一.Zookeeper
1.定义
ZooKeeper 是一个开源的分布式协调服务,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。这些功能的实现主要依赖于 ZooKeeper 提供的 数据存储+事件监听 功能
2.ZooKeeper 重要概念
1.Data model(数据模型)
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二进制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
2.znode(数据节点)
介绍了 ZooKeeper 树形数据模型之后,我们知道每个数据节点在 ZooKeeper 中被称为 znode,它是 ZooKeeper 中数据的最小单元。
我们通常是将 znode 分为 4 大类:
- 持久(PERSISTENT)节点:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
- 临时(EPHEMERAL)节点:临时节点的生命周期是与 客户端会话(session) 绑定的,会话消失则节点消失。并且,临时节点只能做叶子节点 ,不能创建子节点。
- 持久顺序(PERSISTENT_SEQUENTIAL)节点:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如
/node1/app0000000001、/node1/app0000000002。 - 临时顺序(EPHEMERAL_SEQUENTIAL)节点:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
每个 znode 由 2 部分组成:
- stat:状态信息
- data:节点存放的数据的具体内容
3.版本(version)
在前面我们已经提到,对应于每个 znode,ZooKeeper 都会为其维护一个叫作 Stat 的数据结构,Stat 中记录了这个 znode 的三个相关的版本:
- dataVersion:当前 znode 节点的版本号
- cversion:当前 znode 子节点的版本
- aclVersion:当前 znode 的 ACL 的版本。
4.ACL(权限控制)
对于 znode 操作的权限,ZooKeeper 提供了以下 5 种:
- CREATE : 能创建子节点
- READ:能获取节点数据和列出其子节点
- WRITE : 能设置/更新节点数据
- DELETE : 能删除子节点
- ADMIN : 能设置节点 ACL 的权限
5.Watcher(事件监听器)
Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。

6.会话(Session)
Session 可以看作是 ZooKeeper 服务器与客户端的之间的一个 TCP 长连接,通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向 ZooKeeper 服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的 Watcher 事件通知。
Session 有一个属性叫做:sessionTimeout ,sessionTimeout 代表会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,只要在sessionTimeout规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。
另外,在为客户端创建会话之前,服务端首先会为每个客户端都分配一个 sessionID。由于 sessionID是 ZooKeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionID 的,因此,无论是哪台服务器为客户端分配的 sessionID,都务必保证全局唯一
3.ZooKeeper 集群
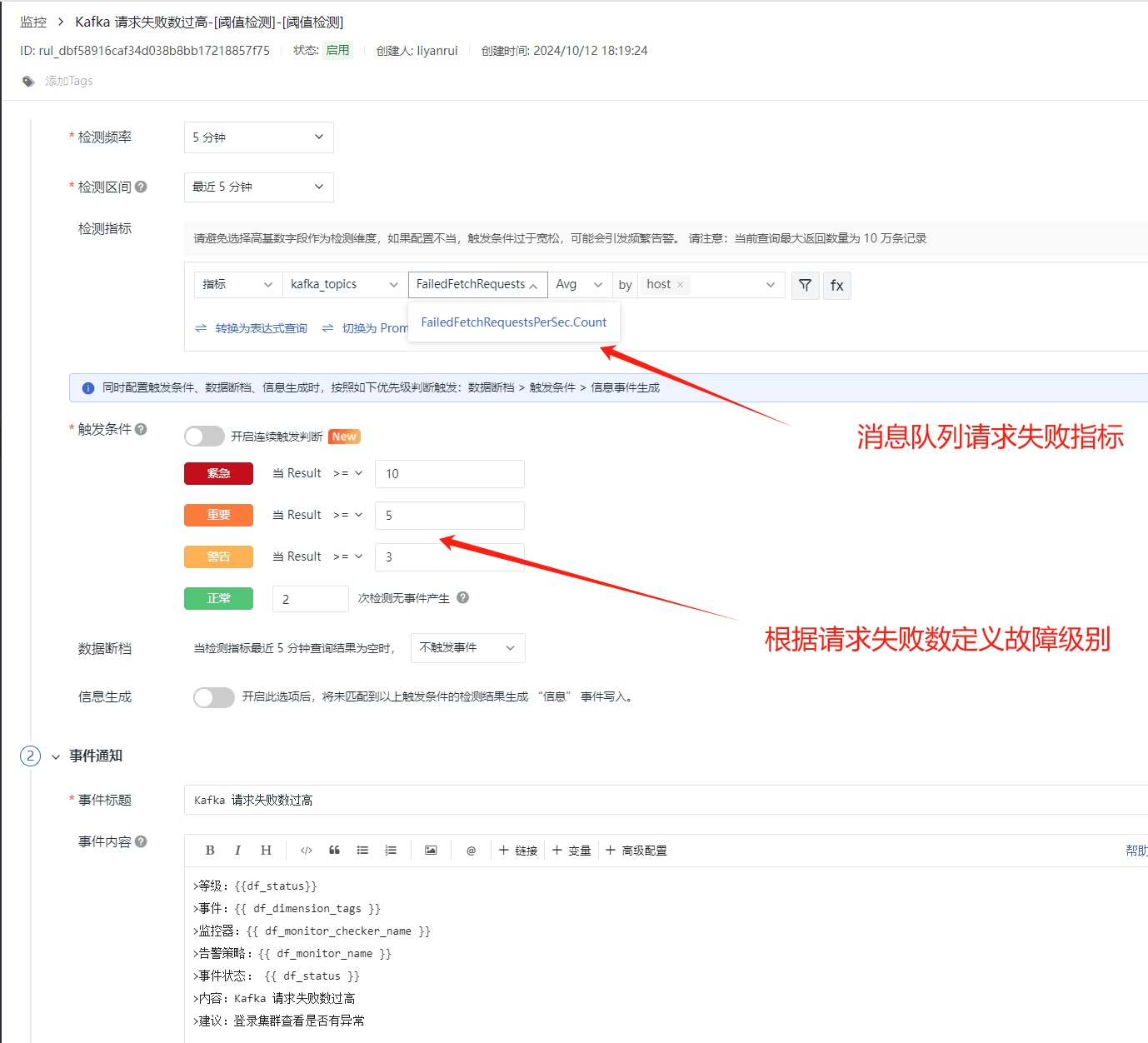
