十 集成学习方法之随机森林
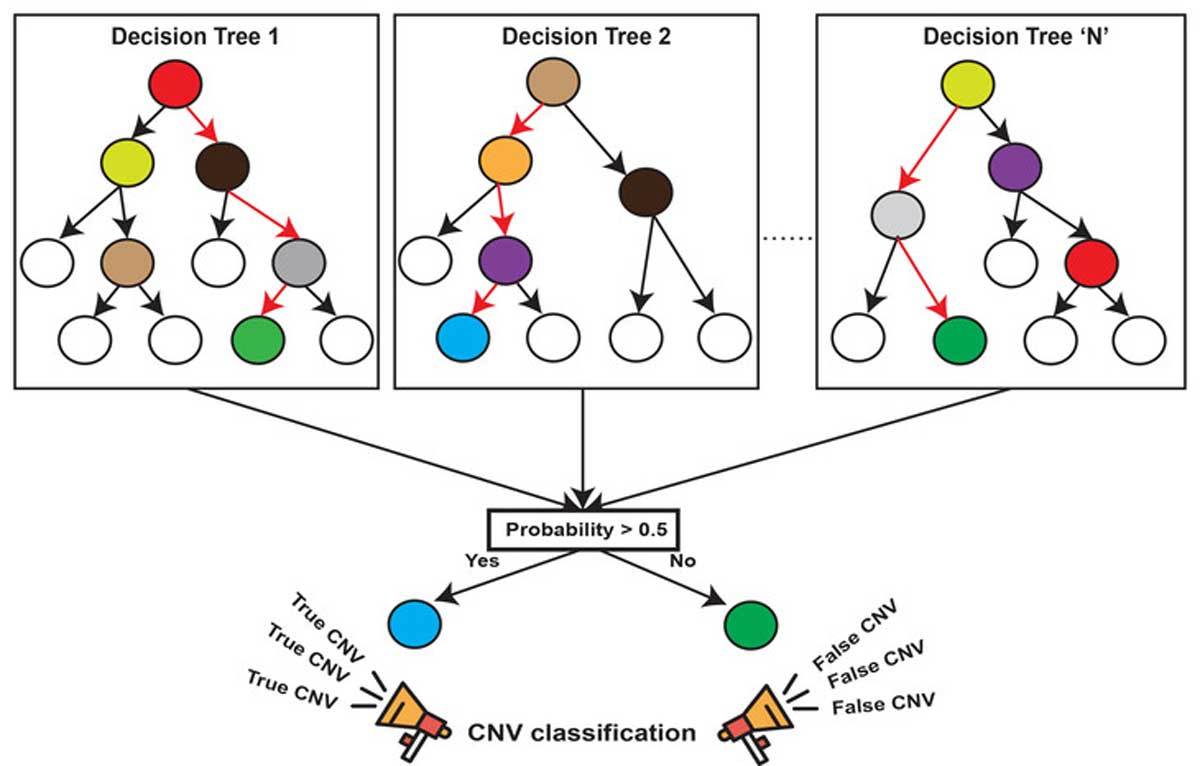
机器学习中有一种大类叫集成学习(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。集成算法大致可以分为:Bagging,Boosting 和 Stacking 三大类型。
(1)每次有放回地从训练集中取出 n 个训练样本,组成新的训练集;
(2)利用新的训练集,训练得到M个子模型;
(3)对于分类问题,采用投票的方法,得票最多子模型的分类类别为最终的类别;
随机森林就属于集成学习,是通过构建一个包含多个决策树(通常称为基学习器或弱学习器)的森林,每棵树都在不同的数据子集和特征子集上进行训练,最终通过投票或平均预测结果来产生更准确和稳健的预测。这种方法不仅提高了预测精度,也降低了过拟合风险,并且能够处理高维度和大规模数据集
1 算法原理

- 随机: 特征随机,训练集随机
- 样本:对于一个总体训练集T,T中共有N个样本,每次有放回地随机选择n个样本。用这n个样本来训练一个决策树。
- 特征:假设训练集的特征个数为d,每次仅选择k(k<d)个来构建决策树。
- 森林: 多个决策树分类器构成的分类器, 因为随机,所以可以生成多个决策树
- 处理具有高维特征的输入样本,而且不需要降维
- 使用平均或者投票来提高预测精度和控制过拟合
2 Sklearn API
class sklearn.ensemble.RandomForestClassifier参数:
n_estimators int, default=100
森林中树木的数量。(决策树个数)criterion {“gini”, “entropy”}, default=”gini” 决策树属性划分算法选择当criterion取值为“gini”时采用 基尼不纯度(Gini impurity)算法构造决策树,当criterion取值为 “entropy” 时采用信息增益( information gain)算法构造决策树.max_depth int, default=None 树的最大深度。
3 示例
坦尼克号乘客生存
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV# 1、获取数据
titanic = pd.read_csv("src/titanic/titanic.csv")
titanic.head()
# 筛选特征值和目标值
x = titanic[["pclass", "age", "sex"]]
y = titanic["survived"]#2、数据处理
# 1)缺失值处理
x["age"].fillna(x["age"].mean(), inplace=True)
# 2) 转换成字典
x = x.to_dict(orient="records")
# 3)、数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 4)、字典特征抽取
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)'''
#3 预估: 不加网格搜索与交叉验证的代码
estimator = RandomForestClassifier(n_estimators=120, max_depth=5)
# 训练
estimator.fit(x_train, y_train)
'''#3 预估: 加网格搜索与交叉验证的代码
estimator = RandomForestClassifier()
# 参数准备 n_estimators树的数量, max_depth树的最大深度
param_dict = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5,8,15,25,30]}
# 加入网格搜索与交叉验证, cv=3表示3次交叉验证
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3)
# 训练
estimator.fit(x_train, y_train)# 5)模型评估
# 方法1:直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)# 方法2:计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)'''
加网格搜索与交叉验证的代码
print("最佳参数:\n", estimator.best_params_)
print("最佳结果:\n", estimator.best_score_)
print("最佳估计器:\n", estimator.best_estimator_)
print("交叉验证结果:\n", estimator.cv_results_)
'''
#估计运行花1min
十一 线性回归(重点)
前面介绍了很多分类算法,分类的目标变量是标称型数据,回归是对连续型的数据做出预测。
标称型数据(Nominal Data)是统计学和数据分析中的一种数据类型,它用于分类或标记不同的类别或组别,数据点之间并没有数值意义上的距离或顺序。例如,颜色(红、蓝、绿)、性别(男、女)或产品类别(A、B、C)。
标称数据的特点:
- 无序性:标称数据的各个类别之间没有固有的顺序关系。例如,“性别”可以分为“男”和“女”,但“男”和“女”之间不存在大小、高低等顺序关系。
- 非数值性:标称数据不能进行数学运算,因为它们没有数值含义。你不能对“颜色”或“品牌”这样的标称数据进行加减乘除。
- 多样性:标称数据可以有很多不同的类别,具体取决于研究的主题或数据收集的目的。
- 比如西瓜的颜色,纹理,敲击声响这些数据就属于标称型数据,适用于西瓜分类
连续型数据(Continuous Data)表示在某个范围内可以取任意数值的测量,这些数据点之间有明确的数值关系和距离。例如,温度、高度、重量等
连续型数据的特点包括:
- 可测量性:连续型数据通常来源于物理测量,如长度、重量、温度、时间等,这些量是可以精确测量的。
- 无限可分性:连续型数据的取值范围理论上是无限可分的,可以无限精确地细分。例如,你可以测量一个物体的长度为2.5米,也可以更精确地测量为2.53米,甚至2.5376米,等等。
- 数值运算:连续型数据可以进行数学运算,如加、减、乘、除以及求平均值、中位数、标准差等统计量。
在数据分析中,连续型数据的处理和分析方式非常丰富,常见的有:
- 描述性统计:计算均值、中位数、众数、标准差、四分位数等,以了解数据的中心趋势和分布情况。
- 概率分布:通过拟合概率分布模型,如正态分布、指数分布、伽玛分布等,来理解数据的随机特性。
- 图形表示:使用直方图、密度图、箱线图、散点图等来可视化数据的分布和潜在的模式。
- 回归分析:建立连续型变量之间的数学关系,预测一个或多个自变量如何影响因变量。
- 比如西瓜的甜度,大小,价格这些数据就属于连续型数据,可以用于做回归
1.什么是回归?
回归的目的是预测数值型的目标值y。最直接的办法是依据输入x写出一个目标值y的计算公式。假如你想预测小姐姐男友汽车的功率,可能会这么计算:
HorsePower = 0.0015 * annualSalary - 0.99 * hoursListeningToPublicRadio
写成中文就是:
小姐姐男友汽车的功率 = 0.0015 * 小姐姐男友年薪 - 0.99 * 收听公共广播的时间
这就是所谓的回归方程(regression equation),其中的0.0015和-0.99称为回归系数(regression weights),求这些回归系数的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法是用回归系数乘以输入值,再将结果全部加在一起,就得到了预测值。
2.线性回归
说到回归,一般都是指线性回归(linear regression)。线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。线性回归是机器学习中一种有监督学习的算法,回归问题主要关注的是因变量(需要预测的值)和一个或多个数值型的自变量(预测变量)之间的关系.
需要预测的值:即目标变量,target,y
影响目标变量的因素: X 1 , X 2 . . . X n X_1,X_2...X_n X1,X2...Xn,可以是连续值也可以是离散值
因变量和自变量之间的关系:即模型,model,就是我们要求解的
比如1个包子是2元 3个包子是6元 预测5个包子多少钱
列出方程: y = w x + b y=wx+b y=wx+b
带入:
2=w*1+b
6=w*3+b
轻易求得 w=2 b=0
模型(x与y的关系): y = 2 ∗ x + 0 y=2*x+0 y=2∗x+0
预测 x=5 时 target_y=2*5+0=10元
上面的方程式我们人类很多年以前就知道了,但是不叫人工智能算法,因为数学公式是理想状态,是100%对的,而人工智能是一种基于实际数据求解最优最接近实际的方程式,这个方程式带入实际数据计算后的结果是有误差的.
人工智能中的线性回归:数据集中,往往找不到一个完美的方程式来100%满足所有的y目标
我们就需要找出一个最接近真理的方程式
比如:
有这样一种植物,在不同的温度下生长的高度是不同的,对不同温度环境下,几颗植物的环境温度(横坐标),植物生长高度(纵坐标)的关系进行了采集,并且将它们绘制在一个二维坐标中,其分布如下图所示:
坐标分别为[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]。

