我自己的原文哦~ https://blog.51cto.com/whaosoft/12500982
#SAM
今天,Meta发布史上首个图像分割基础模型SAM,将NLP领域的prompt范式引进CV,让模型可以通过prompt一键抠图。网友直呼:CV不存在了!
就在刚刚,Meta AI发布了Segment Anything Model(SAM)——第一个图像分割基础模型。
SAM能从照片或视频中对任意对象实现一键分割,并且能够零样本迁移到其他任务。

整体而言,SAM遵循了基础模型的思路:
1. 一种非常简单但可扩展的架构,可以处理多模态提示:文本、关键点、边界框。
2. 直观的标注流程,与模型设计紧密相连。
3. 一个数据飞轮,允许模型自举到大量未标记的图像。
而且,毫不夸张地说,SAM已经学会了「物体」的一般概念,甚至对于未知物体、不熟悉的场景(例如水下和显微镜下)以及模糊的案例也是如此。
此外,SAM还能够泛化到新任务和新领域,从业者并不需要自己微调模型了。
论文地址:https://ai.facebook.com/research/publications/segment-anything/
最强大的是,Meta实现了一个完全不同的CV范式,你可以在一个统一框架prompt encoder内,指定一个点、一个边界框、一句话,直接一键分割出物体。

对此,腾讯AI算法专家金天表示,「NLP领域的prompt范式,已经开始延展到CV领域了。而这一次,可能彻底改变CV传统的预测思路。这一下你可以真的可以用一个模型,来分割任意物体,并且是动态的!」
英伟达AI科学家Jim Fan对此更是赞叹道:我们已经来到了计算机视觉领域的「GPT-3时刻」!
所以,CV真的不存在了?
SAM:一键「切出」任何图像中的所有对象
Segment Anything是致力于图像分割的第一个基础模型。
分割(Segmentation)是指识别哪些图像像素属于一个对象,一直是计算机视觉的核心任务。
但是,如果想为特定任务创建准确的分割模型,通常需要专家进行高度专业化的工作,这个过程需要训练AI的基础设施,和大量仔细标注的域内数据,因此门槛极高。
为了解决这个问题,Meta提出了一个图像分割的基础模型——SAM。这个接受了多样化数据训练的可提示模型,不仅能适应各种任务,而且操作起来也类似于在NLP模型中使用提示的方式。
SAM模型掌握了「什么是对象」这个概念,可以为任何图像或视频中的任何对象生成掩码,即使是它在训练中没有见过的对象。
SAM具有如此广泛的通用性,足以涵盖各种用例,不需要额外训练,就可以开箱即用地用于新的图像领域,无论是水下照片,还是细胞显微镜。也即是说,SAM已经具有了零样本迁移的能力。
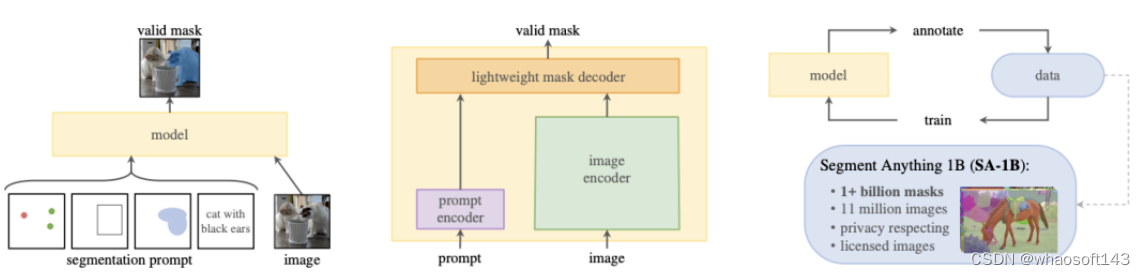
Meta在博客中兴奋地表示:可以预计,在未来,在任何需要在图像中查找和分割对象的应用中,都有SAM的用武之地。
SAM可以成为更大的AI系统的一部分,对世界进行更通用的多模态理解,比如,理解网页的视觉和文本内容。
在AR/VR领域,SAM可以根据用户的视线选择对象,然后把对象「提升」为 3D。
对于内容创作者,SAM可以提取图像区域进行拼贴,或者视频编辑。
SAM还可以在视频中定位、跟踪动物或物体,有助于自然科学和天文学研究。

通用的分割方法
在以前,解决分割问题有两种方法。
一种是交互式分割,可以分割任何类别的对象,但需要一个人通过迭代微调掩码。
第二种是自动分割,可以分割提前定义的特定对象,但训练过程需要大量的手动标注对象(比如要分割出猫,就需要成千上万个例子)。
总之,这两种方式都无法提供通用、全自动的分割方法。
而SAM可以看作这两种方法的概括,它可以轻松地执行交互式分割和自动分割。
在模型的可提示界面上,只要为模型设计正确的提示(点击、框、文本等),就可以完成广泛的分割任务。
另外,SAM在包含超过10亿个掩码的多样化、高质量数据集上进行训练,使得模型能够泛化到新的对象和图像,超出其在训练期间观察到的内容。因此,从业者不再需要收集自己的细分数据,为用例微调模型了。
这种能够泛化到新任务和新领域的灵活性,在图像分割领域尚属首次。

1) SAM 允许用户通过单击一下,或交互式单击许多点,来分割对象,还可以使用边界框提示模型。
(2) 在面对被分割对象的歧义时,SAM可以输出多个有效掩码,这是解决现实世界中分割问题的必备能力。
(3) SAM 可以自动发现、屏蔽图像中的所有对象。(4) 在预计算图像嵌入后,SAM可以实时为任何提示生成分割掩码,允许用户与模型进行实时交互。
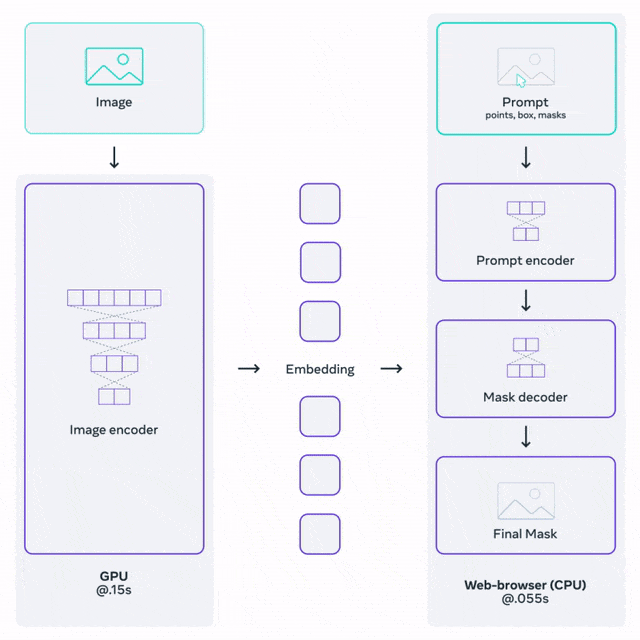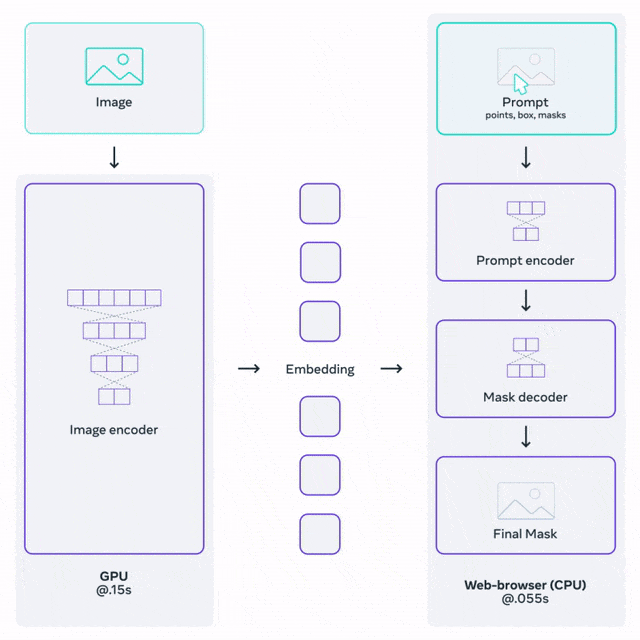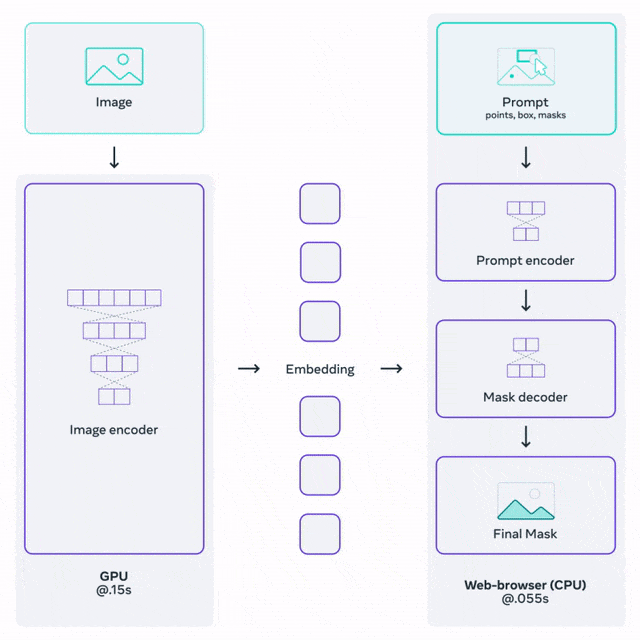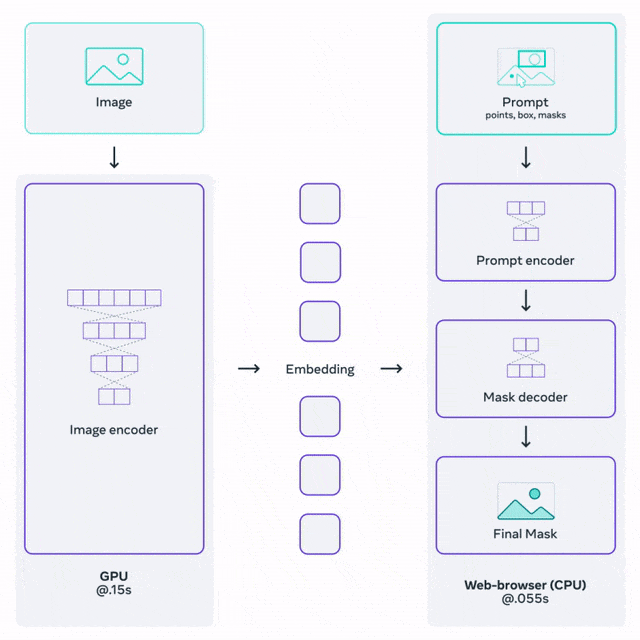
工作原理
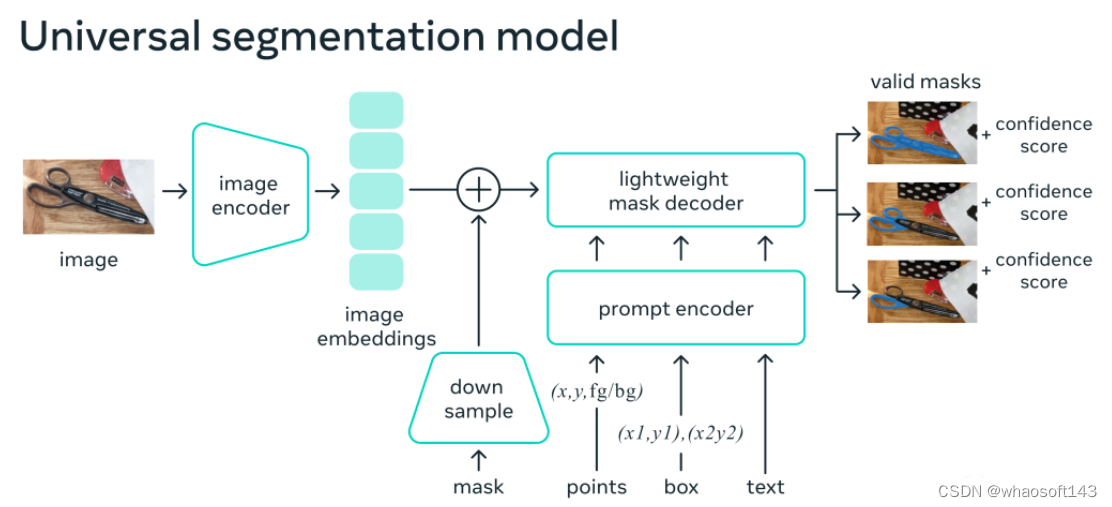
研究人员训练的SAM可以针对任何提示返回有效的分割掩码。提示可以是前景/背景点、粗略的框或掩码、自由形式的文本,或者总体上任何指示图像中需要分割的信息。
有效掩码的要求仅仅意味着即使在提示模糊且可能指代多个对象的情况下(例如,衬衫上的一个点可能表示衬衫或者穿衬衫的人) ,输出应该是其中一个对象的合理掩码。
研究人员观察到,预训练任务和交互式数据收集对模型设计施加了特定的约束。
特别是,该模型需要在网络浏览器中CPU上实时运行,以便让标准人员能够高效实时与SAM互动进行标注。
虽然运行时间的约束,意味着质量与运行时间之间需要权衡,但研究人员发现,在实践中,简单的设计可以取得良好的效果。
SAM的图像编码器为图像产生一次性嵌入,而轻量级解码器将任何提示实时转换为矢量嵌入。然后将这两个信息源在一个预测分割掩码的轻量级解码器中结合起来。
在计算出图像嵌入之后,SAM可以在短短50毫秒内生成一段图像,并在网络浏览器中给出任何提示。
最新SAM模型在256张A100上训练了68小时(近5天)完成。

项目演示多种输入提示
在图像中指定要分割的内容的提示,可以实现各种分割任务,而无需额外的训练。

用互动点和方框作为提示

自动分割图像中的所有元素

为模棱两可的提示生成多个有效的掩码
可提示的设计
SAM可以接受来自其他系统的输入提示。
例如,根据AR/VR头显传来的用户视觉焦点信息,来选择对应的物体。Meta通过发展可以理解现实世界的AI,恰恰为它未来元宇宙之路铺平道路。
或者,利用来自物体检测器的边界框提示,实现文本到物体的分割。

可扩展的输出
输出掩码可以作为其他AI系统的输入。
例如,物体的mask可以在视频中被跟踪,通过成像编辑应用程序,变成3D,或用于拼贴等创造性任务。

零样本的泛化
SAM学会了关于物体是什么的一般概念——这种理解使其能够对不熟悉的物体和图像进行零样本概括,而不需要额外训练。

各种评测
选择Hover&Click,点Add Mask后就出现绿点,点Remove Area后出现红点,吃苹果的花花立刻就被圈出来了。

而在Box功能中,简单框选一下,就立马完成识别。

点Everything后,所有系统识别出的对象立刻全部被提取出来。
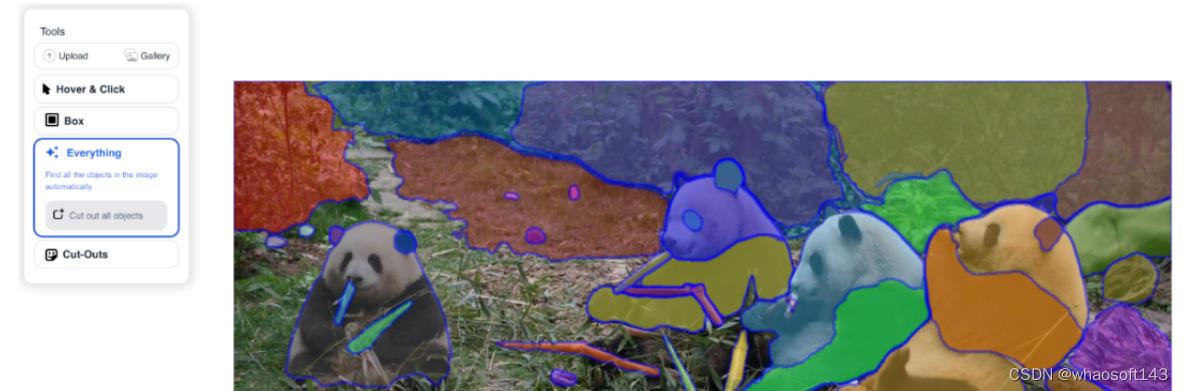
选Cut-Outs后,秒得一个三角团子。

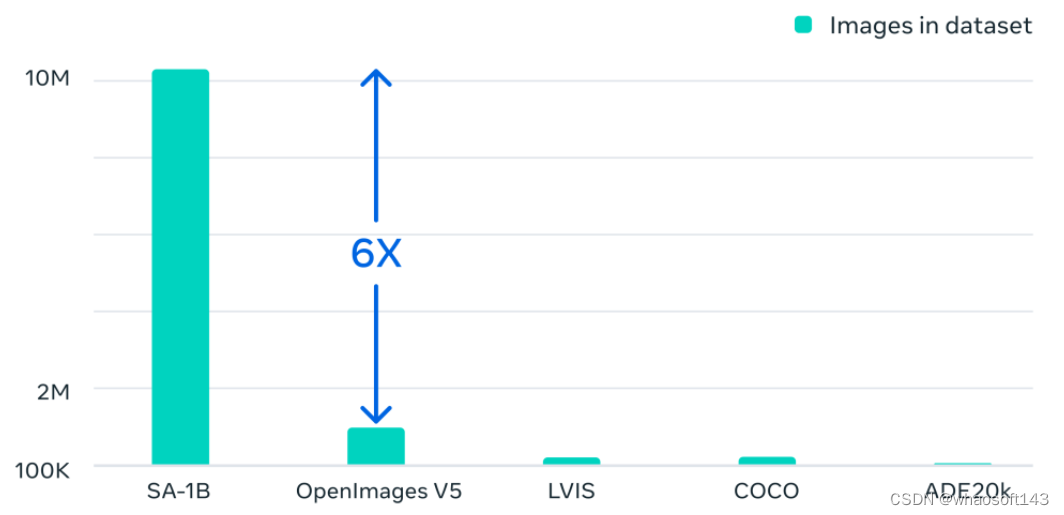
SA-1B数据集:1100万张图像,11亿个掩码
除了发布的新模型,Meta还发布了迄今为止最大的分割数据集SA-1B。
这个数据集由1100万张多样化、高分辨率、保护隐私的图像,以及11亿个高质量分割掩码组成。
数据集的整体特性如下:
· 图像总数: 1100万
· 掩码总数: 11亿
· 每张图像的平均掩码: 100
· 平均图像分辨率: 1500 × 2250 pixels
注意:图像或掩码标注没有类标签
Meta特别强调,这些数据是通过我们的数据引擎收集的,所有掩码均由SAM完全自动生成。
有了SAM模型,收集新的分割掩码的速度比以往任何时候都快,交互式标注一个掩码只需要大约14秒。
每个掩码标注过程只比标注边界框慢2倍,使用最快的标注界面,标注边界框大约需要7秒。
与以前的大规模分割数据收集工作相比,SAM模型COCO完全手动的基于多边形的掩码标注快6.5倍,比以前最大的数据标注工作(也是模型辅助)快2倍。
然而,依赖于交互式标注掩码并不足以创建10亿多个掩码数据集。因此,Meta构建了一个用于创建SA-1B数据集的数据引擎。
这个数据引擎有三个「齿轮」:
1. 模型辅助标注
2. 全自动标注与辅助标注的混合,有助于增加收集到的掩码的多样性
3. 全自动掩码创建,使数据集能够扩展
我们的最终数据集包括超过11亿个分割掩码,这些掩码收集在大约1100万张授权和保护隐私的图像上。
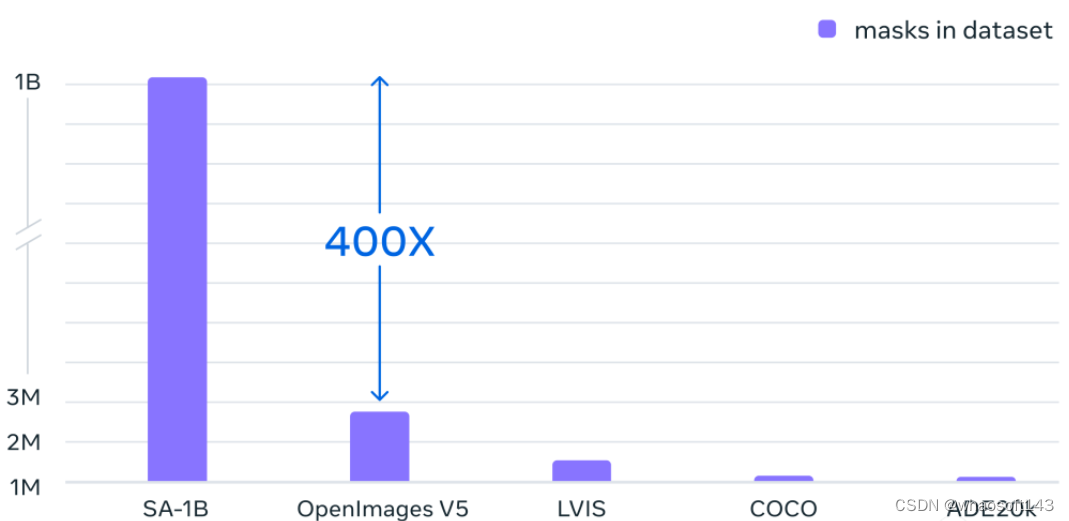
SA-1B比任何现有的分割数据集多出400倍的掩码。并且通过人类评估研究证实,掩码具有高质量和多样性,在某些情况下,甚至在质量上可与之前规模更小、完全手动标注数据集的掩码相媲美。
SA-1B的图片是通过来自多个国家/地区的照片提供商获取的,这些国家/地区跨越不同的地理区域和收入水平。
虽然某些地理区域仍然代表性不足,但SA-1B比以前的分割数据集在所有地区都有更多的图像和更好的整体代表性。
最后,Meta称希望这些数据可以成为新数据集的基础,这些数据集包含额外的标注,例如与每个掩模相关联的文本描述。
RBG大神带队
Ross Girshick