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构图就是一个 ZooKeeper 集群整体对外提供服务。
ZooKeeper 集群架构
上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
最典型集群模式:Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务
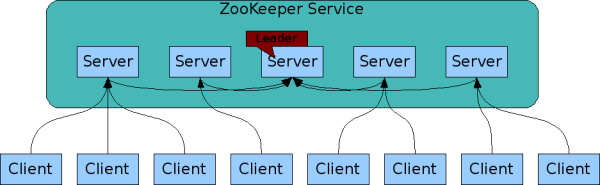
1.ZooKeeper 集群角色
在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示
ZooKeeper 集群中角色
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程 来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
| 角色 | 说明 |
|---|---|
| Leader | 为客户端提供读和写的服务,负责投票的发起和决议,更新系统状态。 |
| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
2.ZooKeeper 集群 Leader 选举过程
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
这个过程大致是这样的:
- Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
- Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
- Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
- Broadcast(广播阶段):到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
ZooKeeper 集群中的服务器状态有下面几种:
- LOOKING:寻找 Leader。
- LEADING:Leader 状态,对应的节点为 Leader。
- FOLLOWING:Follower 状态,对应的节点为 Follower。
- OBSERVING:Observer 状态,对应节点为 Observer,该节点不参与 Leader 选举。
3.ZooKeeper 集群为啥最好奇数台?
ZooKeeper 集群在宕掉几个 ZooKeeper 服务器之后,如果剩下的 ZooKeeper 服务器个数大于宕掉的个数的话整个 ZooKeeper 才依然可用。假如我们的集群中有 n 台 ZooKeeper 服务器,那么也就是剩下的服务数必须大于 n/2。先说一下结论,2n 和 2n-1 的容忍度是一样的,都是 n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
比如假如我们有 3 台,那么最大允许宕掉 1 台 ZooKeeper 服务器,如果我们有 4 台的的时候也同样只允许宕掉 1 台。
假如我们有 5 台,那么最大允许宕掉 2 台 ZooKeeper 服务器,如果我们有 6 台的的时候也同样只允许宕掉 2 台。
综上,何必增加那一个不必要的 ZooKeeper 呢?
4.ZooKeeper 选举的过半机制防止脑裂
何为集群脑裂?
对于一个集群,通常多台机器会部署在不同机房,来提高这个集群的可用性。保证可用性的同时,会发生一种机房间网络线路故障,导致机房间网络不通,而集群被割裂成几个小集群。这时候子集群各自选主导致“脑裂”的情况。
举例说明:比如现在有一个由 6 台服务器所组成的一个集群,部署在了 2 个机房,每个机房 3 台。正常情况下只有 1 个 leader,但是当两个机房中间网络断开的时候,每个机房的 3 台服务器都会认为另一个机房的 3 台服务器下线,而选出自己的 leader 并对外提供服务。若没有过半机制,当网络恢复的时候会发现有 2 个 leader。仿佛是 1 个大脑(leader)分散成了 2 个大脑,这就发生了脑裂现象。脑裂期间 2 个大脑都可能对外提供了服务,这将会带来数据一致性等问题。
过半机制是如何防止脑裂现象产生的?
