一、NLP 分词技术概述
(一)定义
自然语言处理(NLP)中的分词技术是将连续的文本序列按照一定的规则切分成有意义的词语的过程。例如,将句子 “我爱自然语言处理” 切分为 “我”、“爱”、“自然语言处理” 或者 “我”、“爱”、“自然”、“语言”、“处理” 等不同的词语组合。
(二)分词技术的重要性
- 基础作用:分词是 NLP 许多任务的基础,如文本分类、信息检索、机器翻译等。例如在机器翻译中,如果分词不准确,会导致翻译的句子语义混乱。
- 语义理解:正确的分词有助于更好地理解文本的语义。不同的分词方式可能会导致对句子的理解产生差异。
(三)分词技术的主要方法
1. 基于规则的分词方法
- 原理:依据语言学的规则和字典来进行分词。例如,最大匹配法,它包括正向最大匹配和逆向最大匹配。正向最大匹配是从句子的开头开始,每次尝试匹配字典中最长的词。逆向最大匹配则是从句子的末尾开始。
- 优点:简单直观,对于一些具有明确语法规则的文本效果较好,而且不需要大量的训练数据。
- 缺点:规则的制定依赖于人工,对于复杂的语言现象(如歧义、新词等)处理能力有限。
-
#分词方法最大正向切分的实现方式import re import time import json#加载词前缀词典 #用0和1来区分是前缀还是真词 #需要注意有的词的前缀也是真词,在记录时不要互相覆盖 def load_prefix_word_dict(path):prefix_dict = {}with open(path, encoding="utf8") as f:for line in f:word = line.split()[0]for i in range(1, len(word)):if word[:i] not in prefix_dict: #不能用前缀覆盖词prefix_dict[word[:i]] = 0 #前缀prefix_dict[word] = 1 #词return prefix_dict#输入字符串和字典,返回词的列表 def cut_method2(string, prefix_dict):if string == "":return []words = [] # 准备用于放入切好的词start_index, end_index = 0, 1 #记录窗口的起始位置window = string[start_index:end_index] #从第一个字开始find_word = window # 将第一个字先当做默认词while start_index < len(string):#窗口没有在词典里出现if window not in prefix_dict or end_index > len(string):words.append(find_word) #记录找到的词start_index += len(find_word) #更新起点的位置end_index = start_index + 1window = string[start_index:end_index] #从新的位置开始一个字一个字向后找find_word = window#窗口是一个词elif prefix_dict[window] == 1:find_word = window #查找到了一个词,还要在看有没有比他更长的词end_index += 1window = string[start_index:end_index]#窗口是一个前缀elif prefix_dict[window] == 0:end_index += 1window = string[start_index:end_index]#最后找到的window如果不在词典里,把单独的字加入切词结果if prefix_dict.get(window) != 1:words += list(window)else:words.append(window)return words#cut_method是切割函数 #output_path是输出路径 def main(cut_method, input_path, output_path):word_dict = load_prefix_word_dict("dict.txt")writer = open(output_path, "w", encoding="utf8")start_time = time.time()with open(input_path, encoding="utf8") as f:for line in f:words = cut_method(line.strip(), word_dict)writer.write(" / ".join(words) + "\n")writer.close()print("耗时:", time.time() - start_time)returnstring = "王羲之草书《平安帖》共有九行" # string = "你到很多有钱人家里去看" # string = "金鹏期货北京海鹰路营业部总经理陈旭指出" # string = "伴随着优雅的西洋乐" # string = "非常的幸运" prefix_dict = load_prefix_word_dict("dict.txt") # print(cut_method2(string, prefix_dict)) # print(json.dumps(prefix_dict, ensure_ascii=False, indent=2)) main(cut_method2, "corpus.txt", "cut_method2_output.txt")
2. 基于统计的分词方法
- 原理:利用语料库中词语出现的统计信息来进行分词。常见的有隐马尔可夫模型(HMM)。HMM 假设文本中的每个词是一个状态,词与词之间的转换是一个马尔可夫过程。通过对大量文本的训练,学习到词语出现的概率和转移概率,从而进行分词。
- 优点:可以处理一些有歧义的情况,并且能够适应新的语言现象。
- 缺点:需要大量的训练数据来估计概率模型,而且模型相对复杂,训练和推理的时间成本较高。
隐马尔科夫模型
- 定义与概念
- 隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用于描述一个含有隐含未知参数的马尔可夫过程。它由两个部分组成:一个是马尔可夫链,用于描述状态之间的转移;另一个是观测概率分布,用于描述在每个状态下产生观测值的概率。
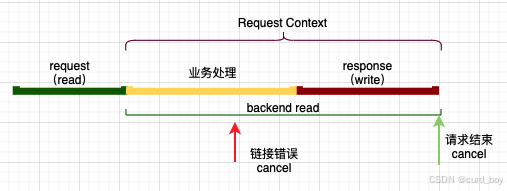
- 状态转移概率矩阵(A):用一个矩阵来表示状态之间的转移概率。如果用S1表示 “晴天”,S2表示 “雨天”,那么状态转移概率矩阵可能是这样的:

