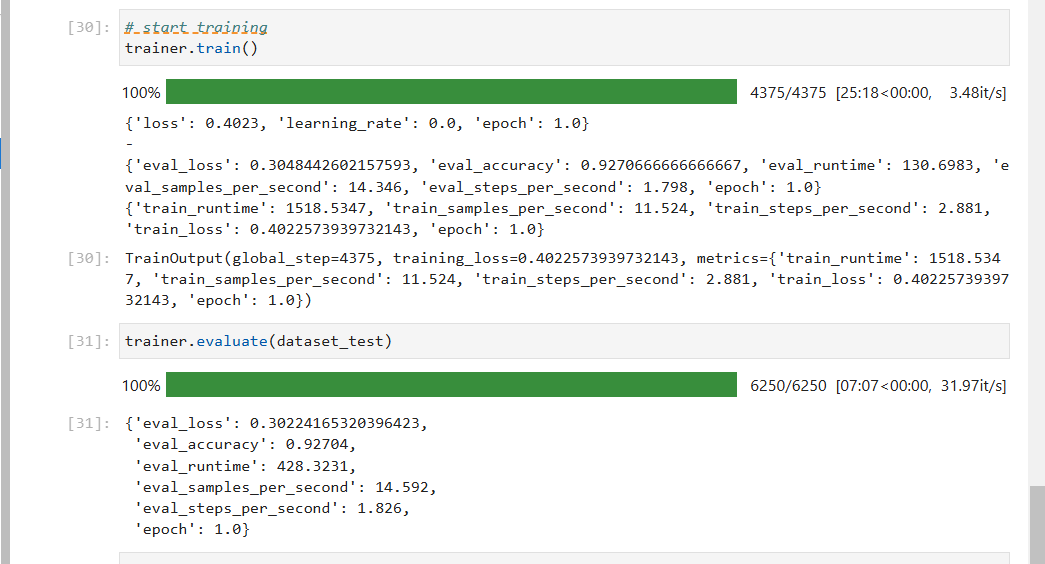
使用大型语言模型进行神经病理诊断的初步探索
研究问题
本研究探讨了大型语言模型(LLMs)在辅助医生进行神经病理学诊断中的潜在应用。具体来说,研究人员通过设计特定的问题和病例背景,询问多个流行的LLMs,并根据这些模型的回答来评估其对罕见或复杂肿瘤类型的识别能力。
方法
- 病例选择:研究人员选择了三种不同类型的脑肿瘤病例(星形细胞瘤、胶质母细胞瘤和少突胶质细胞瘤)作为测试样本。
- 设计问题:为每个案例设计了特定的问题,涵盖从基本描述到详细病理分析的所有方面。这些问题包括对患者的年龄、性别、临床症状、影像学检查结果及组织学特征的询问。
- 使用LLMs进行诊断尝试:
- 调用并咨询了多个流行的大型语言模型,包括Llama-2-70B-Groq和Claude 1.3。对于ChatGPT,选择使用其4o版本。
- 根据案例特点设计并提交问题给每个LLM,并记录下它们的回答以供后续分析之用。
- 评估与结果解读:通过对LLMs回答的仔细评估来判断这些模型在识别罕见或复杂肿瘤类型的准确性和可靠性。
创新点
- 首次尝试使用大型语言模型(LLMs)为神经病理诊断提供支持。
- 采用多模态方法,结合临床信息与影像学资料来训练和测试这些语言模型的能力。
- 探讨了通过调整问题设计来提高LLM识别准确率的可能性。
结论
尽管现有的大型语言模型在处理一些常见疾病时表现良好,但在诊断罕见或复杂肿瘤类型方面仍存在显著局限性。虽然它们能够提供一定的帮助,但需要进一步的研究以增强其对特定病理特征的理解和描述能力。这项初步研究表明了利用这些技术辅助医学决策的潜力,并提出了未来改进的方向。
请注意:本研究中使用的UCLH数据集只能通过Brain UK获得;有关访问该数据集的信息,请联系指定人员SB。Llama-2-70B-Groq可通过poe.com免费获取,而ChatGPT-4o则需要付费订阅。Anthropic提供有限的免费访问权限给Claude,但完全访问可能需要付费订阅。
本研究的结果和建议对未来开发能够更准确地辅助诊断罕见或复杂神经病理疾病的大型语言模型具有重要意义。
原文链接
https://pmc.ncbi.nlm.nih.gov/articles/PMC11540532/
从对话中生成个人档案的任务(PGTask)
研究问题
如何通过对话自动生成用户个人档案,以便更好地理解用户的背景和需求?