Ross Girshick(常被称为RBG大神)是Facebook人工智能研究院(FAIR)的一名研究科学家,他致力于计算机视觉和机器学习的研究。
2012年,Ross Girshick在Pedro Felzenszwalb的指导下获得了芝加哥大学的计算机科学博士学位。
在加入FAIR之前,Ross是微软研究院的研究员,也是加州大学伯克利分校的博士后,在那里他的导师是Jitendra Malik和Trevor Darrell。
他获得了2017年的PAMI青年研究员奖,2017年和2021年的PAMI Mark Everingham奖,以表彰他对开源软件的贡献。
众所周知,Ross和何恺明大神一起开发了R-CNN方法的目标检测算法。2017年,Ross和何恺明大神的Mask R-CNN论文获得了ICCV 2017最佳论文。
网友:CV真不存在了
Meta打造的这款CV领域的分割基础模型,让许多网友高呼「这下,CV是真不存在了。」

Meta科学家Justin Johnson表示:「对我来说,Segment Anything的数据引擎和ChatGPT的RLHF代表了大规模人工智能的新时代。与其从嘈杂的网络数据中学习一切,不如巧妙地应用人类标注与大数据相结合,以释放新的能力。监督学习强势回归!」

唯一遗憾的是,SAM模型发布主要是由Ross Girshick带队,何恺明却缺席了。

知友「matrix明仔」表示,这篇文章进一步证明多模态才是CV的未来,纯CV是没有明天的。
参考资料:
https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
#Grounded-Segment-Anything
AI 技术的迭代,已经以天为单位。所以,如果你有什么好的想法,最好赶紧做,不然睡一觉可能就被抢先了。
这个被很多人看好的 idea 源于 Meta 两天前发布的「分割一切」AI 模型(Segment Anything Model,简称 SAM)。Meta 表示,「SAM 已经学会了关于物体的一般概念,可以为任何图像或视频中的任何物体生成 mask,甚至包括在训练过程中没有遇到过的物体和图像类型。SAM 足够通用,可以涵盖广泛的用例,并且可以在新的图像『领域』即开即用,无需额外的训练。」

这一模型的发布在计算机视觉领域引发轰动,预示着 CV 也将走向「一个全能基础模型统一某个(某些?全部?)任务」的道路。当然,大家对此早有预感,但没想到这一天来得如此之快。
比基础模型迭代更快的是研究社区「二创」的速度。论文才刚刚发布两天,几位国内工程师就基于此想出了新的点子并将其付诸实践,组建出了一个不仅可以「分割一切」,还能「检测一切」、「生成一切」的视觉工作流模型。

具体来说,他们使用一个 SOTA 的 zero-shot 目标检测器(Grounding DINO)提取物体 box 和类别,然后输入给 SAM 模型出 mask,使得模型可以根据文本输入检测和分割任意物体。另外,他们还将其和 Stable Diffusion 结合做可控的图像编辑。
这个三合一模型项目名叫 Grounded Segment Anything,三种类型的模型既可以分开使用,也可以组合使用。
项目链接:https://github.com/IDEA-Research/Grounded-Segment-Anything
对于 Grounded Segment Anything 未来的用途,项目作者构想了几种可能:
- 可控的、自动的图像生成,用于构建新的数据集;
- 提供更强的基础模型与分割预训练;
- 引入 GPT-4,进一步激发视觉大模型的潜力;
- 一条自动标记图像(带 box 和 mask)并生成新图像的完整 pipeline;
- ……
安装
要实现 SAM+Stable Diffusion 需要一些安装步骤。首先该项目要求 Python 3.8 以上版本,pytorch 1.7 以上版本,torchvision 0.8 以上版本,并安装相关依赖项。项目作者还建议安装支持 CUDA 的 PyTorch 和 TorchVision。
然后,按照如下代码安装 Segment Anything:
python -m pip install -e segment_anything安装 GroundingDINO:
python -m pip install -e GroundingDINO以下是可选依赖项,这些对于掩码后处理、以 COCO 格式保存掩码、example notebook 以及以 ONNX 格式导出模型是必需的。另外,该项目还需要 jupyter 来运行 example notebook。
pip install opencv-python pycocotools matplotlib onnxruntime onnx ipykernel运行 GroundingDINO demo
下载 groundingdino 检查点:
cd Grounded-Segment-Anything
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth运行 demo:
export CUDA_VISIBLE_DEVICES=0
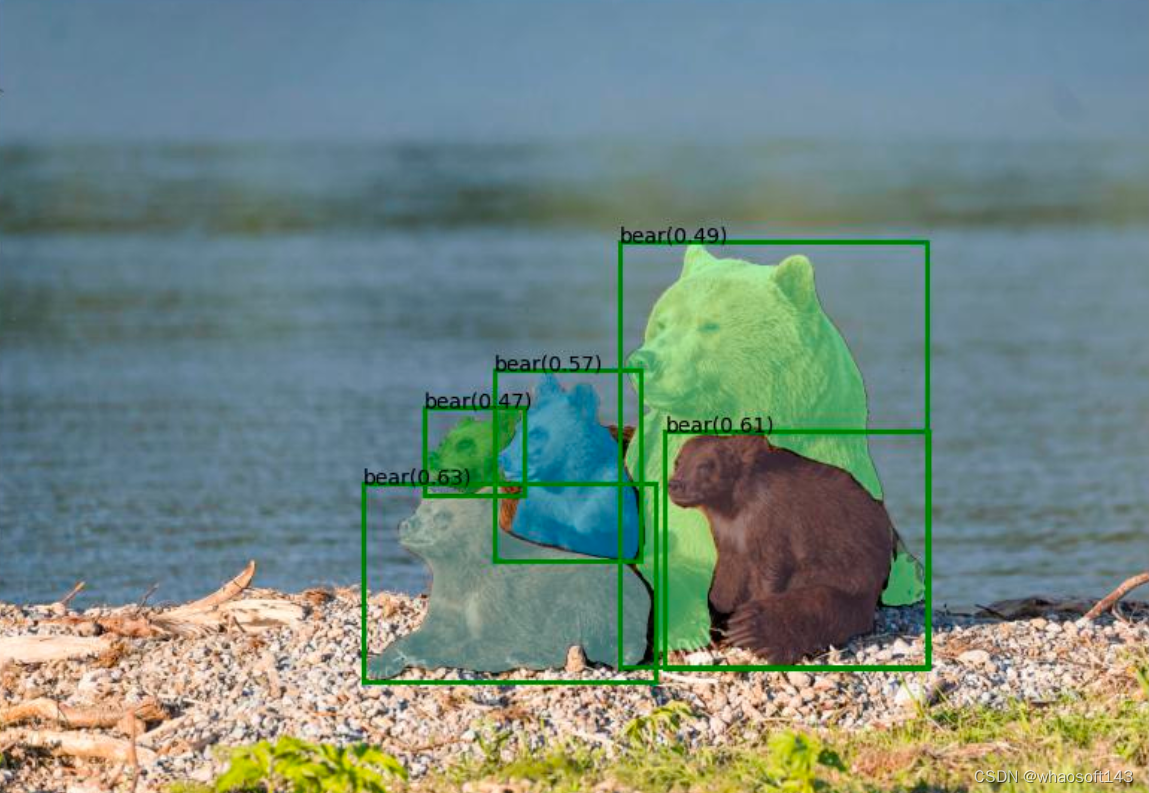
python grounding_dino_demo.py \--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint groundingdino_swint_ogc.pth \--input_image assets/demo1.jpg \--output_dir "outputs" \--box_threshold 0.3 \--text_threshold 0.25 \--text_prompt "bear" \--device "cuda"模型预测可视化将保存在 output_dir 中,如下所示:

运行 Grounded-Segment-Anything Demo
下载 segment-anything 和 ground- dino 的检查点:
cd Grounded-Segment-Anything
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
wget https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth运行 demo:
export CUDA_VISIBLE_DEVICES=0
python grounded_sam_demo.py \--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint groundingdino_swint_ogc.pth \--sam_checkpoint sam_vit_h_4b8939.pth \--input_image assets/demo1.jpg \--output_dir "outputs" \--box_threshold 0.3 \--text_threshold 0.25 \--text_prompt "bear" \--device "cuda"模型预测可视化将保存在 output_dir 中,如下所示:
运行 Grounded-Segment-Anything + Inpainting Demo
CUDA_VISIBLE_DEVICES=0
python grounded_sam_inpainting_demo.py \--config GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py \--grounded_checkpoint groundingdino_swint_ogc.pth \--sam_checkpoint sam_vit_h_4b8939.pth \--input_image assets/inpaint_demo.jpg \--output_dir "outputs" \--box_threshold 0.3 \--text_threshold 0.25 \--det_prompt "bench" \--inpaint_prompt "A sofa, high quality, detailed" \--device "cuda"运行 Grounded-Segment-Anything + Inpainting Gradio APP
python gradio_app.py#MobileSAM
本文提出一种"解耦蒸馏"方案对SAM的ViT-H解码器进行蒸馏,同时所得轻量级编码器可与SAM的解码器"无缝兼容" 。在推理速度方面,MobileSAM处理一张图像仅需10ms,比FastSAM的处理速度快4倍。
arXiv:https://arxiv.org/abs/2306.14289
code:https://github.com/ChaoningZhang/MobileSAM
SAM(Segment Anything Model)是一种提示词引导感兴趣目标分割的视觉基础模型。自提出之日起,SAM引爆了CV社区,也衍生出了大量相关的应用(如检测万物、抠取万物等等),但是受限于计算量问题,这些应用难以用在移动端。
本文旨在将SAM的"重量级"解码器替换为"轻量级"以使其可在移动端部署应用。为达成该目标,本文提出一种"解耦蒸馏"方案对SAM的ViT-H解码器进行蒸馏,同时所得轻量级编码器可与SAM的解码器"无缝兼容" 。此外,所提方案,只需一个GPU不到一天时间即可完成训练,比SAM小60倍且性能相当,所得模型称之为MobileSAM。在推理速度方面,MobileSAM处理一张图像仅需10ms(8ms@Encoder,2ms@Decoder),比FastSAM的处理速度快4倍,这就使得MobileSAM非常适合于移动应用。
SAM
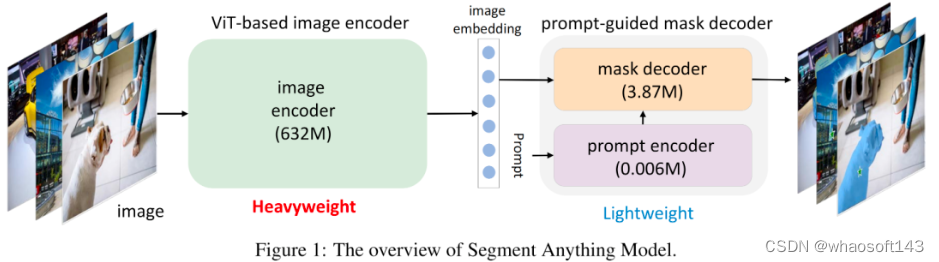
上图给出了SAM架构示意图,它包含一个"重量级"ViT编码器与一个提示词引导Mask解码器。解码器以图像作为输入,输出将被送入Mask解码器的隐特征(embedding);Mask解码器将基于提示词(如point、bbox)生成用于目标分割的Mask。此外,SAM可以对同一个提示词生成多个Mask以缓解"模棱两可"问题。更多关于SAM及衍生技术可参考文末推荐阅读材料。

延续SAM架构体系:采用轻量级ViT解码器生成隐特征,然后采用提示词引导解码器生成期望的Mask。本文目标:构建一个移动端友好的SAM方案MobileSAM,即比原生SAM更快且具有令人满意的性能。考虑到SAM不同模块之间的参数量问题,本文主要聚焦于采用更轻量型的Encoder替换SAM的重量级Encoder。
实现方案
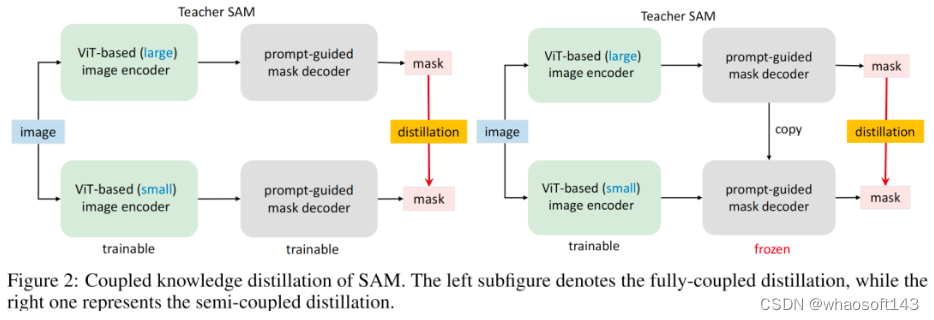
Coupled Distillation 一种最直接的方式是参考SAM方案重新训练一个具有更小Encoder的SAM,见Figure2左图。如SAM一文所提到:SAM-ViT-H的训练需要256个A100,且训练时间达68小时;哪怕Encoder为ViT-B也需要128个GPU。这样多的资源消耗无疑阻碍了研究人员进行复现或改进。此外,需要注意的是SAM所提供数据集的Mask是有预训练SAM所生成,本质上讲,重训练过程也是一种知识蒸馏过程,即讲ViT-H学习到的知识迁移到轻量级Encoder中。
Semi-coupled Distillation 当对原生SAM进行知识蒸馏时,主要困难在于: Encoder与Decoder的耦合优化,两者存在互依赖。有鉴于此,作者将整个知识蒸馏过程拆解为Encoder蒸馏+Decoder微调,该方案称之为半耦合蒸馏(Semi-coupled Distillation),见Figure2右图。也就是说,我们首先对Encoder进行知识蒸馏,然后再与Decoder进行协同微调。
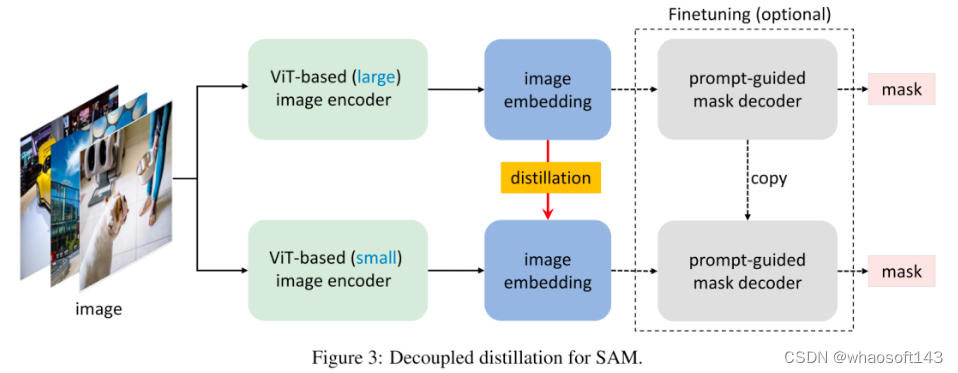
Decoupled Distillation 根据经验,我们发现这种半耦合蒸馏方案仍然极具挑战性,这是因为提示词的选择具有随机性,使得Decoder可变,进而导致优化变难。有鉴于此,作者提出直接对原生SAM的编码器进行蒸馏且无需与Decoder组合,该方案称之为解耦合蒸馏。该方案的一个优势在于:仅需使用MSE损失即可,而无需用于Mask预测的Focal与Dice组合损失。
Necessity of Mask Decoder Finetuning 不同于半耦合蒸馏,经解耦合蒸馏训练得到的轻量级Encoder可能与冻结的Decoder存在不对齐问题。根据经验,我们发现:该现象并不存在。这是因为学生Encoder生成的隐特征非常接近于原始老师Encoder生成的隐特征,因此并不需要与Decoder进行组合微调。当然,进一步的组合微调可能有助于进一步提升性能。
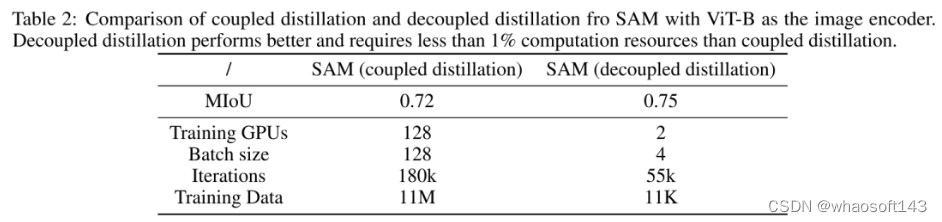
Preliminary Evaluation 上表对比了耦合蒸馏与解耦合蒸馏的初步对比。可以看到:
- 从指标方面,解耦合蒸馏方案指标稍高,0.75mIoU vs 0.72mIoU;
- 从训练GPU方面,解耦合蒸馏方案仅需两个GPU,远小于耦合蒸馏方案的128卡,大幅降低了对GPU的依赖;
- 从迭代次数方面,解耦合蒸馏方案仅需55k次迭代,远小于耦合蒸馏方案的180K,大幅降低了训练消耗;
- 从训练数据方面,解耦合蒸馏方案仅需11K数据量,远小于耦合蒸馏方案的11M,大幅降低了数据依赖。
尽管如此,但ViT-B对于移动端部署仍然非常困难。因此,后续实验主要基于TinyViT进行。
本文实验

在具体实现方面,作者基于ViT-Tiny进行本文所提方案的有效性验证,所得MobileSAM与原生SAM的参数+速度的对比可参考上表。在训练方面,仅需SA-1B的1%数据量+单卡(RTX3090),合计训练8个epoch,仅需不到一天即可完成训练

上述两个图给出了point与bbox提示词下MobileSAM与原生SAM的结果对比,可以看到:MobileSAM可以取得令人满意的Mask预测结果。
消融实验
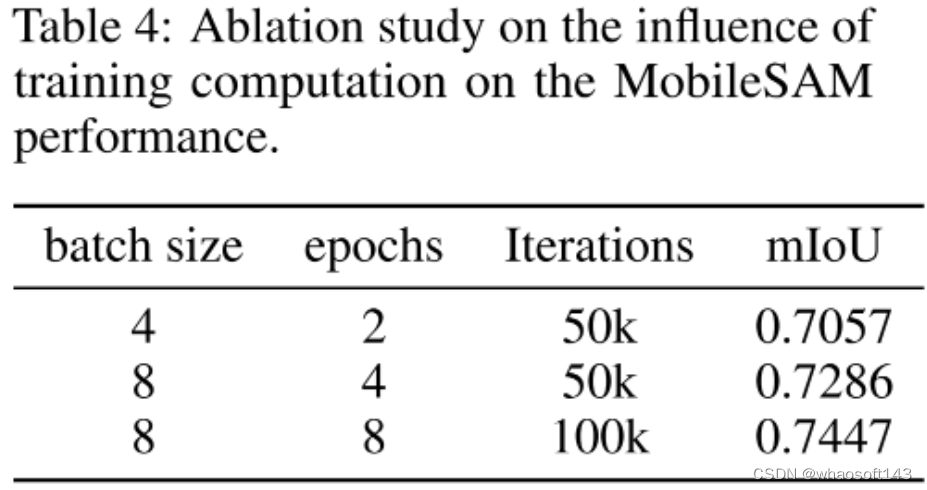
上表从训练超参bs、epoch、iter等维度进行了对比分析,可以看到:
- 在同等迭代次数下,提升bs可以进一步提升模型性能;
- 在同等bs下,提升iter可以进一步提升模型性能。

上报对比了FastSAM与MobileSAM,可以看到:
- 从参数量方面,MobileSAM只有不到10M的参数量,远小于FastSAM的68M;
- 从处理速度方面,MobileSAM仅需10ms,比FastSAM的40ms快4倍.

