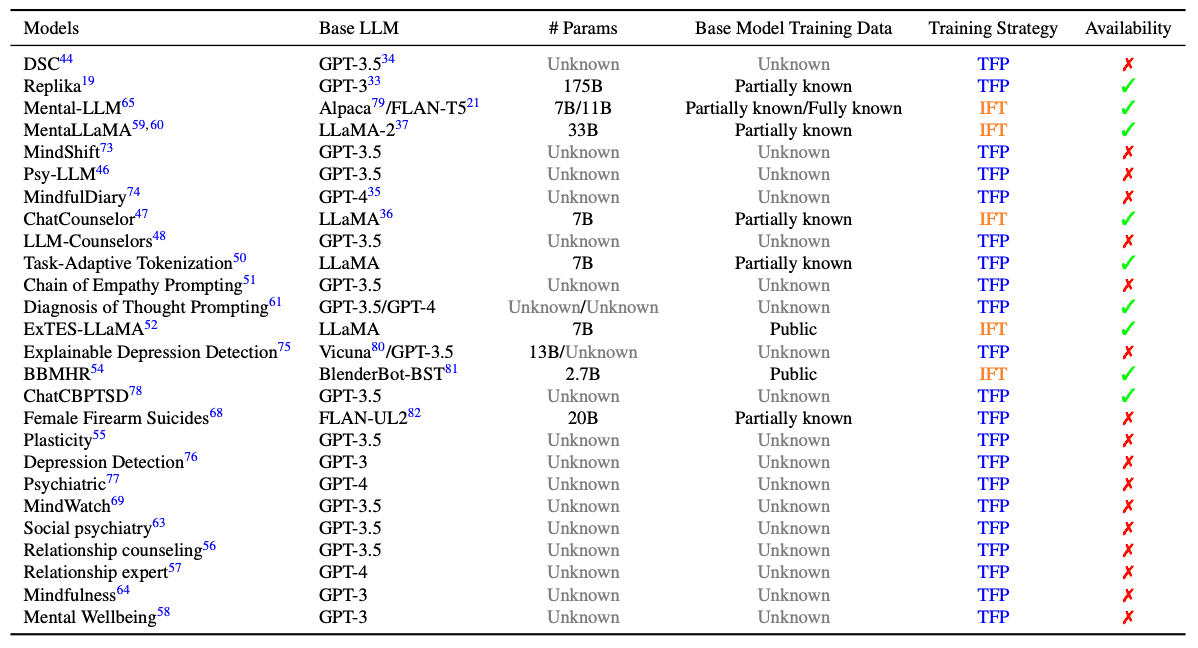
大模型基础BERT——Transformers的双向编码器表示
整体概况
BERT:用于语言理解的深度双向Transform的预训练
论文题目:BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding
Bidirectional Encoder Representations from Transformers.
概括:这篇文章在摘要部分说明了其参考的主要的文章就是ELBO和GPT的相关工作。
-
BERT 模型只需一个额外的输出层即可进行微调,从而为各种任务(例如问答和语言推理)创建最先进的模型,而无需对特定于任务的架构进行大量修改
-
和论文的标题要对应起来
预训练最早我们使用的是词嵌入来做模型的预训练的任务的,当然后面GPT系列的文章。 -
做预训练任务的时候主要有两种方式例如ELBO基于特征的方式,和BERT基于微调的方式。(GPT)感觉就像是迁移学习
-
受完形填空任务启发,通过使用“掩码语言模型”(MLM)预训练目标来实现前面提到的单向性约束(Taylor,1953)。
词嵌入wordembing(word2vec)
在进一步学习自然语言处理之前,因为自己之前主要研究的是cv的方向,因此对自然语言处理缺乏足够的知识去学习。在学习双向编码器之前需要先学习一些NLP的基础知识。