ZooKeeper 的过半机制导致不可能产生 2 个 leader,因为少于等于一半是不可能产生 leader 的,这就使得不论机房的机器如何分配都不可能发生脑裂。
5.ZAB 协议和 Paxos 算法
4.一致性协议和算法
1.一致性问题
设计一个分布式系统必定会遇到一个问题—— 因为分区容忍性(partition tolerance)的存在,就必定要求我们需要在系统可用性(availability)和数据一致性(consistency)中做出权衡 。这就是著名的 CAP 定理。
理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。
2.一致性协议和算法
而为了解决数据一致性问题,在科学家和程序员的不断探索中,就出现了很多的一致性协议和算法。比如 2PC(两阶段提交),3PC(三阶段提交),Paxos 算法等等。
1.2PC(两阶段提交)
两阶段提交是一种保证分布式系统数据一致性的协议,现在很多数据库都是采用的两阶段提交协议来完成 分布式事务 的处理。
在介绍 2PC 之前,我们先来想想分布式事务到底有什么问题呢?
还拿秒杀系统的下订单和加积分两个系统来举例吧(我想你们可能都吐了 🤮🤮🤮),我们此时下完订单会发个消息给积分系统告诉它下面该增加积分了。如果我们仅仅是发送一个消息也不收回复,那么我们的订单系统怎么能知道积分系统的收到消息的情况呢?如果我们增加一个收回复的过程,那么当积分系统收到消息后返回给订单系统一个 Response ,但在中间出现了网络波动,那个回复消息没有发送成功,订单系统是不是以为积分系统消息接收失败了?它是不是会回滚事务?但此时积分系统是成功收到消息的,它就会去处理消息然后给用户增加积分,这个时候就会出现积分加了但是订单没下成功。
所以我们所需要解决的是在分布式系统中,整个调用链中,我们所有服务的数据处理要么都成功要么都失败,即所有服务的 原子性问题 。
在两阶段提交中,主要涉及到两个角色,分别是协调者和参与者。
第一阶段:当要执行一个分布式事务的时候,事务发起者首先向协调者发起事务请求,然后协调者会给所有参与者发送 prepare 请求(其中包括事务内容)告诉参与者你们需要执行事务了,如果能执行我发的事务内容那么就先执行但不提交,执行后请给我回复。然后参与者收到 prepare 消息后,他们会开始执行事务(但不提交),并将 Undo 和 Redo 信息记入事务日志中,之后参与者就向协调者反馈是否准备好了。
第二阶段:第二阶段主要是协调者根据参与者反馈的情况来决定接下来是否可以进行事务的提交操作,即提交事务或者回滚事务。
比如这个时候 所有的参与者 都返回了准备好了的消息,这个时候就进行事务的提交,协调者此时会给所有的参与者发送 Commit 请求 ,当参与者收到 Commit 请求的时候会执行前面执行的事务的 提交操作 ,提交完毕之后将给协调者发送提交成功的响应。
而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送 回滚事务的 rollback 请求,参与者收到之后将会 回滚它在第一阶段所做的事务处理 ,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。(背这个就行)
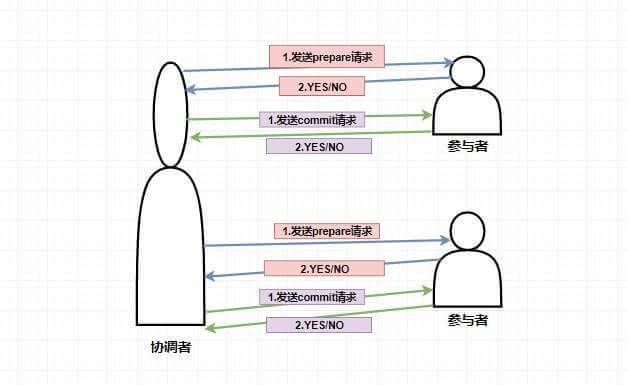
2PC流程
个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。

- 单点故障问题,如果协调者挂了那么整个系统都处于不可用的状态了。
- 阻塞问题,即当协调者发送
prepare请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。 - 数据不一致问题,比如当第二阶段,协调者只发送了一部分的
