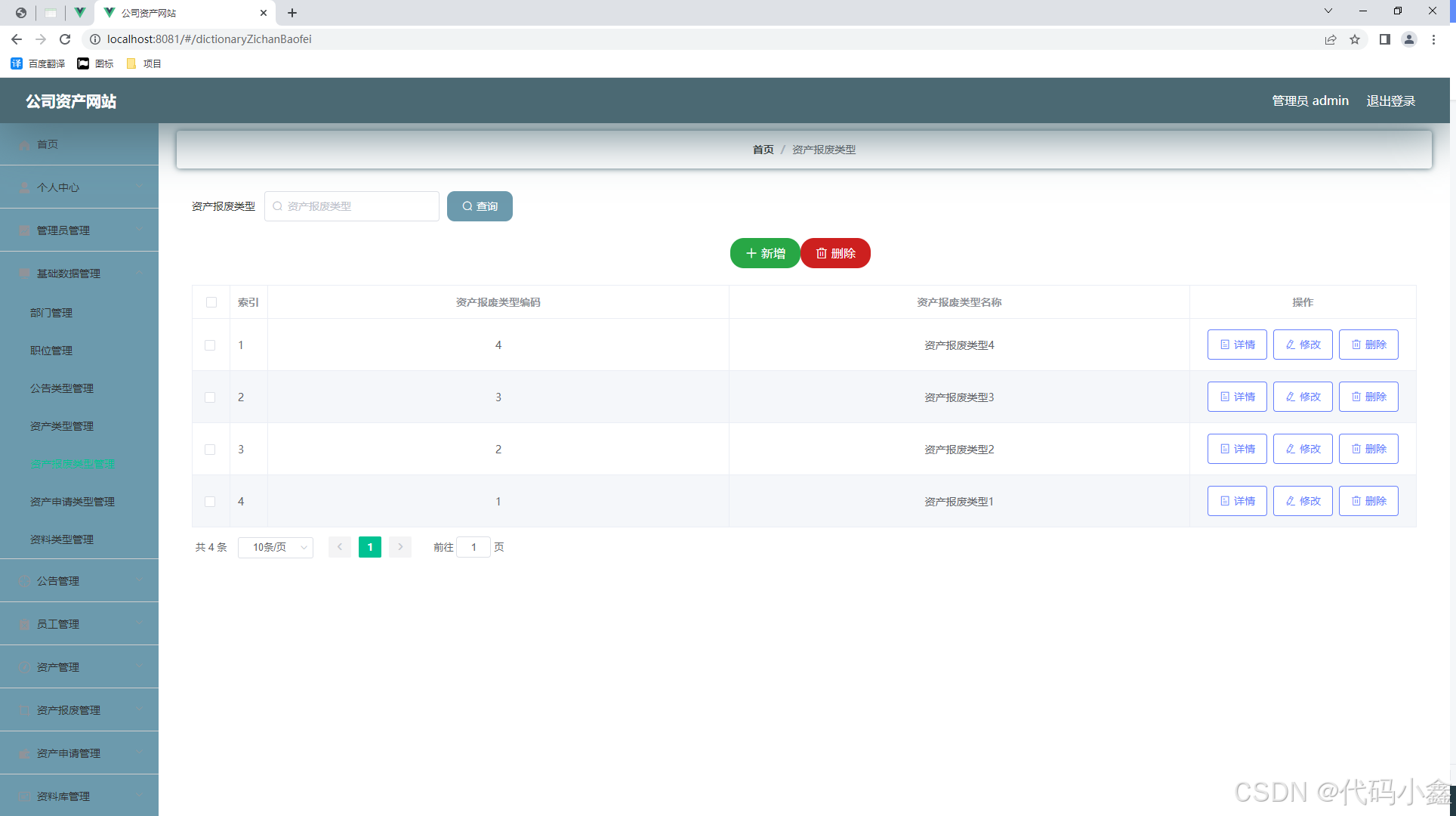
使用场景:
需要初始化国家(地区表),字段有国家名称、国家编码等等。
解决方案:
使用requests发送请求,使用bs4解析得到的HTML,打开F12,查看元素,(可以Ctrl+S直接保存HTML使用VS code 打开更加清晰)找到数据所在标签,再根据标签获取内容。获取需要的数据,再存储到数组,最后使用pandas将数据转成DataFrame,调用to_excel方法导出。
import requests
from bs4 import BeautifulSoup
import pandas as pd# 目标网页URL
url = 'https://www.guojiadaima.com/'# 发送HTTP请求获取网页内容
response = requests.get(url)
response.encoding = 'utf-8' # 根据网页的编码调整# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')# 找到数据所在的标签
tbodyData = soup.find('tbody')# 初始化数据列表
data = []# 提取表格中的数据
for row in tbodyData.find_all('tr')[1:]: # 跳过表头columns = row.find_all('td')if len(columns) > 1:if columns[3].text.strip() != '':country_name = columns[3].text.strip() # 中文简称english_name = columns[4].text.strip() # 英文简称iso2_code = columns[5].text.strip() # ISO 2iso3_code = columns[6].text.strip() # ISO 3numerical_code = columns[7].text.strip() # 数字代码ip_code = columns[9].text.strip() # 数字代码data.append({'国家名称': country_name,'英文名称': english_name,'国家编码2': iso2_code,'国家编码3': iso3_code,'数字代码': numerical_code,'域名后缀': ip_code})# 打印提取的数据
for item in data:print(item)# 将数据转换为DataFrame
df = pd.DataFrame(data)
print(df)# 导出到Excel文件
# index=False表示不导出DataFrame的索引
df.to_excel('countries_codes.xlsx', index=False)# 指定输出的Excel文件的完整路径
# 假设你想要将文件保存在C盘的某个文件夹中
output_path = 'C:/Users/YourUsername/Documents/output.xlsx'
# 或者在Linux/macOS系统中使用正斜杠(/)或双反斜杠(\\)作为路径分隔符
# output_path = '/home/yourusername/Documents/output.xlsx'
# 或者
# output_path = 'C:\\Users\\YourUsername\\Documents\\output.xlsx'
df.to_excel(output_path, index=False)需要使用的依赖:








![[JAVA]有关MyBatis环境配置介绍](https://i-blog.csdnimg.cn/direct/6b2d13bbc9a1426e88e3439575945e55.png)