我们发现这些点好像分布在一条直线的附近,那么我们能不能找到这样一条直线,去“拟合”这些点,这样的话我们就可以通过获取环境的温度大概判断植物在某个温度下的生长高度了。
于是我们的最终目的就是通过这些散点来拟合一条直线,使该直线能尽可能准确的描述环境温度与植物高度的关系。
3.损失函数
数据: [[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]]
我们假设 这个最优的方程是:
y = w x + b y=wx+b y=wx+b
这样的直线随着w和b的取值不同 可以画出无数条
在这无数条中,哪一条是比较好的呢?

我们有很多方式认为某条直线是最优的,其中一种方式:均方差
就是每个点到线的竖直方向的距离平方 求和 在平均 最小时 这条直接就是最优直线

假设: y = w x + b y=wx+b y=wx+b
把 x 1 , x 2 , x 3 . . . x_1,x_2,x_3... x1,x2,x3...带入进去 然后得出:
y 1 , = w x 1 + b y_1^,=wx_1+b y1,=wx1+b
y 2 , = w x 2 + b y_2^,=wx_2+b y2,=wx2+b
y 3 , = w x 3 + b y_3^,=wx_3+b y3,=wx3+b
…
然后计算 y 1 − y 1 , {y_1-y_1^,} y1−y1, 表示第一个点的真实值和计算值的差值 ,然后把第二个点,第三个点…最后一个点的差值全部算出来
有的点在上面有点在下面,如果直接相加有负数和正数会抵消,体现不出来总误差,平方后就不会有这个问题了
所以最后:
总误差(也就是传说中的损失):
loss1= ( y 1 − y 1 , ) 2 + ( y 2 − y 2 , ) 2 + . . . . ( y n − y n , ) 2 {(y_1-y_1^,)^2}+{(y_2-y_2^,)^2}+....{(y_n-y_n^,)^2} (y1−y1,)2+(y2−y2,)2+....(yn−yn,)2
平均误差(总误差会受到样本点的个数的影响,样本点越多,该值就越大,所以我们可以对其平均化,求得平均值,这样就能解决样本点个数不同带来的影响)
这样就得到了传说中的损失函数:
e ˉ = 1 n ∑ i = 1 n ( y i − w x i − b ) 2 \bar e = \frac{1}{n} \textstyle\sum_{i=1}^{n}(y_{i}-w x_{i} - b)^{2} eˉ=n1∑i=1n(yi−wxi−b)2
怎么样让这个损失函数的值最小呢?
我们先假设b=0 (等后面多元方程求解这个b就解决了)
e ˉ = 1 n ∑ i = 1 n ( w x i − y i ) 2 = 1 n ∑ i = 1 n x i 2 w 2 − 2 n ∑ i = 1 n x i y i w + 1 n ∑ i = 1 n y i 2 x i , y i 都是已知的因此 : = a w 2 + b w + c = 10 w 2 − 15.9 w + 6.5 \begin{aligned} \bar e &=\frac{1}{n} \textstyle\sum_{i=1}^{n}(w x_{i}-y_{i})^{2}\\ &={\frac{1}{n}}\sum_{i=1}^{n}x_{i}^{2}w^{2}-{\frac{2}{n}}\sum_{i=1}^{n} x_{i}y_{i}w+{\frac{1}{n}}\sum_{i=1}^{n} y_{i}^{2}\\ &x_i,y_i都是已知的因此:\\ &= {a w^{2}+b w+c} \\ &= 10w^{2}-15.9w+6.5 \end{aligned} eˉ=n1∑i=1n(wxi−yi)2=n1i=1∑nxi2w2−n2i=1∑nxiyiw+n1i=1∑nyi2xi,yi都是已知的因此:=aw2+bw+c=10w2−15.9w+6.5
然后就简单了 算w在什么情况下损失函数的值最小(初中的抛物线求顶点的横坐标,高中求导数为0时)
求得w=0.795时损失函数取得最小值
那我们最终那个真理函数(最优解)就得到了
y = 0.795 x + 0 y=0.795x+0 y=0.795x+0
在这个求解的过程中,我们是假设了b=0的 学了多元方程求解后 这个b也是可以求解出来的,因为一元方程是一种特殊的多元方程
总结:
1.实际数据中 x和y组成的点 不一定是全部落在一条直线上
2.我们假设有这么一条直线 y = w x + b y=wx+b y=wx+b 是最符合描述这些点的
3.最符合的条件就是这个方程带入所有x计算出的所有y与真实的y值做 均方差计算
4.找到均方差最小的那个w
5.这样就求出了最优解的函数(前提条件是假设b=0)
4.多参数回归
上面案例中,实际情况下,影响这种植物高度的不仅仅有温度,还有海拔,湿度,光照等等因素:
实际情况下,往往影响结果y的因素不止1个,这时x就从一个变成了n个, x 1 , x 2 , x 3 . . . x n x_1,x_2,x_3...x_n x1,x2,x3...xn 上面的思路是对的,但是求解的公式就不再适用了
案例: 假设一个人健康程度怎么样,由很多因素组成
| 被爱 | 学习指数 | 抗压指数 | 运动指数 | 饮食情况 | 金钱 | 心态 | 压力 | 健康程度 |
|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 8 | 0 | 5 | -2 | 9 | -3 | 339 |
| -4 | 10 | 6 | 4 | -14 | -2 | -14 | 8 | -114 |
| -1 | -6 | 5 | -12 | 3 | -3 | 2 | -2 | 30 |
| 5 | -2 | 3 | 10 | 5 | 11 | 4 | -8 | 126 |
| -15 | -15 | -8 | -15 | 7 | -4 | -12 | 2 | -395 |
| 11 | -10 | -2 | 4 | 3 | -9 | -6 | 7 | -87 |
| -14 | 0 | 4 | -3 | 5 | 10 | 13 | 7 | 422 |
| -3 | -7 | -2 | -8 | 0 | -6 | -5 | -9 | -309 |
| 11 | 14 | 8 | 10 | 5 | 10 | 8 | 1 | ? |
求如果karen的各项指标是:
被爱:11 学习指数:14 抗压指数:8 运动指数:10 饮食水平:5 金钱:10 心态:8 压力:1
那么karen的健康程度是多少?
直接能想到的就是八元一次方程求解:
14 w 2 + 8 w 3 + 5 w 5 + − 2 w 6 + 9 w 7 + − 3 w 8 = 399 14w_2+8w_3+5w_5+-2w_6+9w_7+-3w_8=399 14w2+8w3+5w5+−2w6+9w7+−3w8=399
− 4 w 1 + 10 w 2 + 6 w 3 + 4 w 4 + − 14 w 5 + − 2 w 6 + − 14 w 7 + 8 w 8 = − 144 -4w_1+10w_2+6w_3+4w_4+-14w_5+-2w_6+-14w_7+8w_8=-144 −4w1+10w2+6w3+4w4+−14w5+−2w6+−14w7+8w8=−144
− 1 w 1 + − 6 w 2 + 5 w 3 + − 12 w 4 + 3 w 3 + − 3 w 6 + 2 w 7 + − 2 w 8 = 30 -1w_1+-6w_2+5w_3+-12w_4+3w_3+-3w_6+2w_7+-2w_8=30 −1w1+−6w2+5w3+−12w4+3w3+−3w6+2w7+−2w8=30
5 w 1 + − 2 w 2 + 3 w 3 + 10 w 4 + 5 w 5 + 11 w 6 + 4 w 7 + − 8 w 8 = 126 5w_1+-2w_2+3w_3+10w_4+5w_5+11w_6+4w_7+-8w_8=126 5w1+−2w2+3w3+10w4+5w5+11w6+4w7+−8w8=126
− 15 w 1 + − 15 w 2 + − 8 w 3 + − 15 w 4 + 7 w 5 + − 4 w 6 + − 12 w 7 + 2 w 8 = 126 -15w_1+-15w_2+-8w_3+-15w_4+7w_5+-4w_6+-12w_7+2w_8=126 −15w1+−15w2+−8w3+−15w4+7w5+−4w6+−12w7+2w8=126
11 w 1 + − 10 w 2 + − 2 w 3 + 4 w 4 + 3 w 5 + − 9 w 6 + − 6 w 7 + 7 w 8 = − 87 11w_1+-10w_2+-2w_3+4w_4+3w_5+-9w_6+-6w_7+7w_8=-87 11w1+−10w2+−2w3+4w4+3w5+−9w6+−6w7+7w8=−87
− 14 w 1 + 4 w 3 + − 3 w 4 + 5 w 5 + 10 w 6 + 13 w 7 + 7 w 8 = 422 -14w_1+4w_3+-3w_4+5w_5+10w_6+13w_7+7w_8=422 −14w1+4w3+−3w4+5w5+10w6+13w7+7w8=422
− 3 w 1 + − 7 w 2 + − 2 w 3 + − 8 w 4 + − 6 w 6 + − 5 w 7 + − 9 w 8 = − 309 -3w_1+-7w_2+-2w_3+-8w_4+-6w_6+-5w_7+-9w_8=-309 −3w1+−7w2+−2w3+−8w4+−6w6+−5w7+−9w8=−309
解出 权重 w ( w 1 , w 2 . . . w 8 ) w(w_1,w_2...w_8) w(w1,w2...w8) 然后带入即可求出karen的健康程度
权重即重要程度,某一项的权重越大说明它影响最终健康的程度越大
但是这有一个前提:这个八元一次方程组得有解才行
因此我们还是按照损失最小的思路来求权重 w ( w 1 , w 2 . . . w 8 ) w(w_1,w_2...w_8) w(w1,w2...w8)
多元线性回归:
y , = w 1 x 1 + w 2 x 2 + . . . . w n x n + b y^,=w_1x_1+w_2x_2+....w_nx_n+b y,=w1x1+w2x2+....wnxn+b
b是截距,我们也可以使用 w 0 w_0 w0来表示只要是个常量就行
y , = w 1 x 1 + w 2 x 2 + . . . . w n x n + w 0 y^,=w_1x_1+w_2x_2+....w_nx_n+w_0 y,=w1x1+w2x2+....wnxn+w0
y , = w 1 x 1 + w 2 x 2 + . . . . w n x n + w 0 ∗ 1 y^,=w_1x_1+w_2x_2+....w_nx_n+w_0*1 y,=w1x1+w2x2+....wnxn+w0∗1
那么损失函数就是
l o s s = [ ( y 1 − y 1 , ) 2 + ( y 2 − y 2 , ) 2 + . . . . ( y n − y n , ) 2 ] / n loss=[(y_1-y_1^,)^2+(y_2-y_2^,)^2+....(y_n-y_n^,)^2]/n loss=[(y1−y1,)2+(y2−y2,)2+....(yn−yn,)2]/n
如何求得对应的 W ( w 1 , w 2 . . w 0 ) W{(w_1,w_2..w_0)} W(w1,w2..w0) 使得loss最小呢?
数学家高斯给出了答案
5.最小二乘法MSE
| x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x0 | y |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 14 | 8 | 0 | 5 | -2 | 9 | -3 | 1 | 339 |
| -4 | 10 | 6 | 4 | -14 | -2 | -14 | 8 | 1 | -114 |
| -1 | -6 | 5 | -12 | 3 | -3 | 2 | -2 | 1 | 30 |
| 5 | -2 | 3 | 10 | 5 | 11 | 4 | -8 | 1 | 126 |
| -15 | -15 | -8 | -15 | 7 | -4 | -12 | 2 | 1 | -395 |
| 11 | -10 | -2 | 4 | 3 | -9 | -6 | 7 | 1 | -87 |
| -14 | 0 | 4 | -3 | 5 | 10 | 13 | 7 | 1 | 422 |
| -3 | -7 | -2 | -8 | 0 | -6 | -5 | -9 | 1 | -309 |
5.1前景知识: 矩阵相关公式

