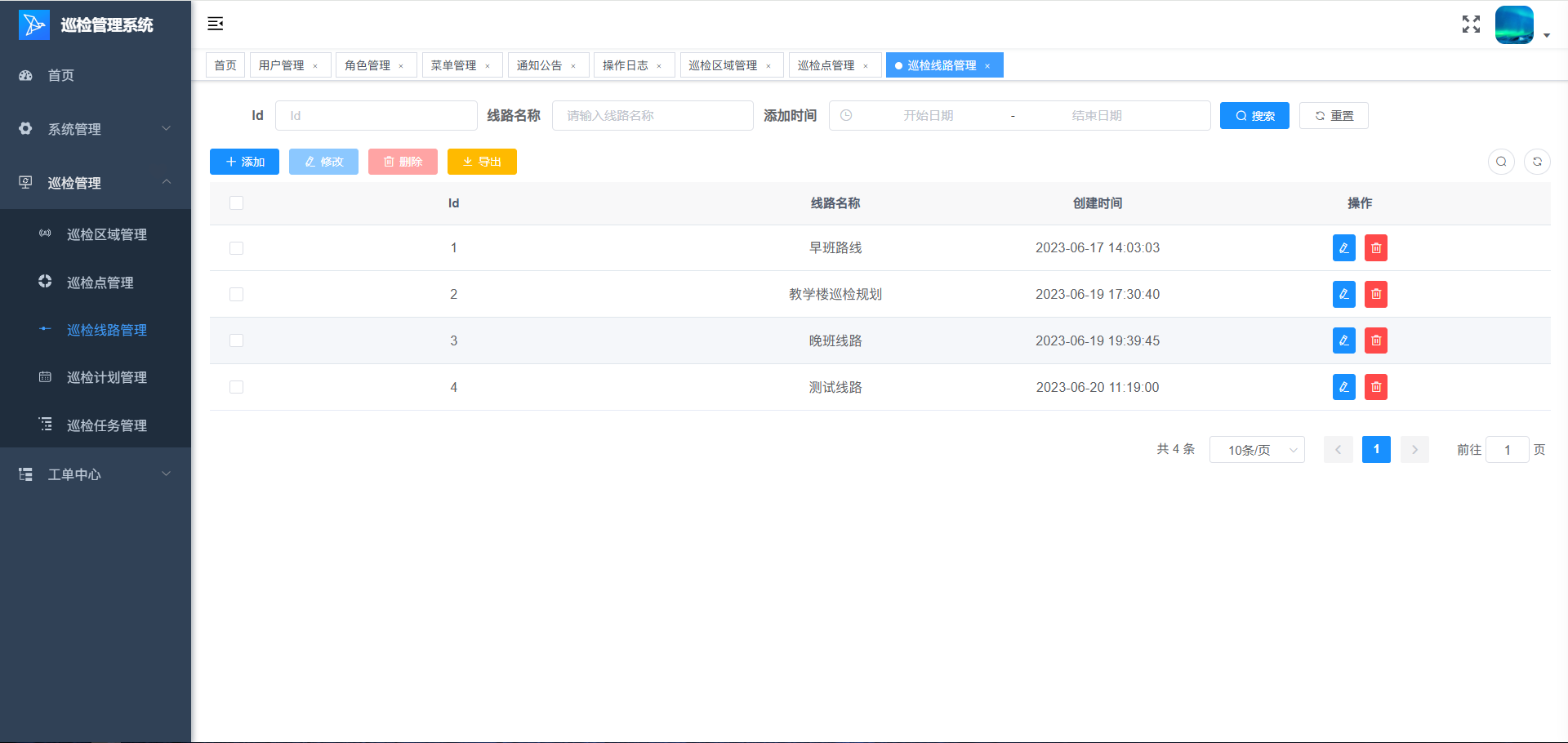
前言:可借鉴资料
文档:https://docs.nebula-graph.com.cn
Nebula Graph架构,实践等文章:https://nebula-graph.com.cn/posts
视频分享和教程:https://space.bilibili.com/472621355
入门文章索引:https://zhuanlan.zhihu.com/p/368781105
用户问答论坛:https://discuss.nebula-graph.com.cn
GitHub:https://github.com/vesoft-inc/nebula-graph
Nebula 布道者博客:https://siwei.io/posts/
Nebula 图数据库的逻辑组成:
图空间(Space) 由 点(Vertex),标签(Tag),边(Edge),边类型(Edge type)
图空间(Space) 在NGQL中 有TAG 与 EDGE两个存储概念。
TAG:记录实体信息,每个实体中都有一个VID 在一个图空间中,VID的值是唯一的 但是VID 在insert时,并不限制VID重复,但是在delete时,会导致所有相同的VID 被删除。
EDGE:记录关系信息,每个关系信息中都有一个RANK 在一个关系中用于组成组合唯一值。它也可以为点增加属性,比如 100->100:(money=一个小目标)。
一、图空间的创建
涉及两个参数:partition_num和replica_factor
partition_num 默认值是100,replica_factor 的参数值是1
第一种创建图空间方式,默认值创建
#默认值创建表空间
create space default_value;
#查看表空间的属性
describe space default_value;
第二种创建图空间的方式,是通过指定partition_num值
create space specify_partition(partition_num=10)
查看图空间属性
describe space specify_partition;
第三种创建图空间的方式,是通过指定replica_factor值
create space specify_replica(replica_factor=3);
describe space specify_replica;
第四种创建图空间的方式,是通过指定partition_num与replica_factor值的方式
create space nba(partition_num=10,replica_factor=3);
describe space nba;
#使用如下命令查看已存在的图空间
show spaces;
#使用如下命令删除图空间
drop space default_value;
#使用如下命令切换到图空间中
use nba;
二、在Nebula Graph 中创建标签
#创建与查看
create tag player(name string,age int);
show tags;
create tag team(name string);
show team;
#查看tag详情
describe tag player;
describe tag team;
#创建于删除
create tag property_free();
drop tag property_free;
三、在Nebula Graph 中创建边类型
#创建与查看
create edge follow(degree int);
show edges;
create edge serve(start_year int,end_year int);
show edges;
#查看edge详情
describe edge follow;
describe edge serve;
#创建与删除
create edge no_property();
drop edge no_property;
四、在Nebula Graph 中插入点(VID 必须要引号引起来,否则报错)
insert vertex player(name,age) values "100":("Tim Duncan",42);