commit请求就挂了,那么也就意味着,收到消息的参与者会进行事务的提交,而后面没收到的则不会进行事务提交,那么这时候就会产生数据不一致性问题。
2.3PC(三阶段提交)
- CanCommit 阶段:协调者向所有参与者发送
CanCommit请求,参与者收到请求后会根据自身情况查看是否能执行事务,如果可以则返回 YES 响应并进入预备状态,否则返回 NO 。 - PreCommit 阶段:协调者根据参与者返回的响应来决定是否可以进行下面的
PreCommit操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送PreCommit预提交请求,参与者收到预提交请求后,会进行事务的执行操作,并将Undo和Redo信息写入事务日志中 ,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了 任何一个 NO 的信息,或者 在一定时间内 并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。 - DoCommit 阶段:这个阶段其实和
2PC的第二阶段差不多,如果协调者收到了所有参与者在PreCommit阶段的 YES 响应,那么协调者将会给所有参与者发送DoCommit请求,参与者收到DoCommit请求后则会进行事务的提交工作,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在PreCommit阶段 收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应 ,那么就会进行中断请求的发送,参与者收到中断请求后则会 通过上面记录的回滚日志 来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。
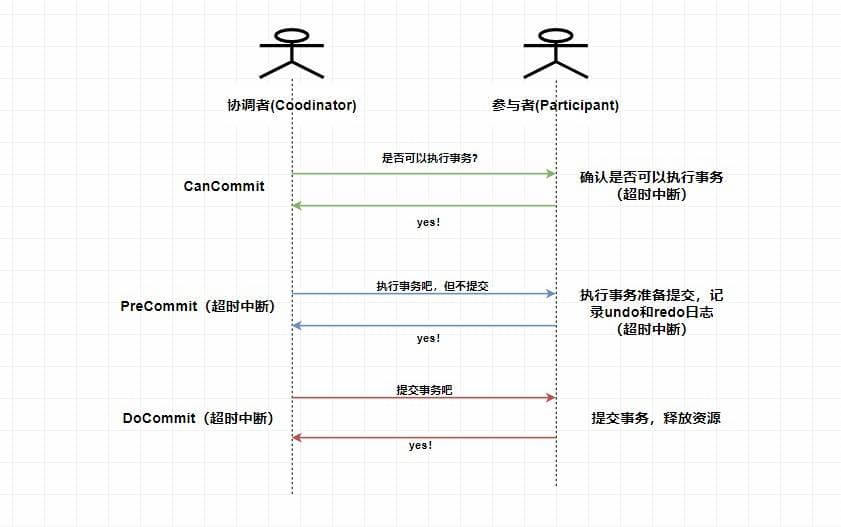
3PC流程
这里是
3PC在成功的环境下的流程图,你可以看到3PC在很多地方进行了超时中断的处理,比如协调者在指定时间内未收到全部的确认消息则进行事务中断的处理,这样能 减少同步阻塞的时间 。还有需要注意的是,3PC在DoCommit阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交。为什么这么做呢?是因为这个时候我们肯定保证了在第一阶段所有的协调者全部返回了可以执行事务的响应,这个时候我们有理由相信其他系统都能进行事务的执行和提交,所以不管协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
总之,3PC 通过一系列的超时机制很好的缓解了阻塞问题,但是最重要的一致性并没有得到根本的解决,比如在 DoCommit 阶段,当一个参与者收到了请求之后其他参与者和协调者挂了或者出现了网络分区,这个时候收到消息的参与者都会进行事务提交,这就会出现数据不一致性问题。
所以,要解决一致性问题还需要靠 Paxos 算法 ⭐️ ⭐️ ⭐️ 。
3.Paxos 算法
Paxos 算法旨在确保在分布式系统中达成一致意见,即在多个节点之间达到对某一个值的同意。它特别适用于需要保证一致性的分布式系统。
主要角色
- 提议者 (Proposer):
- 提议者负责提出提案,并尝试让提案被接受。
- 接受者 (Acceptor):
- 接受者收到提案后可以接受或拒绝提案。提案被多数接受者接受后就被定为一致结果。
- 学习者 (Learner):
- 学习者在提案被多数接受者接受后,学习已达成的一致结果。
工作流程
Paxos 算法的工作分为两个主要阶段:
-
准备阶段 (Prepare Phase):
- 提议者选择一个提案编号
n并发送一个准备请求 (Prepare Request) 给所有接受者。 - 接受者收到请求后,如果
n大于接受者已响应过的所有提案编号,它会返回其已接受的最大编号提案(若有)以及该提案的值,并承诺不再接受编号小于n的提案。
- 提议者选择一个提案编号
-
接受阶段 (Accept Phase):
- 提议者收到多数接受者的响应后,选取一个值(可能是返回的最大编号提案的值,或自己选择的值),并发送一个包含提案编号
n和该值的接受请求 (Accept Request) 给所有接受者。 - 接受者收到接受请求后,如果
n依然大于等于它已响应过的最大编号,它会接受该提案并向提议者返回响应。
- 提议者收到多数接受者的响应后,选取一个值(可能是返回的最大编号提案的值,或自己选择的值),并发送一个包含提案编号
4.paxos 算法的死循环问题
其实就有点类似于两个人吵架,小明说我是对的,小红说我才是对的,两个人据理力争的谁也不让谁 🤬🤬。
比如说,此时提案者 P1 提出一个方案 M1,完成了 Prepare 阶段的工作,这个时候 acceptor 则批准了 M1,但是此时提案者 P2 同时也提出了一个方案 M2,它也完成了 Prepare 阶段的工作。然后 P1 的方案已经不能在第二阶段被批准了(因为 acceptor 已经批准了比 M1 更大的 M2),所以 P1 自增方案变为 M3 重新进入 Prepare 阶段,然后 acceptor ,又批准了新的 M3 方案,它又不能批准 M2 了,这个时候 M2 又自增进入 Prepare 阶段。。。
就这样无休无止的永远提案下去,这就是 paxos 算法的死循环问题。
3.消息广播模式
第一步肯定需要 Leader 将写请求 广播 出去呀,让 Leader 问问 Followers 是否同意更新,如果超过半数以上的同意那么就进行 Follower 和 Observer 的更新(和 Paxos 一样)。当然这么说有点虚,画张图理解一下。
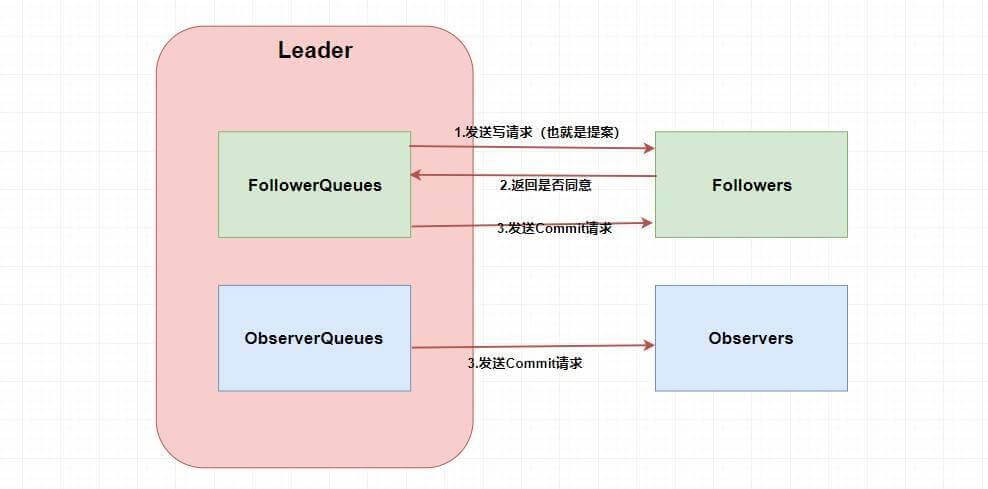
消息广播
嗯。。。看起来很简单,貌似懂了 🤥🤥🤥。这两个 Queue 哪冒出来的?答案是 ZAB 需要让 Follower 和 Observer 保证顺序性 。何为顺序性,比如我现在有一个写请求 A,此时 Leader 将请求 A 广播出去,因为只需要半数同意就行,所以可能这个时候有一个 Follower F1 因为网络原因没有收到,而 Leader 又广播了一个请求 B,因为网络原因,F1 竟然先收到了请求 B 然后才收到了请求 A,这个时候请求处理的顺序不同就会导致数据的不同,从而 产生数据不一致问题 。
所以在 Leader 这端,它为每个其他的 zkServer 准备了一个 队列 ,采用先进先出的方式发送消息。由于协议是 通过 TCP 来进行网络通信的,保证了消息的发送顺序性,接受顺序性也得到了保证。
4.崩溃恢复模式
其实主要就是 当集群中有机器挂了,我们整个集群如何保证数据一致性?
如果只是 Follower 挂了,而且挂的没超过半数的时候,因为我们一开始讲了在 Leader 中会维护队列,所以不用担心后面的数据没接收到导致数据不一致性。
如果 Leader 挂了那就麻烦了,我们肯定需要先暂停服务变为 Looking 状态然后进行 Leader 的重新选举(上面我讲过了),但这个就要分为两种情况了,分别是 确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交 和 跳过那些已经被丢弃的提案 。
确保已经被 Leader 提交的提案最终能够被所有的 Follower 提交是什么意思呢?