y = ( 339 − 114 30 126 − 395 − 87 422 − 309 ) y=\begin{pmatrix} 339&\\ -114&\\ 30&\\ 126&\\ -395&\\ -87&\\ 422&\\ -309 \\\end{pmatrix} y= 339−11430126−395−87422−309
X = X= X= ( 0 14 8 0 5 − 2 9 − 3 1 − 4 10 6 4 − 14 − 2 − 14 8 1 − 1 − 6 5 − 12 3 − 3 2 − 2 1 5 − 2 3 10 5 11 4 − 8 1 − 15 − 15 − 8 − 15 7 − 4 − 12 2 1 11 − 10 − 2 4 3 − 9 − 6 7 1 − 14 0 4 − 3 5 10 13 7 1 − 3 − 7 − 2 − 8 0 − 6 − 5 − 9 1 ) \begin{pmatrix} 0& 14& 8& 0& 5& -2& 9& -3&1 \\ -4& 10& 6& 4& -14& -2& -14& 8&1\\-1& -6& 5& -12& 3& -3& 2& -2&1\\5& -2& 3& 10& 5& 11& 4& -8&1\\-15& -15& -8& -15& 7& -4& -12& 2&1\\11& -10& -2& 4& 3& -9& -6& 7&1\\-14& 0& 4& -3& 5& 10& 13& 7&1\\-3& -7& -2& -8& 0& -6& -5& -9&1\end{pmatrix} 0−4−15−1511−14−31410−6−2−15−100−78653−8−24−204−1210−154−3−85−14357350−2−2−311−4−910−69−1424−12−613−5−38−2−8277−911111111
W = ( w 1 w 2 w 3 w 4 w 5 w 6 w 7 w 8 w 0 ) W=\begin{pmatrix} w_1&\\ w_2&\\ w_3&\\ w_4&\\ w_5&\\ w_6&\\ w_7&\\ w_8&\\w_0\end{pmatrix} W= w1w2w3w4w5w6w7w8w0
5.2最小二乘法
h ( x ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + w 4 x 4 + w 5 x 5 + w 6 x 6 + w 7 x 7 + w 8 x 8 + w 0 x 0 h(x)=w_1x_1+w_2x_2+w_3x_3+w_4x_4+w_5x_5+w_6x_6+w_7x_7+w_8x_8+w_0x_0 h(x)=w1x1+w2x2+w3x3+w4x4+w5x5+w6x6+w7x7+w8x8+w0x0
l o s s = [ ( h 1 ( x ) − y 1 ) 2 + ( h 2 ( x ) − y 2 ) 2 + . . . ( h n ( x ) − y n ) 2 ] / n = 1 n ∑ i = 1 n ( h ( x i ) − y i ) 2 = 1 n ∣ ∣ ( X W − y ) ∣ ∣ 2 = 1 2 ∣ ∣ ( X W − y ) ∣ ∣ 2 这就是传说中的最小二乘法公式 ∣ ∣ A ∣ ∣ 2 是欧几里得范数的平方 也就是每个元素的平方相加 loss=[(h_1(x)-y_1)^2+(h_2(x)-y_2)^2+...(h_n(x)-y_n)^2]/n\\=\frac{1}{n} \textstyle\sum_{i=1}^{n}(h(x_{i})-y_{i})^{2}\\=\frac{1}{n}||(XW-y)||^2\\=\frac{1}{2}||(XW-y)||^2 这就是传说中的最小二乘法公式 \\ ||A||^2 是欧几里得范数的平方\,也就是每个元素的平方相加 loss=[(h1(x)−y1)2+(h2(x)−y2)2+...(hn(x)−yn)2]/n=n1∑i=1n(h(xi)−yi)2=n1∣∣(XW−y)∣∣2=21∣∣(XW−y)∣∣2这就是传说中的最小二乘法公式∣∣A∣∣2是欧几里得范数的平方也就是每个元素的平方相加
虽然这个案例中n=8,但是常常令n=2,因为是一个常数 求最小值时n随便取哪个正数都不会影响W结果,但是求导过程可以约掉前面的系数,会加速后面的计算
h ( x 1 ) 表示 y 1 , = X 第 1 行分别和 W 相乘 h(x_1)表示y^,_1= X第1行分别和W相乘 h(x1)表示y1,=X第1行分别和W相乘
h ( x 2 ) 表示 y 2 , = X 第 2 行分别和 W 相乘 h(x_2)表示y^,_2= X第2行分别和W相乘 h(x2)表示y2,=X第2行分别和W相乘
…
高斯把公式给了,但是何时loss最小呢?
1.二次方程导数为0时最小
l o s s = 1 2 ∣ ∣ ( X W − y ) ∣ ∣ 2 求导 : loss=\frac{1}{2}||(XW-y)||^2 求导: loss=21∣∣(XW−y)∣∣2求导:
2.先展开矩阵乘法
l o s s = 1 2 ( X W − y ) T ( X W − y ) loss=\frac{1}{2}(XW-y)^T(XW-y) loss=21(XW−y)T(XW−y)
l o s s = 1 2 ( W T X T − y T ) ( X W − y ) loss=\frac{1}{2}(W^TX^T-y^T)(XW-y) loss=21(WTXT−yT)(XW−y)
l o s s = 1 2 ( W T X T X W − W T X T y − y T X W + y T y ) loss=\frac{1}{2}(W^TX^TXW-W^TX^Ty-y^TXW+y^Ty) loss=21(WTXTXW−WTXTy−yTXW+yTy)
3.进行求导(注意X,y都是已知的,W是未知的)
l o s s ′ = 1 2 ( W T X T X W − W T X T y − y T X W + y T y ) ′ loss'=\frac{1}{2}(W^TX^TXW-W^TX^Ty-y^TXW+y^Ty)' loss′=21(WTXTXW−WTXTy−yTXW+yTy)′
l o s s ′ = 1 2 ( X T X W + ( W T X T X ) T − X T y − ( y T X ) T ) loss'=\frac{1}{2}(X^TXW+(W^TX^TX)^T-X^Ty-(y^TX)^T) loss′=21(XTXW+(WTXTX)T−XTy−(yTX)T)
l o s s ′ = 1 2 ( X T X W + X T X W − X T y − X T y ) loss'=\frac{1}{2}(X^TXW+X^TXW-X^Ty-X^Ty) loss′=21(XTXW+XTXW−XTy−XTy)
l o s s ′ = 1 2 ( 2 X T X W − 2 X T y ) loss'=\frac{1}{2}(2X^TXW-2X^Ty) loss′=21(2XTXW−2XTy)
l o s s ′ = X T X W − X T y loss'=X^TXW-X^Ty loss′=XTXW−XTy
4.令导数 l o s s ′ = 0 loss'=0 loss′=0
0 = X T X W − X T y 0=X^TXW-X^Ty 0=XTXW−XTy
X T X W = X T y X^TXW=X^Ty XTXW=XTy
5.矩阵没有除法,使用逆矩阵转化
( X T X ) − 1 ( X T X ) W = ( X T X ) − 1 X T y (X^TX)^{-1}(X^TX)W=(X^TX)^{-1}X^Ty (XTX)−1(XTX)W=(XTX)−1XTy
W = ( X T X ) − 1 X T y W=(X^TX)^{-1}X^Ty W=(XTX)−1XTy
第二种方式链式求导(推荐,因为后期深度学习全是这种):
内部函数是$ f(W) = XW - y $,外部函数是 $ g(u) = \frac{1}{2} u^2 $,其中 $ u = f(W) $。
外部函数的导数:$ \frac{\partial g}{\partial u} = u = XW - y $
内部函数的导数:$ \frac{\partial f}{\partial W} = X^T $
应用链式法则,我们得到最终的梯度:$ \frac{\partial L}{\partial W} = \left( \frac{\partial g}{\partial u} \right) \left( \frac{\partial f}{\partial W} \right) = (XW - y) X^T $
有了W,回到最初的问题:
求如果karen的各项指标是:
被爱:11 学习指数:14 抗压指数:8 运动指数:10 饮食水平:5 金钱:10 权利:8 压力:1
那么karen的健康程度是多少?
分别用W各项乘以新的X 就可以得到y健康程度
5.3 API
sklearn.linear_model.LinearRegression()
功能: 普通最小二乘法线性回归, 权重和偏置是直接算出来的,对于数量大的不适用,因为计算量太大,计算量太大的适合使用递度下降法参数:
fit_intercept bool, default=True是否计算此模型的截距(偏置)。如果设置为False,则在计算中将不使用截距(即,数据应中心化)。
属性:
coef_ 回归后的权重系数
intercept_ 偏置print("权重系数为:\n", estimator.coef_) #权重系数与特征数一定是同样的个数。
print("偏置为:\n", estimator.intercept_)5.4 示例代码
from sklearn.linear_model import LinearRegression
import numpy as np
data=np.array([[0,14,8,0,5,-2,9,-3,399],[-4,10,6,4,-14,-2,-14,8,-144],[-1,-6,5,-12,3,-3,2,-2,30],[5,-2,3,10,5,11,4,-8,126],[-15,-15,-8,-15,7,-4,-12,2,-395],[11,-10,-2,4,3,-9,-6,7,-87],[-14,0,4,-3,5,10,13,7,422],[-3,-7,-2,-8,0,-6,-5,-9,-309]])
x=data[:,0:8]
y=data[:,8:]
estimator=LinearRegression(fit_intercept=False)
estimator.fit(x,y)
print("权重系数为:\n", estimator.coef_) #权重系数与特征数一定是同样的个数。
print("偏置为:\n", estimator.intercept_)
x_new=[[11,14,8,10,5,10,8,1]]
y_predict=estimator.predict(x)
print("预测结果:\n",y_predict)
print(-3*0.4243965-7*7.32281732-2*15.05217218-8*3.5996297+0*12.05805264-6*1.76972959-5*17.0276393-9*11.31212591)
权重系数为:[[ 0.4243965 7.32281732 15.05217218 3.5996297 12.05805264 1.7697295917.0276393 11.31212591]]
偏置为:0.0
预测结果:[[ 399.][-144.][ 30.][ 126.][-395.][ -87.][ 422.][-309.]]
-308.99999993
6.梯度下降
6.1梯度下降概念
正规方程求解的缺点
之前利用正规方程求解的W是最优解的原因是MSE这个损失函数是凸函数。但是,机器学习的损失函数并非都是凸函数,设置导数为0会得到很多个极值,不能确定唯一解,MSE还有一个问题,当数据量和特征较多时,矩阵计算量太大.
1.假设损失函数是这样的,利用正规方程求解导数为0会得到很多个极值,不能确定唯一解

2.使用正规方程 W = ( X T X ) − 1 X T y W=(X^TX)^{-1}X^Ty W=(XTX)−1XTy 求解要求X的特征维度 ( x 1 , x 2 , x 3 . . . ) (x_1,x_2,x_3...) (x1,x2,x3...) 不能太多,逆矩阵运算时间复杂度为 O ( n 3 ) O(n^3) O(n3) , 也就是说如果特征x的数量翻倍,计算时间就是原来的 2 3 2^3 23倍,8倍太恐怖了,假设2个特征1秒,4个特征8秒,8个特征64秒,16个特征512秒,而往往现实生活中的特征非常多,尤其是大模型,运行时间太长了
所以 正规方程求出最优解并不是机器学习和深度学习常用的手段,梯度下降算法更常用
什么是梯度下降

