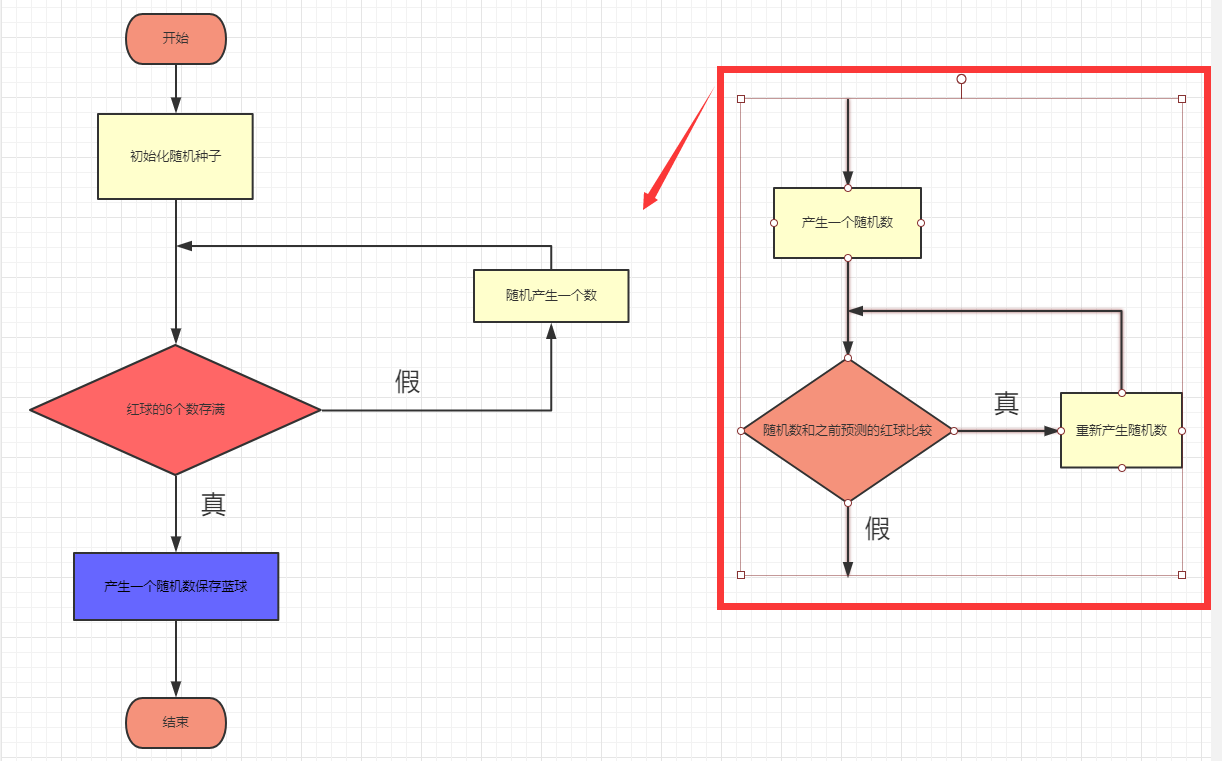
步骤
1.获得数据
2.清洗保存数据
3.读取数据并可视化
4.得出结论

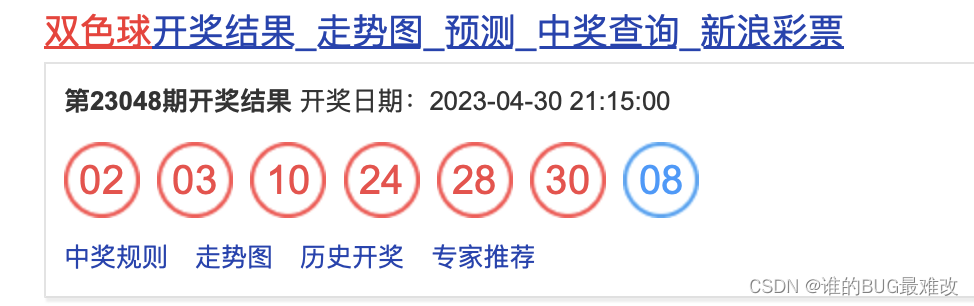
首先,简单说下国民彩票双色球的规则:选6位数字作为红球和1位数字作为篮球组成一注彩票,红球的区间是1~33,蓝球的区间是1 ~ 16。篮球+红球与开奖号码相同的个数决定中奖的金额。
其中的单式,复式等玩法就不展开了,这里主要复习爬虫和可视化
1.获取数据
毋庸置疑,有数据才能分析。这里的数据来源有两个:一是自己写爬虫获取,二是到 Kaggle 下载,作者已经把数据上传到Kaggle了,下载即用。
这里简单说下Kaggle, 这个网站有各种各样的数据,而且都是处理好的(波斯顿房价、绝地求生等相关数据),上面的数据都是提供给机器学习的。
回到正题,获取数据的网址:http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html
首先打开网址看看相关的访问规则
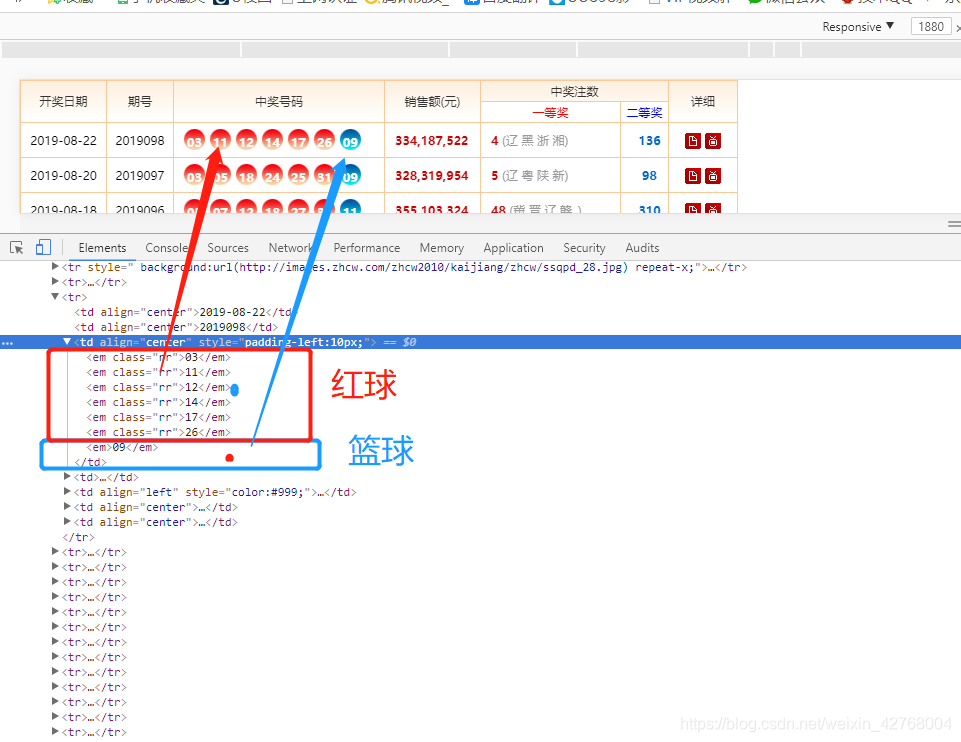
这里可以看到开奖号码的HTML源码。这样的标签获取起来有点麻烦,不过问题不大
下面我们再开看看页面切换,URL会有什么变化
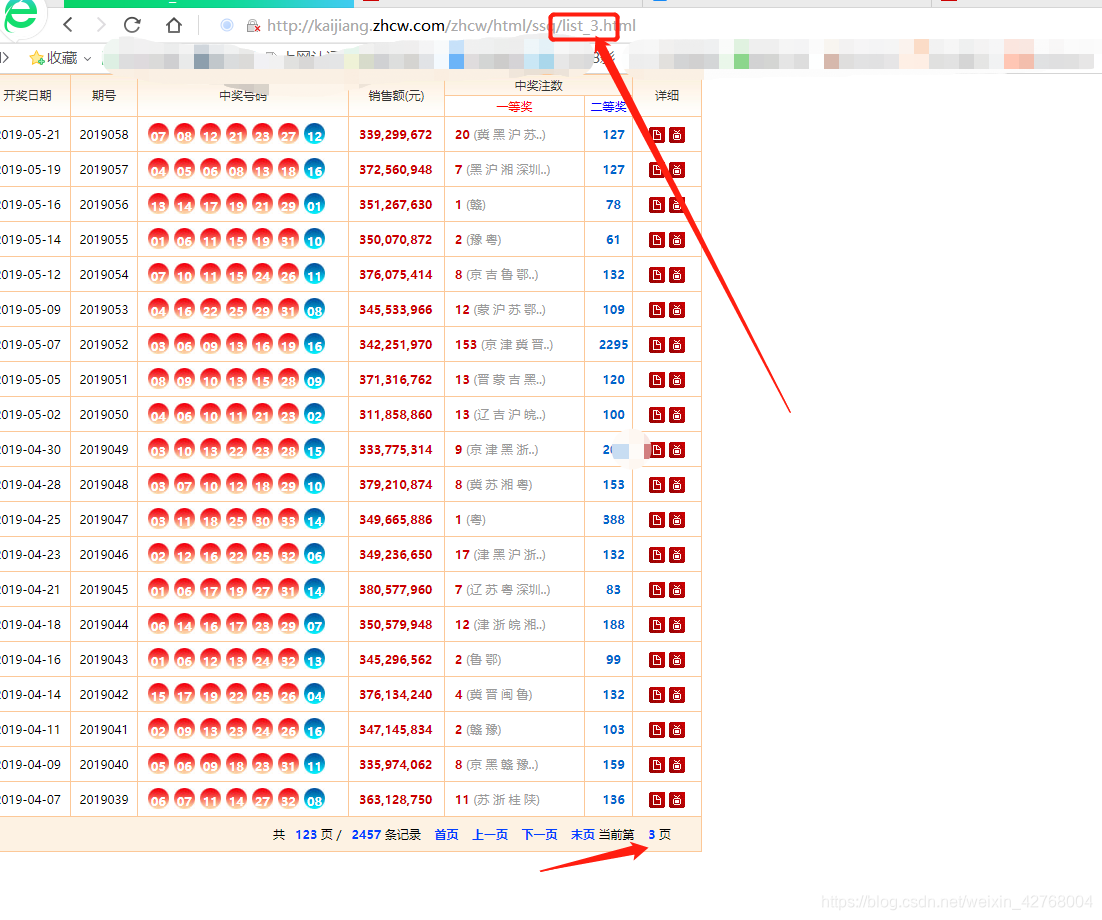
作者切换了几页发现,在URL中控制页码的就是其中的 ‘list_’,这里就好办了。
下面我们可以来写敲代码写爬虫了
res = requests.get(url1,headers = headers)soup = BeautifulSoup(res.text,'lxml')item = soup.find_all('td',{'style':'padding-left:10px;'})
这里爬虫的基础request,BeautifuleSoup就不过多展开了。
上文说到的HTML源码获取起来很麻烦,因为它都在不同的标签并且红球和篮球的标签是一样的,不同的就是属性。作者尝试过按属性来获取篮球,但是不知道为什么没有返回数据。所以先把整个大的标签拿下来。
for num in item:a = num.find_all('em')[0].get_text()red_one.append(a)a = num.find_all('em')[1].get_text()red_two.append(a)a = num.find_all('em')[2].get_text()red_three.append(a)a = num.find_all('em')[3].get_text()red_four.append(a)a = num.find_all('em')[4].get_text()red_five.append(a)a = num.find_all('em')[5].get_text()red_six.append(a)a = num.find_all('em')[6].get_text()blue.append(a)
可以看到这里是按List的位置来获取红球的每一位和篮球。获取有更好的方法,可以下方留言一起探讨!
