一、引言
在当今互联网时代,随着电商、金融等行业的快速发展,订单数量呈爆炸式增长。传统的单一数据库存储订单信息的方式面临着巨大的挑战,如数据存储容量有限、查询性能下降、数据备份和恢复困难等。为了解决这些问题,分库分表技术应运而生。本文将详细介绍订单信息分库分表的相关知识,包括其原理、方法、实际应用以及注意事项等。
二、订单信息分库分表的重要性
(一)解决数据存储容量问题
随着业务的不断发展,订单数量不断增加,单一数据库的存储容量很快就会达到上限。通过分库分表,可以将订单数据分散存储在多个数据库和表中,从而有效地解决数据存储容量问题。
(二)提高查询性能
当订单数据量庞大时,对订单信息的查询会变得非常缓慢。分库分表可以将数据分散到多个数据库和表中,减少每个数据库和表中的数据量,从而提高查询性能。同时,可以根据查询条件进行合理的分库分表设计,使得查询能够更快地定位到所需的数据。
(三)便于数据备份和恢复
对于庞大的订单数据,备份和恢复是一项非常耗时的任务。通过分库分表,可以将数据分散到多个数据库和表中,使得备份和恢复可以并行进行,从而大大缩短备份和恢复的时间。同时,分库分表也可以降低单个数据库或表的故障对整个系统的影响,提高系统的可靠性。
三、订单信息分库分表的原理
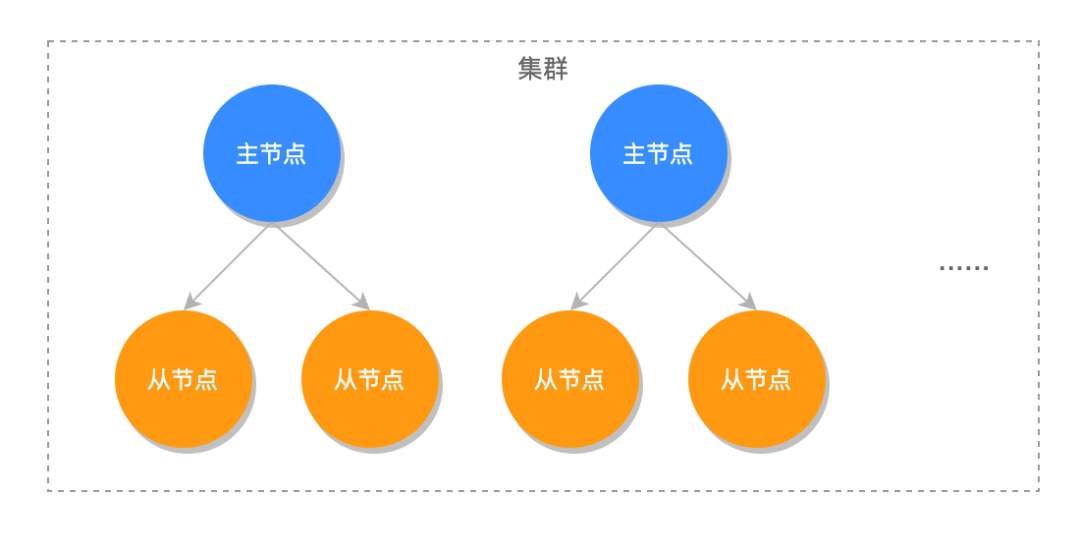
(一)分库原理
分库是将订单数据分散存储在多个数据库中。通常可以根据业务需求、数据量大小、访问模式等因素进行分库。例如,可以按照订单的时间范围、业务类型、地域等进行分库。分库可以有效地分散数据存储压力,提高系统的可扩展性和性能。
(二)分表原理
分表是将订单数据分散存储在多个表中。通常可以根据订单的属性、业务规则等因素进行分表。例如,可以按照订单的状态、支付方式、用户 ID 等进行分表。分表可以有效地减少单个表中的数据量,提高查询性能和数据管理的灵活性。
(三)分库分表的实现方式
- 垂直分库分表
- 垂直分库是按照业务模块将一个数据库拆分成多个数据库,每个数据库存储不同业务模块的数据。例如,可以将订单数据库拆分成订单库、用户库、商品库等。垂直分表是按照表的字段将一个表拆分成多个表,每个表存储不同字段的数据。例如,可以将订单表拆分成订单基本信息表、订单商品信息表等。
- 垂直分库分表的优点是可以将不同业务模块的数据分离,提高数据的独立性和可维护性。同时,也可以根据不同业务模块的特点进行针对性的优化,提高系统的性能。缺点是可能会增加系统的复杂度,需要进行跨库跨表的查询和事务处理。
- 水平分库分表
- 水平分库是将一个数据库中的数据按照一定的规则分散存储到多个数据库中。例如,可以按照订单的 ID 进行哈希分库,将订单数据分散存储到多个数据库中。水平分表是将一个表中的数据按照一定的规则分散存储到多个表中。例如,可以按照订单的创建时间进行范围分表,将订单数据分散存储到多个表中。
- 水平分库分表的优点是可以有效地分散数据存储压力,提高系统的可扩展性和性能。同时,也可以根据数据的特点进行合理的分布,提高查询性能。缺点是需要进行数据的路由和合并,增加了系统的复杂度。
四、订单信息分库分表的方法
(一)确定分库分表策略
- 分析业务需求
- 了解业务的特点、数据量大小、访问模式等因素,确定分库分表的必要性和可行性。