上图从Segment everything角度对比了SAM、FastSAM以及MobileSAM三个模型,可以看到:
- MobileSAM与原生SAM结果对齐惊人的好,而FastSAM会生成一些无法满意的结果;
- FastSAM通常生成非平滑的边缘,而SAM与MobileSAM并没有该问题。
最后,补充一下Segment Anything与Segment Everything之间的区别。
- 如SAM一文所提到,SAM通过提示词进行物体分割,也就是说,提示词的作用是指定想分割哪些物体。理论上讲,当给定合适的提示词后,任何目标都可以被分割,故称之为
Segment Anything。 - 相反,
Segment Everything本质上是物体候选框生成过程,不需要提示词。故它往往被用来验证下游任务上的zero-shot迁移能力。
总而言之,Segment Anything解决了任意物体的提示分割基础任务;Segment Everything则解决了所有物体面向下游任务的候选框生成问题。
#Relate-Anything-Model(RAM)
RAM 模型赋予了 Segment Anything Model(SAM)识别不同视觉概念之间的各种视觉关系的能力。
Meta 推出的「分割一切(Segment Anything Model,SAM)」模型引起了广泛的关注。最近,来自南洋理工大学 MMLab 团队、伦敦国王学院和同济大学 VisCom 实验室的研究者们联合推出了一款名为 「Relate-Anything-Model(RAM)」的新模型。RAM 模型赋予了 Segment Anything Model(SAM)识别不同视觉概念之间的各种视觉关系的能力。该模型由同学利用闲暇时间合作开发。
- 演示程序链接:https://huggingface.co/spaces/mmlab-ntu/relate-anything-model
- 代码链接:https://github.com/Luodian/RelateAnything
- 数据集链接:https://github.com/Jingkang50/OpenPSG
RAM 模型基于 ECCV'22 SenseHuman Workshop & 国际算法算例大赛 “Panoptic Scene Graph Generation” 赛道冠军方案 GRNet。首先,我们来了解一下PSG baseline的基本信息和 GRNet 的工作原理。
PSG baseline
PSG 挑战赛奖金百万,共收到来自全球 100 支团队提交的各种解决方案,其中包括先进的图像分割方法、解决长尾问题等等。该竞赛还收到了一些创新性的方法,如场景图专用的数据增强技术。经过评估,考虑性能指标、解决方案的新颖性和意义等,小红书团队的 GRNet 脱颖而出,成为获胜方案。

