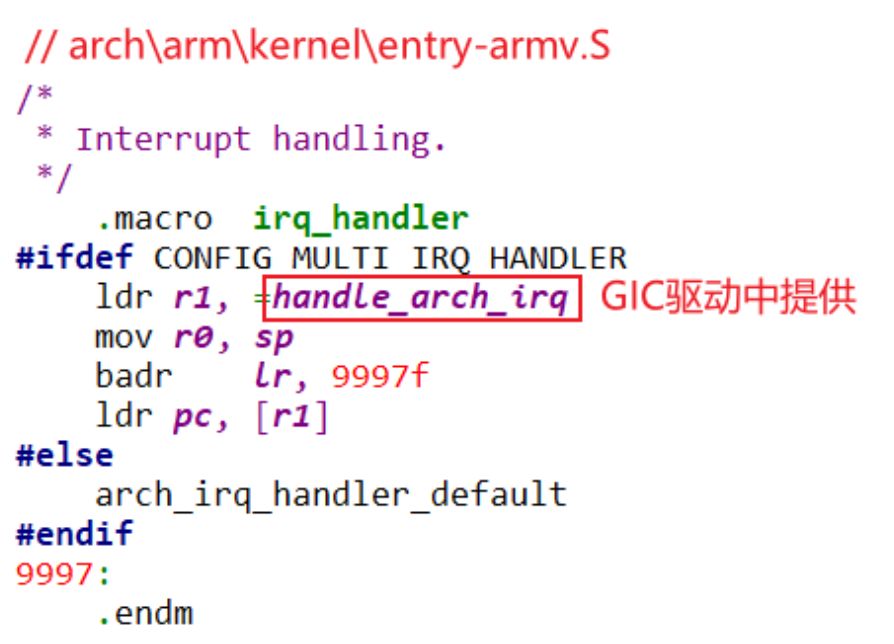
《Python网络安全项目实战》项目5 编写网站扫描程序
- 项目目标:
- 任务5.1 暴力破解网站目录和文件位置
- 任务描述
- 任务分析
- 任务实施
- 相关知识
- 任务评价
- 任务5.2 制作网页JPG爬虫
- 任务分析
- 任务实施
- 相关知识
- 任务评价
- 任务拓展
WEB网站安全渗透测试过程中需要进行目录扫描和网站爬行,网上可以找到一些不错的工具软件,但是对于别人写的工具是否安全可靠有待商榷,所以我们如果能够写出自己的网站扫描和爬行程序,对于我们的工作会有极大的帮助。
使用Python的标准网络模块编写网络工具软件非常方便,这里我们使用Python完成网站扫描程序的编写。
项目目标:
熟悉使用Python进行网站扫描程序的编写。
任务5.1 暴力破解网站目录和文件位置
任务描述
当我们通过sql注入等方式得到网站的数据库时,由于后台一般是隐藏起来的,所以我们想要登陆后台的话,还是要手工或者以暴力破解的方式找到后台。
任务分析
对一个站点目录和文件进行扫描,那么就需要用Python3环境下requests模块。扫描目录主要是对网站地址发出请求,若网站存在这个地址则会返回状态码200,如果不存在则会返回404,如果是没有权限访问,或者是其他一些情况,都会有相应的状态码,我们主要是需要访问成功的状态码和地址就可以了。
Requests 是使用 Apache2 Licensed 许可证的 HTTP 库, 支持 HTTP 连接保持和连接池,支持使用cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。本次任务要扫描的WWW服务器就搭建在本机上,我们在本机搭建了一个Discuz网站,计划扫描的网址是:http://127.0.0.1/Discuz/upload。
pathlist.txt是预先准备的字典文件,包含网站常用文件路径的字符串列表。
应用字典碰撞的原理,使用上万条字典条目进行碰撞。字典中包括常用网站的含有路径的文件名,获得有反馈的条目记录,其中就体现出了常用网站的目录结构。
任务实施
实验环境:windows 7、phpstudy、php5.4.45、apache、mysql5.0.10。
【步骤1】:建立pathlist.txt,我们将这些文件夹的名字保存进一个TXT文件中,建立一个目录字典,再加一些这个目录中没有的文件名扩展程序可查找文件范围,如图5-1-1所示。

图5-1-1 建立字典文件
【步骤2】:对网站的请求我们需要用requests模块中的一些方法,所以在写之前需要引用requests模块,如图5-1-2所示。

图5-1-2 引用requests模块
【步骤3】:我们需要对一个网站进行扫描,那么就需要一个网站的地址,和一个扫描的字典,如图5-1-3所示。

图5-1-3 定义变量接收网址和字典
【步骤4】:因为我们要将字典与网站路径结合形成一个新的url,每形成一个新的url,就对这个url进行一次请求,所以我们用for来实现,如图5-1-4所示。