2.清洗保存数据
这里用到比较实用和强大的一个库 Pandas,因为把数据存为CSV格式,方便后面的可视化
下面来看代码实现:
dataframe=pd.DataFrame({'red_one':red_one,'red_two':red_two,'red_three':red_three,'red_four':red_four,'red_five':red_five,'red_six':red_six,'blue':blue})
dataframe.to_csv('data.csv',sep=',')
比较简单,下面来看看成功保存的数据长什么样:
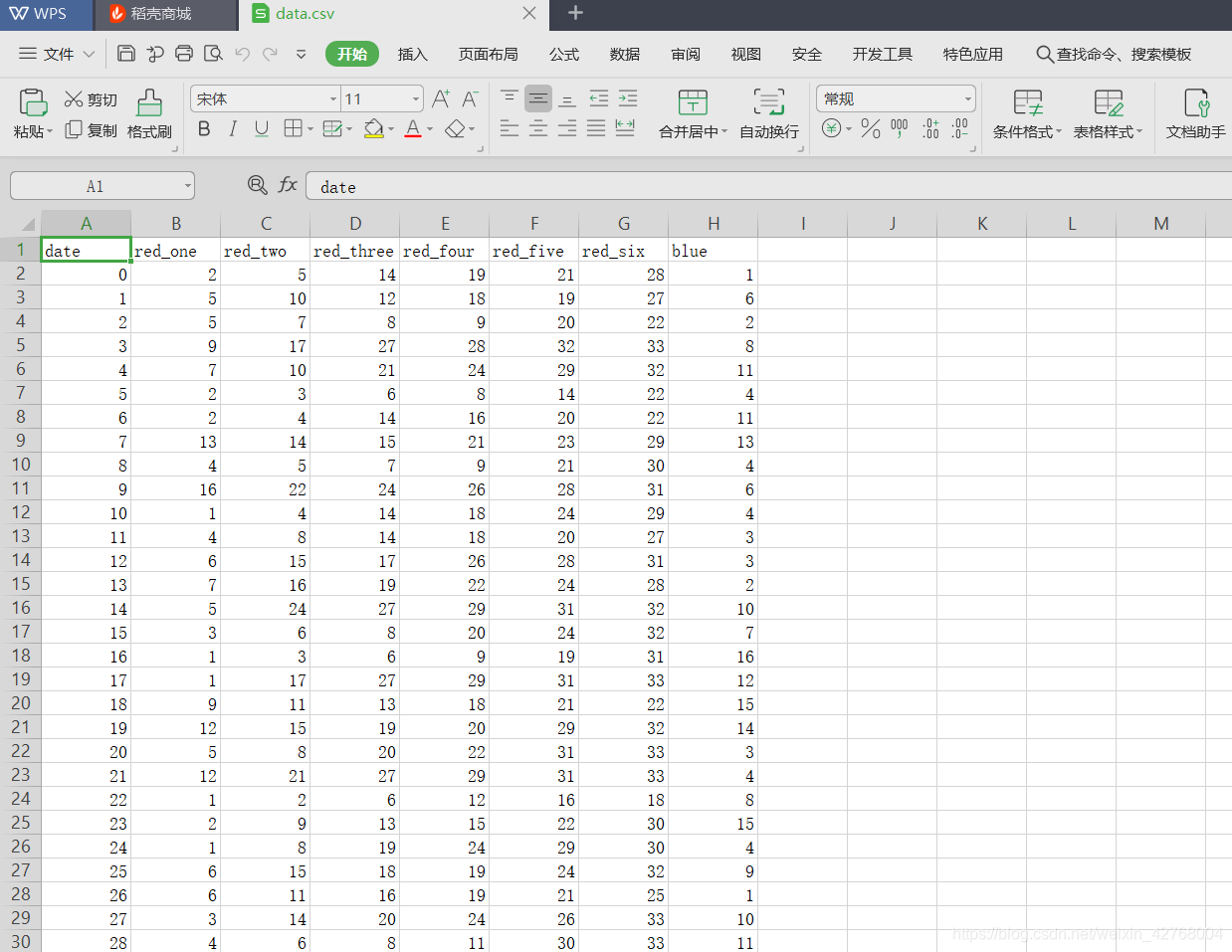
一共获取了2400+条数据左右,大概是2003年到2019年8月的数据
3,数据可视化分析
这里用到一个库 matplotlib
下面我们把每一位的数据以条形图来展示。因为代码有重复性,所以这里就贴蓝球的
import pandas as pd
import matplotlib.pyplot as plt# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['KaiTi']
# 读取数据并去掉第一列
datasets = pd.read_csv(r'data.csv')
x_data = datasets['date']