假设你在一个陌生星球的山地上,你想找到一个谷底,那么肯定是想沿着向下的坡行走,如果想尽快的走到谷底,那么肯定是要沿着最陡峭的坡下山。每走一步,都找到这里位置最陡峭的下坡走下一步,这就是梯度下降。
在这个比喻中,梯度就像是山上的坡度,告诉我们在当前位置上地势变化最快的方向。为了尽快走向谷底,我们需要沿着最陡峭的坡向下行走,而梯度下降算法正是这样的方法。
每走一步,我们都找到当前位置最陡峭的下坡方向,然后朝着该方向迈进一小步。这样,我们就在梯度的指引下逐步向着谷底走去,直到到达谷底(局部或全局最优点)。
在机器学习中,梯度表示损失函数对于模型参数的偏导数。具体来说,对于每个可训练参数,梯度告诉我们在当前参数值下,沿着每个参数方向变化时,损失函数的变化率。通过计算损失函数对参数的梯度,梯度下降算法能够根据梯度的信息来调整参数,朝着减少损失的方向更新模型,从而逐步优化模型,使得模型性能更好。
在 e ˉ = 1 n ∑ i = 1 n x i 2 w 2 − 2 n ∑ i = 1 n x i y i w + 1 n ∑ i = 1 n y i 2 \bar e={\frac{1}{n}}\sum_{i=1}^{n}x_{i}^{2}w^{2}-{\frac{2}{n}}\sum_{i=1}^{n} x_{i}y_{i}w+{\frac{1}{n}}\sum_{i=1}^{n} y_{i}^{2} eˉ=n1∑i=1nxi2w2−n2∑i=1nxiyiw+n1∑i=1nyi2 这个一元二次方程中,损失函数对于参数 w 的梯度就是关于 w 点的切线斜率。梯度下降算法会根据该斜率的信息来调整参数 w,使得损失函数逐步减小,从而找到使得损失最小化的参数值,优化模型的性能。
梯度下降法(Gradient Descent)是一个算法,但不是像多元线性回归那样是一个具体做回归任务的算法,而是一个非常通用的优化算法来帮助一些机器学习算法求解出最优解,所谓的通用就是很多机器学习算法都是用梯度下降,甚至深度学习也是用它来求解最优解。
所有优化算法的目的都是期望以最快的速度把模型参数W求解出来,梯度下降法就是一种经典常用的优化算法。
6.5梯度下降步骤

梯度下降流程就是“猜"正确答案的过程:
1、Random随机数生成初始W,随机生成一组成正太分布的数值 w 0 , w 1 , w 2 . . . . w n w_0,w_1,w_2....w_n w0,w1,w2....wn,这个随机是成正太分布的(高斯说的)
2、求梯度g,梯度代表曲线某点上的切线的斜率,沿着切线往下就相当于沿着坡度最陡峭的方向下降.
3、if g < 0,w变大,if g >0,w变小(目标左边是斜率为负右边为正 )
4、判断是否收敛,如果收敛跳出迭代,如果没有达到收敛,回第2步再次执行2~4步收敛的判断标准是:随着迭代进行查看损失函数Loss的值,变化非常微小甚至不再改变,即认为达到收敛
5.上面第4步也可以固定迭代次数
6.2梯度下降公式


随机给一个w初始值,然后就不停的修改它,直到达到抛物线最下面附近,比如
w=0.2
w=w-0.01*w为0.2时的梯度(导数) 假设算出来是 0.24
w=w-0.01*w为0.24时的梯度(导数) 假设算出来是 0.33
w=w-0.01*w为0.33时的梯度(导数) 假设算出来是 0.51
w=w-0.01*w为0.51时的梯度(导数) 假设算出来是 0.56
w=w-0.01*w为0.56时的梯度(导数) 假设算出来是 0.58
w=w-0.01*w为0.58时的梯度(导数) 假设算出来是 0.62
就这样一直更新下去,会在真实值附近,我们可以控制更新的次数
关于随机的w在左边和右边问题:
因为导数有正负
如果在左边 导数是负数 减去负数就是加 往右移动
如果在右边 导数是正数 减去正数就是减 往左移动
6.3学习率
根据我们上面讲的梯度下降公式,我们知道α是学习率,设置大的学习率α;每次调整的幅度就大,设置小的学习率α;每次调整的幅度就小,然而如果步子迈的太大也会有问题! 学习率大,可能一下子迈过了,到另一边去了(从曲线左半边跳到右半边),继续梯度下降又迈回来,使得来来回回震荡。步子太小呢,就像蜗牛一步步往前挪,也会使得整体迭代次数增加。

学习率的设置是门一门学问,一般我们会把它设置成一个小数,0.1、0.01、0.001、0.0001,都是常见的设定数值(然后根据情况调整)。一般情况下学习率在整体迭代过程中是不变,但是也可以设置成随着迭代次数增多学习率逐渐变小,因为越靠近山谷我们就可以步子迈小点,可以更精准的走入最低点,同时防止走过。还有一些深度学习的优化算法会自己控制调整学习率这个值
6.4自己实现梯度下降
我们自己用代码亲自实现一遍梯度下降,之后使用API时就明白它底层的核心实现过程了.
1.假设损失函数是只有一个 w 1 w_1 w1特征的抛物线:
l o s s ( w 1 ) = ( w 1 − 3.5 ) 2 − 4.5 w 1 + 10 loss(w_1)=(w_1-3.5)^2-4.5w_1+10 loss(w1)=(w1−3.5)2−4.5w1+10

我们要求解这个抛物线最小值时的横坐标 w 1 w_1 w1的值
#1.列损失函数 画出函数图像
loss=lambda w_1:(w_1-3.5)**2-4.5*w_1+10
w_1=np.linspace(0,11.5,100)
plt.plot(w_1,loss(w_1))
#2.求这个损失函数的最小值:梯度下降
def cb():g=lambda w_1:2*(w_1-3.5)-4.5#导函数t0,t1=1,100 alpha=t0/t1#学习率,设置大和过大会导致震荡或者无法收敛w_1=np.random.randint(0,10,size=1)[0]#随机初始值#控制更新次数for i in range(1000):alpha=t0/(i+t1)#控制学习率 逐步变小w_1=w_1-alpha*g(w_1)#梯度下降公式print("更新后的w_1:",w_1)
cb()
2.假设损失函数是有两个 w 1 , w 2 w_1,w_2 w1,w2特征的椎体(我画不来 假装下面是个椎体)
l o s s ( w 1 , w 2 ) = ( w 1 − 3.5 ) 2 + ( w 2 − 2 ) 2 + 3 w 1 w 2 − 4.5 w 1 + 2 w 2 + 20 loss(w_1,w_2)=(w_1-3.5)^2+(w_2-2)^2+3w_1w_2-4.5w_1+2w_2+20 loss(w1,w2)=(w1−3.5)2+(w2−2)2+3w1w2−4.5w1+2w2+20