在自然语言处理中: 词是意义的基本单元。顾名思义, 词向量是用于表示单词意义的向量, 并且还可以被认为是单词的特征向量或表示。 将单词映射到实向量的技术称为词嵌入。 近年来,词嵌入逐渐成为自然语言处理的基础知识
在NLP领域构建词向量的过程中,我们如果使用独热编码的方式来进行词向量的构建是一个不好的方式。
-
独热向量很容易构建,但它们通常不是一个好的选择。一个主要原因是独热向量不能准确表达不同词之间的相似度,比如我们经常使用的“余弦相似度”
-
由于任意两个不同词的独热向量之间的余弦相似度为0,所以独热向量不能编码词之间的相似性。
x ⊤ y ∥ x ∥ ∥ y ∥ ∈ [ − 1 , 1 ] . \frac{\mathbf{x}^{\top} \mathbf{y}}{\|\mathbf{x}\|\|\mathbf{y}\|} \in[-1,1] . ∥x∥∥y∥x⊤y∈[−1,1].
我们通过词嵌入的技术可以将onehot编码下的高维稀疏向量,转化为低维且连续的向量。
然后我们这一部分学习的就是常用的词嵌入算法 ——word2vec的技术。通过特定的词嵌入算法,如word2vec、fasttext、Glove等训练一个通用的嵌入矩阵

word2vec工具是为了解决上述问题而提出的。它将每个词映射到一个固定长度的向量,这些向量能更好地表达不同词之间的相似性和类比关系
嵌入矩阵的行,是语料库中词语的个数,矩阵的列是表示词语的维度

5000个单词每个单词都使用128维度的向量来进行表示。

主要包括了两个部分组成。训练依赖于条件概率
- 跳元模型(skip-gram)
- 连续词袋(CBOW)
跳元模型(Skip-Gram)
跳元模型假设一个词可以用来在文本序列中生成其周围的单词。以文本序列“the”“man”“loves”“his”“son”为例。假设中心词选择“loves”,并将上下文窗口设置为2。
给定中心词“loves”,跳元模型考虑生成上下文词“the”“man”“him”“son”的条件概率:

P("the","man","his","son" | "loves"). \text { P("the","man","his","son" | "loves"). } P("the","man","his","son" | "loves").
假设上下文词是在给定中心词的情况下独立生成的(即条件独立性)。在这种情况下,上述条件概率可以重写为:
P ( "the" | "loves") ⋅ P ( "man" | "loves") ⋅ P ( "his" | "loves" ) ⋅ P ( "son" | "loves") P(\text { "the" | "loves") } \cdot P(\text { "man" | "loves") } \cdot P(\text { "his" | "loves" }) \cdot P(\text { "son" | "loves") } P( "the" | "loves") ⋅P( "man" | "loves") ⋅P( "his" | "loves" )⋅P( "son" | "loves")
也就是要设置好窗口的长度。设置好窗口的长度后,需要根据目标词,预测窗口内的上下文词:

在这里我们抛开公式来解释一下这一个跳元模型的建模的思想是什么?
也就是:Skip-gram在迭代时。
- 调整词向量使目标词的词向量与其上下文的词向量尽可能的接近。
- 使目标词的词向量与非上下文词的词向量尽可能的远离。

这里我们的建模的思想就是给定一个词向量,我们希望这样建模也就是:上下文词的词向量相似与非上下文词的词向量不相似。那么我们的词向量就能捕获词语之间的语义关系。
之后我们需要提出的问题就是,如何判断两个词向量是否相似呢?这里就是给定两个词向量,我们与Transform中一样使用点积来判断两个词向量之间的相似性。
A ⋅ B = a 1 b 1 + a 2 b 2 + … + a n b n A = ( a 1 , a 2 , … , a n ) B = ( b 1 , b 2 , … , b n ) \begin{array}{l} A \cdot B=a 1 b 1+a 2 b 2+\ldots+a n b n \\ A=(a 1, a 2, \ldots, a n) \\ B=(b 1, b 2, \ldots, b n) \end{array} A⋅B=a1b1+a2b2+…+anbnA=(a1,a2,…,an)B=(b1,b2,…,bn)
向量的点积:衡量了两个向量在同一方向上的强度点积越大:两个向量越相似,它们对应的词语的语义就越接近。

跳元网络结构
Skip-Gram网络模型是一个神经网络。它主要是包括了
- in_embedding和out_embedding两个嵌入层组成。
- 向该神经网络输入一个目标词之后。
- 模型会返回一个词表大小的分布情况。
词汇表中的每个词是目标词的上下文的可能性