data = datasets.iloc[:,1:]# 查看篮球各数字的个数
num_data = data['blue'].value_counts()
print(num_data)
# 横坐标,这里以打印出来的为准
x = ['12','11','9','16','14','7','1','15','13','5','6','10','3','4','2','8']
bar = plt.bar(x,num_data,color = 'blue')
plt.xlabel('号码',fontsize = 15)
plt.ylabel('频率/次',fontsize = 15)
plt.title('篮球',fontsize = 20)
# 在条形图上标注次数
for num in bar :height = num.get_height()plt.text(num.get_x() + num.get_width() / 2, height + 1, str(height), ha="center", va="bottom")
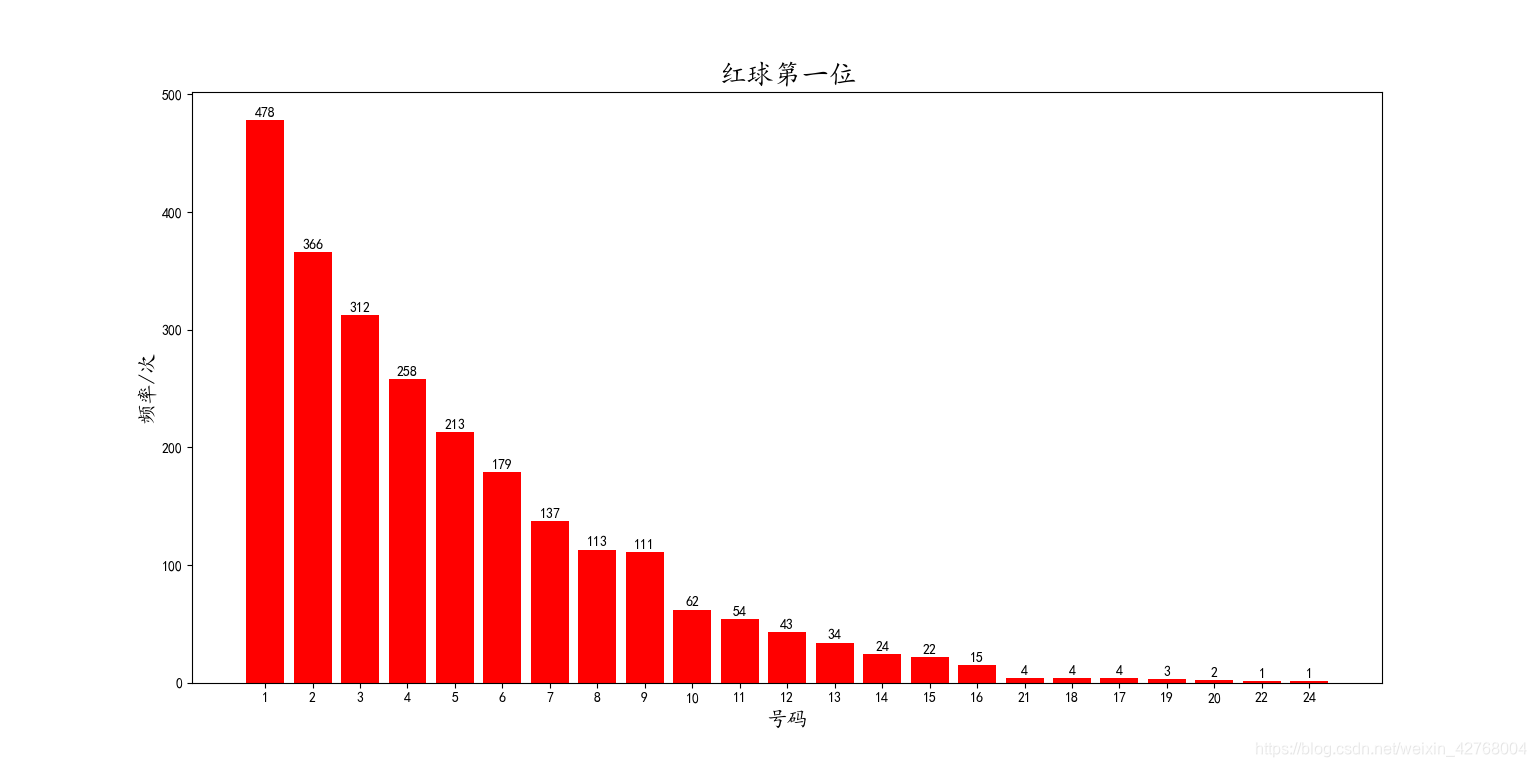
plt.show()下面来看画出来的各位数字的详情:
红球第一位:
红球第二位:
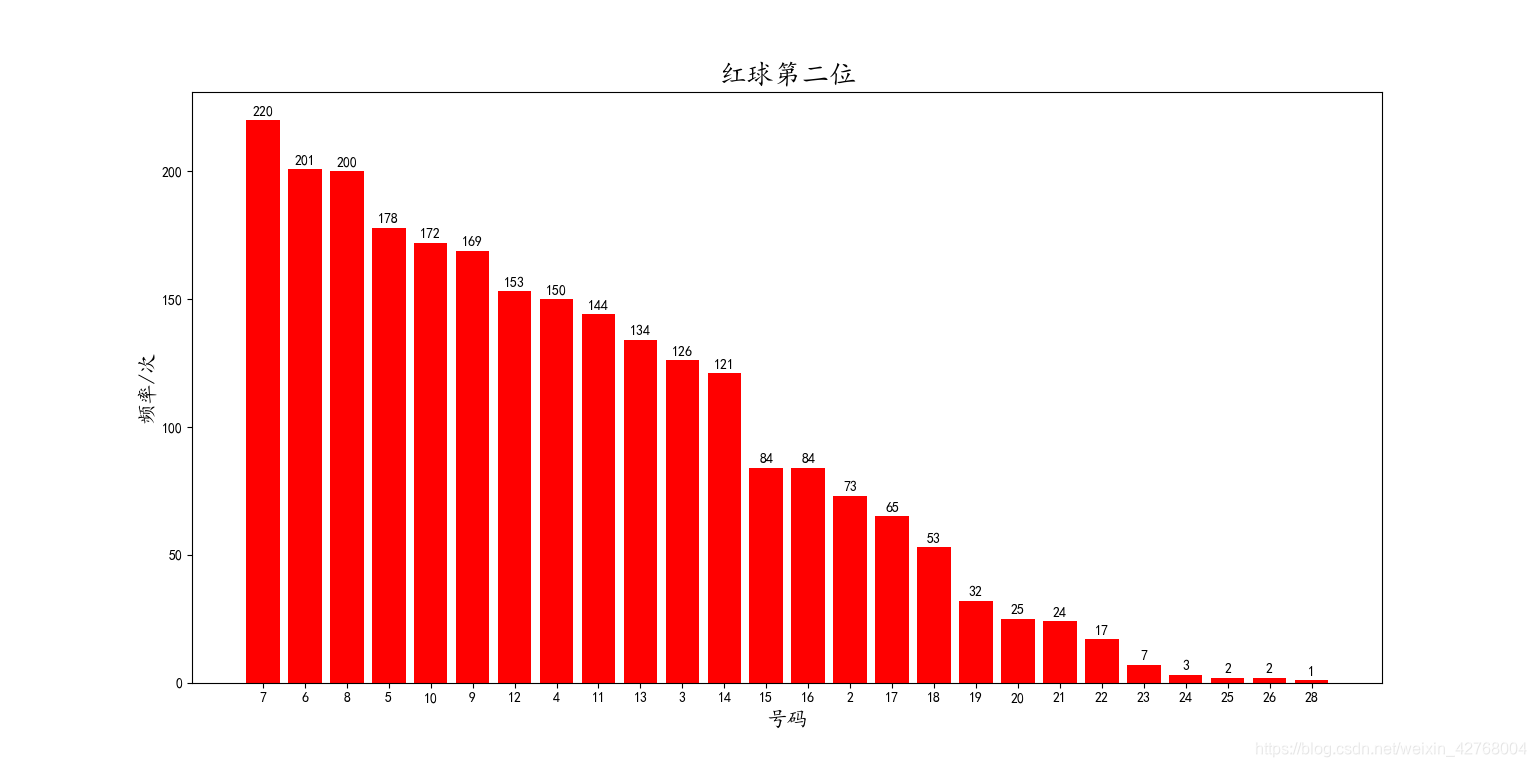