比赛详情请参考:https://github.com/Jingkang50/OpenPSG
在介绍 PSG 挑战赛的获胜方案之前,我们首先介绍两个经典的 PSG 基线方法,其中一个是双阶段方法,另一个是单阶段方法。如下图(a)所示,双阶段基线方法在第一阶段使用预训练的全景分割模型 Panoptic FPN 从图像中提取特征、分割和分类预测。然后,将每个个体对象的特征提供给经典的场景图生成器(例如 IMP),以便在第二阶段进行适应 PSG 任务的场景图生成。该双阶段方法让经典的 SGG 方法以最少的修改适应 PSG 任务。
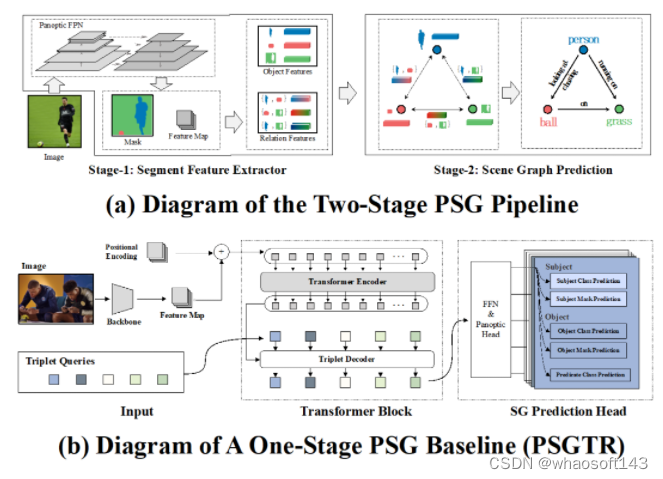
如上图(b)所示,单阶段基线方法 PSGTR 首先使用 CNN 提取图像特征,然后使用类似 DETR 的 transformer 编码器 - 解码器来直接学习三元组表示。其中,匈牙利匹配器用于将预测的三元组与 ground truth 三元组进行比较,然后优化目标最大化匹配器计算的成本,并使用交叉熵进行分类损失,使用 DICE/F-1 计算分割的损失。
冠军方案模型架构
PSG 任务的获胜团队提出了一种名为 GRNet 的新方法。PSG 原文的研究已经表明:单阶段模型目前表现优于双阶段模型,因此获胜团队推测,这主要是因为来自图像特征图的直接监督信号有利于捕捉关系。然而,获胜团队还发现,单阶段模型通常无法达到良好的分割性能。
基于这一观察,获胜方案旨在在两个模式之间找到一个权衡,通过重视双阶段范式并赋予其类似于单阶段范式中获取全局上下文的能力来实现。具体来说,如下图所示,获胜团队首先采用 Mask2Former 等现成的全景分割方法生成每个对象的分割。然后将来自分割器的特定对象的中间特征映射与其对应的分割融合成对象级别特征。获胜团队提出了一种全局上下文模块,利用处理全局信息特征映射的 transformer 处理每个对象级别内容。
值得注意的是,该方案还添加了一个类别嵌入以指示对象的类别。通过 transformer 编码器中的交叉注意力机制,输出的对象特征从其他对象中收集了更多的全局信息。最后,该方案对每个对象级别特征执行全局平均池化,以进一步生成上下文丰富的新对象嵌入。对于每个关系类别,执行关系二元分类任务以确定对象对之间是否存在关系。
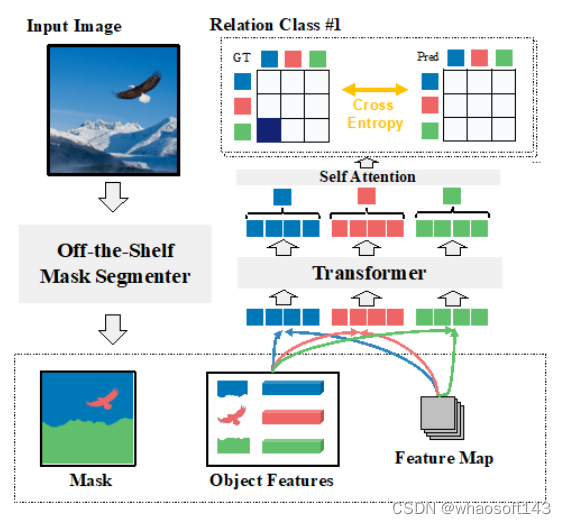
冠军方案关系分类
获胜团队对关系二元分类任务还有一些特别的考虑。例如,他们注意到 PSG 数据集通常包含两个具有多个关系的对象,例如 “人看着大象” 和 “人喂大象” 同时存在。为了解决这个问题,他们的解决方案是将关系预测从单标签分类问题转换为多标签分类问题。
此外,获胜团队还意识到,PSG 数据集通过要求注释者选择特定和准确的谓词(如 “停在” 而不是更一般的 “在”)来追求精度和相关性,可能不适合学习边界关系(如 “在” 实际上与 “停在” 同时存在)。为了解决这个问题,获胜团队提出了一种自我训练策略,使用自我蒸馏标签进行关系分类,并使用指数移动平均(EMA)来动态更新标签。
冠军方案的其他设计
在计算关系二元分类损失时,每个预测对象必须与其对应的 ground truth 对象配对。匈牙利匹配算法能完成这个任务,但该算法容易出现不稳定的情况,特别是在网络准确度低的早期训练阶段。这可能导致对于相同的输入,产生不同的匹配结果,导致网络优化方向不一致,使训练变得更加困难,这个问题通常被称为 “匹配抖动”。为了解决该问题,获胜团队采用了去噪训练,其中将嘈杂的真实结果以快捷方式输入到解码器中,以学习相对偏移量,跳过匹配步骤,允许直接学习方法,有效地克服了匹配抖动带来的挑战。
冠军方案获奖理由
PSG 挑战的获胜解决方案 GRNet 旨在重新使用双阶段范式并赋予其像单阶段范式一样获取全局上下文的能力,以实现双阶段和单阶段两种范式之间的平衡。GRNet 首先采用全景分割方法生成每个对象的分割。然后将来自分割器的特定对象的中间特征映射和其对应的分割融合成对象级别特征。获胜团队通过使用 transformer 处理每个对象级别内容并利用交叉注意力机制进一步丰富全局特征映射来构建全局上下文模块。最后,对每个对象级别特征执行全局平均池化以生成新的对象嵌入。对于每个关系类别,执行关系二元分类任务以确定对象对之间是否存在关系。
获胜团队解决了许多挑战,例如双阶段范式利用全局信息的方法、关系精度和概括性之间的冲突,以及轻量级双阶段范式的计算效率。最终,获胜方案在所有参与者中获得了最好的总体得分。
RAM 模型
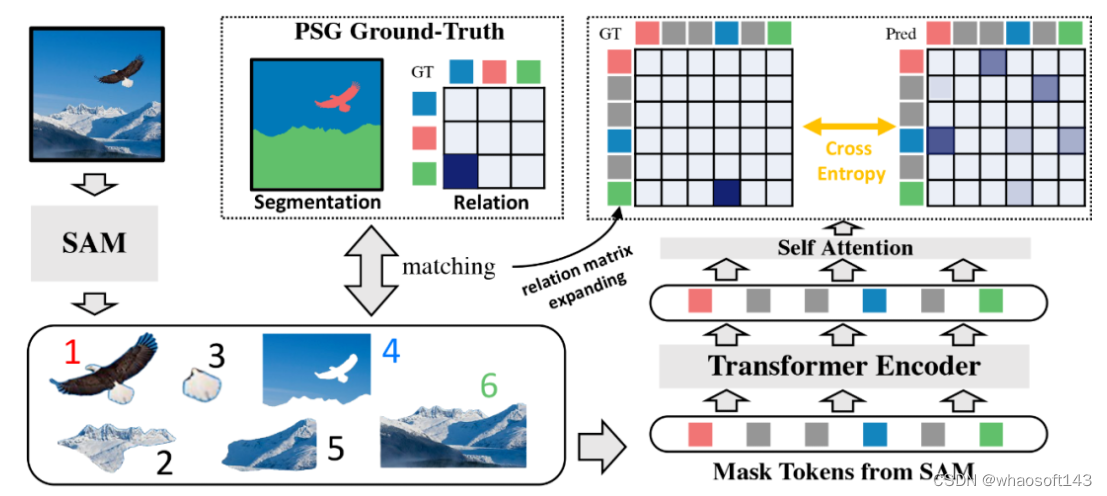
RAM 模型大致的设计思路是:利用 Segment Anything Model(SAM)来识别和分割图像中的物体,并提取每个分割物体的特征。RAM 使用 Transformer 模块使分割物体之间产生交互作用,从而得到新的特征,计算它们的配对关系并分类它们的相互关系。相比于 GRNet,RAM 做了如下简易的修改:
1. 利用 Segment Anything Model(SAM)作为特征提取器,代替原方案的 mask2former。
2. 新 GT 匹配:由于 RAM 研究团队使用 PSG 数据集来训练模型,对于每个训练图像,SAM 会分割多个物体,但只有少数与 PSG 的 ground truth(GT)mask 相匹配。RAM 研究团队根据它们的交集 - 并集(IOU)分数进行简单的匹配,以便(几乎)每个 GT mask 都被分配到一个 SAM mask 中。然后,该研究根据 SAM 的 mask 重新生成关系图,最后使用交叉熵损失来训练 RAM 模型。
RAM 方案整体流程如下图所示:
我们来看一些「Relate-Anything-Model(RAM)」的应用实例。如下图所示,RAM 模型实现的图像分析结果令人印象深刻。这些结果展示了 RAM 模型出色的性能和多样化应用的潜力。
感兴趣的读者可以访问 RAM 模型的 Huggingface 演示页面和数据集,了解更多研究细节。研究团队表示希望 RAM 模型能够为使用者带来启发和创新,并期待获得反馈和建议。
#A Comprehensive Survey on Segment Anything Model for Vision and Beyond
作为首个全面介绍基于 SAM 基础模型进展的研究,本文聚焦于 SAM 在各种任务和数据类型上的应用,并讨论了其历史发展、近期进展,以及对广泛应用的深远影响。
人工智能(AI)正在向 AGI 方向发展,这是指人工智能系统能够执行广泛的任务,并可以表现出类似于人类的智能水平,狭义上的 AI 就与之形成了对比,因为专业化的 AI 旨在高效执行特定任务。可见,设计通用的基础模型迫在眉睫。基础模型在广泛的数据上训练,因而能够适应各种下游任务。最近 Meta 提出的分割一切模型(Segment Anything Model,SAM)突破了分割界限,极大地促进了计算机视觉基础模型的发展。
SAM 是一个提示型模型,其在 1100 万张图像上训练了超过 10 亿个掩码,实现了强大的零样本泛化。许多研究人员认为「这是 CV 的 GPT-3 时刻,因为 SAM 已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为 CV 基本模型的巨大潜力。
为了充分了解 SAM,来自香港科技大学(广州)、上海交大等机构的研究者对其进行了深入研究并联合发表论文《 A Comprehensive Survey on Segment Anything Model for Vision and Beyond 》。
论文地址:https://arxiv.org/pdf/2305.08196.pdf
作为首个全面介绍基于 SAM 基础模型进展的研究,该论文聚焦于 SAM 在各种任务和数据类型上的应用,并讨论了其历史发展、近期进展,以及对广泛应用的深远影响。
本文首先介绍了包括 SAM 在内的基础模型的背景和术语,以及对分割任务有重要意义的最新方法;
然后,该研究分析并总结了 SAM 在各种图像处理应用中的优势和限制,包括软件场景、真实世界场景和复杂场景,重要的是,该研究得出了一些洞察,以指导未来的研究发展更多用途广泛的基础模型并改进 SAM 的架构;
最后该研究还总结了 SAM 在视觉及其他领域的应用。
下面我们看看论文具体内容。
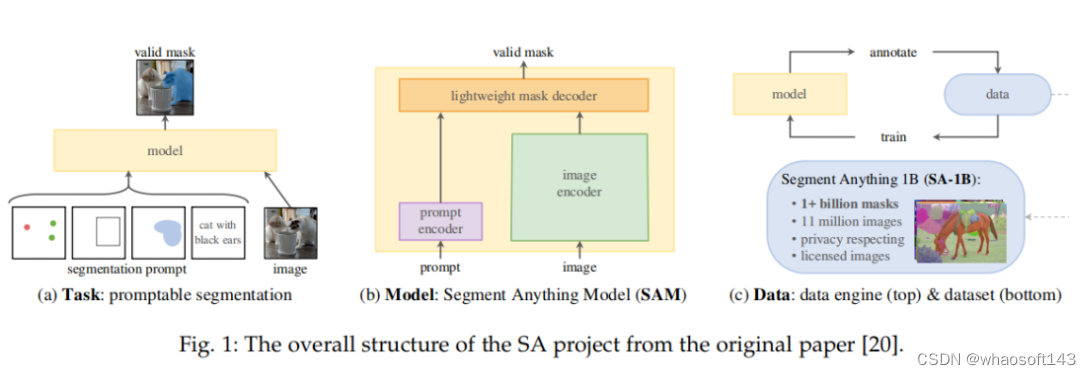
SAM 模型概览
SAM 源自于 2023 年 Meta 的 Segment Anything (SA) 项目。该项目发现在 NLP 和 CV 领域中出现的基础模型表现出较强的性能,研究人员试图建立一个类似的模型来统一整个图像分割任务。然而,在分割领域的可用数据较为缺乏,这与他们的设计目的不同。因此,如图 1 所示,研究者将路径分为任务、模型和数据三个步骤。
SAM 架构如下所示,主要包含三个部分:图像编码器;提示编码器;以及掩码解码器。
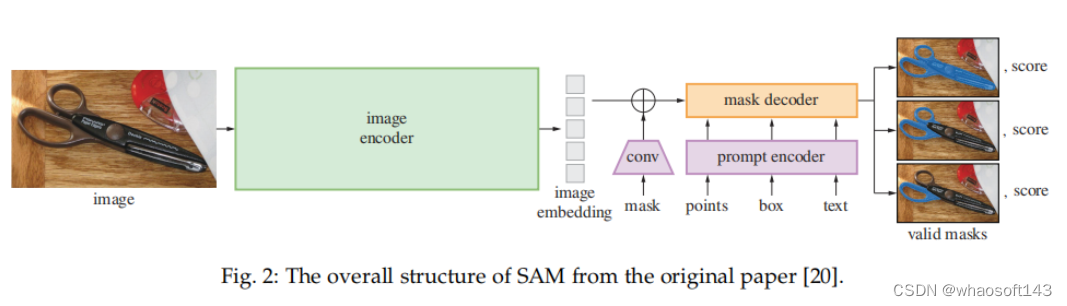
在对 SAM 有了初步认知后,接下来该研究介绍了 SAM 用于图像处理。
SAM 用于图像处理
这部分主要分场景进行介绍,包括:软件场景、真实场景以及复杂场景。
软件场景
软件场景需要对图像编辑和修复进行操作,例如移除对象、填充对象和替换对象。然而,现有的修复工作,如 [99]、[100]、[101]、[102],需要对每个掩码进行精细的注释以达到良好的性能,这是一项劳动密集型的工作。SAM [20] 可以通过简单的提示如点或框来生成准确的掩码,可以帮助辅助图像编辑场景。
Inpaint Anything (IA) [39] 设计了一个流程,通过结合 SAM 的优势、最先进的图像修复器 [99],以及 AI 生成的内容模型 [103],来解决与修复相关的问题。这个流程如图 3 所示。对于对象移除,该流程由 SAM 和最先进的修复器组成,如 LaMa [99]。用户的点击操作被用作 SAM 的提示,以生成对象区域的掩码,然后 LaMa 使用 corrosion 和 dilation 操作进行填充。对于对象的填充和替换,第二步使用像 Stable Diffusion (SD) [103] 这样的 AI 生成的内容模型,通过文本提示用新生成的对象填充选定的对象。
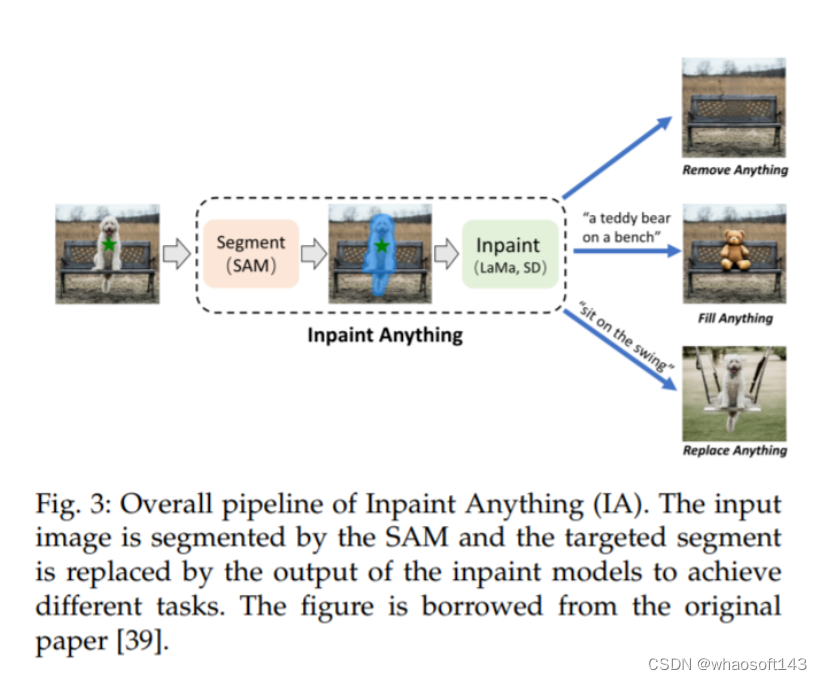
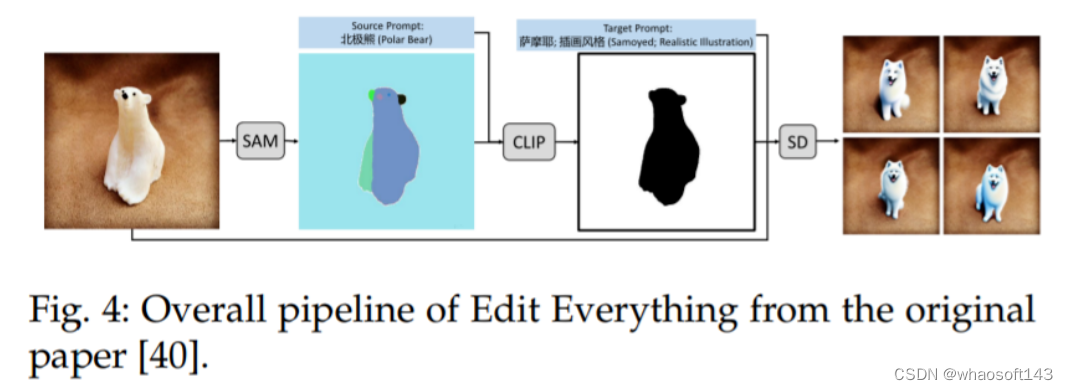