上一个案例:一个 w 1 w_1 w1更新梯度时是抛物线对于 w 1 w_1 w1 求导然后更新 w 1 w_1 w1
这个案例是:两个 w 1 , w 2 w_1,w_2 w1,w2,那么我们再分别更新 w 1 , w 2 w_1,w_2 w1,w2时 就是对于另一个求偏导
比如随机初始: w 1 = 10 , w 2 = 40 w_1=10,w_2=40 w1=10,w2=40
第一次更新时:
w 1 新 = 10 − 学习率 ∗ 把 w 2 = 40 带入求 w 1 的导数 w_1新 = 10-学习率*把w_2=40带入求w_1的导数 w1新=10−学习率∗把w2=40带入求w1的导数
w 2 新 = 40 − 学习率 ∗ 把 w 1 = 10 带入求 w 2 的导数 w_2新 = 40-学习率*把w_1=10带入求w_2的导数 w2新=40−学习率∗把w1=10带入求w2的导数
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
#1.列损失函数 画出函数图像
loss=lambda w_1,w_2:(w_1-3.5)**2+(w_2-2)**2+2*w_2-4.5*w_1+3*w_1*w_2+20
#2.求这个损失函数的最小值:梯度下降
def cb2():t0,t1=1,100 alpha=t0/t1#学习率,设置大和过大会导致震荡或者无法收敛w_1=10#np.random.randint(0,100,size=1)[0]#随机初始值w_2=40#np.random.randint(0,100,size=1)[0]#随机初始值dw_1=lambda w_1,w_2:2*(w_1-3.5)+3*w_2-4.5#w_1的导函数dw_2=lambda w_1,w_2:3*w_1+2*w_2-2#w_2的导函数#控制更新次数for i in range(100):alpha=t0/(i+t1)#控制学习率 逐步变小w_1_=w_1#保存起来 防止梯度下降过程中w_1和w_2的值发生改变w_2_=w_2#w_1=w_1-alpha*dw_1(w_1_,w_2_)#梯度下降公式w_2=w_2-alpha*dw_2(w_1_,w_2_)print("更新后的w_1,w_2:",w_1,w_2)
cb2()
至此我们已经实现了BGD批量梯度下降
3.假设损失函数是有多个 w 1 , w 2 . . . . w_1,w_2.... w1,w2....特征的超平面
这时候我们也可以自己写 但是学到这里 知道原理以后 该上API了
6.5 sklearn梯度下降
官方的梯度下降API常用有三种:
批量梯度下降BGD(Batch Gradient Descent)
小批量梯度下降MBGD(Mini-BatchGradient Descent)
随机梯度下降SGD(Stochastic Gradient Descent)。

三种梯度下降有什么不同呢?
- Batch Gradient Descent (BGD): 在这种情况下,每一次迭代都会使用全部的训练样本计算梯度来更新权重。这意味着每一步梯度更新都是基于整个数据集的平均梯度。这种方法的优点是每次更新的方向是最准确的,但缺点是计算量大且速度慢,尤其是在大数据集上。
- Mini-Batch Gradient Descent (MBGD): 这种方法介于批量梯度下降和随机梯度下降之间。它不是用全部样本也不是只用一个样本,而是每次迭代从数据集中随机抽取一小部分样本(例如,从500个样本中选取32个),然后基于这一小批样本的平均梯度来更新权重。这种方法在准确性和计算效率之间取得了一个平衡。
- Stochastic Gradient Descent (SGD): 在随机梯度下降中,每次迭代仅使用随机单个样本(或有时称为“例子”)来计算梯度并更新权重。这种方法能够更快地收敛,但由于每次更新都基于单个样本,所以会导致权重更新路径不稳定。
6.6批量梯度下降BGD
批量梯度下降是一种用于机器学习和深度学习中的优化算法,它用于最小化损失函数(目标函数)。批量梯度下降使用整个训练数据集来计算梯度并更新模型参数。
原理
批量梯度下降的基本思想是在每个迭代步骤中使用所有训练样本来计算损失函数的梯度,并据此更新模型参数。这使得更新方向更加准确,因为它是基于整个数据集的梯度,而不是像随机梯度下降那样仅基于单个样本。
更新规则
假设我们有一个包含 ( m ) 个训练样本的数据集 { ( x ( i ) , y ( i ) ) } i = 1 m \{(x^{(i)}, y^{(i)})\}_{i=1}^{m} {(x(i),y(i))}i=1m,其中 $ x^{(i)} 是输入特征, 是输入特征, 是输入特征, y^{(i)} $ 是对应的标签。我们的目标是最小化损失函数 $J(\theta) $ 相对于模型参数 $ \theta $ 的值。
损失函数可以定义为:
$ J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y{(i)})2 $
其中 $ h_\theta(x^{(i)}) $ 是模型对第 $ i $ 个样本的预测输出。
批量梯度下降的更新规则为:
$ \theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)} $
对于 $ j = 0, 1, \ldots, n $ (其中 $n $ 是特征的数量),并且 $ \alpha $ 是学习率。
特点
- 准确性:由于使用了所有训练样本,所以得到的梯度是最准确的,这有助于找到全局最小值。
- 计算成本:每次更新都需要遍历整个数据集,因此计算量较大,特别是在数据集很大的情况下。
- 收敛速度:虽然每一步的更新都是准确的,但由于计算成本较高,实际收敛到最小值的速度可能不如其他方法快。
- 内存需求:需要在内存中存储整个数据集,对于大型数据集来说可能成为一个问题。
使用场景
- 小数据集:当数据集较小时,批量梯度下降是一个不错的选择,因为它能保证较好的收敛性和准确性。
- 不需要实时更新:如果模型不需要实时更新,例如在离线训练场景下,批量梯度下降是一个合理的选择。
实现注意事项
- 选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
- 数据预处理:对数据进行标准化或归一化,可以提高批量梯度下降的效率。
- 监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
API
批量梯度下降通常不是首选方法,因为它在大数据集上的计算成本较高。如果你确实需要批量梯度下降,那么可以考虑自己实现。
6.7随机梯度下降SGD
随机梯度下降(Stochastic Gradient Descent, SGD)是一种常用的优化算法,在机器学习和深度学习领域中广泛应用。与批量梯度下降(BGD)和小批量梯度下降(MBGD)相比,SGD 每一步更新参数时仅使用单个训练样本,这使得它更加灵活且计算效率更高,特别是在处理大规模数据集时。
基本步骤
-
初始化参数:
- 选择一个初始点作为参数向量 θ \theta θ的初始值。
-
选择样本:
- 随机选取一个训练样本$ (x^{(i)}, y^{(i)})$。
-
计算梯度:
- 使用所选样本 ( x ( i ) , y ( i ) ) (x^{(i)}, y^{(i)}) (x(i),y(i))来近似计算损失函数 $J(\theta) $的梯度 ∇ J ( θ ) \nabla J(\theta) ∇J(θ)。
-
更新参数:
- 根据梯度的方向来更新参数 θ \theta θ。更新公式为:
θ : = θ − α ⋅ ∇ J ( θ ) \theta := \theta - \alpha \cdot \nabla J(\theta) θ:=θ−α⋅∇J(θ) - 其中 α \alpha α 是学习率,决定了每次迭代时参数更新的步长。
- 根据梯度的方向来更新参数 θ \theta θ。更新公式为:
-
重复步骤 2 到 4:
- 对所有的训练样本重复此过程,直到完成一个完整的 epoch(即所有样本都被访问过一次)。
-
重复多个 epoch:
- 重复上述过程,直到满足某个停止条件,比如达到最大迭代次数或者梯度足够小。
-
输出结果:
- 输出最小化损失函数后的最优参数 θ ∗ \theta^* θ∗。
数学公式
假设我们有一个包含 (m) 个样本的数据集 { ( x ( i ) , y ( i ) ) } i = 1 m \{(x^{(i)}, y^{(i)})\}_{i=1}^m {(x(i),y(i))}i=1m,其中 x ( i ) x^{(i)} x(i) 是第 i i i 个样本的特征向量, y ( i ) y^{(i)} y(i) 是对应的标签。对于线性回归问题,损失函数 J ( θ ) J(\theta) J(θ) 可以定义为均方误差 (Mean Squared Error, MSE):
J ( θ ) = 1 2 ( h θ ( x ( i ) ) − y ( i ) ) 2 J(\theta) = \frac{1}{2}(h_\theta(x^{(i)}) - y^{(i)})^2 J(θ)=21(hθ(x(i))−y(i))2
其中 h θ ( x ( i ) ) = θ T x ( i ) h_\theta(x^{(i)}) = \theta^T x^{(i)} hθ(x(i))=θTx(i)是模型对第 i i i个样本的预测值。
梯度 ∇ J ( θ ) \nabla J(\theta) ∇J(θ) 对于每个参数 θ j \theta_j θj 的偏导数可以表示为:
∂ J ( θ ) ∂ θ j = ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial J(\theta)}{\partial \theta_j} = (h_\theta(x^{(i)}) - y^{(i)})x_j^{(i)} ∂θj∂J(θ)=(hθ(x(i))−y(i))xj(i)
更新规则
参数 θ \theta θ 的更新规则为:
θ j : = θ j − α ⋅ ∂ J ( θ ) ∂ θ j \theta_j := \theta_j - \alpha \cdot \frac{\partial J(\theta)}{\partial \theta_j} θj:=θj−α⋅∂θj∂J(θ)
