这是我的第374篇原创文章。
一、引言
SHAP有多种实现方式,每种方式都适用于特定的模型类型,可以实现更快的逼近。
-
TreeExplainer :TreeExplainer专为树集合方法开发,如XGBoost,LightGBM或CatBoost。
-
DeepExplainer :DeepExplainer是为深度学习模型开发的,支持TensorFlow / Keras。
-
GradientExplainer :GradientExplainer也是为深度学习模型中的SHAP值而开发的,但速度比DeepExplainer慢,并且做出了不同的假设。此方法基于Integrated Gradient归因方法,并支持TensorFlow / Keras / PyTorch。
-
KernelExplainer :KernelExplainer使用加权线性回归近似任何类型模型的SHAP值。
使用特定于模型类型的算法(TreeExplainer,DeepExplainer)而不是通用KernelExplainer更快更有效。
本文以XGB分类器为例,展示了如何使用条形图和蜂群图来可视化全局特征重要性。
二、实现过程
2.1 准备数据
# 准备数据
data = pd.read_csv(r'dataset.csv')
df = pd.DataFrame(data)
# 提取目标变量和特征变量
target = 'target'
features = df.columns.drop(target)
# 划分训练集和测试集
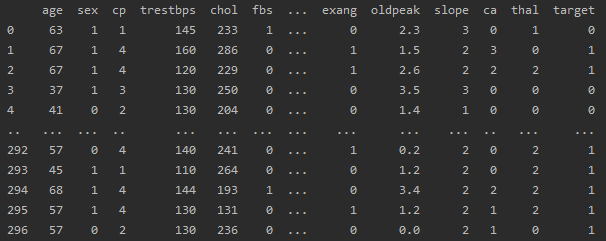
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)df:
2.2 模型训练
# 模型的构建与训练
model = XGBClassifier()
model.fit(X_train, y_train)2.3 创建SHAP解释器
# 创建Explainer
explainer = shap.TreeExplainer(model, X_test)
# 以numpy数组的形式输出SHAP值
shap_values = explainer.shap_values(X_test)
print(shap_values) # shap_values = shap_obj.values
# 以SHAP的Explanation对象形式输出SHAP值
shap_obj = explainer(X_test)
print(shap_obj.values) # shap_values = shap_obj.values2.4 绘制全局条形图
SHAP提供了一种全局特征重要性图的方法,这种方法考虑了所有样本,并计算每个特征的平均绝对SHAP值:
shap.plots.bar(shap_obj)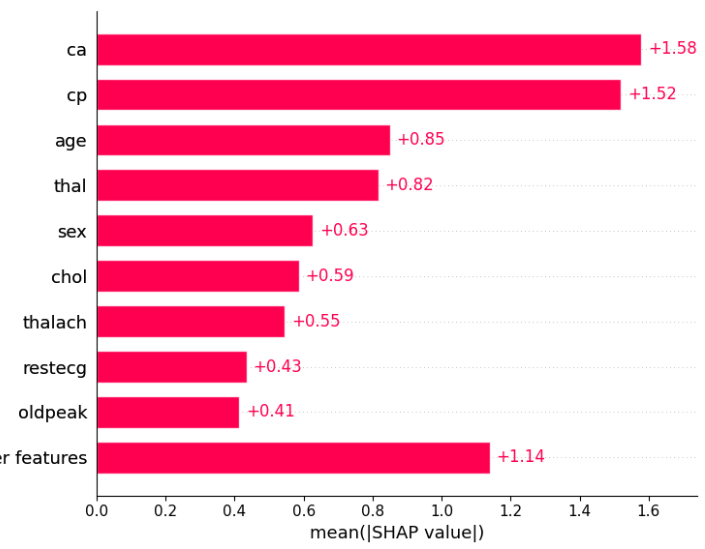
2.5 绘制全局蜂群图
蜂群图(Beeswarm Plot)是另一种可视化特征重要性和影响的方法。蜂群图旨在显示数据集中的TOP特征如何影响模型输出的信息密集摘要。
shap.plots.beeswarm(shap_obj, show=True) # 全局蜂群图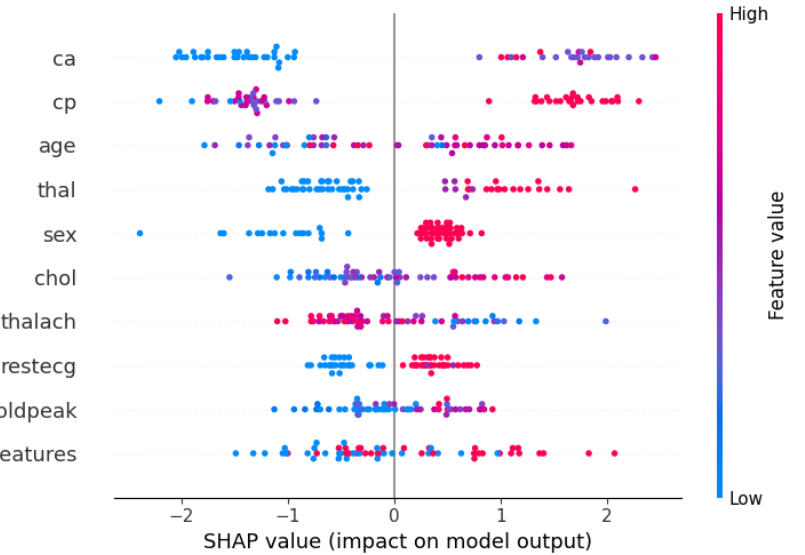
给定解释的每个实例由每个特征流上的一个点表示;点的 x 位置由该特征的 SHAP 值 ( shap_values.value[instance,feature]) 确定,并且点沿每个特征行“堆积”以显示密度;
条形图与蜂群图的对比,条形图就只是展示了蜂群图的平均值。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。