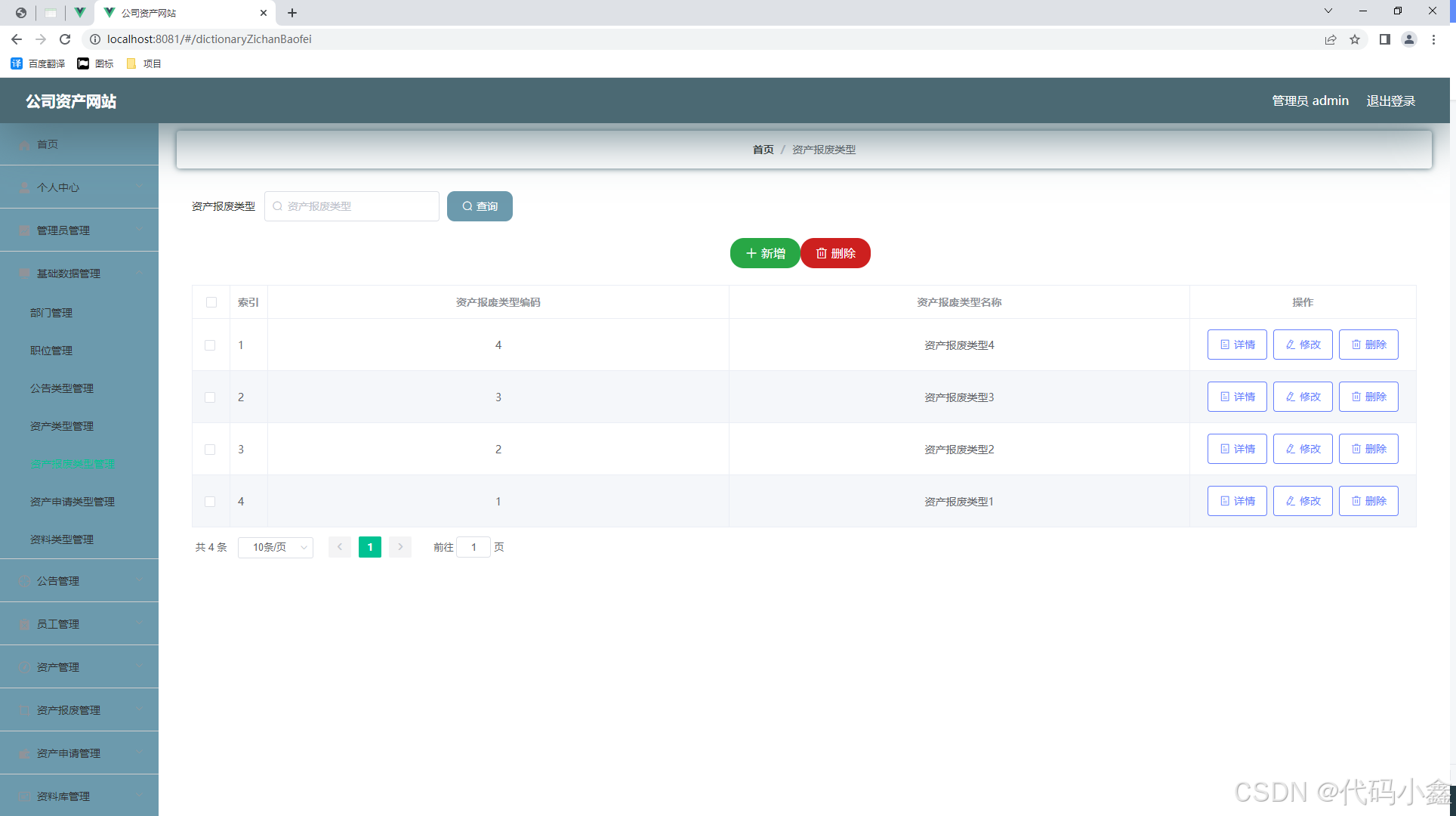
插入排序——希尔排序
- 7.5 插入排序——希尔排序
- 概念和思路
- 参考程序
- 希尔排序的特性总结
- 复杂度
- 稳定性
7.5 插入排序——希尔排序
概念和思路
我们都知道,直接插入排序的时间复杂度为 O ( n 2 ) O(n^2) O(n2),但当数据无限接近有序或本身就是有序的时候,插入排序的时间复杂度能来到 O ( n ) O(n) O(n)。
希尔排序就是诞生于这个背景下。
希尔排序法又称缩小增量法。希尔排序法的基本思想是:
先选定一个整数d,把待排序文件中所有记录分成若干个组,所有距离为d的记录分在同一组内,并对每一组内的记录进行排序。然后,取d的缩小值,再重复上述分组和排序的工作。当到达d=1时,所有记录在统一组内排好序。
根据基本思想,得出希尔排序的思路:
- 预排序,使局部有序。
- 插入排序。
步骤:
- 数据间隔gap分为一组,总计分为gap组。
- 预排序:对gap组数据分别进行插入排序。
- 逐渐缩小gap的大小,当gap为1时,希尔排序和插入排序无任何差别。
gap的取法并不固定。从希尔排序这个排序算法被发明以来,人们一直都在寻找最合适的gap的取值。目前比较成熟的方法是,将gap和n绑定在一起。
推荐gap和n的关系为gap的初始值为n,之后gap通过表达式gap=f(gap)+1来缩小gap的大小,即 g a p < f ( g a p ) + 1 gap<f(gap)+1 gap<f(gap)+1。f(gap)是数学表达式,一般常用 f ( g a p ) = g a p 2 f(gap)=\frac{gap}{2} f(gap)=2gap,或 f ( g a p ) = [ g a p / 3 ] f(gap)=[gap/3] f(gap)=[gap/3]。官方更喜欢用gap=gap/3+1,虽然它的预排序次数不如gap=gap/2。
根据上述描述,画出草图:

参考程序
void shellSort(Datatype* a, int n) {int gap = n;while (gap > 1) {gap = gap / 2;//缩小增量int i = 0;for (i = 0; i < n - gap; ++i) {//插入排序int end = i;int tmp = a[end + gap];while (end >= 0) {if (a[end] > tmp) {a[end + gap] = a[end];end -= gap;}else break;}a[end + gap] = tmp;}}
}
gap的表达式可以更换:
void shellSort(Datatype* a, int n) {int gap = n;while (gap > 1) {gap = gap / 3 + 1;//+1可以保证最后一次一定是1int i = 0;for (i = 0; i < n - gap; ++i) {//插入排序int end = i;int tmp = a[end + gap];while (end >= 0) {if (a[end] > tmp) {a[end + gap] = a[end];end -= gap;}else break;}a[end + gap] = tmp;}}
}
希尔排序的特性总结
-
希尔排序是对直接插入排序的优化。
-
当
gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,遍历就会很快。整体而言,对比插入排序可以达到可观的优化的效果。后续会进行对比。
复杂度
希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此目前给出的希尔排序的时间复杂度都不固定。
我们可以尝试计算这里写的希尔排序的时间复杂度。不想看的可直接翻到后面记结论。
void shellSort(Datatype* a, int n) {int gap = n;while (gap > 1) {gap = gap / 3 + 1;//+1可以保证最后一次一定是1int i = 0;for (i = 0; i < n - gap; ++i) {//插入排序int end = i;int tmp = a[end + gap];while (end >= 0) {if (a[end] > tmp) {a[end + gap] = a[end];end -= gap;}else break;}a[end + gap] = tmp;}}
}
当gap=gap/3+1时,设x为for循环的次数,则 n = 3 x n=3^x n=3x(1是常数,对最后的时间复杂度没有影响),所以 x = l o g 3 n x=log_3n x=log3n。
同理当gap=gap/2时可得 x = l o g 2 n x=log_2n x=log2n。
之后gap组数据进行的预排序因为gap的大小会变,最后只能确认gap最大或最小时都是 O ( n ) O(n) O(n):
例如: g a p = n 3 gap=\frac{n}{3} gap=3n,每组3个,合计 n 3 \frac{n}{3} 3n组,每组最坏比较 ( 1 + 2 + 3 ) = 6 (1+2+3)=6 (1+2+3)=6次。
所以循环次数为 n 3 × 6 = 2 n \frac{n}{3}\times6=2n 3n×6=2n。
当 g a p = = 1 gap==1 gap==1时,经过之前的预排序,数据已经十分有序,循环相当于检查一遍,所以这一步的时间复杂度为 O ( n ) O(n) O(n)。
随着中间gap的变化运行次数也发生变化:

中间部分的时间复杂度(或者说循环次数)据说需要用复变函数和扎实的数学基础才能算出大概,以自己目前的数学功底无法算出希尔排序的复杂度,以后有机会的话再来看看。
算到这里,虽然我们无法算出,但可以借鉴别人的成果:
时间复杂度为 O ( n 1.3 ) O(n^{1.3}) O(n1.3),当 n → + ∞ n\rightarrow+\infty n→+∞时,时间复杂度为 O ( n ( l o g 2 n ) 2 ) O(n(log_2n)^2) O(n(log2n)2)(按增量为 g a p = g a p / 3 + 1 gap=gap/3+1 gap=gap/3+1来算)。但就整体而言,记结论 O ( n 1.3 ) O(n^{1.3}) O(n1.3)会更轻松。
下面的介绍摘自《数据结构(C语言版)》,作者严蔚敏。

还有一段介绍摘自《数据结构-用面向对象方法与C++描述》,作者殷人昆

这里的gap是按照Knuth提出的方式取值的,而且Knuth进行了大量的试验统计,如果继续用这个gap取值方式的希尔排序的话,暂时就按照时间复杂度在 O ( n 1.25 ) O(n^{1.25}) O(n1.25)到 O ( 1.6 n 1.26 ) O(1.6n^{1.26}) O(1.6n1.26)来算。
简记的话记时间复杂度为 O ( n 1.3 ) O(n^{1.3}) O(n1.3)即可。
由于希尔排序并没有额外开辟空间,所以空间复杂度为 O ( 1 ) O(1) O(1)。
稳定性
希尔排序在不同的间隔(增量)序列下,相同元素的相对位置可能会改变。
例如,数组[4,4,1],假设gap==2,则第一次比较并产生交换的是第一个4和1,交换后数组变成[1,4,4],此时两个4的位置发生了变化。所以希尔排序是不稳定的排序算法。
我们除了这个,还可以通过这个参考程序来证明。这里我们用结构体来同时存储数据和这个数据在原来的数组中的位置。对结构体数组排序后,可观察他们的顺序变化。
#include<stdio.h>
#include<stdlib.h>
#include<time.h>typedef struct Datatype {int x; int i;
}Datatype;void shellSort(Datatype* a, int n) {int gap = n;while (gap > 1) {gap = gap / 3 + 1;//可以试着自己更换不同的增量int i = 0;for (i = 0; i < n - gap; ++i) {//插入排序int end = i;Datatype tmp = a[end + gap];while (end >= 0) {if (a[end].x > tmp.x) {a[end + gap] = a[end];end -= gap;}else break;}a[end + gap] = tmp;}}
}void f() {srand((size_t)time(0));Datatype a[30] = { 0 };int i = 0;for (i = 0; i < 30; i++) {a[i].x = rand() % 100 + 1;a[i].i = i;printf("%d %d,", a[i].x,a[i].i);}shellSort(a, 30);printf("\n");for (i = 0; i < 30; i++)printf("%d %d,", a[i].x, a[i].i);
}int main() {f();return 0;
}








![[JAVA]有关MyBatis环境配置介绍](https://i-blog.csdnimg.cn/direct/6b2d13bbc9a1426e88e3439575945e55.png)