注意事项
- 学习率 α \alpha α: 需要适当设置,太大会导致算法不收敛,太小则收敛速度慢。
- 随机性: 每次迭代都从训练集中随机选择一个样本,这有助于避免陷入局部最小值。
- 停止条件: 可以是达到预定的最大迭代次数,或者梯度的范数小于某个阈值。
随机梯度下降的一个关键优势在于它能够快速地进行迭代并适应较大的数据集。然而,由于每次只使用一个样本进行更新,梯度估计可能较为嘈杂,这可能导致更新过程中出现较大的波动。在实际应用中,可以通过减少学习率(例如采用学习率衰减策略)来解决这个问题。
API
sklearn.linear_model.SGDRegressor()
功能:梯度下降法线性回归
参数:loss: 损失函数,默认为 ’squared_error’fit_intercept: 是否计算偏置, default=Trueeta0: float, default=0.01学习率初始值learning_rate: str, default=’invscaling’ The learning rate schedule:‘constant’: eta = eta0 学习率为eta0设置的值,保持不变‘optimal’: eta = 1.0 / (alpha * (t + t0)) ‘invscaling’: eta = eta0 / pow(t, power_t)‘adaptive’: eta = eta0, 学习率由eta0开始,逐步变小max_iter: int, default=1000 经过训练数据的最大次数(又名epoch)shuffle=True 每批次是否洗牌penalty: {‘l2’, ‘l1’, ‘elasticnet’, None}, default=’l2’要使用的惩罚(又称正则化项)。默认为' l2 ',这是线性SVM模型的标准正则化器。' l1 '和' elasticnet '可能会给模型(特征选择)带来' l2 '无法实现的稀疏性。当设置为None时,不添加惩罚。
属性:
coef_ 回归后的权重系数
intercept_ 偏置
案例:
加载加利福尼亚住房数据集,进行回归预测, 注意网络
# 线性回归 加载加利福尼亚住房数据集,进行回归预测
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.metrics import mean_squared_errorfrom sklearn.datasets import fetch_california_housing
# 1)加载数据
housing = fetch_california_housing(data_home="./src")
print(housing)
# 2)划分训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(housing.data, housing.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)线性回归预估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=1000, penalty="l1",loss="squared_error")estimator.fit(x_train, y_train)# 5)得出模型
print("权重系数为:\n", estimator.coef_) #权重系数与特征数一定是同样的个数。
print("偏置为:\n", estimator.intercept_)# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测的数据集:\n", y_predict)
print("得分:\n",estimator.score(x_test, y_test))
error = mean_squared_error(y_test, y_predict)
print("均方误差为:\n", error)
6.8小批量梯度下降MBGD
小批量梯度下降是一种介于批量梯度下降(BGD)与随机梯度下降(SGD)之间的优化算法,它结合了两者的优点,在机器学习和深度学习中被广泛使用。
原理
小批量梯度下降的基本思想是在每个迭代步骤中使用一小部分(即“小批量”)训练样本来计算损失函数的梯度,并据此更新模型参数。这样做的好处在于能够减少计算资源的需求,同时保持一定程度的梯度准确性。
更新规则
假设我们有一个包含 ( m ) 个训练样本的数据集 { ( x ( i ) , y ( i ) ) } i = 1 m \{(x^{(i)}, y^{(i)})\}_{i=1}^{m} {(x(i),y(i))}i=1m,其中 $ x^{(i)} $ 是输入特征,$y^{(i)} $ 是对应的标签。我们将数据集划分为多个小批量,每个小批量包含 ( b ) 个样本,其中 ( b ) 称为批量大小(batch size),通常 ( b ) 远小于 ( m )。
损失函数可以定义为:
$ J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^{(i)}) - y{(i)})2 $
其中 $ h_\theta(x^{(i)}) $ 是模型对第 $ i $ 个样本的预测输出。
小批量梯度下降的更新规则为:
$ \theta_j := \theta_j - \alpha \frac{1}{b} \sum_{i \in B} (h_\theta(x^{(i)}) - y^{(i)}) \cdot x_j^{(i)} $
对于 $ j = 0, 1, \ldots, n $ (其中 $n $是特征的数量),并且 $ \alpha $ 是学习率,$ B $ 表示当前小批量中的样本索引集合。
特点
- 计算效率:相比于批量梯度下降,小批量梯度下降每次更新只需要处理一部分数据,减少了计算成本。
- 梯度估计:相比于随机梯度下降,小批量梯度下降提供了更准确的梯度估计,这有助于更稳定地接近最小值。
- 内存需求:相比批量梯度下降,小批量梯度下降降低了内存需求,但仍然比随机梯度下降要高。
- 收敛速度与稳定性:小批量梯度下降能够在保持较快的收敛速度的同时,维持相对较高的稳定性。
使用场景
- 中等规模数据集:当数据集大小适中时,小批量梯度下降是一个很好的折衷方案,既能够高效处理数据,又能够保持良好的收敛性。
- 在线学习:在数据流式到达的场景下,小批量梯度下降可以有效地处理新到来的数据批次。
- 分布式环境:在分布式计算环境中,小批量梯度下降可以更容易地在多台机器上并行执行。
实现注意事项
- 选择合适的批量大小:批量大小的选择对性能有很大影响。较大的批量可以减少迭代次数,但计算成本增加;较小的批量则相反。
- 选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
- 数据预处理:对数据进行标准化或归一化,可以提高小批量梯度下降的效率。
- 监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
API
还是使用sklearn.linear_model.SGDRegressor()
只是训练时我们分批次地训练模型,调用partial_fit函数训练会直接更新权重,而不需要调fit从头开始训练。通常情况下,我们会将数据分成多个小批量,然后对每个小批量进行训练。
案例
# 线性回归 加载加利福尼亚住房数据集,进行回归预测
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.metrics import mean_squared_errorfrom sklearn.datasets import fetch_california_housing
# 1)加载数据
housing = fetch_california_housing(data_home="./src")
print(housing)
# 2)划分训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(housing.data, housing.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)线性回归预估器
estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=1000,shuffle=True, penalty="l1")
# 小批量梯度下降
batch_size = 50 # 批量大小
n_batches = len(x_train) // batch_size # 批次数量
for epoch in range(estimator.max_iter):indices = np.random.permutation(len(x_train)) # 随机打乱样本顺序for i in range(n_batches):start_idx = i * batch_sizeend_idx = (i + 1) * batch_sizebatch_indices = indices[start_idx:end_idx]X_batch = x_train[batch_indices]y_batch = y_train[batch_indices]estimator.partial_fit(X_batch, y_batch) # 更新模型权重# 5)得出模型
print("权重系数为:\n", estimator.coef_) #权重系数与特征数一定是同样的个数。
print("偏置为:\n", estimator.intercept_)# 6)模型评估
y_predict = estimator.predict(x_test)
print("得分:\n",estimator.score(x_test, y_test))
print("预测的数据集:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("均方误差为:\n", error)
6.9梯度下降优化
1.标准化
前期数据的预处理,之前讲的
2.正则化
防止过拟合
7.欠拟合过拟合


