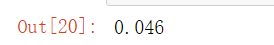前言
嗯,先说说这个项目我用到的框架吧。。。
首先用到了自动化爬虫框架selenium,用来爬取数据,网址
由于主要想看看每期开奖号码,所以可视化就简单一点matplotlib折线图就可以了。
好的一切准备就绪,开搞。
源代码如下:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# @date: 2020/8/11 17:31
# @name: 双色球预测
# @author:咩小饬
from selenium import webdriver
import matplotlib.font_manager as fm
from matplotlib import pyplot as plt
import matplotlib as mpl
import numpy as np
# 解决中文乱码问题
#sans-serif就是无衬线字体,是一种通用字体族。
#常见的无衬线字体有 Trebuchet MS, Tahoma, Verdana, Arial, Helvetica, 中文的幼圆、隶书等等。
mpl.rcParams['font.sans-serif']=['SimHei'] #指定默认字体 SimHei为黑体
mpl.rcParams['axes.unicode_minus']=False #用来正常显示负号
url = "http://www.cwl.gov.cn/kjxx/ssq/kjgg/"
driver = webdriver.Chrome()
driver.get(url)
r1_list = []
r2_list = []
r3_list = []
r4_list = []
r5_list = []
r6_list = []
#红球预测
red_dataset = driver.find_elements_by_xpath('//tbody/tr')
for r1,r2,r3,r4,r5,r6 in zip(red_dataset,red_dataset,red_dataset,red_dataset,red_dataset,red_dataset):r1 = r1.find_element_by_xpath('./td/span[1]').textr2 = r2.find_element_by_xpath('./td/span[2]').textr3 = r3.find_element_by_xpath('./td/span[3]').textr4 = r4.find_element_by_xpath('./td/span[4]').textr5 = r5.find_element_by_xpath('./td/span[5]').textr6 = r6.find_element_by_xpath('./td/span[6]').textr1_list.append(r1)r2_list.append(r2)r3_list.append(r3)r4_list.append(r4)r5_list.append(r5)r6_list.append(r6)
y=list(range(1,31))
print(len(r1_list),len(y))
plt.figure()
plt.title("双色球预测走势图")
ln1, = plt.plot(y,r1_list,color="red")
ln2, = plt.plot(y,r2_list,color="blue")
ln3, = plt.plot(y,r3_list,color="orange")
ln4, = plt.plot(y,r4_list,color="green")
ln5, = plt.plot(y,r5_list,color="black")
ln6, = plt.plot(y,r6_list,color="yellow")
plt.legend(handles=[ln1, ln2,ln3,ln4,ln5,ln6], labels=['一号红球走势', '二号红球走势','三号红球走势','四号红球走势','五号红球走势','六号红球走势'])
plt.show()
运行结果:

当然咯,主要内容不是我这些瞎比比。看代码!!!主要掌握selenium框架与matplotlib的使用方法就行,至于后面的预测阶段。。。这个。。。需要自己设计算法。有兴趣就搞搞看,说不定你找到其中的规律了,那可真的就发了!(苟富贵,勿相忘。
)