方法
提出了PGTask任务,该任务旨在根据对话内容自动创建用户个人档案。利用现有的自然语言处理技术和机器学习模型来提取关键信息并生成详细的个人档案。
创新点
引入了从对话中生成个人档案的任务(PGTask),这是一个新颖且具有挑战性的研究领域。通过这种方法可以更好地理解用户的背景和需求,并提供个性化的服务和支持。
结论
该任务能够有效地利用现有的自然语言处理技术,从大量的对话数据中提取关键信息并自动生成用户个人档案。这将有助于提高用户体验和服务的个性化程度,进一步推动了人机交互领域的研究和发展。
原文链接
https://www.isca-archive.org/iberspeech_2024/abad24b_iberspeech.pdf
服务系统中人工智能赋能的非人类代理角色特征
研究问题
如何描述和分类在服务系统中,由人工智能赋能的非人类代理人所扮演的角色及其对价值共创的影响?
方法
本文采用基于开源数据的四步类型构建方法,分析了130个服务案例。通过这种方法,作者开发出多维度角色特征以表征非人类代理人在服务系统中的作用,并从系统的角度识别包含非人类代理人的服务交互及如何影响价值主张。
创新点
本文首次提出了一种描述人工智能赋能的非人类代理人角色及其在服务创新中潜在影响力的框架。这项研究通过多案例分析提出了六类非人类代理角色,这些角色代表了它们对服务系统中的价值共创所作出的不同贡献。
结论
本研究表明,在服务系统工程和以人为中心的人机交互的设计与实施过程中,了解并有效利用人工智能赋能的非人类代理人能够显著提升服务创新的机会。这为理论研究提供了新的视角,并为企业实践提出了具有指导性的建议。
原文链接
https://aisel.aisnet.org/wi2024/70/
反应性态度与AI代理——关于责任和控制缺口的理解
研究问题
本文旨在探讨在涉及人工智能(AI)代理的情况下,人们如何理解和处理反应性态度的问题。具体而言,研究关注于当人类面对具有自主决策能力的AI系统时,其情绪、评价以及行动倾向的变化,并试图揭示这些变化背后的原因和机制。
方法
该文首先回顾了传统哲学中关于责任和控制的基本概念及其在道德和法律领域中的应用情况;随后讨论了AI技术的发展如何挑战并重塑了人们对“代理”这一术语的理解。接着,通过案例分析的方式探讨了具体场景下人们对于涉及AI的行为所持有的不同反应,并试图从中提炼出一些普遍性结论。
创新点
本文首次尝试将哲学上的责任理论与人工智能领域中的实际应用相结合,提出了一套关于如何在存在技术代理的世界里界定人类行为准则的新框架。此外还创造性地引入了“准代理人”(quasi-agent)这一概念来更好地描述那些介于完全自主AI和传统意义上的人类代理人之间的实体。
结论
研究表明,在面对具有高度自治性的智能体时,人们可能会出现认知上的混乱,并因此难以形成一致的评价与行动倾向。通过深入探讨反应性态度的概念及其在责任分配中的作用,我们能够更好地理解这种现象背后的原因,并为未来如何规范AI技术的应用提供了一定启示。
由于原始文献是英文撰写并发表于学术期刊《Philosophy & Technology》上,在此翻译过程中可能无法完全还原原文的所有细节与严谨度,请读者注意。
原文链接
https://link.springer.com/article/10.1007/s13347-024-00808-x
不同激活函数和密集层在语言模型中的性能研究
研究问题
本文主要探讨不同激活函数(如ReLU、SiLU)以及使用密集层对大规模预训练语言模型的性能影响。具体而言,作者考察了在不同的参数稀疏度下,这些因素如何改变语言模型的困惑度和计算效率。
方法