7.1欠拟合
欠拟合是指模型在训练数据上表现不佳,同时在新的未见过的数据上也表现不佳。这通常发生在模型过于简单,无法捕捉数据中的复杂模式时。欠拟合模型的表现特征如下:
- 训练误差较高。
- 测试误差同样较高。
- 模型可能过于简化,不能充分学习训练数据中的模式。
7.2过拟合
过拟合是指模型在训练数据上表现得非常好,但在新的未见过的数据上表现较差。这通常发生在模型过于复杂,以至于它不仅学习了数据中的真实模式,还学习了噪声和异常值。过拟合模型的表现特征如下:
-
训练误差非常低。
-
测试误差较高。
-
模型可能过于复杂,以至于它对训练数据进行了过度拟合。
7.3正则化
正则化就是防止过拟合,增加模型的鲁棒性,鲁棒是Robust 的音译,也就是强壮的意思。就像计算机软件在面临攻击、网络过载等情况下能够不死机不崩溃,这就是软件的鲁棒性,鲁棒性调优就是让模型拥有更好的鲁棒
性,也就是让模型的泛化能力和推广能力更加的强大。
比如,下面两个方程描述同一条直线,哪个更好?
y = 0.5 x 1 + 0.6 x 2 + 0.7 y=0.5x_1+0.6x_2+0.7 y=0.5x1+0.6x2+0.7
y = 5 x 1 + 6 x 2 + 7 y=5x_1+6x_2+7 y=5x1+6x2+7
第一个更好,因为下面的公式是上面的十倍,当w越小公式的容错的能力就越好。我们都知道人工智能中回归是有误差的,为了把误差降低而拟合出来的一个接近真实的公式,比如把一个测试数据[10,20]带入计算得到的值跟真实值会存在一定的误差,但是第二个方程会把误差放大,公式中 y = W T x y = W^Tx y=WTx,当 x x x有一点错误,这个错误会通过w放大。但是w不能太小,当w太小时(比如都趋近0),模型就没有意义了,无法应用。想要有一定的容错率又要保证正确率就要由正则项来发挥作用了!
所以**正则化(鲁棒性调优)**的本质就是牺牲模型在训练集上的正确率来提高推广、泛化能力,W在数值上越小越好,这样能抵抗数值的扰动。同时为了保证模型的正确率W又不能极小。因此将原来的损失函数加上一个惩罚项使得计算出来的模型W相对小一些,就是正则化。这里面损失函数就是原来固有的损失函数,比如回归的话通常是MSE,然后在加上一部分惩罚项来使得计算出来的模型W相对小一些来带来泛化能力。
常用的惩罚项有L1正则项或者L2正则项:
L 1 = ∣ ∣ w ∣ ∣ 1 = ∑ i = 1 n ∣ w i ∣ L1=||w||_1=\textstyle\sum_{i=1}^{n}|w_i| L1=∣∣w∣∣1=∑i=1n∣wi∣ 对应曼哈顿距离
L 2 = ∣ ∣ w ∣ ∣ 2 = ∑ i = 1 n x i p , X = ( x 1 , x 2 , . . . x n ) p L2=||w||_2=\textstyle\sqrt[p]{\sum_{i=1}^{n}x^p_i,X=(x_1,x_2,...x_n)} L2=∣∣w∣∣2=p∑i=1nxip,X=(x1,x2,...xn) 对应欧氏距离
其实 L 1 L1 L1 和 L 2 L2 L2 正则的公式在数学里面的意义就是范数,代表空间中向量到原点的距离
当我们把多元线性回归损失函数加上 L 2 L2 L2正则的时候,就诞生了Ridge岭回归。当我们把多元线性回归损失函数加上 L 1 L1 L1正则的时候,就孕育出来了Lasso回归。其实 L 1 L1 L1和 L 2 L2 L2正则项惩罚项可以加到任何算法的损失函数上面去提高计算出来模型的泛化能力的。
8.岭回归Ridge
8.1 损失函数公式
岭回归是失损函数通过添加所有权重的平方和的乘积(L2)来惩罚模型的复杂度。