假设 Leader (server2) 发送 commit 请求(忘了请看上面的消息广播模式),他发送给了 server3,然后要发给 server1 的时候突然挂了。这个时候重新选举的时候我们如果把 server1 作为 Leader 的话,那么肯定会产生数据不一致性,因为 server3 肯定会提交刚刚 server2 发送的 commit 请求的提案,而 server1 根本没收到所以会丢弃。
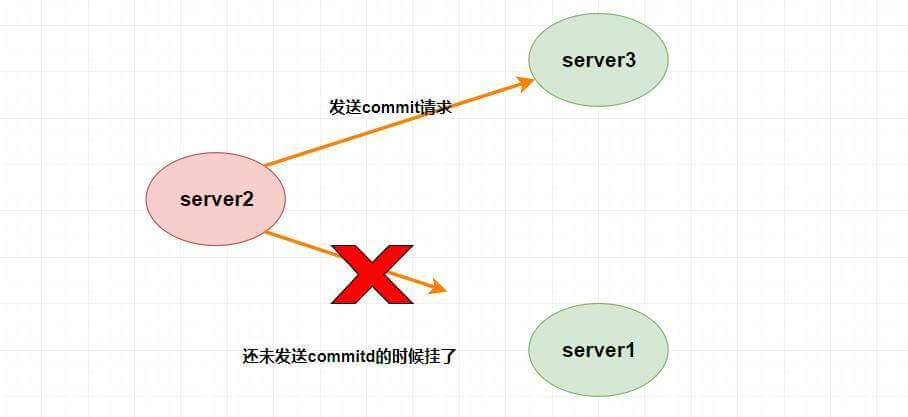
崩溃恢复
那怎么解决呢?
聪明的同学肯定会质疑,这个时候 server1 已经不可能成为 Leader 了,因为 server1 和 server3 进行投票选举的时候会比较 ZXID ,而此时 server3 的 ZXID 肯定比 server1 的大了。(不理解可以看前面的选举算法)
那么跳过那些已经被丢弃的提案又是什么意思呢?
假设 Leader (server2) 此时同意了提案 N1,自身提交了这个事务并且要发送给所有 Follower 要 commit 的请求,却在这个时候挂了,此时肯定要重新进行 Leader 的选举,比如说此时选 server1 为 Leader (这无所谓)。但是过了一会,这个 挂掉的 Leader 又重新恢复了 ,此时它肯定会作为 Follower 的身份进入集群中,需要注意的是刚刚 server2 已经同意提交了提案 N1,但其他 server 并没有收到它的 commit 信息,所以其他 server 不可能再提交这个提案 N1 了,这样就会出现数据不一致性问题了,所以 该提案 N1 最终需要被抛弃掉 。
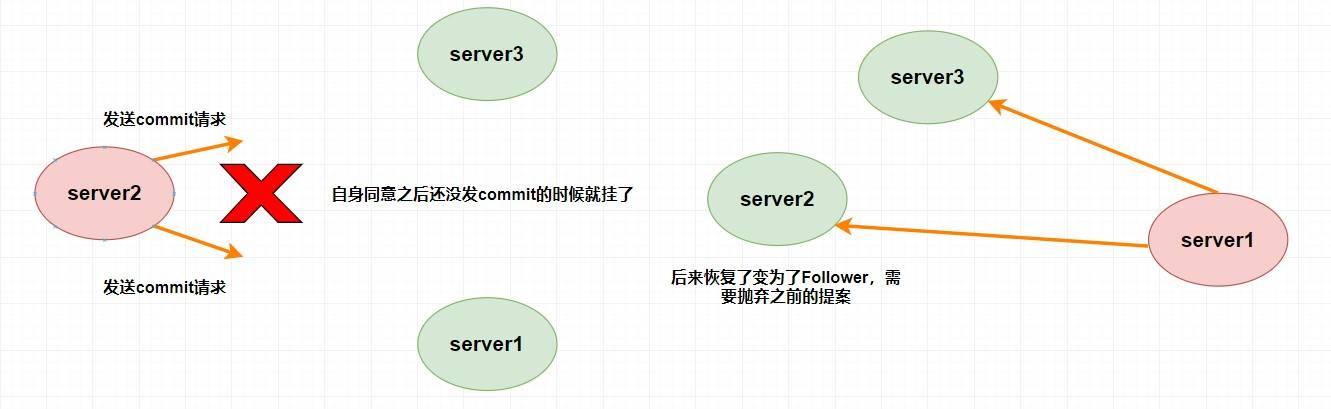
崩溃恢复
5.Zookeeper 的几个典型应用场景
补充
二.消息队列
1.什么是消息队列?
我们可以把消息队列看作是一个存放消息的容器,当我们需要使用消息的时候,直接从容器中取出消息供自己使用即可。由于队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。

参与消息传递的双方称为 生产者 和 消费者 ,生产者负责发送消息,消费者负责处理消息。
操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 中间件 。
维基百科是这样介绍中间件的:
中间件(英语:Middleware),又译中间件、中介层,是一类提供系统软件和应用软件之间连接、便于软件各部件之间的沟通的软件,应用软件可以借助中间件在不同的技术架构之间共享信息与资源。中间件位于客户机服务器的操作系统之上,管理着计算资源和网络通信。
简单来说:中间件就是一类为应用软件服务的软件,应用软件是为用户服务的,用户不会接触或者使用到中间件。
2.消息队列有什么用?