- 分析订单数据的属性和关系,确定分库分表的依据和规则。
- 选择分库分表方式
- 根据业务需求和数据特点,选择垂直分库分表或水平分库分表方式。
- 如果业务模块之间独立性较强,可以选择垂直分库分表方式;如果数据量较大且需要进行水平扩展,可以选择水平分库分表方式。
- 确定分库分表规则
- 根据选择的分库分表方式,确定具体的分库分表规则。例如,如果选择水平分库分表方式,可以按照订单的 ID 进行哈希分库,按照订单的创建时间进行范围分表。
(二)设计数据库架构
- 数据库选型
- 根据业务需求和数据特点,选择合适的数据库产品。例如,如果需要支持高并发读写,可以选择 MySQL、PostgreSQL 等关系型数据库;如果需要支持海量数据存储和高可扩展性,可以选择 MongoDB、Cassandra 等 NoSQL 数据库。
- 数据库部署
- 根据分库分表策略,确定数据库的部署方式。可以采用分布式部署方式,将多个数据库部署在不同的服务器上,提高系统的可扩展性和性能。
- 数据库连接管理
- 设计合理的数据库连接管理机制,确保系统能够高效地连接和访问多个数据库。可以采用数据库连接池技术,提高数据库连接的复用率,减少连接创建和销毁的开销。
(三)实现数据路由和合并
- 数据路由
- 实现数据路由功能,确保系统能够根据分库分表规则将数据正确地存储到相应的数据库和表中。可以采用哈希算法、范围算法等方式进行数据路由。
- 对于查询操作,需要根据查询条件进行数据路由,定位到相应的数据库和表中进行查询。可以采用索引、缓存等技术提高查询性能。
- 数据合并
- 对于跨库跨表的查询操作,需要进行数据合并,将多个数据库和表中的数据合并成一个结果集返回给用户。可以采用分布式查询引擎、数据仓库等技术进行数据合并。
- 在进行数据合并时,需要注意数据的一致性和完整性,避免出现数据重复、缺失等问题。
(四)进行数据迁移和同步
- 数据迁移
- 如果已经存在大量的订单数据,需要进行数据迁移,将数据从原有的数据库和表中迁移到新的分库分表架构中。可以采用数据迁移工具、脚本等方式进行数据迁移。
- 在进行数据迁移时,需要注意数据的一致性和完整性,避免出现数据丢失、错误等问题。同时,也需要考虑数据迁移的时间和成本,选择合适的迁移方式和时机。
- 数据同步
- 在分库分表架构中,需要进行数据同步,确保多个数据库和表中的数据保持一致。可以采用数据同步工具、消息队列等方式进行数据同步。
- 在进行数据同步时,需要注意数据的实时性和准确性,避免出现数据延迟、错误等问题。同时,也需要考虑数据同步的性能和资源消耗,选择合适的同步方式和策略。
五、订单信息分库分表的实际应用
(一)电商平台订单系统
- 业务需求分析
- 电商平台的订单系统通常需要处理大量的订单数据,包括订单的创建、查询、修改、删除等操作。同时,订单系统还需要与其他系统进行交互,如用户系统、商品系统、支付系统等。
- 订单数据的特点是数据量大、增长速度快、访问频繁。因此,需要采用分库分表技术来提高订单系统的性能和可扩展性。
- 分库分表策略
- 采用水平分库分表方式,按照订单的 ID 进行哈希分库,将订单数据分散存储到多个数据库中。按照订单的创建时间进行范围分表,将订单数据分散存储到多个表中。