一个类似的想法也可以在 Edit Everything [40] 中看到,如图 4 所示,该方法允许用户使用简单的文本指令编辑图像。
真实场景
研究者表示 SAM 具有协助处理许多真实世界场景的能力,例如真实世界的物体检测、物体计数以及移动物体检测场景。最近,[108] 对 SAM 在多种真实世界分割场景(例如,自然图像、农业、制造业、遥感和医疗健康场景)中的性能进行了评估。该论文发现,在像自然图像这样的常见场景中,它具有优秀的泛化能力,而在低对比度的场景中,它的效果较差,而且在复杂场景中需要强大的先验知识。
例如,在民用基础设施缺陷评估的应用中,[42] 利用 SAM 来检测混凝土结构中的裂缝,并将其性能与基线 U-Net [109] 进行比较。裂缝检测过程如图 6 所示。结果显示,SAM 在检测纵向裂缝方面表现优于 UNet,这些裂缝更可能在正常场景中找到类似的训练图像,而在不常见的场景,即剥落裂缝方面,SAM 的表现不如 U-Net。
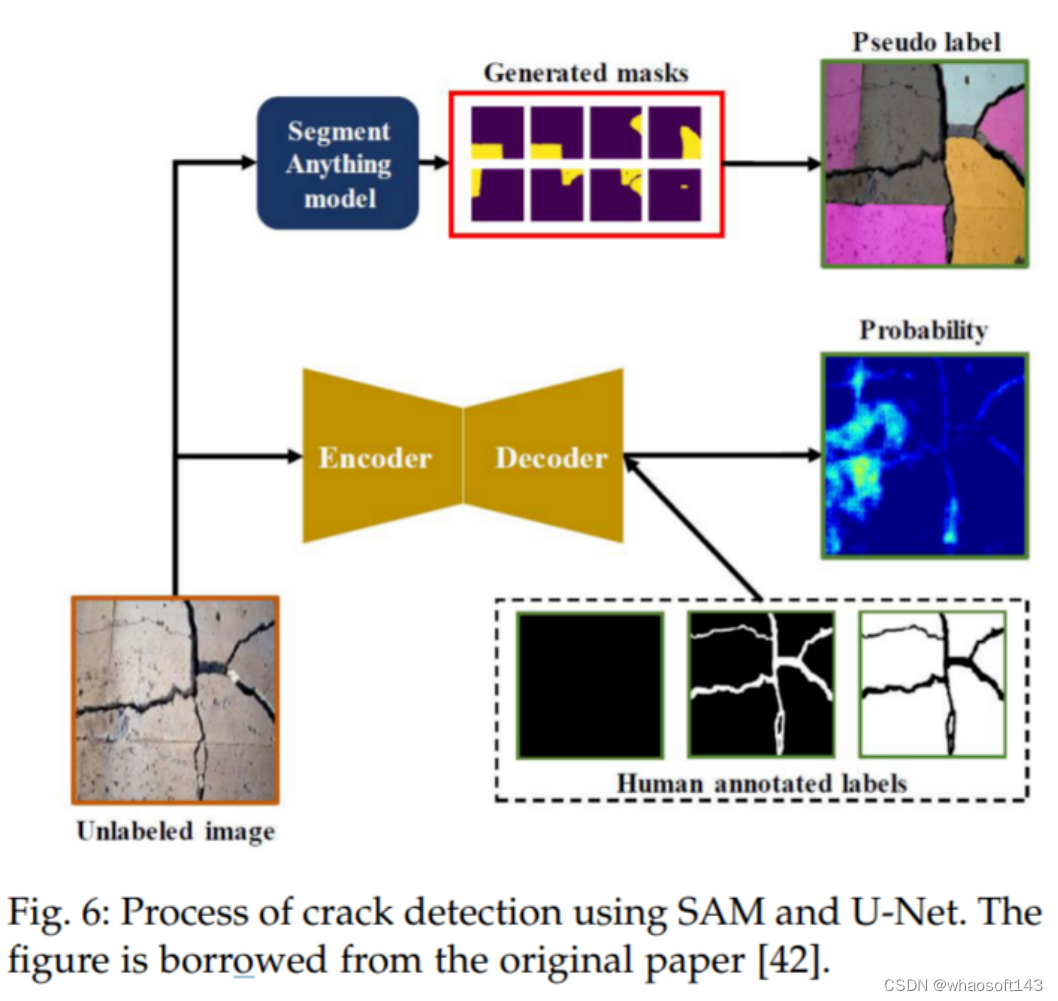
使用 SAM 和 U-Net 进行裂纹检测的过程。图摘自原论文 [42]。
与裂缝检测中的复杂图像案例不同,由于陨石坑的形状主要集中在圆形或椭圆形,所以使用 SAM 作为检测工具来进行陨石坑检测更为合适。陨石坑是行星探索中最重要的形态特征之一,检测和计数它们是行星科学中一个重要但耗时的任务。尽管现有的机器学习和计算机视觉工作成功地解决了陨石坑检测中的一些特定问题,但它们依赖于特定类型的数据,因此在不同的数据源中无法很好地工作。
在 [110] 中,研究者提出了一种使用 SAM 对不熟悉对象进行零样本泛化的通用陨石坑检测方案。这个流程使用 SAM 来分割输入图像,对数据类型和分辨率没有限制。然后,它使用圆形 - 椭圆形指数来过滤不是圆形 - 椭圆形的分割掩码。最后,使用一个后处理过滤器来去除重复的、人为的和假阳性的部分。这个流程在当前领域显示出其作为通用工具的巨大潜力,并且作者还讨论了只能识别特定形状的缺点。
复杂场景
除了上述的常规场景,SAM 是否能解决复杂场景(如低对比度场景)中的分割问题,也是一个有意义的问题,可以扩大其应用范围。为了探索 SAM 在更复杂场景中的泛化能力,Ji 等人 [22] 在三种场景,即伪装动物、工业缺陷和医学病变中,定量地将其与尖端模型进行比较。他们在三个伪装物体分割(COS)数据集上进行实验,即拥有 250 个样本的 CAMO [116],拥有 2026 个样本的 COD10K [117],以及拥有 4121 个样本的 NC4K [118]。并将其与基于 Transformer 的模型 CamoFormer-P/S [119] 和 HitNet [120] 进行比较。结果表明,SAM 在隐蔽场景中的技巧不足,并指出,潜在的解决方案可能依赖于在特定领域的先验知识的支持。在 [29] 中也可以得出同样的结论,作者在上述同样的三个数据集上,将 SAM 与 22 个最先进的方法在伪装物体检测上进行比较。
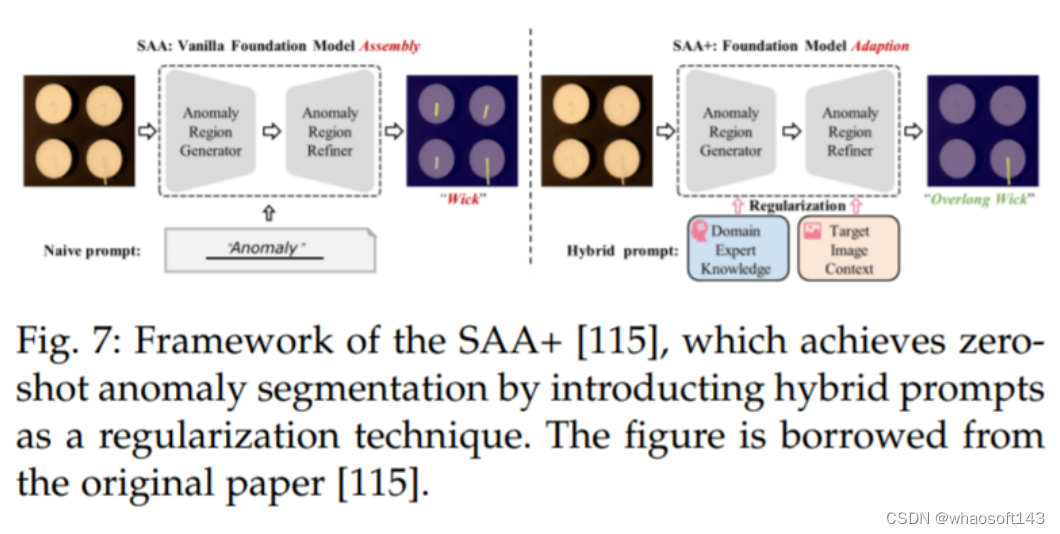
Cao 等人 [115] 提出了一个新的框架,名为 Segment Any Anomaly + (SAA+),用于零样本异常分割,如图 7 所示。该框架利用混合提示规范化来提高现代基础模型的适应性,从而无需领域特定的微调就能进行更精确的异常分割。作者在四个异常分割基准上进行了详细的实验,即 VisA [122],MVTecAD [123],MTD [124] 和 KSDD2 [125],并取得了最先进的性能。
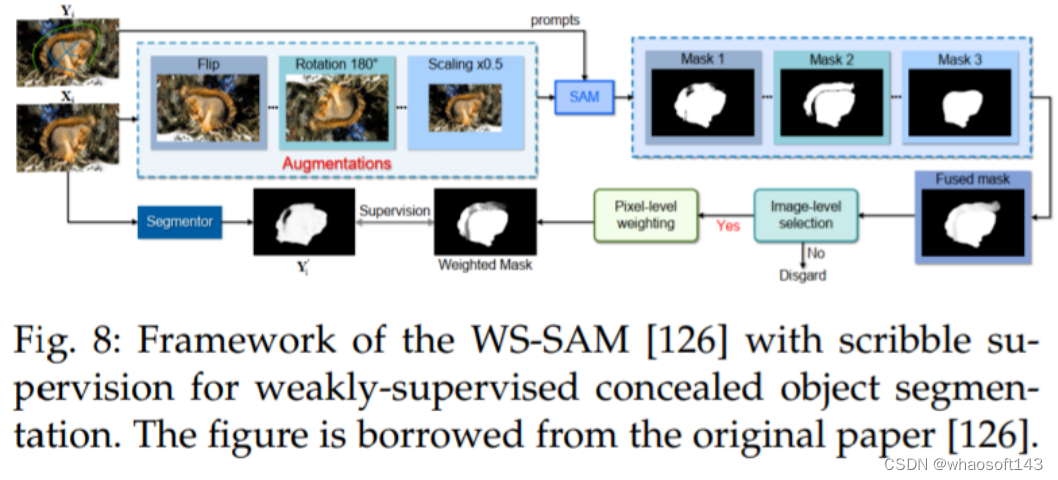
He 等人 [126] 提出了第一种方法(WSSAM),利用 SAM 进行弱监督隐蔽物体分割,解决了使用稀疏注释数据分割与周围环境融为一体的物体的挑战(参见图 8)。所提出的 WSSAM 包括基于 SAM 的伪标记和多尺度特征分组,以提高模型学习和区分隐蔽物体和背景。作者发现,仅使用 scribble 监督 [127],SAM 就可以生成足够好的分割掩码,以训练分割器。
更多模型和应用:视觉及其他
视觉相关
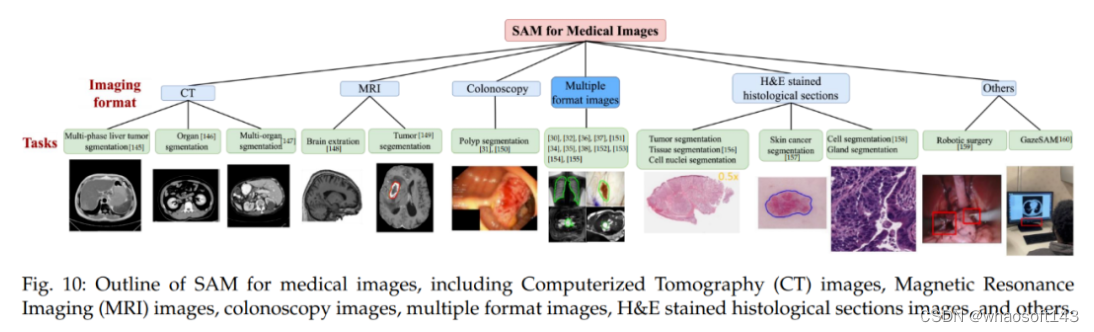
首先是医疗成像。医疗图像分割的目的是展示相应组织的解剖或病理结构,可以用于计算机辅助诊断和智能临床手术。
下图 10 为医疗图像 SAM 概览,包括了计算机断层扫描(CT)图像、磁共振成像(MRI)图像、结肠镜检查图像、多格式图像、H&E 染色组织切片图像等。
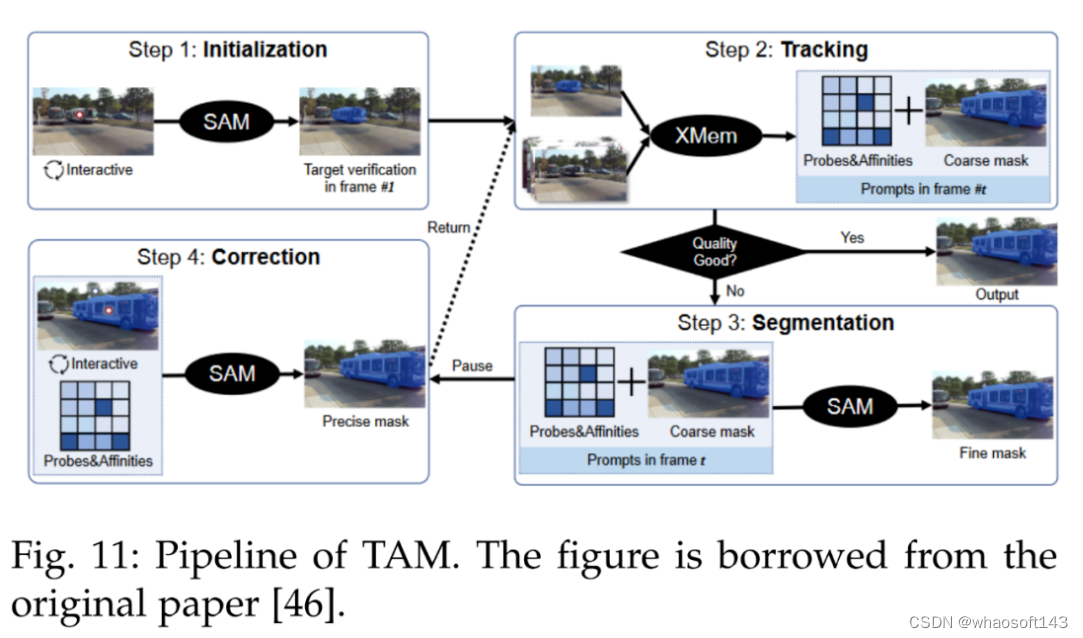
其次是视频。在计算机视觉领域,视频目标跟踪(VOT)和视频分割被认为是至关重要且不可或缺的任务。VOT 涉及在视频帧中定位特定目标,然后在整个视频的其余部分对其进行跟踪。因此,VOT 具有各种实际应用,例如监视和机器人技术。
SAM 在 VOT 领域做出了杰出贡献。参考文献 [46] 中引入了跟踪一切模型(Track Anything Model, TAM),高效地在视频中实现了出色的交互式跟踪和分割。下图 11 为 TAM pipeline。
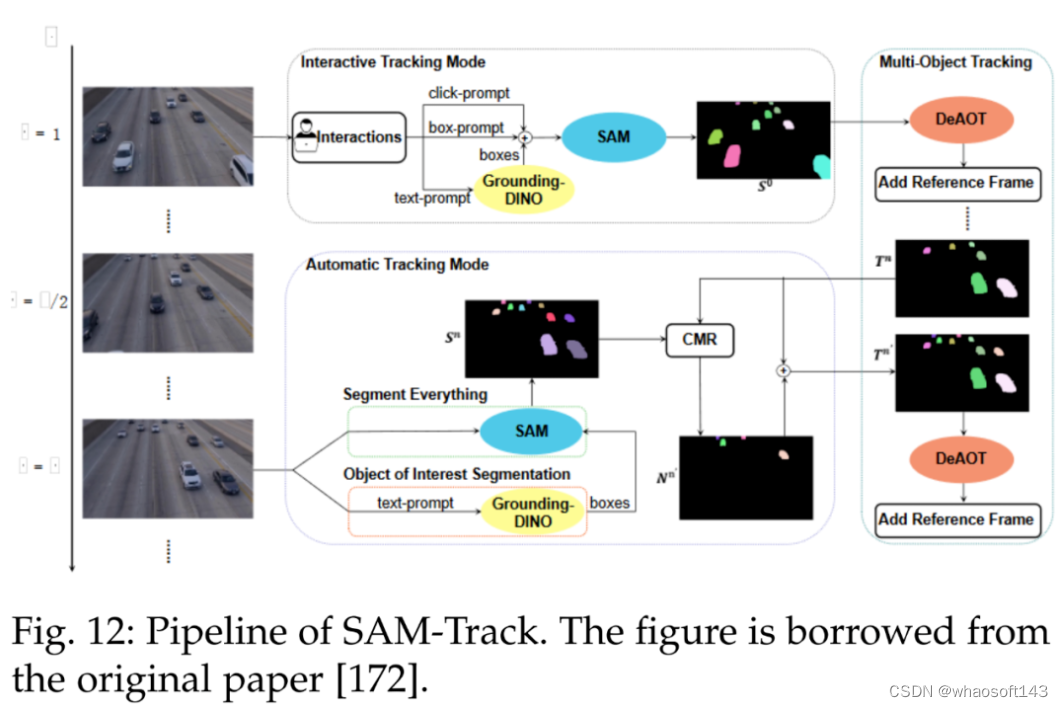
此外另一个跟踪模型为 SAMTrack,详见参考文献 [172]。SAMTrack 是一种视频分割框架,可通过交互和自动的方法实现目标跟踪和分割。下图 12 为 SAMTrack 的 pipeline。
下图 13 为一个轻量级 SAM 指导的优化模块(SAM-guided refinement module, SEEM),用于提升现有方法的性能。
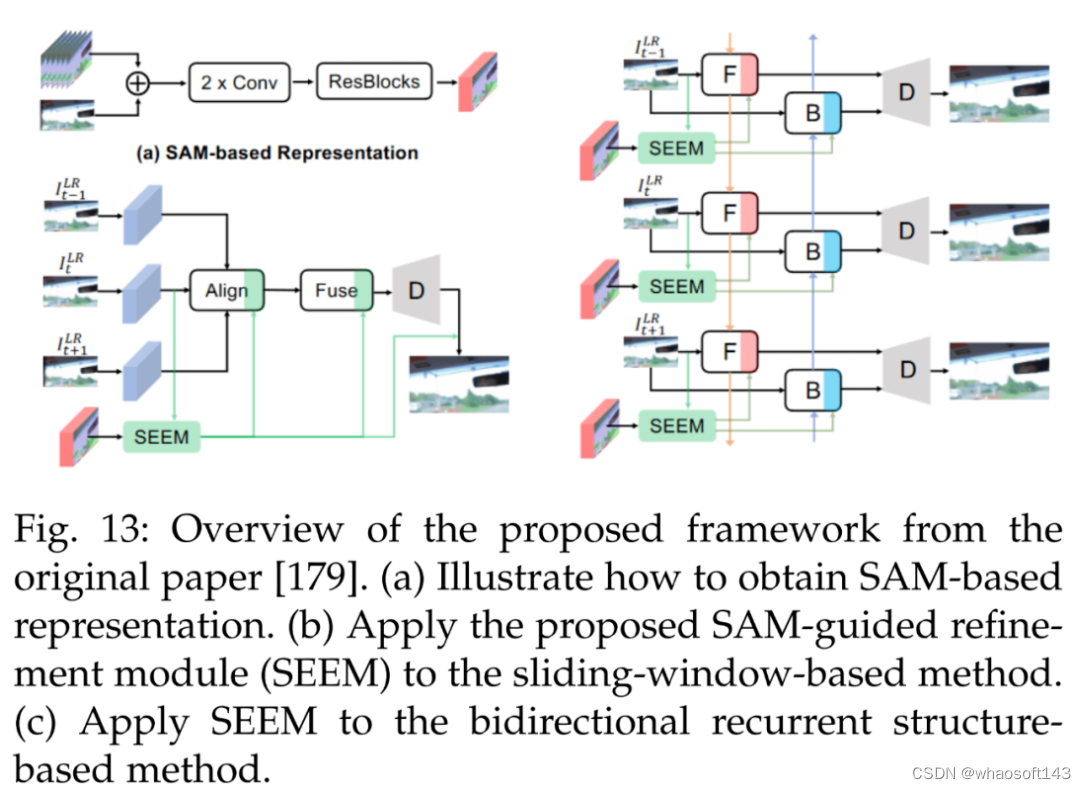
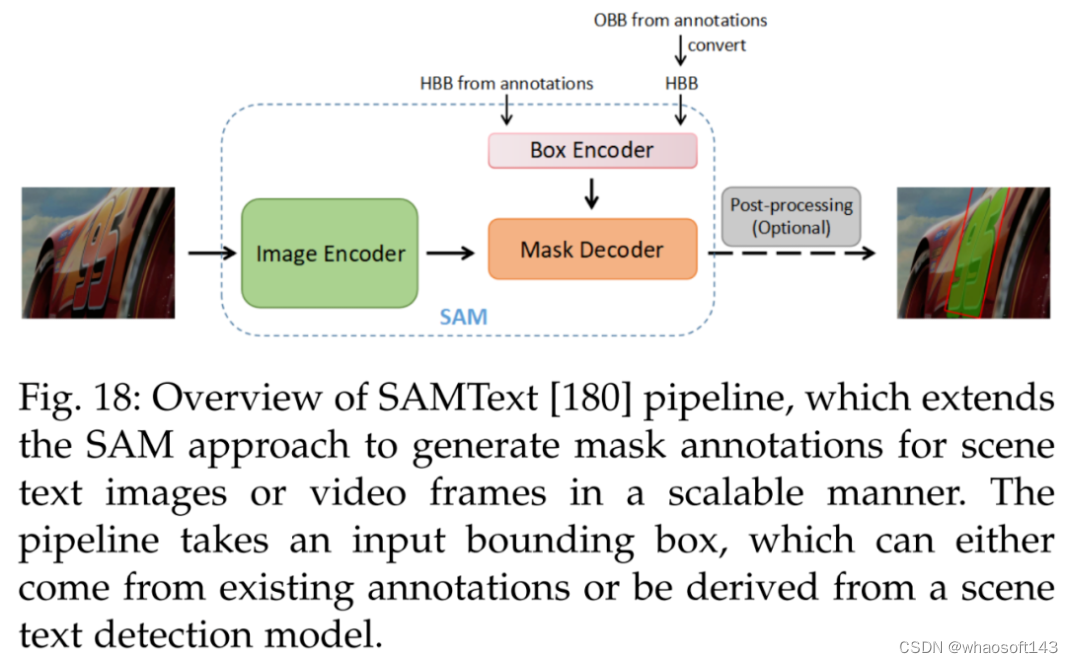
接着是数据注释。SAMText [180] 是一种用于视频中场景文本掩码注释的可扩展 pipeline。它利用 SAM 在大型数据集 SAMText-9M 上生成掩码注释,该数据集包含超过 2,400 个视频片段和超过 900 万个掩码注释。
此外参考文献 [143] 利用现有遥感目标检测数据集和以数据为中心的机器学习模型 SAM,构建了一个大规模遥感图像分割数据集 SAMRS,包含目标分类、位置和实例信息,可以用于语义分割、实例分割和目标检测研究。
视觉之外
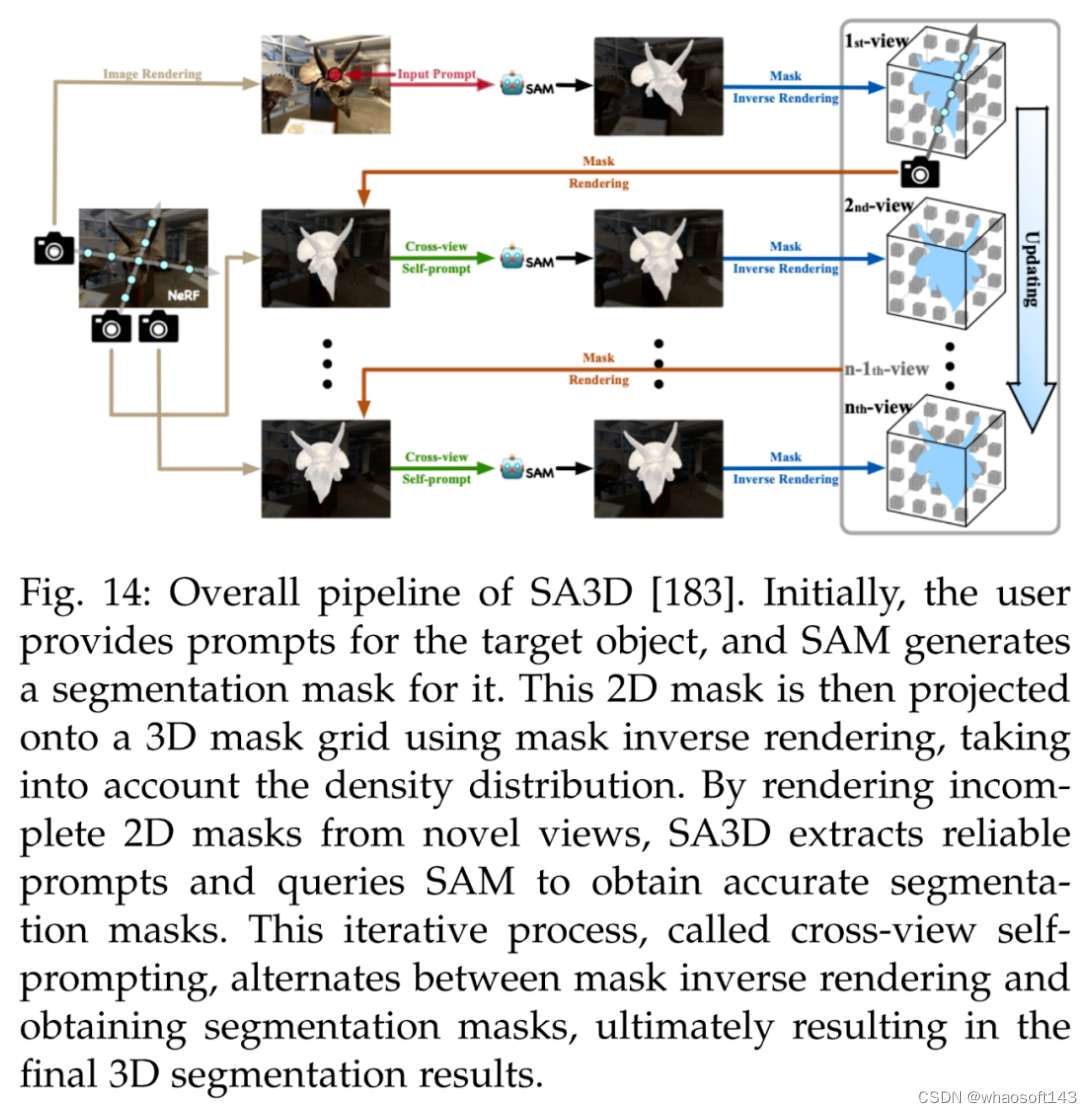
首先是 3D 重建。除了实现细粒度的 3D 分割,SA3D [183] 可以用于 3D 重建。利用 3D 掩码网格,研究者可以确定物体在 3D 中的占用空间,并以各种方式重建。下图 14 为 SA3D 的整体 pipeline。
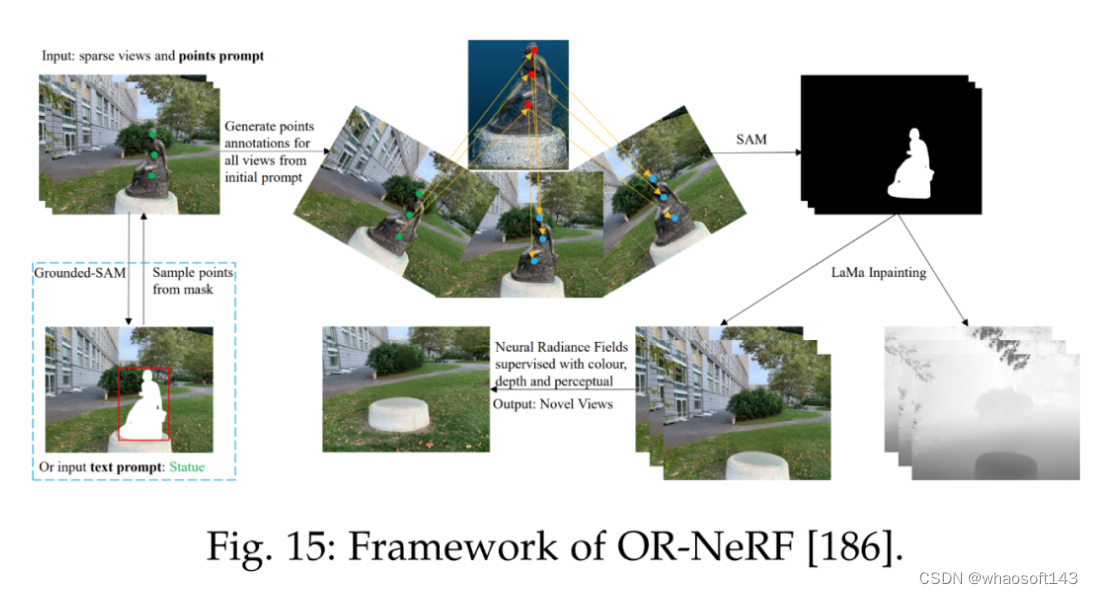
参考文献 [186] 提出了一种新的对象移除 pipeline ORNeRF,它使用单个视图上的点或文本 prompt 从 3D 场景中移除对象。通过使用点投影策略将用户注释快速传播给所有视图,该方法使用比以往工作更少的时间实现了更好的性能。下图 15 为 ORNeRF 的框架。
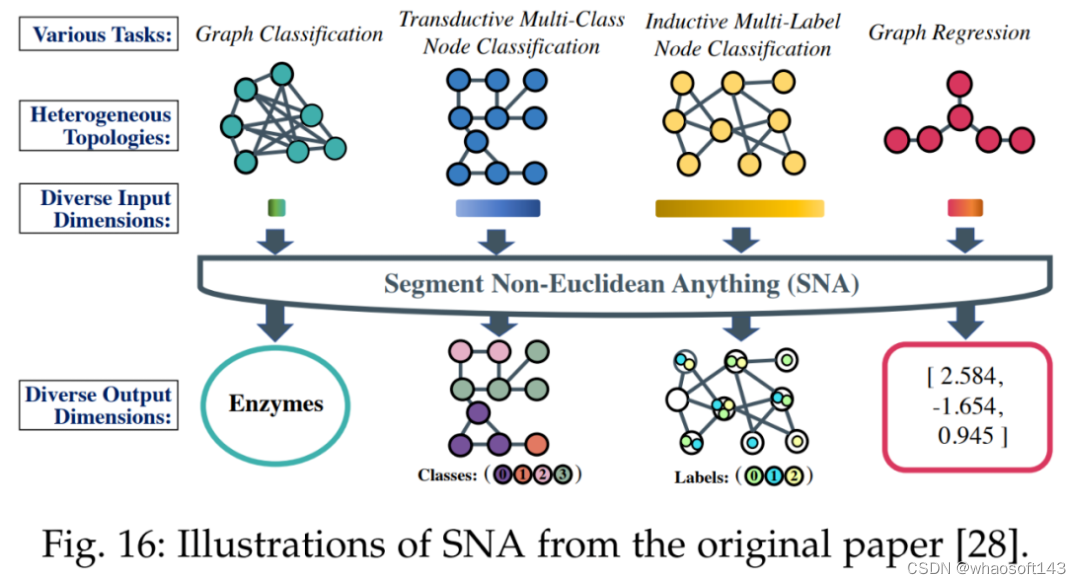
其次是非欧式域。为了为不同任务处理不同特征维度,下图 16 中所示的 SNA 方法引入了一个专门的可精简图卷积层。该层可以根据输入的特征维度进行通道的动态激活或停用。
然后是机器人。下图 17 展示了 Instruct2Act [190] 的整体流程。在感知部分,预定义的 API 用于访问多个基础模型。SAM [20] 准确定位候选对象,CLIP [13] 对它们进行分类。该框架利用基础模型的专业知识和机器人能力将复杂的高级指令转换为精确的策略代码。
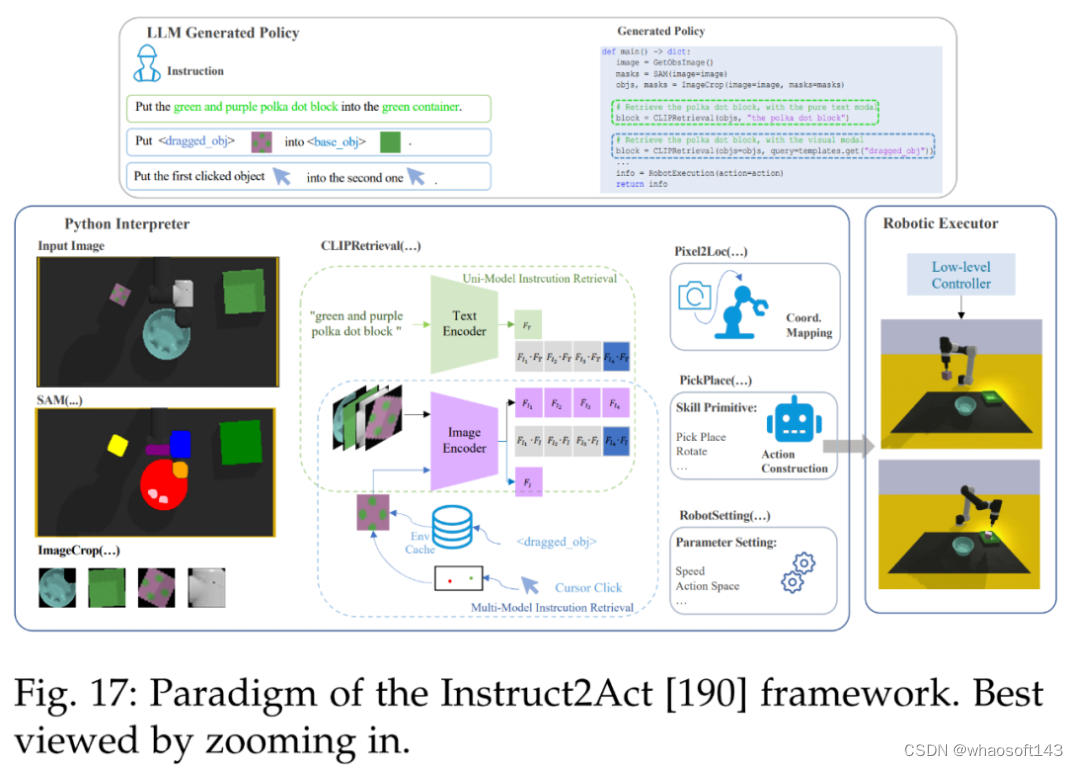
接着是视频文本定位。下图 18 展示了一种为视频文本定位任务生成掩码注释的可扩展高效解决方案 SAMText [180]。通过将 SAM 模型应用于边界框注释,它可以为大规模视频文本数据集生成掩码注释。
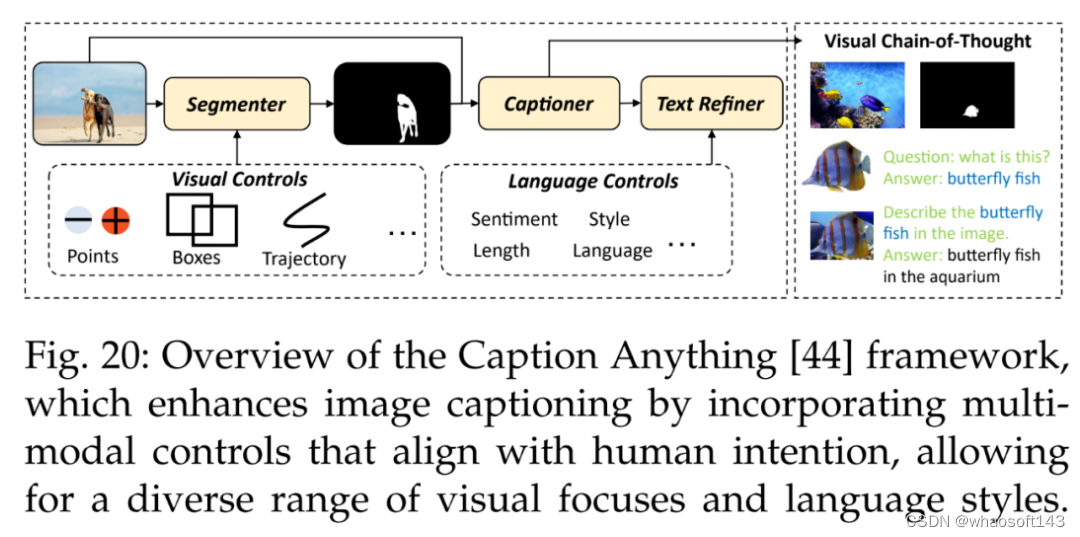
此外还有图像字幕。Wang et al. [44] 提出了一种用于可控图像字幕的方法 Caption Anything(CAT),如下图 20 所示,CAT 的框架将多模态控制引入图像字幕,呈现符合人类意图的各种视觉焦点和语言风格。
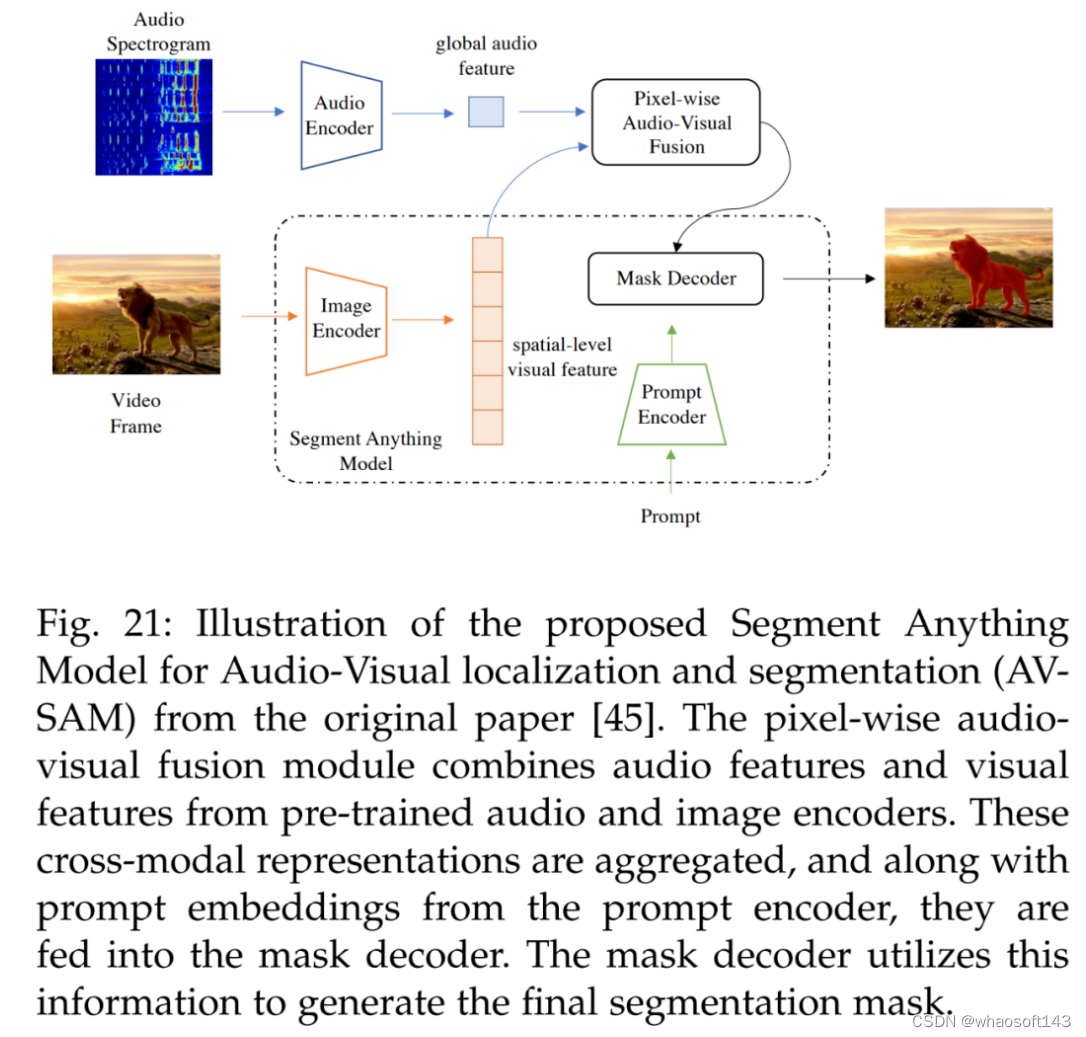
视听也有涉及。参考文献 [45] 的视听定位和分割方法用于学习可以对齐音频和视觉信息的跨模态表示,具体如下图 21 所示。AV-SAM 利用预训练音频编码器和图像编码器中跨音频和视觉特征的像素级视听融合来聚合跨模态表示。然后将聚合的跨模态特征输入 prompt 编码器和掩码解码器,生成最终的视听分割掩码。
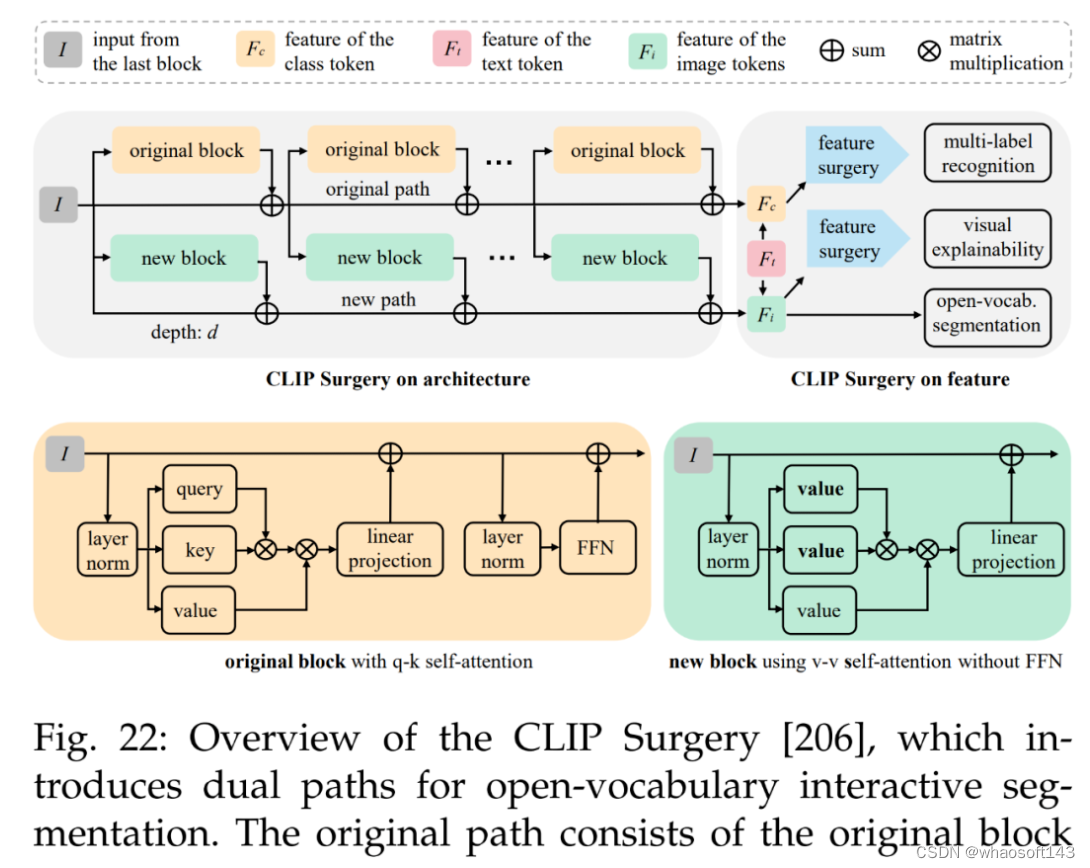
最后是多模态视觉和开放词汇交互分割。参考文献 [44] 的方法如下图 22 所示,旨在使用仅文本输入的 CLIP 策略来完全取代手动点(manual point)。这种方法提供来自文本输入的像素级结果,可以很容易地转换为 SAM 模型的点 prompt。
本文首次全面回顾了计算机视觉及其他领域 SAM 基础模型的研究进展。首先总结了基础模型(大语言模型、大型视觉模型和多模态大模型)的发展历史以及 SAM 的基本术语,并着重于 SAM 在各种任务和数据类型中的应用,总结和比较了 SAM 的并行工作及其后续工作。研究者还讨论 SAM 在广泛的图像处理应用中的巨大潜力,包括软件场景、真实世界场景和复杂场景。
此外,研究者分析和总结了 SAM 在各种应用程序中的优点和局限性。这些观察结果可以为未来开发更强大的基础模型和进一步提升 SAM 的稳健性和泛化性提供一些洞见。文章最后总结了 SAM 在视觉和其他领域的大量其他令人惊叹的应用。
#Awesome-Segmentation-With-Transformer
基于Transformer的视觉分割最新综述出炉
项目地址:https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
论文地址:https://arxiv.org/pdf/2304.09854.pdf