红球第三位:
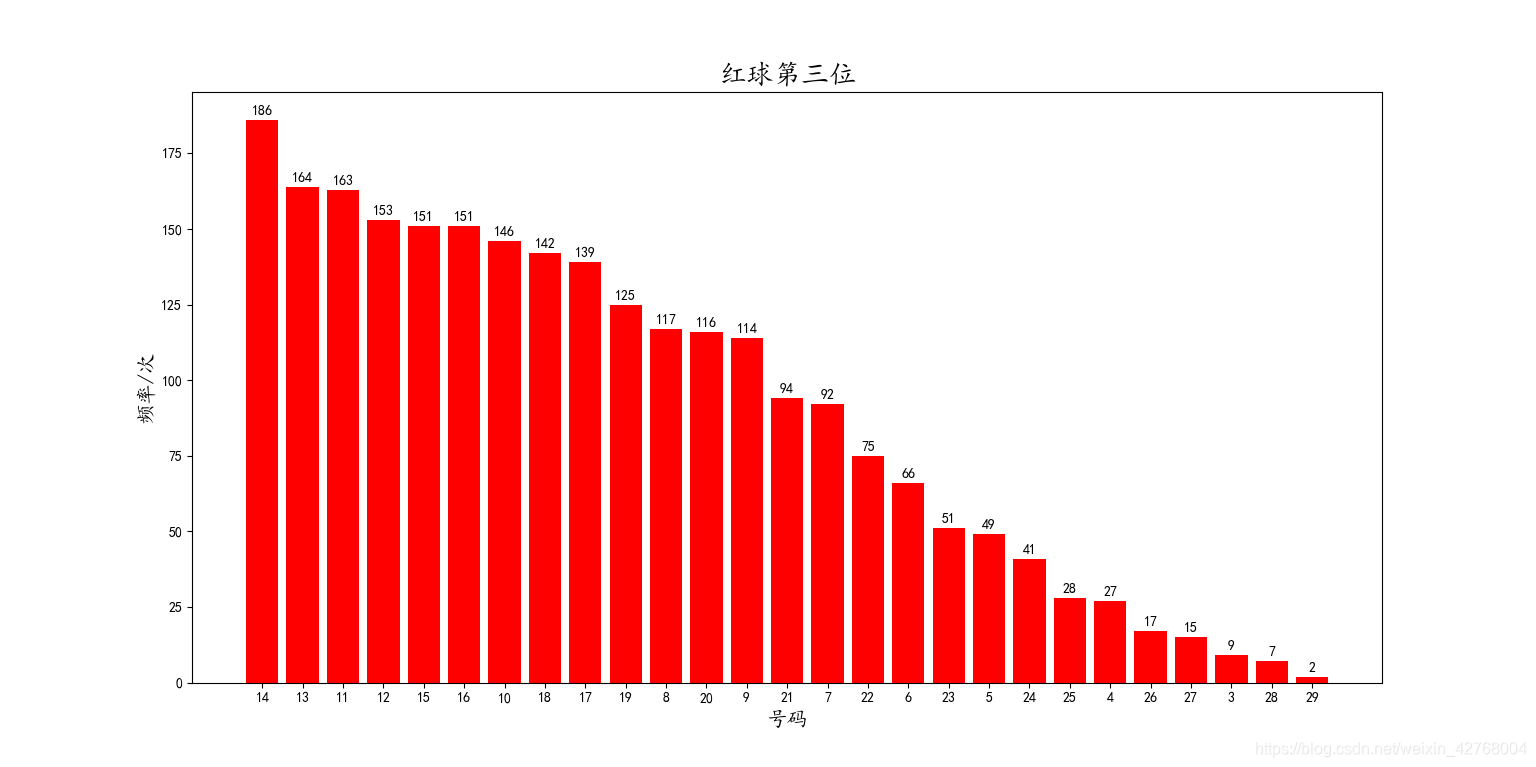
红球第四位:
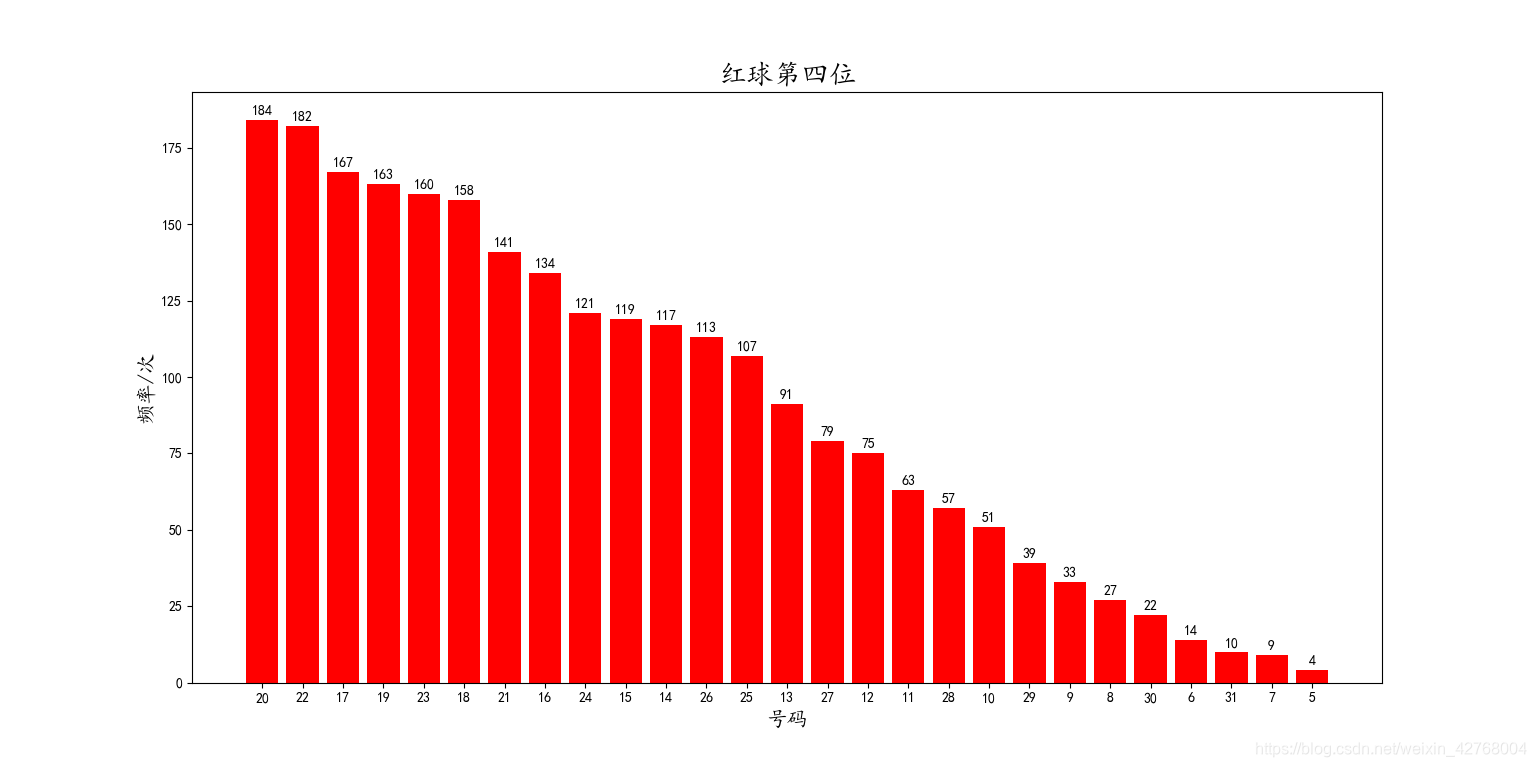
红球第五位:
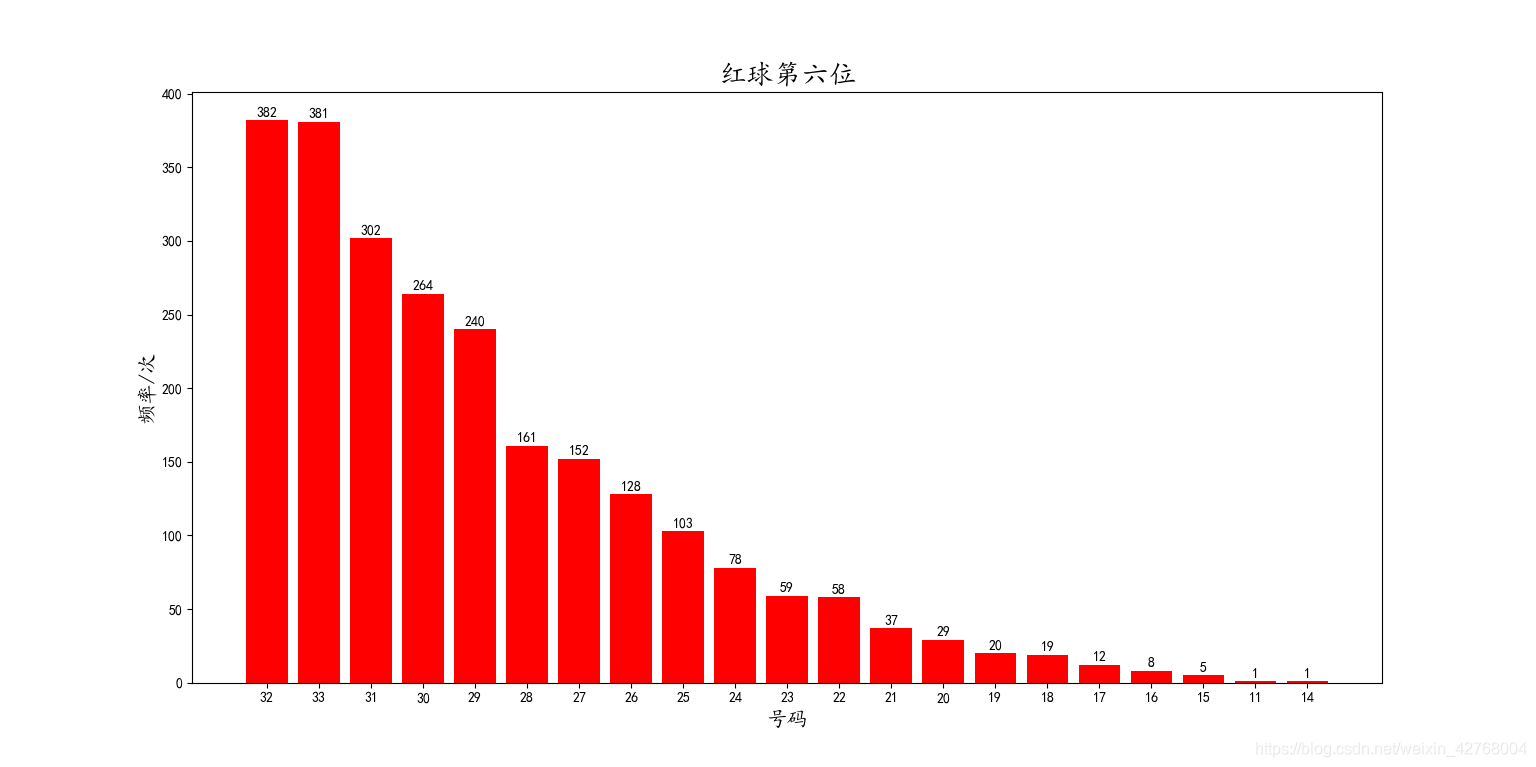
红球第六位:
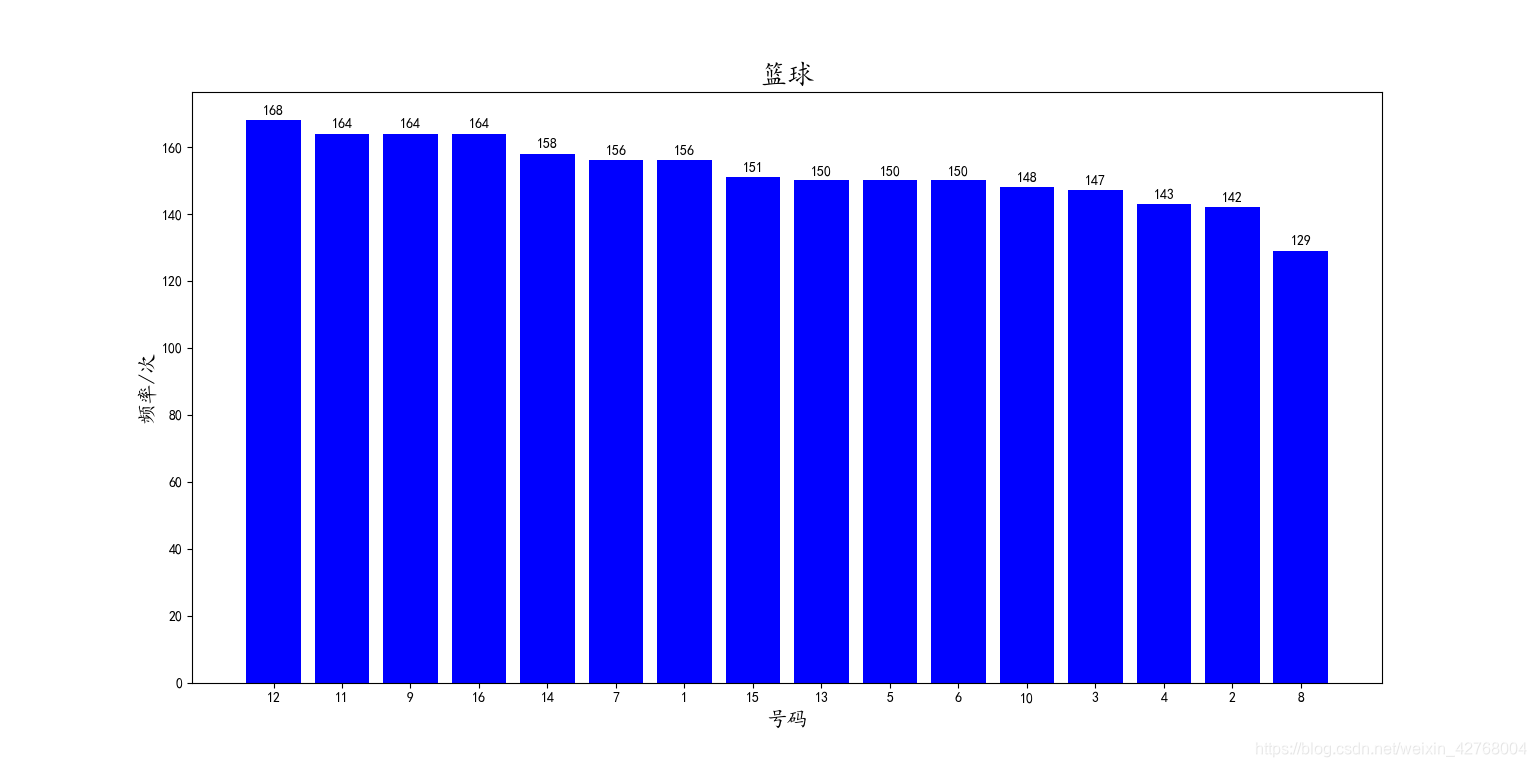
蓝球:
4.得出结论
从红球的图中可以看到中奖号码的出现频率分布情况,相信读者都能一眼看出来。这里就不费篇幅了。
蓝色球的中奖号码分布比较均匀,所以没啥结论。
5.完整代码
获取数据:
from bs4 import BeautifulSoup
import requests
import pandas as pd
import time
# 控制页码
url = ['http://kaijiang.zhcw.com/zhcw/html/ssq/list_{}.html'.format(str(i)) for i in range (1,123,1)]
#url = 'http://kaijiang.zhcw.com/zhcw/html/ssq/list_4.html'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36','Host':'kaijiang.zhcw.com','Upgrade-Insecure-Requests':'1'