词表中的词,与目标词有两种关系上下文词:正样本,标记为1非上下文词:负样本,标记为0
给定中心词w(词典中的索引lc),生成任何上下文词w。(词典中的索引lo)的条件概率可以通过对向量点积的softmax操作来建模:
P ( w o ∣ w c ) = exp ( u o ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v c ) P\left(w_{o} \mid w_{c}\right)=\frac{\exp \left(\mathbf{u}_{o}^{\top} \mathbf{v}_{c}\right)}{\sum_{i \in \mathcal{V}} \exp \left(\mathbf{u}_{i}^{\top} \mathbf{v}_{c}\right)} P(wo∣wc)=∑i∈Vexp(ui⊤vc)exp(uo⊤vc)

整体的模型得到的词表概率分布的公式如下所示:
∏ t = 1 T ∏ − m ≤ j ≤ m , j ≠ 0 P ( w ( t + j ) ∣ w ( t ) ) \prod_{t=1}^{T} \prod_{-m \leq j \leq m, j \neq 0} P\left(w^{(t+j)} \mid w^{(t)}\right) t=1∏T−m≤j≤m,j=0∏P(w(t+j)∣w(t))
网络训练
跳元模型参数是词表中每个词的中心词向量和上下文词向量。在训练中,我们通过最大化似然函数(即极大似然估计)来学习模型参数。这相当于最小化以下损失函数:
指定窗口长度为m,同时词向量的长度为T
− ∑ t = 1 T ∑ − m ≤ j ≤ m , log P ( w ( t + j ) ∣ w ( t ) ) -\sum_{t=1}^{T} \sum_{-m \leq j \leq m,} \log P\left(w^{(t+j)} \mid w^{(t)}\right) −t=1∑T−m≤j≤m,∑logP(w(t+j)∣w(t))
这里就可以使用随机梯度下降来最小化损失函数的值。
连续词袋(CBOW)模型
CBOW连续词袋模型 Continuous Bag of Words与刚刚说过的跳元模型相比是一个相反的过程了。

假设将我们的窗口长度设置为2以后,就有如下的推导关系了。

连续词袋模型假设中心词是基于其在文本序列中的周围上下文词生成的。例如,在文本序列“the”“man”“loves”“his”“son”中,在“loves”为中心词且上下文窗口为2的情况下,连续词袋模型考虑基于上下文词“the”“man”“him”“son”

P ( "loves" | "the","man","his","son"). P(\text { "loves" | "the","man","his","son"). } P( "loves" | "the","man","his","son").
CBOW的网络结构
我们按照这个顺序继续向下推导直到整个句子推导结束的时候在停止。
CBOW模型同样也是一个神经网络模型,该神经网络会接收上下文词语将上下文词语转换为最有可能得目标词。

我们将这个网络模型在进一步的进行细化进行解释。我们将其中每一个部分的蓝色部分单独的拿出来其中蓝色的部分就是我们的嵌入矩阵,也就是之前提到的N x V的部分。 其输出的结果就是一个词向量。
然后:由于某个词的上下文中,包括了多个词语这些词语会同时输入至embeddings层每个词语都会被转换为一个词向量。
embeddings层的输出结果:是一个将语义信息平均的向量V
v = ( v 1 + v 2 + v 3 + v 4 ) / 4 v=(v 1+v 2+v 3+v 4) / 4 v=(v1+v2+v3+v4)/4


最后一步我们将所有词向量得到的平均值输入到最后的线性层中,通过最后的激活函数就可以得到需要预测的词了。整个过程就可以如下所示。概率最大的词就是我们的输出结果了。

按照和上面同样的思想我们就可以采用如下的方式来进行数学上的建模操作。
P ( w c ∣ w o 1 , … , w o 2 m ) = exp ( 1 2 m u c ⊤ ( v o 1 + … , + v o 2 m ) ) ∑ i ∈ V exp ( 1 2 m u i ⊤ ( v o 1 + … , + v o 2 m ) ) P\left(w_{c} \mid w_{o_{1}}, \ldots, w_{o_{2 m}}\right)=\frac{\exp \left(\frac{1}{2 m} \mathbf{u}_{c}^{\top}\left(\mathbf{v}_{o_{1}}+\ldots,+\mathbf{v}_{o_{2 m}}\right)\right)}{\sum_{i \in \mathcal{V}} \exp \left(\frac{1}{2 m} \mathbf{u}_{i}^{\top}\left(\mathbf{v}_{o_{1}}+\ldots,+\mathbf{v}_{o_{2 m}}\right)\right)} P(wc∣wo1,…,wo2m)=∑i∈Vexp(2m1ui⊤(vo1+…,+vo2m))exp(2m1uc⊤(vo1+…,+vo2m))