- 对于查询操作,可以根据订单的 ID、用户 ID、创建时间等条件进行数据路由,定位到相应的数据库和表中进行查询。对于跨库跨表的查询操作,可以采用分布式查询引擎进行数据合并。
- 数据库架构设计
- 选择 MySQL 作为数据库产品,采用分布式部署方式,将多个数据库部署在不同的服务器上。使用数据库连接池技术管理数据库连接,提高连接的复用率。
- 设计订单表结构,包括订单基本信息表、订单商品信息表、订单支付信息表等。根据分库分表规则,将订单数据存储到相应的数据库和表中。
- 数据迁移和同步
- 使用数据迁移工具将原有的订单数据迁移到新的分库分表架构中。在数据迁移过程中,需要注意数据的一致性和完整性,避免出现数据丢失、错误等问题。
- 采用消息队列进行数据同步,当订单数据发生变化时,将变化的数据发送到消息队列中,由其他系统进行消费和处理,确保多个系统中的订单数据保持一致。
(二)金融交易系统
- 业务需求分析
- 金融交易系统通常需要处理大量的交易订单数据,包括交易的创建、查询、修改、删除等操作。同时,交易系统还需要保证数据的安全性和准确性,以及高可用性和高性能。
- 交易订单数据的特点是数据量大、增长速度快、价值高。因此,需要采用分库分表技术来提高交易系统的性能和可扩展性,同时保证数据的安全性和准确性。
- 分库分表策略
- 采用垂直分库分表方式,将交易系统拆分成多个数据库,每个数据库存储不同业务模块的数据。例如,可以将交易数据库拆分成交易订单库、用户信息库、资金账户库等。
- 对于交易订单库,可以按照交易的类型、时间范围等进行水平分表,将交易订单数据分散存储到多个表中。对于查询操作,可以根据交易的 ID、用户 ID、交易类型等条件进行数据路由,定位到相应的数据库和表中进行查询。
- 数据库架构设计
- 选择 Oracle 作为数据库产品,采用分布式部署方式,将多个数据库部署在不同的服务器上。使用数据库连接池技术管理数据库连接,提高连接的复用率。
- 设计交易订单表结构,包括交易订单基本信息表、交易订单明细信息表、交易订单状态表等。根据分库分表规则,将交易订单数据存储到相应的数据库和表中。
- 数据迁移和同步
- 使用数据迁移脚本将原有的交易订单数据迁移到新的分库分表架构中。在数据迁移过程中,需要注意数据的一致性和完整性,避免出现数据丢失、错误等问题。
- 采用数据库复制技术进行数据同步,将交易订单数据实时同步到备份数据库中,保证数据的安全性和可用性。同时,也可以采用消息队列进行数据同步,将交易订单数据发送到其他系统进行处理,确保多个系统中的交易订单数据保持一致。
六、订单信息分库分表的挑战与解决方案
(一)数据一致性问题
- 问题描述
- 在分库分表架构中,由于数据分散存储在多个数据库和表中,可能会出现数据不一致的问题。例如,在进行数据更新操作时,如果部分数据库或表更新成功,而部分数据库或表更新失败,就会导致数据不一致。
- 解决方案
- 采用分布式事务处理机制,确保多个数据库和表中的数据更新操作能够同时成功或同时失败。例如,可以使用两阶段提交协议(2PC)、三阶段提交协议(3PC)等分布式事务处理机制。
- 采用数据同步工具或消息队列进行数据同步,确保多个数据库和表中的数据保持一致。在进行数据更新操作时,可以将更新的数据发送到消息队列中,由其他系统进行消费和处理,确保多个系统中的数据保持一致。