- 异步处理
- 削峰/限流
- 降低系统耦合性
1.异步处理
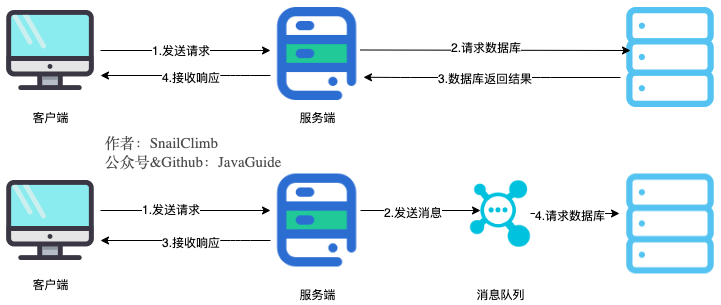
通过异步处理提高系统性能
将用户请求中包含的耗时操作,通过消息队列实现异步处理,将对应的消息发送到消息队列之后就立即返回结果,减少响应时间,提高用户体验。随后,系统再对消息进行消费。
因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,使用消息队列进行异步处理之后,需要适当修改业务流程进行配合,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
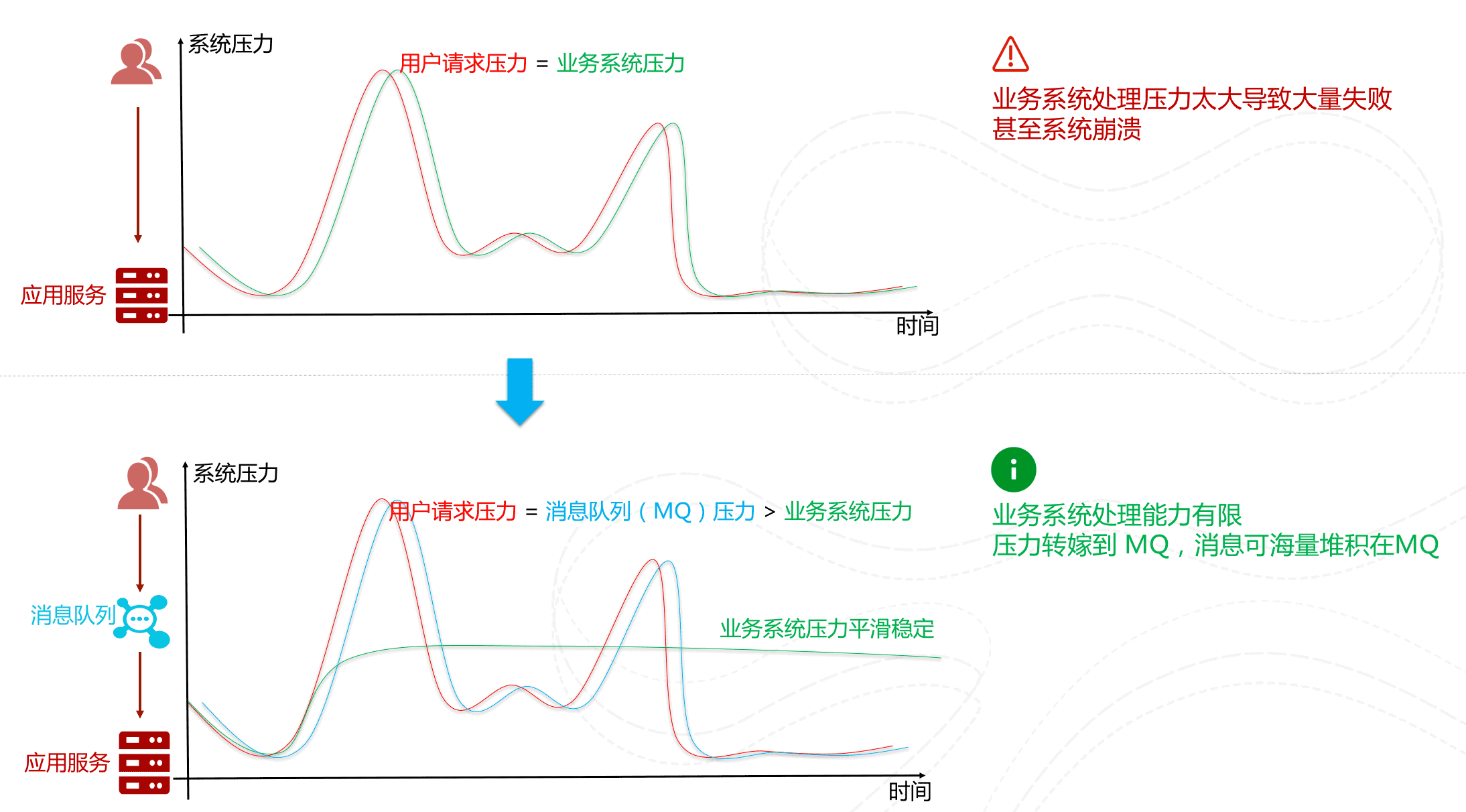
2.削峰/限流
先将短时间高并发产生的事务消息存储在消息队列中,然后后端服务再慢慢根据自己的能力去消费这些消息,这样就避免直接把后端服务打垮掉。
举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
削峰
3.降低系统耦合性
使用消息队列还可以降低系统耦合性。如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
生产者(客户端)发送消息到消息队列中去,消费者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
3.使用消息队列会带来哪些问题?