均方差除以2是因为方便求导, w j w_j wj指所有的权重系数, λ指惩罚型系数,又叫正则项力度
特点:
- 岭回归不会将权重压缩到零,这意味着所有特征都会保留在模型中,但它们的权重会被缩小。
- 适用于特征间存在多重共线性的情况。
- 岭回归产生的模型通常更为平滑,因为它对所有特征都有影响。
8.2 API
具有L2正则化的线性回归-岭回归。
sklearn.linear_model.Ridge()
1 参数:
(1)alpha, default=1.0,正则项力度
(2)fit_intercept, 是否计算偏置, default=True
(3)solver, {‘auto’, ‘svd’, ‘cholesky’, ‘lsqr’, ‘sparse_cg’, ‘sag’, ‘saga’, ‘lbfgs’}, default=’auto’
当值为auto,并且数据量、特征都比较大时,内部会随机梯度下降法。
(4)normalize:,default=True, 数据进行标准化,如果特征工程中已经做过标准化,这里就该设置为False
(5)max_iterint, default=None,梯度解算器的最大迭代次数,默认为150002 属性
coef_ 回归后的权重系数
intercept_ 偏置说明:SGDRegressor也可以做岭回归的事情,比如SGDRegressor(penalty='l2',loss="squared_loss"),但是其中梯度下降法有些不同。所以推荐使用Ridge实现岭回归
8.3 示例
岭回归 加载加利福尼亚住房数据集,进行回归预测
# 岭回归 加载加利福尼亚住房数据集,进行回归预测
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.metrics import mean_squared_errorfrom sklearn.datasets import fetch_california_housing
# 1)加载数据
housing = fetch_california_housing(data_home="./src")
print(housing)
# 2)划分训练集与测试集
x_train, x_test, y_train, y_test = train_test_split(housing.data, housing.target, random_state=22)
# 3)标准化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)# 4)岭回归预估器
estimator = Ridge(alpha=0.5, max_iter=10000)
estimator.fit(x_train, y_train)# 5)得出模型
print("权重系数为:\n", estimator.coef_) #权重系数与特征数一定是同样的个数。
print("偏置为:\n", estimator.intercept_)# 6)模型评估
y_predict = estimator.predict(x_test)
print("预测的数据集:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("均方误差为:\n", error)
9.拉索回归Lasso
9.1 损失函数公式
Lasso回归是一种线性回归模型,它通过添加所有权重的绝对值之和(L1)来惩罚模型的复杂度。
Lasso回归的目标是最小化以下损失函数:
J(w) = 1 2 n ∑ i = 1 n ( h w ( x i ) − y i ) 2 + λ ∑ j = 1 p ∣ w j ∣ \text{J(w)}= \frac{1}{2n}\sum_{i=1}^n (h_w(x_i)-y_i)^2 + \lambda \sum_{j=1}^p |w_j| J(w)=2n1∑i=1n(hw(xi)−yi)2+λ∑j=1p∣wj∣
其中:
- $n $ 是样本数量,
- $ p $ 是特征的数量,
- $ y_i $是第 $ i $ 个样本的目标值,
- $ x_i $ 是第 $ i $ 个样本的特征向量,
- w w w是模型的参数向量,
- $\lambda $ 是正则化参数,控制正则化项的强度。
特点:
- 拉索回归可以将一些权重压缩到零,从而实现特征选择。这意味着模型最终可能只包含一部分特征。
- 适用于特征数量远大于样本数量的情况,或者当特征间存在相关性时,可以从中选择最相关的特征。
- 拉索回归产生的模型可能更简单,因为它会去除一些不重要的特征。
9.2 API
sklearn.linear_model.Lasso()
参数:
- alpha (float, default=1.0):
- 控制正则化强度;必须是非负浮点数。较大的 alpha 增加了正则化强度。
- fit_intercept (bool, default=True):
- 是否计算此模型的截距。如果设置为 False,则不会使用截距(即数据应该已经被居中)。
- precompute (bool or array-like, default=False):
- 如果为 True,则使用预计算的 Gram 矩阵来加速计算。如果为数组,则使用提供的 Gram 矩阵。
- copy_X (bool, default=True):
- 如果为 True,则复制数据 X,否则可能对其进行修改。
- max_iter (int, default=1000):
- 最大迭代次数。
- tol (float, default=1e-4):
- 精度阈值。如果更新后的系数向量减去之前的系数向量的无穷范数除以 1 加上更新后的系数向量的无穷范数小于 tol,则认为收敛。
- warm_start (bool, default=False):
- 当设置为 True 时,再次调用 fit 方法会重新使用之前调用 fit 方法的结果作为初始估计值,而不是清零它们。
- positive (bool, default=False):
- 当设置为 True 时,强制系数为非负。
- random_state (int, RandomState instance, default=None):
- 随机数生成器的状态。用于随机初始化坐标下降算法中的随机选择。
- selection ({‘cyclic’, ‘random’}, default=‘cyclic’):
- 如果设置为 ‘random’,则随机选择坐标进行更新。如果设置为 ‘cyclic’,则按照循环顺序选择坐标。
属性:
- coef_
- 系数向量或者矩阵,代表了每个特征的权重。
- **intercept_ **
- 截距项(如果 fit_intercept=True)。
- **n_iter_ **
- 实际使用的迭代次数。
- n_features_in_ (int):
- 训练样本中特征的数量。
9.3 示例
from sklearn.datasets import fetch_california_housing
from sklearn.linear_model import Lasso
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
import numpy as np# 加载波士顿房价数据集
data = fetch_california_housing(data_home="./src")
X, y = data.data, data.target# 划分训练集和测试集
X_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建Lasso回归模型
lasso = Lasso(alpha=0.1) # alpha是正则化参数# 训练模型
lasso.fit(X_train, y_train)# 得出模型
print("权重系数为:\n", lasso.coef_) #权重系数与特征数一定是同样的个数。
print("偏置为:\n", lasso.intercept_)#模型评估
y_predict = lasso.predict(x_test)
print("预测的数据集:\n", y_predict)
error = mean_squared_error(y_test, y_predict)
print("均方误差为:\n", error)


