- 马尔可夫链:假设系统在 t 时刻的状态只与 t-1 时刻的状态有关,而与更早的状态无关。例如,天气变化可以看作一个马尔可夫链,假设今天的天气(晴、雨、阴)只与昨天的天气有关。
- 隐含状态和观测状态:在 HMM 中,存在一些隐藏的状态,我们无法直接观察到,这些状态会生成可观测的输出。以语音识别为例,隐含状态可能是不同的音素,而观测状态是实际听到的语音信号。
- 观测概率矩阵(B):同样,用一个矩阵来表示在每个隐藏状态下产生不同观测值的概率。用表示 “散步”,表示 “宅家”,观测概率矩阵可能是:

这表示在晴天的时候,人们出去散步的概率是0.6,宅家的概率是0.4;
在雨天的时候,人们出去散步的概率是0.2,宅家的概率是0.8。
4.初始状态概率向量(π):假设一开始晴天的概率是0.6,雨天的概率是0.4,
那么![]() 。整个过程就像是一个有隐藏状态的 “黑箱”,隐藏状态(天气) 按照一定的概率转移,并且在每个隐藏状态下又按照一定的概率产生观测值。
。整个过程就像是一个有隐藏状态的 “黑箱”,隐藏状态(天气) 按照一定的概率转移,并且在每个隐藏状态下又按照一定的概率产生观测值。
代码实例(使用 Python 的 hmmlearn 库进行简单的序列生成)
-
首先,需要安装
hmmlearn库。如果没有安装,可以使用pip install hmmlearn命令安装。 -
以下是一个简单的代码示例,用于生成一个基于 HMM 的观测序列:
-
import numpy as np from hmmlearn import hmm ''' 首先,我们导入了必要的库numpy和hmmlearn中的hmm模块。 然后,定义了隐藏状态的数量n_components为 2 和观测状态的数量n_features为 2。 创建了一个MultinomialHMM对象,它代表一个多项式分布的隐马尔科夫模型。 接着,我们手动设置了初始状态概率向量model.startprob_、状态转移概率矩阵model.transmat_和观测概率矩阵model.emissionprob_,这些参数与我们前面在天气和活动的例子中解释的类似。 最后,使用model.sample方法生成了一个长度为 10 的观测序列X和对应的隐藏状态序列Z,并将它们打印出来。 '''# 定义隐马尔科夫模型的参数 # 假设我们有2个隐藏状态和2个观测状态 n_components = 2 n_features = 2# 创建一个隐马尔科夫模型对象 model = hmm.MultinomialHMM(n_components=n_components)# 初始化状态转移概率矩阵A model.startprob_ = np.array([0.6, 0.4]) model.transmat_ = np.array([[0.7, 0.3], [0.4, 0.6]])# 初始化观测概率矩阵B model.emissionprob_ = np.array([[0.6, 0.4], [0.2, 0.8]])# 生成一个长度为10的观测序列 X, Z = model.sample(n_samples=10) print("观测序列:", X) print("隐藏状态序列:", Z)
3. 基于深度学习的分词方法
- 原理:利用神经网络自动学习文本的特征来进行分词。例如,使用长短期记忆网络(LSTM)或者卷积神经网络(CNN)。这些网络可以对文本序列进行编码,然后输出每个位置的分词结果。
- 优点:能够自动学习到复杂的语言模式,对于未登录词(新词)有较好的处理能力,并且在性能上通常优于传统方法。
- 缺点:需要大量的训练数据和计算资源,模型解释性相对较差。
二、代码项目示例(以 Python 中的 jieba 分词为例)
安装 jieba 分词库
- 如果还没有安装 jieba,可以使用以下命令安装:
-
pip install jieba基本分词示例
- 下面是一个简单的代码,用于对一个句子进行分词。
import jieba
sentence = "我爱自然语言处理"
words = jieba.cut(sentence)
print(" ".join(words))-
- 在这个示例中,
jieba.cut函数会对sentence进行分词,返回一个可迭代的生成器对象。通过" ".join(words)将分词结果以空格分隔的字符串形式输出,结果可能是 “我 爱 自然语言处理”。
- 在这个示例中,
-
精确模式和全模式分词
- jieba 有精确模式(默认)和全模式。精确模式试图将句子最精确地切开,适合文本分析;全模式把句子中所有的可以成词的词语都扫描出来,速度非常快,但不能解决歧义。
import jieba
sentence = "他说的确实在理"
# 精确模式
words_precise = jieba.cut(sentence, cut_all=False)
print("精确模式:", " ".join(words_precise))
# 全模式
words_full = jieba.cut(sentence, cut_all=True)
print("全模式:", " ".join(words_full))- 精确模式可能输出 “他 说 的 确实 在理”,而全模式可能输出 “他 说 的 确实 实在 在意 在理” 等。
添加自定义词典
- 当遇到一些新词或者专业术语时,可以添加自定义词典来提高分词的准确性。
- 假设我们有一个自定义词典文件
user_dict.txt,内容如下(每行一个词和它的词频等信息,词频可以为整数,这里简单示例):
import jieba
jieba.load_userdict("user_dict.txt")
sentence = "我爱自然语言处理"
words = jieba.cut(sentence)
print(" ".join(words))- 这样,在分词的时候,“自然语言处理” 就会被当作一个词来切分,而不是被切成多个部分。
关键词提取(基于 TF - IDF)
- jieba 还提供了基于 TF - IDF(词频 - 逆文档频率)的关键词提取功能。
import jieba.analyse
sentence = "自然语言处理是计算机科学领域与人工智能领域中的一个重要方向"
keywords = jieba.analyse.extract_tags(sentence, topK=3)
print(keywords)- 上述代码中,
extract_tags函数会提取句子中的关键词,topK参数指定提取关键词的数量,这里会输出句子中最重要的 3 个关键词,如 ["自然语言处理", "人工智能", "计算机科学"](具体结果可能因语料库等因素略有不同)。