(二)数据路由问题
- 问题描述
- 在分库分表架构中,需要根据分库分表规则将数据正确地存储到相应的数据库和表中。如果数据路由出现问题,可能会导致数据存储错误或查询不到数据。
- 解决方案
- 采用哈希算法、范围算法等方式进行数据路由,确保数据能够正确地存储到相应的数据库和表中。同时,也可以采用索引、缓存等技术提高数据路由的性能。
- 对于查询操作,需要根据查询条件进行数据路由,定位到相应的数据库和表中进行查询。可以采用分布式查询引擎、数据仓库等技术进行数据合并,提高查询性能。
(三)跨库跨表查询问题
- 问题描述
- 在分库分表架构中,跨库跨表查询操作比较复杂,需要进行数据合并和处理。如果跨库跨表查询性能低下,可能会影响系统的性能和用户体验。
- 解决方案
- 采用分布式查询引擎、数据仓库等技术进行跨库跨表查询,提高查询性能。同时,也可以采用索引、缓存等技术提高查询性能。
- 对于复杂的跨库跨表查询操作,可以考虑将数据进行预聚合或预计算,减少查询时的数据处理量。例如,可以使用数据仓库进行数据预聚合,将查询结果缓存到内存中,提高查询性能。
(四)数据库连接管理问题
- 问题描述
- 在分库分表架构中,需要管理多个数据库连接,如果连接管理不当,可能会导致连接泄漏、连接过多等问题,影响系统的性能和稳定性。
- 解决方案
- 采用数据库连接池技术管理数据库连接,提高连接的复用率,减少连接创建和销毁的开销。同时,也可以采用连接池监控工具对连接池进行监控和管理,及时发现和解决连接泄漏、连接过多等问题。
- 对于分布式数据库架构,可以采用分布式数据库连接管理工具,如 Sharding-JDBC、MyCat 等,对多个数据库连接进行统一管理和调度,提高系统的性能和可扩展性。
七、订单信息分库分表的性能优化
(一)索引优化
- 合理创建索引
- 根据查询条件和业务需求,合理创建索引可以提高查询性能。例如,可以在订单的 ID、用户 ID、创建时间等字段上创建索引。
- 避免创建过多的索引,因为过多的索引会占用大量的存储空间,并且会影响数据的插入、更新和删除操作的性能。
- 索引维护
- 定期对索引进行维护,如重建索引、优化索引等,可以提高索引的性能。同时,也可以根据业务需求和数据变化情况,及时调整索引的创建和使用策略。
(二)查询优化
- 避免全表扫描
- 在进行查询操作时,尽量避免全表扫描,因为全表扫描会消耗大量的系统资源,并且查询性能低下。可以通过合理创建索引、使用条件过滤等方式避免全表扫描。
- 优化查询语句
- 优化查询语句可以提高查询性能。例如,可以避免使用复杂的查询语句、减少查询结果集的大小、使用分页查询等方式优化查询语句。
- 缓存查询结果
- 对于频繁查询的数据,可以将查询结果缓存到内存中,提高查询性能。可以使用缓存框架如 Redis、Ehcache 等进行缓存。
(三)数据存储优化
- 选择合适的数据类型
- 根据数据的特点和业务需求,选择合适的数据类型可以减少存储空间的占用,提高数据的存储和查询性能。例如,可以使用整数类型代替字符串类型存储数字数据。
- 压缩数据存储
- 对于大量的数据,可以采用数据压缩技术减少存储空间的占用,提高数据的存储和查询性能。例如,可以使用数据库的压缩功能对数据进行压缩存储。
(四)数据库服务器优化