SAM (Segment Anything )作为一个视觉的分割基础模型,在短短的 3 个月时间吸引了很多研究者的关注和跟进。如果你想系统地了解 SAM 背后的技术,并跟上内卷的步伐,并能做出属于自己的 SAM 模型,那么接下这篇 Transformer-Based 的 Segmentation Survey 是不容错过!
近期,南洋理工大学和上海人工智能实验室几位研究人员写了一篇关于 Transformer-Based 的 Segmentation 的综述,系统地回顾了近些年来基于 Transformer 的分割与检测模型,调研的最新模型截止至今年 6 月!同时,综述还包括了相关领域的最新论文以及大量的实验分析与对比,并披露了多个具有广阔前景的未来研究方向!
视觉分割旨在将图像、视频帧或点云分割为多个片段或组。这种技术具有许多现实世界的应用,如自动驾驶、图像编辑、机器人感知和医学分析。在过去的十年里,基于深度学习的方法在这个领域取得了显著的进展。最近,Transformer 成为一种基于自注意力机制的神经网络,最初设计用于自然语言处理,在各种视觉处理任务中明显超越了以往的卷积或循环方法。具体而言,视觉 Transformer 为各种分割任务提供了强大、统一甚至更简单的解决方案。本综述全面概述了基于 Transformer 的视觉分割,总结了最近的进展。首先,本文回顾了背景,包括问题定义、数据集和以往的卷积方法。接下来,本文总结了一个元架构,将所有最近的基于 Transformer 的方法统一起来。基于这个元架构,本文研究了各种方法设计,包括对这个元架构的修改和相关应用。此外,本文还介绍了几个相关的设置,包括 3D 点云分割、基础模型调优、域适应分割、高效分割和医学分割。此外,本文在几个广泛认可的数据集上编译和重新评估了这些方法。最后,本文确定了这个领域的开放挑战,并提出了未来研究的方向。本文仍会持续和跟踪最新的基于 Transformer 的分割与检测方法。
研究动机
- ViT 和 DETR 的出现使得分割与检测领域有了十足的进展,目前几乎各个数据集基准上,排名靠前的方法都是基于 Transformer 的。为此有必要系统地总结与对比下这个方向的方法与技术特点。
- 近期的大模型架构均基于 Transformer 结构,包括多模态模型以及分割的基础模型(SAM),视觉各个任务向着统一的模型建模靠拢。
- 分割与检测衍生出来了很多相关下游任务,这些任务很多方法也是采用 Transformer 结构来解决。
综述特色
- 系统性和可读性。本文系统地回顾了分割的各个任务定义,以及相关任务定义,评估指标。并且本文从卷积的方法出发,基于 ViT 和 DETR,总结出了一种元架构。基于该元架构,本综述把相关的方法进行归纳与总结,系统地回顾了近期的方法。具体的技术回顾路线如图 1 所示。
- 技术的角度进行细致分类。相比于前人的 Transformer 综述,本文对方法的分类会更加的细致。本文把类似思路的论文汇聚到一起,对比了他们的相同点以及不同点。例如,本文会对同时修改元架构的解码器端的方法进行分类,分为基于图像的 Cross Attention,以及基于视频的时空 Cross Attention 的建模。
- 研究问题的全面性。本文会系统地回顾分割各个方向,包括图像,视频,点云分割任务。同时,本文也会同时回顾相关的方向比如开集分割于检测模型,无监督分割和弱监督分割。
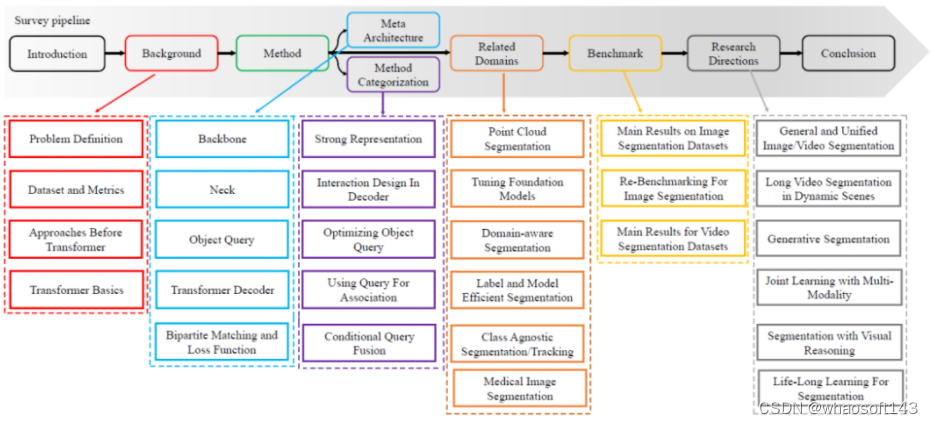
图 1. Survey 的内容路线图
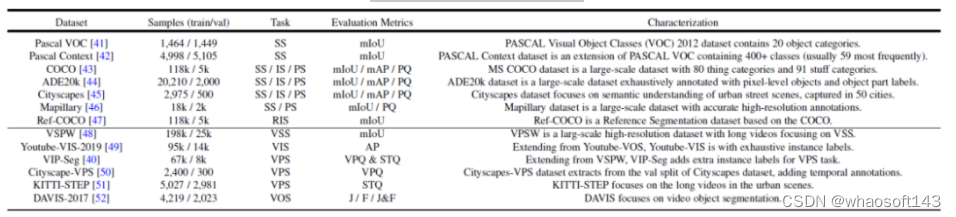
图 2. 常用的数据集以及分割任务总结
Transformer-Based 分割和检测方法总结与对比
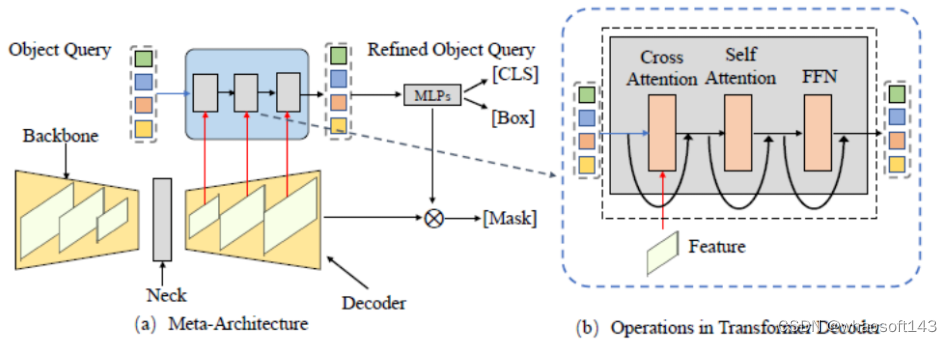
图 3. 通用的元架构框架(Meta-Architecture)
本文首先基于 DETR 和 MaskFormer 的框架总结出了一个元架构。这个模型包括了如下几个不同的模块:
- Backbone:特征提取器,用来提取图像特征。
- Neck:构建多尺度特征,用来处理多尺度的物体。
- Object Query:查询对象,用于代表场景中的每个实体,包括前景物体以及背景物体。
- Decoder:解码器,用于去逐步优化 Object Query 以及对应的特征。
- End-to-End Training:基于 Object Query 的设计可以做到端到端的优化。
基于这个元架构,现有的方法可以分为如下五个不同的方向来进行优化以及根据任务进行调整,如图 4 所示,每个方向有包含几个不同的子方向。
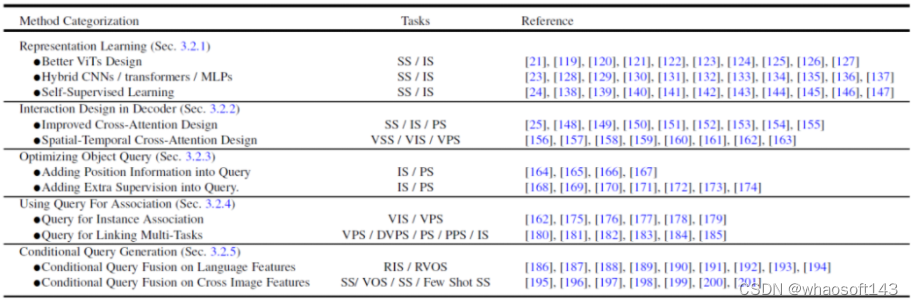
图 4. Transformer-Based Segmentation 方法总结与对比
- 更好的特征表达学习,Representation Learning。强大的视觉特征表示始终会带来更好的分割结果。本文将相关工作分为三个方面:更好的视觉 Transformer 设计、混合 CNN/Transformer/MLP 以及自监督学习。
- 解码器端的方法设计,Interaction Design in Decoder。本章节回顾了新的 Transformer 解码器设计。本文将解码器设计分为两组:一组用于改进图像分割中的交叉注意力设计,另一组用于视频分割中的时空交叉注意力设计。前者侧重于设计一个更好的解码器,以改进原始 DETR 中的解码器。后者将基于查询对象的目标检测器和分割器扩展到视频领域,用于视频目标检测(VOD)、视频实例分割(VIS)和视频像素分割(VPS),重点在建模时间一致性和关联性。
- 尝试从查询对象优化的角度,Optimizing Object Query。与 Faster-RCNN 相比,DETR 要更长的收敛时间表。由于查询对象的关键作用,现有的一些方法已经展开了研究,以加快训练速度和提高性能。根据对象查询的方法,本文将下面的文献分为两个方面:添加位置信息和采用额外监督。位置信息提供了对查询特征进行快速训练采样的线索。额外监督着重设计了除 DETR 默认损失函数之外的特定损失函数。
- 使用查询对象来做特征和实例的关联,Using Query For Association。受益于查询对象的简单性,最近的多个研究将其作为关联工具来解决下游任务。主要有两种用法:一种是实例级别的关联,另一种是任务级别的关联。前者采用实例判别的思想,用于解决视频中的实例级匹配问题,例如视频的分割和跟踪。后者使用查询对象来桥接不同子任务实现高效的多任务学习。
- 多模态的条件查询对象生成,Conditional Query Generation。这一章节主要关注多模态分割任务。条件查询查询对象主要来处理跨模态和跨图像的特征匹配任务。根据任务输入条件而确定的,解码器头部使用不同的查询来获取相应的分割掩码。根据不同输入的来源,本文将这些工作分为两个方面:语言特征和图像特征。这些方法基于不同模型特征融合查询对象的策略,在多个多模态的分割任务以及 few-shot 分割上取得了不错的结果。
图 5 中给出这 5 个不同方向的一些代表性的工作对比。更具体的方法细节以及对比可以参考论文的内容。
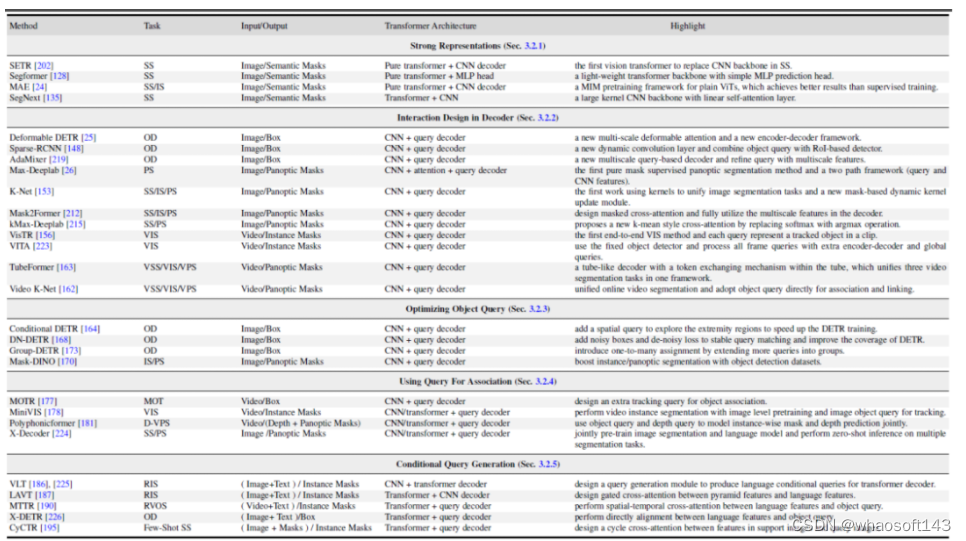
图 5. Transformer-based 的分割与检测代表性的方法总结与对比
相关研究领域的方法总结与对比
本文还探索了几个相关的领域:1,基于 Transformer 的点云分割方法。2, 视觉与多模态大模型调优。3,域相关的分割模型研究,包括域迁移学习,域泛化学习。4,高效语义分割:无监督与弱监督分割模型。5,类无关的分割与跟踪。6,医学图像分割。
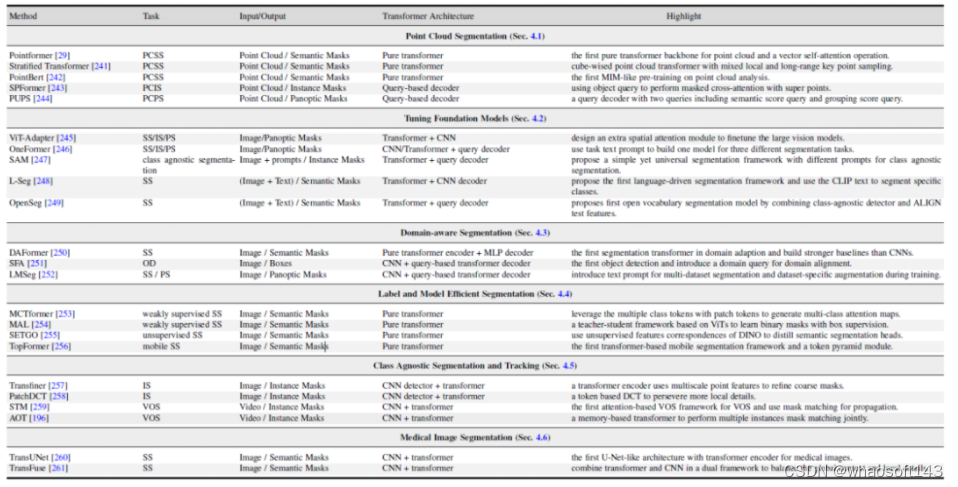
图 6. 相关研究领域的基于 Transformer 方法总结与对比
不同方法的实验结果对比
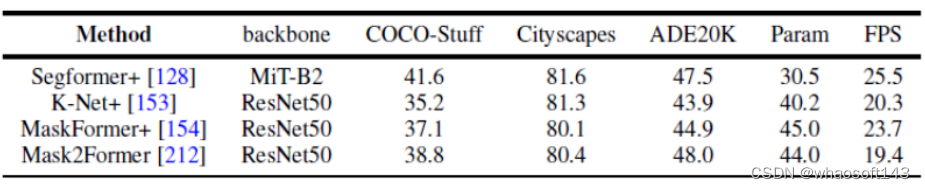
图 7. 语义分割数据集的基准实验
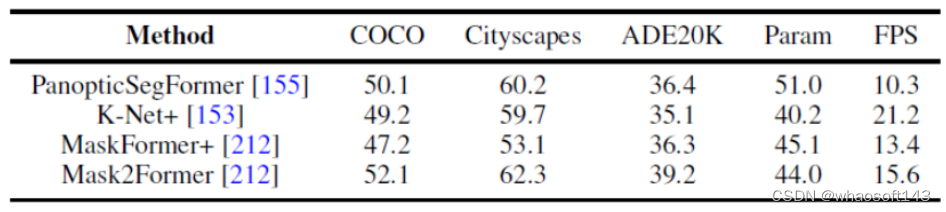
图 8. 全景分割数据集的基准实验
本文还统一地使用相同的实验设计条件来对比了几个代表性的工作在全景分割以及语义分割上多个数据集的结果。结果发现,在使用相同的训练策略以及编码器的时候,方法性能之间的差距会缩小。
此外,本文还同时对比了近期的 Transformer-based 的分割方法在多个不同数据集和任务上结果。(语义分割,实例分割,全景分割,以及对应的视频分割任务)
未来方向
此外本文也给出了一些未来的可能一些研究方向分析。这里给出三个不同的方向作为例子。
- 更加通用与统一的分割模型。使用 Transformer 结构来统一不同的分割任务是一个趋势。最近的研究使用基于查询对象的 Transformer 在一个体系结构下执行不同的分割任务。一个可能的研究方向是通过一个模型在各种分割数据集上统一图像和视频分割任务。这些通用模型可以在各种场景中实现通用和稳健的分割,例如,在各种场景中检测和分割罕见类别有助于机器人做出更好的决策。
- 结合视觉推理的分割模型。视觉推理要求机器人理解场景中物体之间的联系,这种理解在运动规划中起着关键作用。先前的研究已经探索了将分割结果作为视觉推理模型的输入,用于各种应用,如目标跟踪和场景理解。联合分割和视觉推理可以是一个有前景的方向,对分割和关系分类都具有互惠的潜力。通过将视觉推理纳入分割过程中,研究人员可以利用推理的能力提高分割的准确性,同时分割结果也可以为视觉推理提供更好的输入。
- 持续学习的分割模型研究。现有的分割方法通常在封闭世界的数据集上进行基准测试,这些数据集具有一组预定义的类别,即假设训练和测试样本具有预先知道的相同类别和特征空间。然而,真实场景通常是开放世界和非稳定的,新类别的数据可能不断出现。例如,在自动驾驶车辆和医学诊断中,可能会突然出现未预料到的情况。现有方法在现实和封闭世界场景中的性能和能力之间存在明显差距。因此,希望能够逐渐而持续地将新概念纳入分割模型的现有知识库中,使得模型能够进行终身学习。
#samshap
Segment Anything Model(SAM)首次被应用到了基于增强概念的可解释 AI 上。
你是否好奇当一个黑盒深度神经网络 (DNN) 预测下图的时候,图中哪个部分对于输出预测为「击球手」的帮助最大?

