题相关的词。与 BERT 不同,GPT 更适合生成任务,可用来生成与主题相关的长尾关键词。
- 优点:具有较好的语义理解和生成能力。
- 缺点:生成的关键词可能会存在不相关信息,且在计算资源上要求较高。
核心场景
老马感兴趣的主要下面几个点:
自动摘要生成
文本相似度计算与查重
情感分析
文本分类
性别推断
拓展平台
问答系统
检索/搜索