目录
前言
准备环境
准备数据集
训练
验证效果
导出ONNX模型
C++调用
前言
首先先解释下STR和OCR的区别,很多人可能听说过OCR比较多,这两种任务有相似也有不同,以下是来自ChatGPT的解释。
Optical Character Recognition (OCR)和Scene Text Recognition (STR)是计算机视觉领域中两个相关但不同的任务。
OCR的主要目标是将印刷字符(例如书面文件、杂志、报纸等)转换成机器可读的文本。 OCR技术可以通过扫描纸质文档或者读取数字图像中的文本来实现这个目标。OCR技术的主要应用包括数字化文档、自动化数据输入等。
相比之下,STR的目标是从自然场景图像中提取出文本信息。这些场景图像可能是在户外环境中拍摄的,包含不同的视角、光照条件和背景噪声。STR任务涉及的难点主要在于文本区域的检测、文本识别以及文本的语义理解。
因此,OCR主要关注印刷字符的识别和文本的提取,而STR则需要在自然场景图像中进行文本的检测、识别和理解。两个任务在技术上有些相似,但也有很多不同之处,因为STR需要考虑江到文本的自然性和背景噪声,而OCR则主要关注印刷字符的识别。
简单来说就是OCR更关注识别背景更干净,排版更整齐规范的印刷字符。STR偏向于背景复杂,文本位置不确定,文本形态更不规则的自然场景。所以如果是应用在背景复杂,文本不完全规则的场景(个人认为目前需求更多的场景),关注STR领域的项目可能会更贴切。
其次是关于SOTA的定义,以下也是来自ChatGPT的解释。
"SOTA"是指"State-of-the-art",表示某一领域或任务上当前最先进、最优秀的方法、技术或模型。在深度学习领域中,SOTA通常是指在某个任务上,当前最优秀的神经网络模型或算法。这些模型和算法通常是在公开数据集上进行评估,并且经过严格的实验比较,以确定它们在特定任务上的表现是否优于其他模型或算法。SOTA的标准会随着时间的推移而不断提高,因为研究人员不断尝试新的方法,以尝试超越当前的SOTA。
截止目前为止(2023.04.18),STR领域刷榜了大部分公开数据集的模型是PARSeq,数据来源:
Scene Text Recognition | Papers With Code
下面进入正题
系统环境
硬件环境:
RTX 3060
软件环境:
Windows 10
CUDA 11.6
Python 3.10.9
Pytorch 1.12.1
准备环境
parseq项目链接GitHub - baudm/parseq: Scene Text Recognition with Permuted Autoregressive Sequence Models (ECCV 2022)克隆官方代码
git clone https://github.com/baudm/parseq.git安装anaconda,准备python环境
conda create -n parseq python=3.10
conda activate parseq安装项目的python依赖,torch和torchvision建议用官网方式装,尽量用pip装,用conda直接装似乎有坑。(这里我安装的是cuda11.6下的torch1.12.1)
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116其他用requirements.txt装,requirements里的torch和torchvision去掉。
并安装项目本身。
cd parseq
pip install -r requirements.txt
pip install -e .准备数据集
数据集要求很简单,就是用一个txt保存所有的图片路径和对应的文字标签。
格式为每一行是图片的相对路径和文字标注,中间用空格隔开。
例如下面这张图

在标注文件里假设命名为gt.txt,体现为以下一行
... ...
相对路径/abc.jpg 2364Z
... ...准备好数据集后,用项目tools文件夹下的create_lmdb_dataset.py脚本转成lmdb格式。
gt.txt文件里的图片相对路径和执行脚本填入的图片文件夹路径拼接起来为图片的完整路径。
# create_lmdb_dataset.py 图片所在文件夹路径 标注文件路径 输出文件夹路径
create_lmdb_dataset.py path/to/imgs path/to/gt.txt path/to/output执行完会在输出路径生成data.lmdb和lock.lmdb文件。
我这边实际执行的时候,需要把create_lmdb_dataset.py的第35行修改一下,不然会报错,但是在项目的issue里没有看到其他人有提到,这个看情况修改。
# env = lmdb.open(outputPath, map_size=1099511627776)
env = lmdb.open(outputPath, map_size=1073741824)按以上方法分别生成train、test和val数据集,按以下路径存放,注意train数据集是放在real子文件夹下。

训练
在项目的configs/main.yaml下进行以下修改,仅列出不修改有可能会报错的参数,其他的可自行按需修改。
...
model:...# 需要识别的所有字符,按需修改# 实际测试发现他是以defauts下的charset为准的,可以自行测试charset_train: "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"charset_test: "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ"# 训练的时候执行一次预测使用的图片数量,按需修改,小于数据集数量,太大也可能会爆显存# 最好是8的倍数batch_size: 64...data:...# 修改数据集根路径root_dir: lmdb# 修改训练集的相对路径train_dir: train...trainer:...# 训练多少步验证一次效果,按需修改。# 比如你的数据集只有100张,batch_size是64的话,实际一轮只有2步,训练20轮也才40步。# 如果设置的验证间隔超过40步,就会报错。# 数据集少可以设置少一点。val_check_interval: 10# 使用GPU数量,按需修改。gpus: 1...
