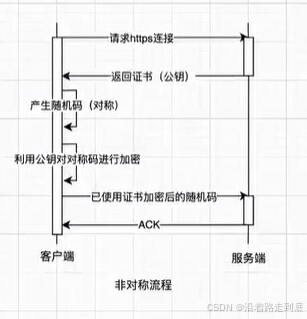
Llama的框架图如图:

源码中含有大量分布式训练相关的代码,读起来比较晦涩难懂,所以我们对llama自顶向下进行了解析及复现,我们对其划分成三层,分别是顶层、中层、和底层,如下:
Llama的整体组成
由上图可知,Llama整体是由1个embedding层,n个transformer层,和1个RMSNorm层组成的,所以顶层代码如下:
顶层
class Llama(torch.nn.Module):def __init__(self, config: ModelArgs):super().__init__()self.config = config# embedding层self.tok_embeddings = torch.nn.Embedding(self.config.vocab_size, self.config.dim)# RMSNormself.norm = RMSNorm(config.dim, eps=config.norm_eps)# n层Transformerself.layers = torch.nn.ModuleList()for i in range(self.config.n_layers):self.layers.append(TransformerBlock(config))def forward(self, tokens):# 进行token的嵌入编码h = self.tok_embeddings(tokens)# decoder架构需要生成一个maskseqlen = h.shape[1]mask = torch.full((seqlen, seqlen), float('-inf'), device=tokens.device)mask = torch.triu(mask, diagonal=1)# 进行n层Transformerfor i in range(self.config.n_layers):h = self.layers[i](h, mask)# 进行RMSNormtoken_embeddings = self.norm(h)return token_embeddings
中层
我们首先进行RMSNorm的复现
class RMSNorm(torch.nn.Module):def __init__(self, dim, eps):super().__init__()self.eps = epsself.weight = torch.nn.Parameter(torch.ones(dim))def _norm(self, tensor):return tensor * torch.rsqrt(tensor.pow(2).mean(-1, keepdim=True) + self.eps)def forward(self, tensor):output = self._norm(tensor)return output * self.weight
然后对Transformer进行复现,在Transformer中,Transformer包括两个RMSNorm层,一个多头attention层,一个全连接层。
class TransformerBlock(torch.nn.Module):def __init__(self, config):super().__init__()self.config = config# 多头注意力层self.attention = Attention(config)# Norm层self.attention_normal = RMSNorm(config.dim, config.norm_eps)self.ffn_norm = RMSNorm(config.dim, config.norm_eps)# 全连接层self.ffn = FeedForwad(self.config.dim, self.config.dim * 4)def forward(self, embeddings, mask):# normh = self.attention_normal(embeddings)# attentionh = self.attention(h, mask)# add & normh = self.ffn_norm(h + embeddings)# fnnf = self.ffn(h)# addreturn f + h
底层
在多头attention中,首先需要对token的嵌入进行空间映射,多头拆分,旋转位置编码,分数计算等操作
class Attention(torch.nn.Module):def __init__(self, config):super().__init__()self.config = configself.n_head = config.n_headsself.dim = config.dim // self.n_headself.k = torch.nn.Linear(config.dim, config.dim)self.q = torch.nn.Linear(config.dim, config.dim)self.v = torch.nn.Linear(config.dim, config.dim)def forward(self, embeddings, mask):bsz, seq_len, dim = embeddings.shapek_embeddings = self.k(embeddings)q_embeddings = self.q(embeddings)v_embeddings = self.v(embeddings)n_q_embeddings = q_embeddings.reshape(bsz, -1, self.n_head, self.dim).permute(0, 2, 1, 3)n_k_embeddings = k_embeddings.reshape(bsz, -1, self.n_head, self.dim).permute(0, 2, 1, 3)n_v_embeddings = v_embeddings.reshape(bsz, -1, self.n_head, self.dim).permute(0, 2, 1, 3)rotated_n_q_embeddings = compute_rotated_embedding(n_q_embeddings, self.dim, seq_len, self.config.rope_theta)rotated_n_k_embeddings = compute_rotated_embedding(n_k_embeddings, self.dim, seq_len, self.config.rope_theta)scores = torch.nn.functional.softmax(mask + rotated_n_q_embeddings @ rotated_n_k_embeddings.transpose(-1, -2)/ math.sqrt(self.dim), dim=-1)n_embeddings = scores @ n_v_embeddingsembeddings = n_embeddings.permute(0, 2, 1, 3).reshape(bsz, -1, self.config.dim)return embeddings
class FeedForwad(torch.nn.Module):def __init__(self, dim, hidden_dim):super().__init__()self.linear1 = torch.nn.Linear(dim, hidden_dim)self.linear2 = torch.nn.Linear(dim, hidden_dim)self.linear3 = torch.nn.Linear(hidden_dim, dim)def forward(self, embeddings):gate = torch.nn.functional.silu(self.linear1(embeddings))up_proj = self.linear2(embeddings) * gatereturn self.linear3(up_proj)
最后,我们复现旋转位置编码,至此我们捋清了llama的所有结构!
def compute_rotated_embedding(embedding, dim, m, base):# 计算所有嵌入位置的旋转角度all_theta = compute_all_theta(dim, m, base)# 旋转后嵌入位置 = 复数平面上初始位置 * 复数平面上角度坐标# 1、将嵌入投影到复数平面embedding_real_pair = embedding.reshape(*embedding.shape[:-1], -1, 2)embedding_complex_pair = torch.view_as_complex(embedding_real_pair)# 2、将旋转角度投影到复数平面all_theta = all_theta[: embedding.shape[-2]]theta_complex_pair = torch.polar(torch.ones_like(all_theta), all_theta)# 3、旋转后嵌入位置 = 复数平面上初始位置 * 复数平面上角度坐标rotated_complex_embedding = embedding_complex_pair * theta_complex_pair# 4、将复数平面的嵌入投影到实数平面rotated_real_embedding = torch.view_as_real(rotated_complex_embedding)rotated_real_embedding = rotated_real_embedding.reshape(*embedding.shape[:-1], -1)return rotated_real_embeddingdef compute_all_theta(dim, m, base):theta = 1 / (base ** (torch.arange(0, dim / 2).float() / (dim / 2)))m = torch.arange(0, m)all_theta = torch.outer(m, theta)return all_theta附录:llama的config参数
@dataclass
class ModelArgs:dim: int = 4096n_layers: int = 32n_heads: int = 32n_kv_heads: Optional[int] = Nonevocab_size: int = -1multiple_of: int = 256 # make SwiGLU hidden layer size multiple of large power of 2ffn_dim_multiplier: Optional[float] = Nonenorm_eps: float = 1e-5rope_theta: float = 500000max_batch_size: int = 32max_seq_len: int = 2048use_scaled_rope: bool = True