}
# 一列表的方式分开存取每一位数据
red_one = []
red_two = []
red_three = []
red_four = []
red_five = []
red_six = []
blue = []
def get_text(url1):res = requests.get(url1,headers = headers)soup = BeautifulSoup(res.text,'lxml')item = soup.find_all('td',{'style':'padding-left:10px;'})for num in item:a = num.find_all('em')[0].get_text()red_one.append(a)a = num.find_all('em')[1].get_text()red_two.append(a)a = num.find_all('em')[2].get_text()red_three.append(a)a = num.find_all('em')[3].get_text()red_four.append(a)a = num.find_all('em')[4].get_text()red_five.append(a)a = num.find_all('em')[5].get_text()red_six.append(a)a = num.find_all('em')[6].get_text()blue.append(a)# 存为CSVdataframe = pd.DataFrame({'red_one':red_one,'red_two':red_two,'red_three':red_three,'red_four':red_four,'red_five':red_five,'red_six':red_six,'blue':blue})dataframe.to_csv('data.csv',sep=',')time.sleep(2)print('成功一次')
# 按页数循环控制
for url1 in url:get_text(url1)print("结束")
可视化代码:
import pandas as pd
import matplotlib.pyplot as plt# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['KaiTi']
# 读取数据并去掉第一列
datasets = pd.read_csv(r'data.csv')
x_data = datasets['date']
data = datasets.iloc[:,1:]# 查看篮球各数字的个数
num_data = data['blue'].value_counts()
print(num_data)
# 横坐标,这里以打印出来的为准
x = ['12','11','9','16','14','7','1','15','13','5','6','10','3','4','2','8']
bar = plt.bar(x,num_data,color = 'blue')
plt.xlabel('号码',fontsize = 15)
plt.ylabel('频率/次',fontsize = 15)
plt.title('篮球',fontsize = 20)
# 在条形图上标注次数
for num in bar :height = num.get_height()plt.text(num.get_x() + num.get_width() / 2, height + 1, str(height), ha="center", va="bottom")
plt.show()6.总结
双色球的随机性很强,几乎无法预测。当然,作者认为这里的图中中奖号码的分布情况,对于真实购买双色球有一定的参考性,总比自己瞎蒙好吧!
本文仅是对爬虫、pandas、matplotlib基础知识的复习和运用。
对于预测双色球,下一篇会以机器学习的方法来尝试。
感谢阅读!