图5-1-4 对地址进行请求,并返回状态码
【步骤5】:在接收到每个地址返回的状态码之后,我们需要对这些信息进行判断和输出,如图5-1-5所示。


图5-1-5 对结果进行判断打印
【步骤6】:在编写完python程序之后,我们对程序进行测试,在本地安装phpstudy,打开phpstudy的安装目录,www文件夹是用来放置web站点文件的,如图5-1-6所示。

图5-1-6 phpstudy目录
【步骤7】:打开www文件夹,我们将Discuz站点放置进来,如图5-1-7所示。

图5-1-7 所有网站主目录
【步骤8】:Discuz需要在web界面去安装一下,一路下一步就可以安装完成,打开Discuz的目录,所有的网站文件都会放在upload文件夹中,如图5-1-8所示。

图5-1-8 Discuz站点安装目录
【步骤9】:Discuz网站的目录中有一些文件和文件夹,这些都是我们需要用python来扫描的,如图5-1-9所示。

图5-1-9 Discuz网站主目录
【步骤10】:做完这些,我们启动我们的phpstudy,看到apache和mysql成功运行,就可以了,如果启动不成功,则重试一次,如图5-1-10所示。

图5-1-10 启动运行phpstudy
【步骤11】:看网站是否可以打开,打开浏览器,输入6,如图5-1-11所示。

图5-1-11 访问Discuz网站
【步骤12】:运行我们之前写好的python脚本,扫描搭建好的站点,扫描结果列出了我们需要的网站目录,如图5-1-12所示。

图5-1-12 运行脚本显示结果
【步骤13】:用netstat -an命令查看本地的网络连接端口,如图5-1-13所示。

图5-1-13 查看网络连接
相关知识
Python目录操作方法
- 创建目录
os.mkdir(“file”) - 复制文件
shutil.copyfile(“oldfile”,“newfile”)
#oldfile和newfile都只能是文件
shutil.copy(“oldfile”,“newfile”)
#oldfile只能是文件夹,newfile可以是文件,也可以是目标目录 - 复制文件夹
shutil.copytree(“olddir”,“newdir”)
#olddir和newdir都只能是目录,且newdir必须不存在 - 重命名文件(目录)
os.rename(“oldname”,“newname”)
#文件或目录都是使用这条命令 - 移动文件(目录)
shutil.move(“oldpos”,“newpos”) - 删除文件
os.remove(“file”) - 删除目录
os.rmdir(“dir”)
#只能删除空目录
shutil.rmtree(“dir”)
#空目录、有内容的目录都可以删 - 转换目录
os.chdir(“path”)
#换路径
任务评价

合计 50
任务拓展
Time模块的主要功能是什么?
任务5.2 制作网页JPG爬虫
任务描述
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。
这里可以通过python来实现这样一个简单的爬虫功能,把我们想要的图片爬取并下载到本地。下面就看看如何使用python来实现这样一个功能。
任务分析
利用Python抓取网络图片的步骤:
- 根据给定的网址获取网页源代码。
- 利用正则表达式把源代码中的图片地址过滤出来。
- 根据过滤出来的图片地址下载网络图片。
任务实施
实验环境:centos7.2、Python2.7。
【步骤1】:代码注释要用到中文所以加载utf-8字符集,对网站的读取我们需要用到urllib模块中的一些方法,所以在写之前需要引用urllib模块,后面获取图片地址要用到正则表达式,所以加载re模块,如图5-2-1所示。

图5-2-1 引用utllib和re模块
【步骤2】:我们需要定义一个过程函数来打开一个URL地址,如图5-2-2所示。

图5-2-2 定义打开URL的过程函数
【步骤3】:我们需要定义一个过程函数在获取图片地址,如图5-2-3所示。

图5-2-3 定义获得图片地址的过程函数
【步骤4】:把筛选的图片地址通过for循环遍历并保存到本地,并且对html对象设置图片下载地址,并print输出结果,如图5-2-4所示。


图5-2-4 对结果进行判断打印
【步骤5】:进入脚本所在目录,如图5-2-5所示。

图5-2-5 进入Python脚本所在目录
【步骤6】:右键点击终端中运行python test1.py,如图5-2-6所示。

图5-2-6 执行Python脚本
【步骤7】:在目录获得图片,如图5-2-7所示。

图5-2-7 图片被下载到目录中
相关知识
正则表达式,又称正规表示法、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE)。正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。正则表达式通常缩写成"regex",单数有regexp、regex,复数有regexps、regexes、regexen。
实例:
字符串;tel:086-0666-88810009999
原始正则:“^tel:[0-9]{1,3}-[0][0-9]{2,3}-[0-9]{8,11}KaTeX parse error: Undefined control sequence: \d at position 102: …价简写后正则写法:"^tel:\̲d̲{1,3}-[0]\d{2,3…” ,简写语法不是所有语言都支持。
以下为元字符速查表:


任务评价

任务拓展
把代码中的for循环改为while循环并且运行,验证输出结果。
项目评价