- 配置数据库参数
- 根据业务需求和服务器硬件资源,合理配置数据库参数可以提高数据库的性能。例如,可以调整数据库的缓存大小、连接数、线程数等参数。
- 定期进行数据库优化
- 定期对数据库进行优化,如清理无用数据、优化数据库结构、重建索引等,可以提高数据库的性能和稳定性。
八、实际案例分析
(一)案例背景
某电商平台随着业务的快速发展,订单数量不断增加,原有的单一数据库架构已经无法满足业务需求。为了解决数据存储容量问题和提高查询性能,该电商平台决定采用分库分表技术对订单系统进行优化。
(二)分库分表策略
- 分析业务需求
- 该电商平台的订单系统主要包括订单的创建、查询、修改、删除等操作。订单数据的特点是数据量大、增长速度快、访问频繁。
- 根据业务需求和数据特点,决定采用水平分库分表方式,按照订单的 ID 进行哈希分库,将订单数据分散存储到多个数据库中。按照订单的创建时间进行范围分表,将订单数据分散存储到多个表中。
- 设计数据库架构
- 选择 MySQL 作为数据库产品,采用分布式部署方式,将多个数据库部署在不同的服务器上。使用数据库连接池技术管理数据库连接,提高连接的复用率。
- 设计订单表结构,包括订单基本信息表、订单商品信息表、订单支付信息表等。根据分库分表规则,将订单数据存储到相应的数据库和表中。
- 实现数据路由和合并
- 采用哈希算法进行数据路由,确保数据能够正确地存储到相应的数据库和表中。对于查询操作,根据查询条件进行数据路由,定位到相应的数据库和表中进行查询。对于跨库跨表的查询操作,采用分布式查询引擎进行数据合并,将多个数据库和表中的数据合并成一个结果集返回给用户。
(三)性能优化措施
- 索引优化
- 在订单的 ID、用户 ID、创建时间等字段上创建索引,提高查询性能。同时,定期对索引进行维护,如重建索引、优化索引等,确保索引的性能。
- 缓存查询结果
- 对于频繁查询的订单数据,将查询结果缓存到 Redis 中,提高查询性能。设置合理的缓存过期时间,避免缓存数据过期导致的查询性能下降。
- 数据库服务器优化
- 合理配置 MySQL 数据库参数,如调整缓存大小、连接数、线程数等,提高数据库的性能。定期对数据库进行优化,如清理无用数据、优化数据库结构、重建索引等,确保数据库的稳定性和性能。
(四)效果评估
- 数据存储容量
- 通过分库分表,将订单数据分散存储到多个数据库和表中,有效地解决了数据存储容量问题。随着业务的不断发展,系统可以轻松地扩展数据库和表的数量,满足不断增长的数据存储需求。
- 查询性能
- 采用哈希算法进行数据路由和分布式查询引擎进行数据合并,大大提高了查询性能。在高并发的情况下,系统能够快速响应查询请求,满足用户的需求。
- 系统稳定性
- 分库分表后,系统的负载得到了均衡分布,避免了单个数据库或表的负载过高导致的系统故障。同时,通过合理的数据库服务器优化和缓存策略,提高了系统的稳定性和可靠性。
九、总结
订单信息分库分表是解决大规模数据存储和查询性能问题的有效手段。通过合理的分库分表策略、数据库架构设计、数据路由和合并实现,以及性能优化措施,可以有效地提高系统的性能、可扩展性和稳定性。在实际应用中,需要根据业务需求和数据特点,选择合适的分库分表方式和技术方案,并不断进行优化和调整,以满足不断变化的业务需求。