insert vertex player(name,age) values "101":("Tony Parker",36),"102":("LaMarcus Aldridge",33),"103":("Rudy Gay",32),"99":("Useless",0);
insert vertex team(name) values "200":("Warriors"),"201":("Nuggets");
#查看(使用FETCH 查询点的属性值)(VID 必须要引号引起来,否则报错)
FETCH PROP ON player "100","101","102","103" YIELD properties(vertex);
FETCH PROP ON team "200","201" YIELD properties(vertex);
#删除点语句
delete vertex "101";
fetch prop on player;
Wrong vertex id type;
五、在Nebula Graph 中插入边
#释义 100是点的起始位置,指向-> 101点的最终位置:(值)
#插入边数据
insert edge follow(degree) values "100" -> "101":(95);
insert edge serve(start_year,end_year) values "100" -> "101":(1997,2016),"101" -> "201":(1999,2018);
#查询点与点之间边的信息(关联关系)
fetch prop on follow "100" -> "101" YIELD properties(edge);
fetch prop on serve "100" -> "200","101" -> "201" YIELD properties(edge);
#在两个点之间插入多条同类型的边,可以使用ranking参数"101"@1 其中1 表示ranking的值
insert edge follow(degree) values "100" -> "101"@1:(80);
fetch prop on follow "100" -> "101"@1 YIELD properties(edge);
#删除边,删除带有ranking值的边
delete edge follow "100" -> "101";
delete edge follow "100" -> "101"@1;
六、在Nebula Graph 中查询数据
使用go语句查询
#指定起始位置遍历所有位置(起点VID 100开始查询,遍历所有被VID 100关注的点)
GO FROM 100 OVER follow;
#找到年龄大于35的球员且该球员被VID为100的球员关注(WHERE语句限定年龄,$$符号表示目标点,YIELD语句指定返回的结果并别名展示)
GO FROM 100 OVER follow WHERE $$.player.age > 35 YIELD $$.player.name AS Teammate,$$.player.age AS Age;
#找到VID 100 关注的球员所效力的球队(两种方式:第一种方式中使用管道(pipe),第二种方式中使用临时变量)
GO FROM 100 OVER follow YIELD follow._dst AS id | \
GO FROM $-.id OVER serve YIELD $$.team.name \
AS Team,$^.player.name AS Player;
解释:|竖线 表示管道,\斜线表换行符。意思是将第一个GO语句得到的值作为第二条GO语句的输入值。
$var=GO FROM 100 OVER follow YIELD follow.dst AS id; \
GO FROM $var.id OVER serve YIELD $$.team.name \
AS Team,$^.player.name AS Player;
解释:将第一个GO语句定义为一个变量,在第二个GO语句中引入该变量
图语义的Query 可以更快的进行操作,书写的SQL 复杂的度较小于关系型SQL。