- 系统可用性降低: 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
- 系统复杂性提高: 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
- 一致性问题: 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
4.JMS 和 AMQP
1.JMS 是什么?
JMS(JAVA Message Service,java 消息服务)是 Java 的消息服务,JMS 的客户端之间可以通过 JMS 服务进行异步的消息传输。JMS(JAVA Message Service,Java 消息服务)API 是一个消息服务的标准或者说是规范,允许应用程序组件基于 JavaEE 平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及异步性。
JMS 定义了五种不同的消息正文格式以及调用的消息类型,允许你发送并接收以一些不同形式的数据:
StreamMessage:Java原始值的数据流MapMessage:一套名称-值对TextMessage:一个字符串对象ObjectMessage:一个序列化的 Java 对象BytesMessage:一个字节的数据流
ActiveMQ(已被淘汰) 就是基于 JMS 规范实现的。
2.JMS 两种消息模型
1.点到点(P2P)模型
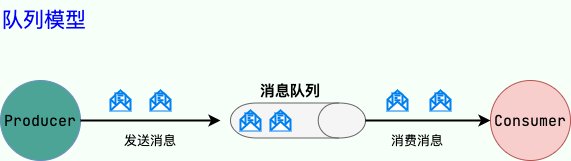
队列模型
使用队列(Queue)作为消息通信载体;满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
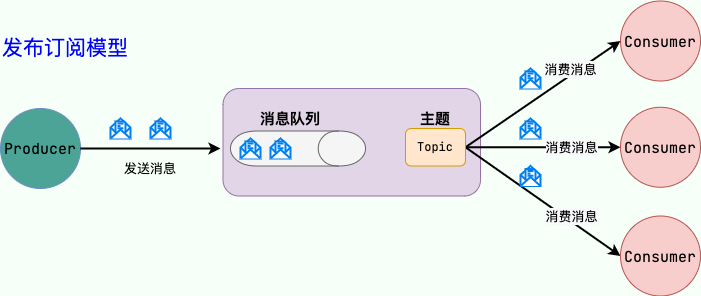
2.发布/订阅(Pub/Sub)模型
发布/订阅(Pub/Sub)模型
发布订阅模型(Pub/Sub) 使用主题(Topic)作为消息通信载体,类似于广播模式;发布者发布一条消息,该消息通过主题传递给所有的订阅者。
3.AMQP 是什么?
AMQP,即 Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准 高级消息队列协议(二进制应用层协议),是应用层协议的一个开放标准,为面向消息的中间件设计,兼容 JMS。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件同产品,不同的开发语言等条件的限制。
RabbitMQ 就是基于 AMQP 协议实现的。
4.JMS vs AMQP
| 对比方向 | JMS | AMQP |
|---|---|---|
| 定义 | Java API | 协议 |
| 跨语言 | 否 | 是 |
| 跨平台 | 否 | 是 |
| 支持消息类型 | 提供两种消息模型:①Peer-2-Peer;②Pub/sub | 提供了五种消息模型:①direct exchange;②fanout exchange;③topic change;④headers exchange;⑤system exchange。本质来讲,后四种和 JMS 的 pub/sub 模型没有太大差别,仅是在路由机制上做了更详细的划分; |
| 支持消息类型 | 支持多种消息类型 ,我们在上面提到过 | byte[](二进制) |
总结:
- AMQP 为消息定义了线路层(wire-level protocol)的协议,而 JMS 所定义的是 API 规范。在 Java 体系中,多个 client 均可以通过 JMS 进行交互,不需要应用修改代码,但是其对跨平台的支持较差。而 AMQP 天然具有跨平台、跨语言特性。
- JMS 支持
TextMessage、MapMessage等复杂的消息类型;而 AMQP 仅支持byte[]消息类型(复杂的类型可序列化后发送)。 - 由于 Exchange 提供的路由算法,AMQP 可以提供多样化的路由方式来传递消息到消息队列,而 JMS 仅支持 队列 和 主题/订阅 方式两种。






![在vue3的vite网络请求报错 [vite] http proxy error:](https://i-blog.csdnimg.cn/direct/5181f30ea2d34325862413868a9bf76e.png)