香港科技大学团队最新的 NeurIPS2023 研究成果给出了他们的答案。
- 论文:https://arxiv.org/abs/2305.10289
- 项目代码:https://github.com/Jerry00917/samshap
继 Meta 的分割一切 (SAM) 后,港科大团队首次借助 SAM 实现了人类可解读的任意 DNN 模型图像概念解释器:Explain Any Concept (EAC)。
你往往会看到传统的 DNN 图像概念解释器会给出这样的解释 (SuperPixel-Based):

但这类输出通常不能完整地将 DNN 对于输入图像里概念的理解表达给人类。
港科大团队首次将具有强大的概念抓取力的 SAM 和博弈论中夏普利公理 (Shapley Value) 结合起来,构建了端对端具有完整概念的模型解释器,并呈现了非常令人惊叹的结果!!

现在,用户只需要将任意 DNN 接入该解释器的 API,EAC 就可以精准地解释出图中哪些概念影响了模型最终的输出。
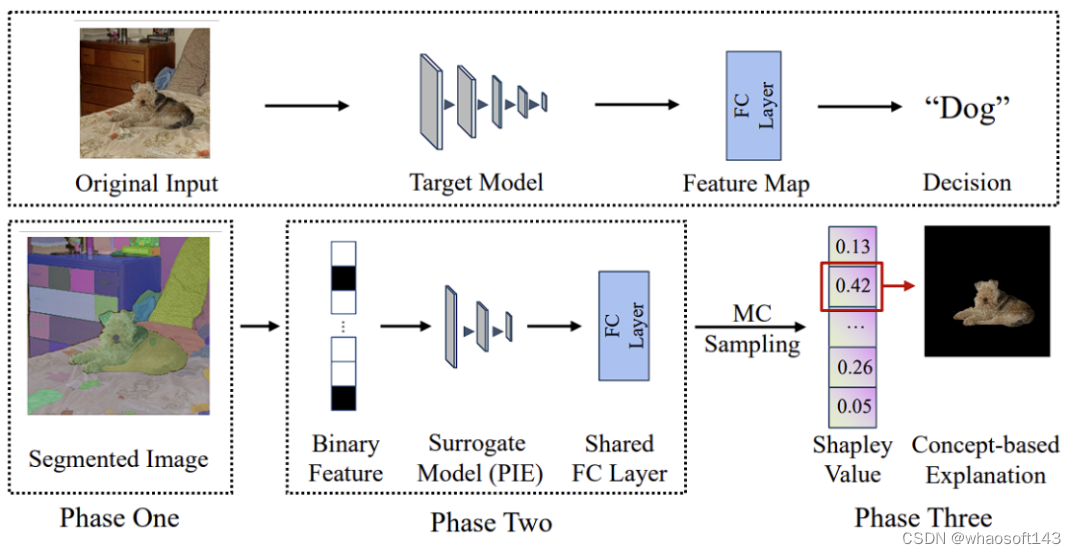
算法原理
如下图所示,解释一切 EAC 的算法流程图可大体分为三个阶段:1)SAM 概念抓取,2)利用 Per-Input Equivalence (PIE) 模拟目标 DNN 模型,3)通过计算出 PIE 的夏普利公理值得出近似原目标 DNN 的最终概念解释输出。
夏普利值实现
在博弈论中,夏普利公理的地位举足轻重。基于它,研究人员可以推算出图片里每一个概念对目标模型输出的贡献值,从而得知哪些概念对于模型预测的帮助最大。不过计算夏普利值所需要的时间复杂度为 O (2^N),这对于几乎任何一个成熟的深度学习模型是灾难性的计算量。
本文为了解决这一问题提出了 Per-Input Equivalence (PIE)轻量型框架。PIE 希望通过一个 surrogate model f' 将原目标 DNN 模型 f 做局部拟合。

文章指出 PIE 的运算十分轻量。在 COCO 标准测试集上,将目标模型设为 ResNet50,平均解释时间仅约为 8.1 秒 / 一张图片。
实验结果
通过给每张测试图逐一添加(Insertion)/ 删除(Deletion)最重要的概念 patch,这两项实验研究者可以直接评估任意解释器在解释目标 DNN 时的表现。
EAC 同时在「添加」和「删除」两项实验中实现了比较优秀的解释效果。
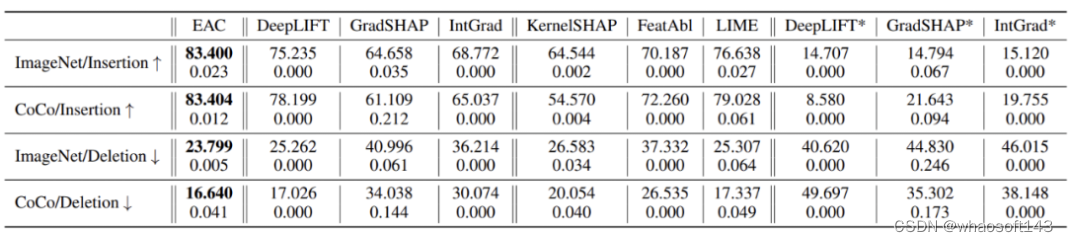
以下是 EAC 效果展示和 baseline 对比:

在文章的最后,团队表示有了 EAC 这项技术,医疗影像,智慧安防等重要的可信机器学习商用应用场景会变的更准确,更可靠。
#将大型模型先验集成到低级计算机视觉任务中的框架
本文提出了一个将大型模型先验集成到低级计算机视觉任务中的框架,该框架利用了灰度编码和通道扩展技术,将大模型先验知识集成到任何低级去雾网络中
Paper: https://arxiv.org/pdf/2306.15870.pdf
大型语言模型和高级视觉模型在大型数据集和模型大小上取得了令人印象深刻的性能改进。但是,低级计算机视觉任务,例如图像去雾和模糊去除,仍然依赖于少量数据集和小尺寸模型,这会导致过度拟合和局部最优。
这启发作者思考:如何将一个大型模型先验集成到低级计算机视觉任务中? 就像图像分割任务一样,雾度的降低也与纹理相关。因此,作者提出了灰度编码、网络通道扩展和预去雾三大结构的框架,以将大模型先验知识集成到任何低级去雾网络中。
通过不同的数据集和算法比较实验证明了大型模型在指导低级视觉任务方面的有效性和适用性。在不需要额外数据和训练资源的条件下,证明了大模型先验知识的集成将提高去雾性能并节省低级视觉任务的训练时间。
本文进行了如下工作:
- 作者发现大规模图像分割模型在去雾方面的能力,并证明这种能力并非来自数据集或训练过程本身,而是通过使用大规模数据集和大规模模型来实现;
- 为了加速小规模数据和小模型的低级视觉去雾任务中特定去雾结果的适应性,提出了一个新框架,该框架利用了灰度编码和通道扩展技术,将大模型先验知识集成到任何低级去雾网络中;
- 进行大量的实验,评估所提出方法的效果,并比较了不同雾场景下不同模型尺寸对最终去雾结果的影响。
背景知识
由于雾霾的形成具有一定的物理学理论基础,对图像质量的影响也是随着距离的增加而提升的。因此,传统的图像带雾模型公式如下:

求解推导示例
研究动机
去雾模型往往缺乏可靠的现实数据集,而且也很难针对不同的去雾任务单独训练不同的大型模型。作者希望能够通过大型图像分割模型来改进基于小模型和小数据的图像去雾网络,使得大型模型能够增强图像去雾的能力。
创新思路
本文方法
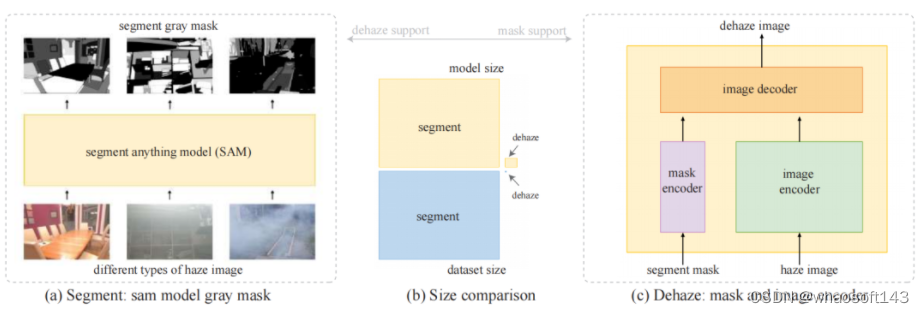
pipeline:将雾霾图像输入放入大规模分割模型中,并以灰度编码输出分割结果。通过利用大型模型的涌现能力,还可以处理以前没有训练过的雾霾图像。同时,无论是网络规模还是数据集规模,现有最大的去雾模型和分割大模型都相差几个数量级。最后,通过编码器-解码器结构将灰度编码分割掩模添加到图像去雾网络的编码器部分。
- 灰度编码
分割模型输出的是图像中每个像素的分割相对应的数字。分割一般用不同的颜色表示图像中不同类型的片段,这还需要转换为三个通道。为了增降低了后续去雾小模型的计算复杂性,作者在灰度通道上结合分割。大分割模型将图像中的所有目标分割出来,图像通常被分成许多部分。作者根据在去雾数据集上的实验,一张图像最多可以分割成130多个部分,而大多数图像的分割数在30到127之间。整个计算量非常大,对此,作者提出了一种灰度编码方法,将分割结果转换为灰度图像。优点是可以清楚地了解每个分割结果的输出顺序,较亮的区域表示分割较多,网络性能较好。
- 通道扩展
上面的操作将分割结果变为的灰度图像,而去雾图像的输入/出都是三通道的RGB图像,这里添加了一个灰度通道将分割的mask输入进去,从而将输入通道扩展到四个通道。输出通道仍然保持为三个通道。由此。网络编码器部分有一个额外的通道并且尺寸得到扩大,而解码器部分保持不变。
针对网络编码器的第四个通道,作者又提出了不同类型的网络结构,其中包括小型、中型和大型模型:
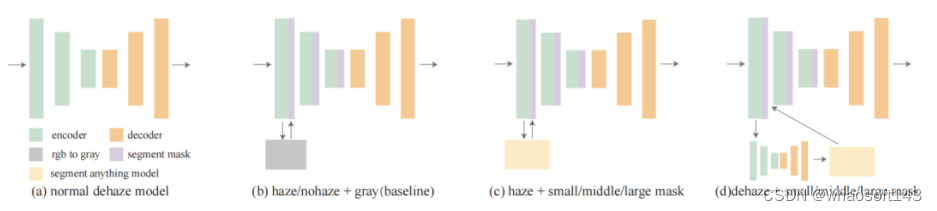
baseline是将带雾图像的灰度图直接作为mask然后输入到模型中,对应的理想情况是将无雾图像的灰度图作为mask输入模型。后面两个图意思是分别将有雾/无雾图像经过不同尺寸的模型分割后得到的mask输入到模型。这些情况用于评估分割网络性能、去雾训练和实际去雾测试。
关键实验结果
这里选择了涵盖室内室外、浓雾、稀雾、不均匀雾等各种场景的数据进行评估
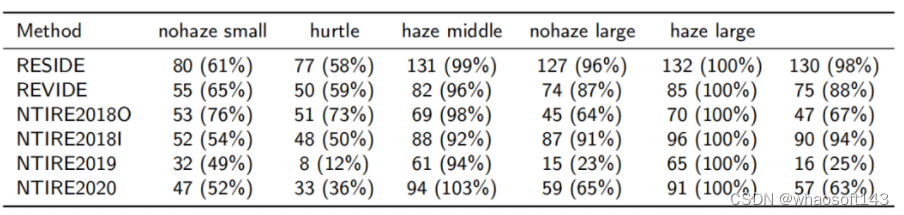
表Ⅰ
表Ⅰ比较了不同数据集下不同尺寸模型的分割性能,所有数据是分割网络对整个去雾数据集进行分割后每张图像的平均分割数,可以发现:
- 对于简单的雾场景来说,小分割模型足够;
- 中等难度的场景,增加模型尺度可以克服雾霾的副作用;
- 极其困难的雾场景,增加模型比例可以减轻雾霾的副作用。
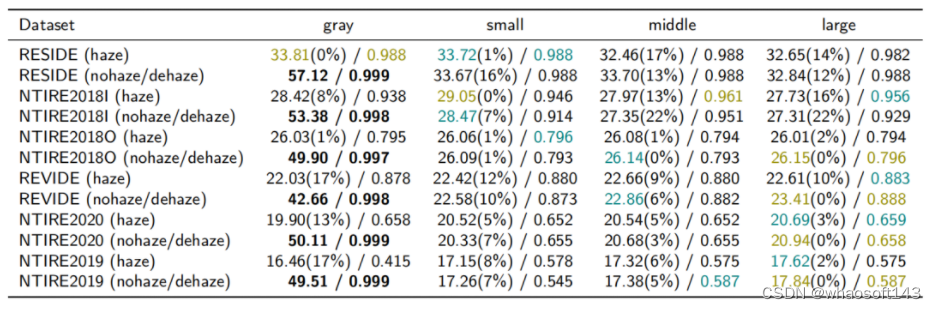
表Ⅱ
表Ⅱ比较了本文方法在不同雾度下的改进效果(数据集的难度从高到低,橄榄色代表最好的结果,青色代表第二好的结果),颜色结果呈对角分布,本文方法对于更困难的去雾数据集表现更好且改进更多,具体如下:
- 温和数据集上,本文方法可以提高1%到8%;
- 中等难度的去雾数据集,较大规模的分割网络很快会产生饱和效果,无法继续提供有效的纹理分割;
- 困难的场景中,本文方法可以提高 13% 到 17%,同时,分割模型规模的增加可以提高去雾性能。
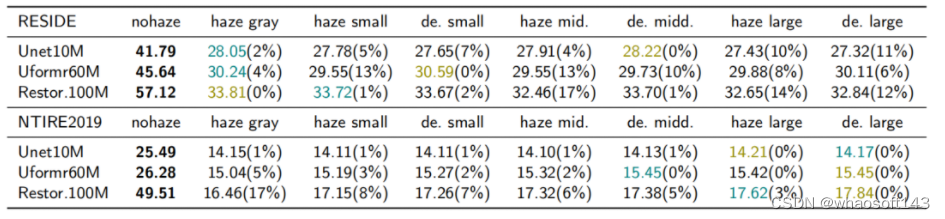
表Ⅲ
表Ⅲ探讨了不同规模模型的作用,同样有如下几点发现:
- 简单的去雾数据集:无论去雾网络的规模如何,分割掩模带来的改进并不明显;
- 复杂的雾霾场景:尺寸更大、更复杂、拟合能力更好的小尺度去雾模型往往可以学习到大规模分割网络的抗雾霾性能。更大规模的去雾模型可以更好地感知大规模分割模型的改进。
最后放上不同数据集上的去雾效果可视化对比:

本文的研究使得大型语义分割模型可以帮助小型去雾模型,即使小型模型无法进行大参数和大型模型的训练。使得小型模型能够享受大型模型的开发优势,而无需针对小型模型任务进行特定优化,是一个比较新奇的想法。更多研究细节请参阅原论文~~
#SAM-E
当我们拿起一个机械手表时,从正面会看到表盘和指针,从侧面会看到表冠和表链,打开手表背面会看到复杂的齿轮和机芯。每个视角都提供了不同的信息,将这些信息综合起来才能理解操作对象的整体三维。
想让机器人在现实生活中学会执行复杂任务,首先需要使机器人理解操作对象和被操作对象的属性,以及相应的三维操作空间,包括物体位置、形状、物体之间的遮挡关系,以及对象与环境的关系等。
其次,机器人需要理解自然语言指令,对未来动作进行长期规划和高效执行。使机器人具备从环境感知到动作预测的能力是具有挑战性的。
近期,中国电信人工智能研究院(TeleAI)李学龙教授团队联合上海人工智能实验室、清华大学等单位,模拟人「感知—记忆—思维—想象」的认知过程,提出了多视角融合驱动的通用具身操作算法,为机器人学习复杂操作给出了可行解决方案,论文被国际机器学习大会ICML 2024录用,为构建通用三维具身策略奠定了基础。
近年来,视觉基础模型对图像的理解能力获得了飞速发展。然而,三维空间的理解还存在许多挑战。能否利用视觉大模型帮助具身智能体理解三维操作场景,使其在三维空间中完成各种复杂的操作任务呢?受「感知—记忆—思维—想象」的认知过程启发,论文提出了全新的基于视觉分割模型Segment Anything(SAM)的具身基座模型SAM-E。
首先,SAM- E具有强大可提示(promptable)「感知」能力,将SAM特有的分割结构应用在语言指令的具身任务中,通过解析文本指令使模型关注到场景中的操作物体。
随后,设计一种多视角Transformer,对深度特征、图像特征与指令特征进行融合与对齐,实现对象「记忆」与操作「思考」,以此来理解机械臂的三维操作空间。
最后,提出了一种全新的动作序列预测网络,对多个时间步的动作序列进行建模,「想象」动作指令,实现了从三维场景感知到具身动作的端到端输出。
- 论文名称:SAM-E: Leveraging Visual Foundation Model with Sequence Imitation for Embodied Manipulation
- 论文链接: https://sam-embodied.github.io/static/SAM-E.pdf
- 项目地址: https://sam-embodied.github.io/
从二维感知到三维感知
在数字时代的浪潮中,随着人工智能技术的飞速发展,我们正逐渐迈入一个崭新的时代——具身智能时代。赋予智能体以身体,使其具备与真实世界直接互动的能力,成为了当前研究的重点方向之一。
要实现这一目标,智能体必须具备强大的三维感知能力,以便能够准确地理解周围环境。
传统的二维感知手段在面对复杂的立体空间时显得力不从心,如何让具身智能体通过学习掌握对三维空间的精准建模能力,成为了一个亟待解决的关键问题。
现有工作通过正视图、俯视图、侧视图等等多个视角的视图还原和重建三维空间,然而所需的计算资源较为庞大,同时在不同场景中具有的泛化能力有限。
为了解决这个问题,本工作探索一种新的途径——将视觉大模型的强大泛化能力应用于具身智能体的三维感知领域。
SAM-E提出了使用具有强大泛化能力的通用视觉大模型 SAM 进行视觉感知,通过在具身场景的高效微调,将其具有的可泛化,可提示(promptable)的特征提取能力、实例分割能力、复杂场景理解等能力有效迁移到具身场景中。
为了进一步优化SAM基座模型的性能,引入了动作序列网络的概念,不仅能够捕捉单个动作的预测,还能够深入理解连续动作之间的内在联系,充分挖掘动作间的时序信息,从而进一步提高基座模型对具身场景的理解与适应能力。
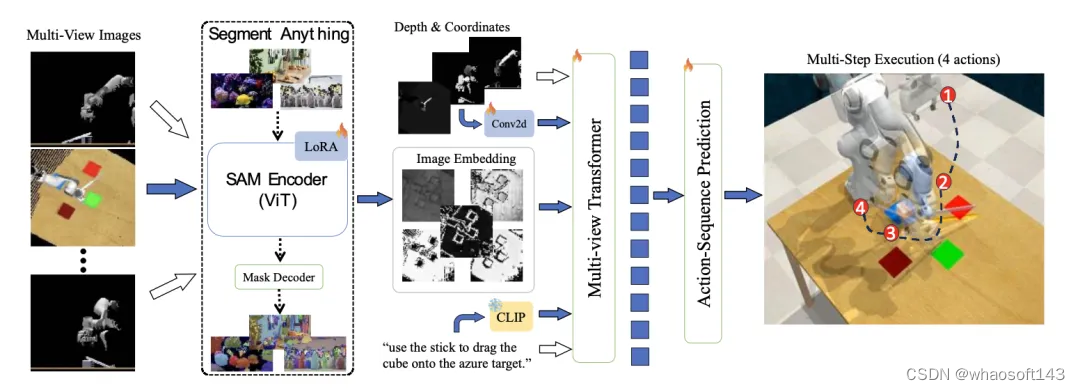
图1. SAM-E总体框架
SAM-E方法
SAM-E方法的核心观点主要包含两个方面:
- 利用SAM的提示驱动结构,构建了一个强大的基座模型,在任务语言指令下拥有出色的泛化性能。通过LoRA微调技术,将模型适配到具身任务中,进一步提升了其性能。
- 采用时序动作建模技术,捕捉动作序列中的时序信息,更好地理解任务的动态变化,并及时调整机器人的策略和执行方式,使机器人保持较高的执行效率。
可提示感知与微调
SAM- E核心在于利用任务指令提示驱动的网络结构,包含一个强大的视觉编码器和一个轻量的解码器。
在具身场景中任务「提示」以自然语言的形式呈现,作为任务描述指令,视觉编码器发挥其可提示的感知能力,提取与任务相关的特征。策略网络则充当解码器的角色,基于融合的视觉嵌入和语言指令输出动作。
在训练阶段,SAM-E 使用 LoRA 进行高效微调,大大减少了训练参数,使视觉基础模型能够快速适应于具身任务。
多视角三维融合
SAM-E引入了多视角Transformer网络,以融合多视角的视觉输入,深入理解三维空间。其工作分为两个阶段:视角内注意力(View-wise Attention)和跨视角注意力(Cross-view Attention)。
首先,对多视角特征分别进行视角内部的注意力处理,然后融合多个视角和语言描述进行混合视角注意力,实现多视角的信息融合和图像—语言对齐。
动作序列建模
在机械臂执行中,末端执行器的位置和旋转通常呈现出连续而平滑的变化趋势。这一特性使得相邻动作之间存在着密切的联系和连续性。基于这一观察,提出了一种新颖的时间平滑假设,旨在充分利用相邻动作之间的内在关联,实现对动作序列的有效模仿学习。
具体来说,SAM-E框架通过序列建模技术捕捉动作序列中的模式和关系,为动作预测提供一种隐性的先验知识,并对动作的连续性加以约束,从而显著提升动作预测的准确性和一致性。
在实际应用中,SAM-E 允许在一次动作预测中执行后续的多步动作,极大地提高了执行效率。
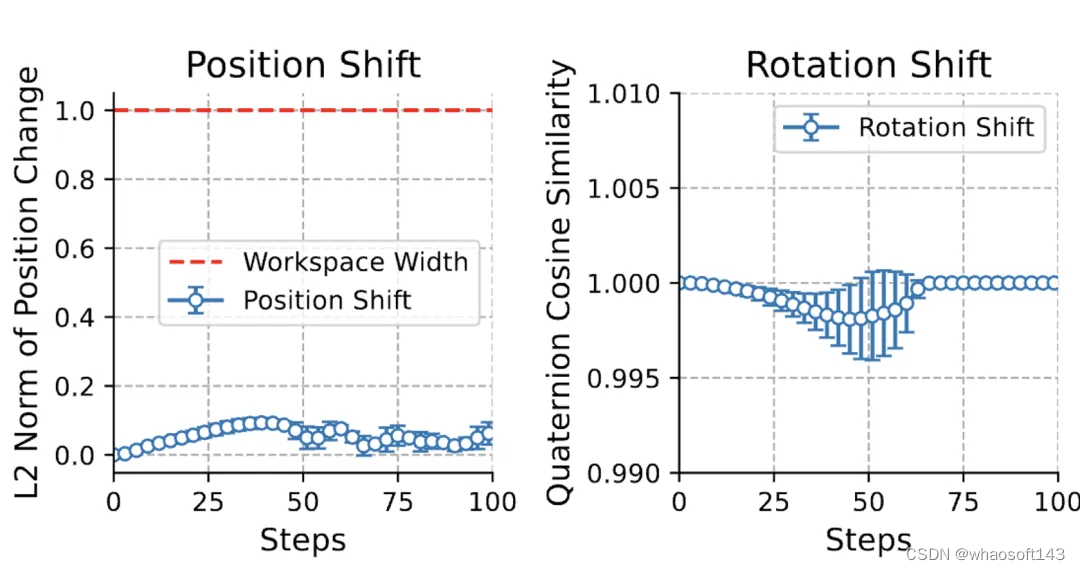
图3.连续动作的位置和旋转变化
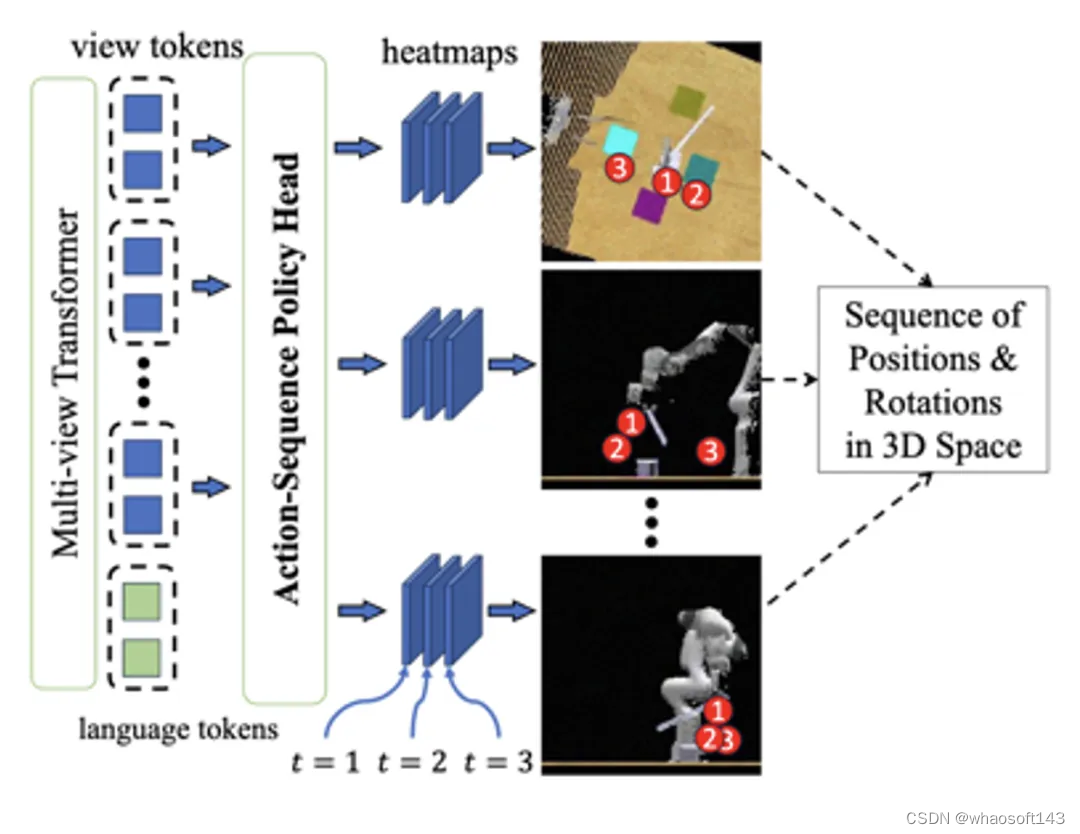
图4.动作序列预测网络
实验
实验使用具有挑战性的机械臂任务集合——RLBench,对多视角观测下的3D操作任务进行了全面评估,SAM-E模型在多个方面均显著优于其他传统方法。
- 在多任务场景下,SAM-E模型显著提高了任务成功率。
- 在面对少量样本迁移至新任务的情况下,SAM-E凭借强大的泛化性能和高效的执行效率,有效提升新任务的表现。
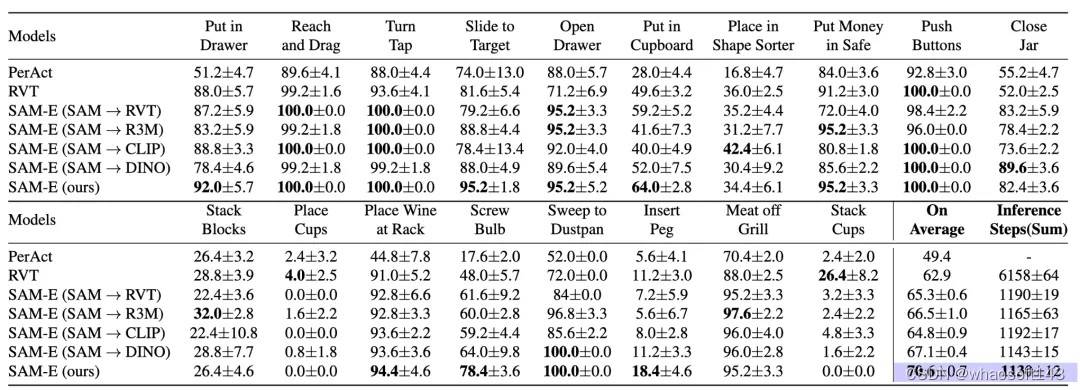
图5.三维操作任务结果比较

图6.三维操作任务示例
此外,动作序列建模显著提高了 SAM-E 的执行效率,同时在策略执行阶段,相比于单个动作,动作序列执行显著降低了模型推理次数,测试中甚至能通过一次模型推理完成相应任务。
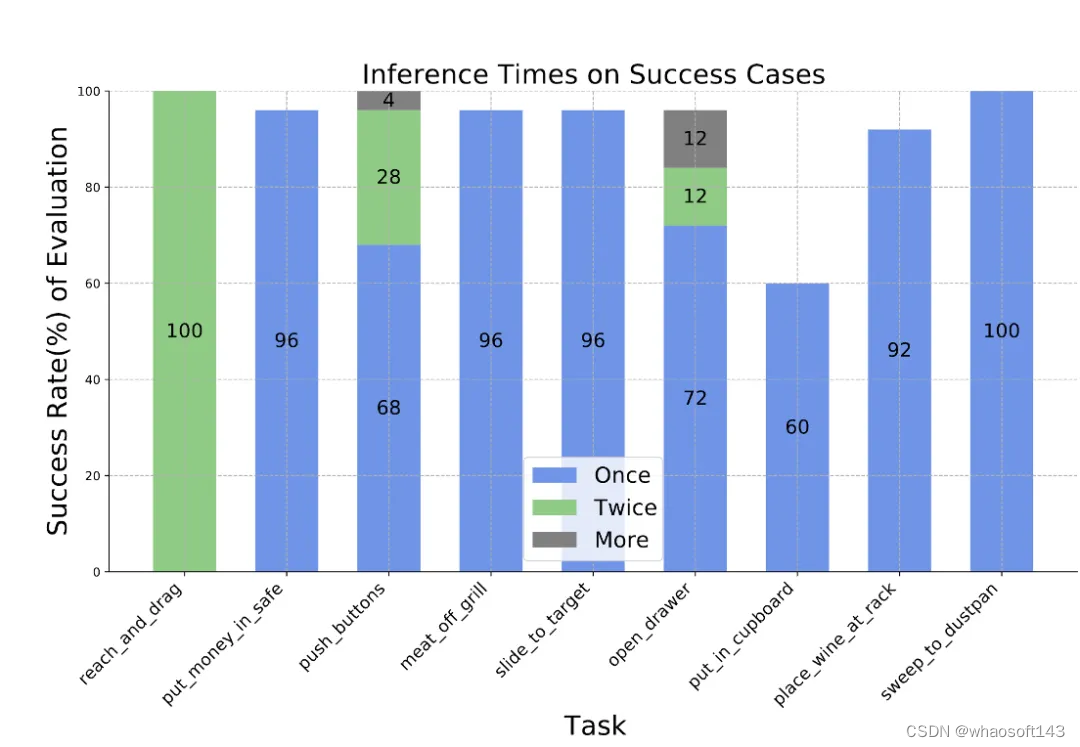
图7.任务执行中的模型推理频率
SAM-E在真实机械臂控制中同样有效,使用两个第三人称相机捕获多视角视觉输入,在五个真实任务上具有实时的推理能力。

图8.真实机械臂任务
总结
该工作开创性地提出了一种以多视角融合的基础的通用具身操作算法,利用视觉分割大模型和多视角融合实现具身智能体的三维物理空间感知。
通过高效的参数微调,将预训练视觉模型迁移到具身场景中,能够解决自然语言指令的复杂3D机械臂操作任务。此外,模型可以通过学习少量专家示例,快速泛化到新的任务中,展现出优越的训练效率和动作执行效率。
更重要的是,SAM-E以「感知—记忆—思维—想象」的认知链路,实现了从数据到动作的端到端映射。其意义不仅在于其在具身智能体中的应用,更在于对提升智能体认知能力的启发。
通过模拟人类的感知和决策方式,智能体能够更好地理解和适应复杂的环境,从而在更广泛的领域发挥更大的作用。






![[全网最细数据结构完整版]第七篇:3分钟带你吃透队列](https://i-blog.csdnimg.cn/direct/504733d4072a4ad7a935c85546836abe.jpeg)