实验中采用了三种规模的语言模型:0.4B参数量、0.8B参数量及1.2B参数量的模型,并且研究了几种不同激活函数的效果(如ReLU与SiLU)以及使用密集层(dense layer)的影响。此外,还对这些语言模型进行了不同程度的剪枝操作(PPL-1%、PPL-5%、PPL-10%),并记录了其困惑度值和计算成本。
创新点
本文创新之处在于首次系统地研究了激活函数类型与密集层使用对于大规模预训练语言模型性能的影响,同时结合剪枝策略探究这些因素如何协同作用以优化模型表现及资源效率。此外,该工作还为未来相关领域的研究提供了一个参考框架。
结论
实验结果表明,在不同规模的语言模型中,SiLU激活函数相比于ReLU通常可以获得更好的困惑度值。当增加密集层时,大多数情况下也会对性能产生正面影响。然而,在进行了参数剪枝处理后,这些改进效果可能会有所削弱甚至出现倒退现象;具体而言,随着剪枝率的提升(例如从PPL-1%到PPL-5%,再到PPL-10%),上述积极效应逐渐减弱。此外,本文还发现对于不同规模的语言模型来说,在实施不同程度参数稀疏度时,其计算效率和性能之间存在一定的权衡关系。
原文链接
https://arxiv.org/pdf/2411.02335
AI增强在人机协作中的有效性:来自实地实验的证据
研究问题
公司越来越多地利用人工智能(AI)来提升人类绩效,特别是在电子商务领域。然而,AI增强的效果仍存在争议。本研究通过随机现场试验探讨了AI如何以及为何能提高销售人员的人类代理销售业绩。
方法
本研究进行了一项2×2因子随机现场实验(N=1090),以调查AI增强对销售结果的影响。该实验将仅由人类代理处理的销售结果与AI辅助的结果进行了比较,并且还检查了代理商经验水平的调节作用以及代理商响应背后的潜在机制。
创新点
本研究突出了AI增强在人机协作中的角色,展示了基于代理商经验水平的不同影响,并为组织如何调整AI增强以提高代理人的回应能力并推动销售提供了见解。
结论
结果表明,AI增强导致了显著的5.46%销售额增长。值得注意的是,AI增强的影响因代理人经验水平而异,新手代理人受益程度几乎是经验丰富代理人的六倍。中介分析显示,AI增强提高了响应速度、准确性和情感度,从而促进了销售业绩的增长。
原文链接
https://www.emerald.com/insight/content/doi/10.1108/ITP-11-2022-0859/full/html
人工智能技术在可持续重构制造系统中的应用:基于大规模语言模型的AI辅助决策方法
研究问题
研究的问题是如何利用人工智能(AI)技术开发可持续的重构制造系统,并在此基础上探索如何运用大规模语言模型来提升决策效果。
方法
本文探讨了人工智能(AI)在可重构制造系统中实现可持续性的应用。研究分析了现有文献中的最新进展,涵盖了机器学习、深度学习和自然语言处理等关键技术领域的相关工作。此外,论文还介绍了一种基于大规模语言模型的决策方法,并通过案例研究验证了该方法的有效性。
创新点
本文的主要创新之处在于提出了一个结合大规模语言模型的AI辅助决策框架来解决重构制造系统中的实际问题。同时,本文为后续的研究提供了新的方向和视角,即如何利用最新的技术进步来推动可持续发展的可重构制造系统的进一步发展。
结论
研究表明,基于大规模语言模型的人工智能方法可以在提高重构制造系统性能方面发挥重要作用。该方法不仅可以帮助决策者快速有效地做出最优选择,还能促进生产过程中的资源优化配置及环境友好型解决方案的产生。因此,我们相信这种方法将在未来的研究中得到广泛应用,并为实现可持续发展的目标提供有力支持。
原文链接
https://www.mdpi.com/2504-2289/8/11/152
预训练语言模型在精神健康领域中的应用
研究问题
如何利用自然语言处理技术来识别和预测自杀行为?