# 使用预训练参数
# 一般来说开启后即使数据集不多,也可以达到比较好的效果
pretrained: parseq
...执行train.py脚本开始训练。
python train.py训练完后会在outpus/parseq文件夹下生成模型参数。
验证效果
执行以下脚本
import torch
from PIL import Image
from strhub.data.module import SceneTextDataModule# 加载模型,并设置为评估模式,路径自行替换
parseq = load_from_checkpoint("parseq_last.ckpt").eval()# 获取图片预处理器,包括缩放,标准化,归一化,转tensor
img_transform = SceneTextDataModule.get_transform(parseq.hparams.img_size)# 加载图片
image = Image.open('/path/to/image.png').convert('RGB')
# 图片预处理,并转成batch * channel * height * width
image = img_transform(image).unsqueeze(0)# 预测
logits = parseq(img)# 解码
pred = logits.softmax(-1)
label, confidence = parseq.tokenizer.decode(pred)
# 打印结果
print('Decoded label = {}'.format(label[0]))至此python版本的使用就到这里完成。
以下为生产部署时用C++调用的步骤。
导出ONNX模型
执行以下脚本,将模型转为onnx
import torch
from strhub.models.utils import load_from_checkpoint# 加载训练好的参数,设置为评估模式
parseq = load_from_checkpoint("parseq_last.ckpt").eval()# 关闭自回归解码
# 开启后,模型的推理过程是动态的,导出成静态图会出现问题。
parseq.decode_ar = False# 生成一张随机的假图
image = torch.rand(1, 3, *parseq.hparams.img_size) # (1, 3, 32, 128) by default# 转成onnx
# onnx的算子版本需要在14或者以上
parseq.to_onnx('parseq.onnx', image, do_constant_folding = True, opset_version=14)验证onnx预测结果和原来的是否一致
# 对比导出成onnx的结果和pytorch执行的结果是否一致。import onnxruntime
import numpy as np
from onnxruntime.datasets import get_example
import torch
from strhub.models.utils import load_from_checkpoint
from PIL import Image
from strhub.data.module import SceneTextDataModule# torch tensor转numpy
def to_numpy(tensor):return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()# 加载参数,设置为评估模式
model = load_from_checkpoint("parseq_last.ckpt").eval()
# 关闭自回归解码
model.decode_ar = False# 获取图片预处理器,包括缩放,标准化,归一化,转tensor
img_transform = SceneTextDataModule.get_transform(model.hparams.img_size)# 加载图片
image = Image.open('/path/to/image.png').convert('RGB')
# 图片预处理,并转成batch * channel * height * width
image = img_transform(image).unsqueeze(0)# 用项目原本的torch模型预测
torch_out = model(image)# 导出的onnx模型
onnx_model = "parseq.onnx"
sess = onnxruntime.InferenceSession(onnx_model)
# 获取输入层名称
inname = [input.name for input in sess.get_inputs()]
# 用导出的onnx模型预测
onnx_out = sess.run(None, {inname[0]: to_numpy(image)})# 判断输出结果是否一致,小数点后4位一致即可
np.testing.assert_almost_equal(to_numpy(torch_out), onnx_out[0], decimal=4)C++调用
步骤和python调用也是差不多的,只不过输入的预处理和最后的后处理解码部分要自己简单实现一下。整个流程大概是以下步骤
- 加载图片。
- 按模型的输入缩放图片,模型输入默认是宽128,高32。
- 图片归一化,标准化,转成batch * channel * height * width的shape。
- 用onnx的C++接口,加载图片和模型,进行预测。
- 对输出的tensor进行解码,默认是输出batch * 26 * 95。
- 26代表最大支持预测字符串的长度(训练的时候可以按需修改),实际是25个字符其中一个是终止符。
- 95代表当前这个字符是95种字符中其中一种的置信度。和通常的分类任务输出结果一样,95个置信度中最大的那个值的索引,即表示识别结果是对应id的字符。实际是94种字符,索引为0的是终止符。例如输出是[0.1, 0.9, 0.1, 0.1 .....],这个时候如果0.9是里面最大的,说明识别的值是索引为1的字符,字符的索引顺序在训练的时候可以设置,例如如果是"abcABC",那么索引为1的字符就是a。
最后用QT5简单做了一个可视化的demo,效果还可以,即使用CPU进行识别也可以达到接近实时的效果。
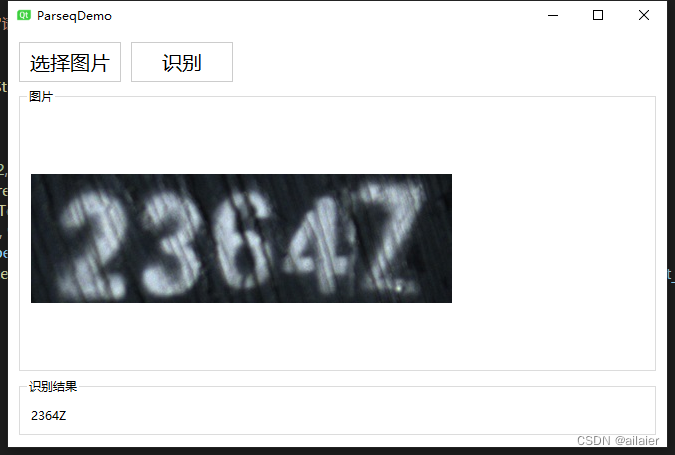
STR文本识别项目一般只进行单行文本的识别,所以需要结合STD文本检测任务,将文本行抠出来,再进行识别。
文本行的检测可以查看另一篇文章
【STD文本检测项目】之 DBNet++(一)用MMOCR在自己的数据集上训练进行文本检测
下篇
【STR文字识别项目】之 最新SOTA项目PARSeq(二)转TensorRT并用C++调用