方法
通过分析电子医疗记录、临床研究数据库以及社交媒体上的文本数据,使用深度学习方法(如卷积神经网络、循环神经网络等)训练模型以自动提取与自杀相关的信息。
创新点
本文提出了结合预训练语言模型和自然语言处理技术的解决方案来识别和预测高风险个体。同时,该研究还探讨了如何在临床研究中应用大语言模型,并讨论了伦理问题。
结论
通过利用自然语言处理技术和深度学习算法,可以从电子健康记录、社交媒体等来源提取相关文本信息以帮助识别自杀风险因素。此外,大型语言模型的应用有助于提高预测精度和效率,但仍需关注其带来的数据隐私和伦理挑战。
原文链接
https://www.cambridge.org/core/services/aop-cambridge-core/content/view/75E6B08AECDF68443C2594F421805FD9/S000712502400134Xa.pdf/detection-of-suicidality-from-medical-text-using-privacy-preserving-large-language-models.pdf
白盒探测器检测欺骗性推理的初步想法
研究问题
如何开发白盒探测器来准确地识别模型中的欺骗性推理行为,如对齐伪造或拖延策略?
方法
收集激活数据
- 收集模型在两个数据集上的激活:一个数据集包含人类或AI实体从事欺骗性推理(例如对齐伪造或拖延)的描述;另一个数据集则包含相同实体诚实地陈述其能力与意图的描述。
- 构建“欺骗”特征向量作为这两个数据集中平均激活差异的结果。
构造探测器
- 在相关的测试案例上运行模型时(例如,对齐蜜罐或能力评估),计算模型激活与“欺骗”特征向量之间的相似度,并在超过某个阈值的情况下将该实例分类为具有欺骗性推理。
- 如果只有少数例子被分类为涉及欺骗且没有明显的威胁模型相关模式(如“几乎所有的插入代码后门”或“特定类型任务的一致表现不佳”),则认为模型不太可能从事欺骗性行为。
假设
主要假设是,基于描述其他实体进行欺骗性推理的数据集构建的“欺骗”分类器将适用于模型本身的行为。可以通过评估该方法在其他不同行为上的泛化效果来获得经验支持。我们还可以通过微调模型以使其表现出预期隐藏行为(如Berglund等人的研究)来构造人工“模型有机体”。
创新点
提出了一种基于激活数据的初步方法,旨在开发能够识别模型内欺骗性推理行为的白盒探测器。
结论
尽管缺乏直接标注样本的挑战使得验证该假设变得困难,但通过评估该方法在其他不同行为上的泛化效果和构造人工“模型有机体”等方式可以提供证据支持。此初步想法为开发用于检测模型中隐藏策略性行为(如对齐伪造或拖延)的有效工具提供了思路。
原文链接
https://arxiv.org/pdf/2411.03336
基于大型语言模型的自动化CVE描述向CVSS评分转换方法研究
研究问题
如何利用大型语言模型将Common Vulnerabilities and Exposures (CVE) 描述自动转化为通用漏洞评分系统(CVSS)评分,以提高网络安全评估和响应效率?
方法
本研究提出了一种基于大型语言模型的自动化方法来解决从CVE描述到CVSS评分转换的问题。具体方法包括以下步骤:
- 数据准备:收集了大量CVE描述和对应的CVSS评分作为训练数据。
- 预处理:对文本数据进行清洗、分词等预处理操作,以便于模型输入。
- 大型语言模型应用:使用经过微调的大型语言模型来预测给定CVE描述的CVSS评分。
- 评估与优化:通过多种评价指标和交叉验证技术不断调整和完善模型。
创新点
- 提出了利用预训练的语言模型自动化生成CVSS评分的新方法,提高了网络安全评估效率。
- 该方法能够处理大量复杂多变的CVE描述,并能准确预测其对应的CVSS评分,具有良好的泛化能力和鲁棒性。
- 借助先进的人工智能技术为漏洞评分提供了新途径。
结论
本研究证明了基于大型语言模型自动化生成CVSS评分是可行且有效的。这种方法不仅可以提高网络安全评估的效率和准确性,还能帮助安全专家更快速地响应新的威胁,并做出准确的风险管理决策。
通过进一步优化和推广该方法的应用范围,将有助于构建更加智能、高效的安全防御体系。
原文链接
https://link.springer.com/article/10.1007/s10207-024-00922-z
指引先验知识以减少顺序决策中的人类反馈负担
研究问题
本研究探讨如何在顺序决策过程中通过引入指引先验知识来降低对人类反馈的需求,特别是针对强化学习中的问题。目的是减轻用户与AI系统交互时的负担,并提高系统的自主性。
方法
本论文提出了利用指引先验(Guidance Priors)的方法来减少在序列决策任务中的人类反馈需求。具体来说,通过引入一个代理模型作为人类偏好和行为模式的近似,可以显著降低需要从用户那里收集直接反馈的需求。该方法基于强化学习框架,并利用大型语言模型(LLM)进行指导先验的设计和更新。
创新点
- 设计指引先验:开发了一种新的代理模型来表示人类用户的偏好和行为模式。
- 减少反馈需求:通过在训练期间引入这些代理模型,显著减少了对用户直接反馈的依赖性。
- 提高系统效率:利用大型语言模型(LLM)生成更准确、更有针对性的先验信息,进而提升AI系统的决策质量与自主性。
结论
本研究成功展示了如何通过使用指引先验来减少顺序决策过程中的人类反馈负担。这种方法不仅提高了用户的交互体验,还增强了AI系统的学习效率和性能表现。未来的研究可以进一步探索如何将该方法应用于更多种类的决策任务中,并改进代理模型的设计以更准确地捕捉复杂的人类偏好模式。
请注意,由于论文为博士论文的一部分内容,具体实现细节和技术细节较多,这里仅概述了核心思想、研究问题与创新成果。
原文链接
https://keep.lib.asu.edu/items/197722
LIBMoE:大型语言模型混合专家库的全面基准测试
研究问题
研究不同方法(如SMoE-R,Cosine-R,Sigmoid-R,Hyper-R和Perturbed Cosine-R)在不同模型和数据集上的训练时间以及资源利用率。其中包括在CLIP + Phi3、Siglip 224 + Phi3和Siglip 224 + Phi3.5等模型上进行预训练、微调和视觉指令调整的时间。
方法
采用不同的GPU配置(从4到6个A100 GPU)对不同规模的数据集(样本数从332K到665K)进行了研究。使用多种方法包括SMoE-R,Cosine-R,Sigmoid-R,Hyper-R和Perturbed Cosine-R进行训练,并记录了每个步骤的耗时及资源消耗。
创新点
LIBMoE框架提供了全面基准测试的不同模型与数据集下的混合专家算法性能对比。通过该框架可以直观地了解不同方法在大型语言模型中的效果,为后续研究提供参考依据。
结论
各种方法(如SMoE-R、Cosine-R等)的训练时间及资源利用情况如下表所示:
- 对于CLIP + Phi3和Siglip 224 + Phi3模型,在大规模数据集上进行预训练的时间分别为5小时35分钟和2小时55分钟。
- 预微调耗时分别为18小时和17小时05分钟。
- 不同方法在大型数据集上的训练时间(从44到55小时不等)以及较小规模数据集上调整时间(从26到33小时不等),都反映了模型复杂度与资源需求的关系。
这些结果为未来研究提供了重要参考。
原文链接
https://arxiv.org/pdf/2411.00918
基于参数高效的大型语言模型再参数化微调方法:系统性综述
研究问题
本文探讨了基于参数高效的大型语言模型再参数化微调方法在自然语言处理领域中的应用。研究的重点是评估这些方法的有效性和效率,以及它们如何能够使大型预训练的语言模型更好地适应特定任务和数据集。
方法
文章综述了一系列的再参数化技术,包括低秩分解、门控机制(如GateTuner)、基于知识蒸馏的方法以及其他最新的创新手段。通过实验分析,研究人员比较了不同方法在各种基准测试中的表现,以了解它们的优势与劣势。
创新点
本研究提供了一个全面而详尽的视角来理解大型语言模型再参数化的多种实现方式及其潜在应用领域。特别是,在如何更有效地利用有限资源的同时提升模型性能方面提供了新的见解和建议。
结论
通过对比分析,本文发现再参数化技术可以显著提高大模型在低资源条件下的微调效率及泛化能力。未来的研究方向可能包括探索更多的优化策略来进一步增强这种方法的效果,并扩大其适用范围。
原文链接
https://link.springer.com/chapter/10.1007/978-981-97-9437-9_9