P ( w c ∣ W o ) = exp ( u c ⊤ v ‾ o ) ∑ i ∈ V exp ( u i ⊤ v ‾ o ) . P\left(w_{c} \mid \mathcal{W}_{o}\right)=\frac{\exp \left(\mathbf{u}_{c}^{\top} \overline{\mathbf{v}}_{o}\right)}{\sum_{i \in \mathcal{V}} \exp \left(\mathbf{u}_{i}^{\top} \overline{\mathbf{v}}_{o}\right)} . P(wc∣Wo)=∑i∈Vexp(ui⊤vo)exp(uc⊤vo).
BERT的由来
BERT的由来本质上来自于NLP领域迁移学习的思考。使用预训练好的模型来抽取词、句子的特征 例如word2vec
最后我们就可以将整个的建模过程表示如下了:
∏ t = 1 T P ( w ( t ) ∣ w ( t − m ) , … , w ( t − 1 ) , w ( t + 1 ) , … , w ( t + m ) ) \prod_{t=1}^{T} P\left(w^{(t)} \mid w^{(t-m)}, \ldots, w^{(t-1)}, w^{(t+1)}, \ldots, w^{(t+m)}\right) t=1∏TP(w(t)∣w(t−m),…,w(t−1),w(t+1),…,w(t+m))
然而对于我们的一个新的任务来说需要构建新的网络来抓取新任务需要的信息Word2vec忽略了时序信息,语言模型只看了一个方向。

在CV方向上迁移学习有广泛的应用这里我自己举一个例子:例如在许多的网络中我们的backbone都使用的是预训练好的restnet50的权重,并且在网络训练的过程中会冻结这部分权重不需要在调整或者进行新的训练了。
同样NLP是否可以:基于微调的NLP模型预训练的模型抽取了足够多的信息新的任务只需要增加一个简单的输出层。
它就是一个只要Transform编码器的部分—只保留编码器的部分。它是第一个在NLP领域做的很大的网络,并且使用了很大的一个数据集,可以看作是大模型的一个前置的基础了
基础架构
BERT: 主要使用的是Transform的编码器的部分。也就是左半部分所以整个完整的结构理解起来还是挺容易的。
这里提到了是Transform的双向编码器的表示方式:也就是在自注意力机制中,每个词元都与其他所有词元计算注意力分数,这意味着每个词元在编码时都能获取到整个序列的信息。这种机制允许模型在编码时同时考虑前文和后文的信息,从而实现双向处理。
但是我们的Transform的Decode部分通常是单项的部分了,主要的原因是:在自然语言处理中,解码器通常用于生成文本,例如在机器翻译、文本摘要或问答系统中生成回答。在这些任务中,解码器需要根据已经生成的文本来预测下一个词元,而不能利用未来的信息。

我们的编码器部分主要包括了三个部分组成,其中BERT base是堆叠了12个编码器,而BERT large部分主要是堆叠了24个编码器部分。
- 输入部分
- 注意力机制部分
- 前馈神经网络的部分
BERT和Transform的主要的区别在什么地方呢?
- Transform是由6个encode部分堆叠起来构成编码端,6个decode部分构成了解码端。

- 在编码方式上存在不同之处,Transform主要使用的是位置编码也就是正余弦的三角函数编码,而BERT采用的是
Input=token emb+ segment emb+ position emb

在我们的Transform的结构中,例如机器翻译的任务我们的句子要从source(原句子)经过encode的部分到target,在将得到的targets输入到decode部分中进行解码。同步的输出翻译的句子
这里的改进主要的就是想:如何通过新的编码的方式只使用encode完成

上面解释了我们的BERT是一个预训练的任务,也就是要实现通用的功能呀
论文中也提到了BERT主要包括了两个步骤预训练和微调

如何做预训练
BERT的预训练主要包括了两个部分,主要是MLM+NSP :掩码语言模型+ 判断两个句子之间的关系。
BERT在预训练的时候使用的是大量的无标记的预料来进行的。(考虑通过无监督来去做。)
MLM:
在这里要考虑到两种无监督的目标函数。AR模型和AE模型
- AR:auto regressive,自回归模型;只能考虑单侧的信息,典型的就是GPT。

自回归模型(Autoregressive Model,简称AR模型)是时间序列分析中的一种常用模型,它假设一个时间序列的未来值可以通过其过去值的线性组合来预测。自回归模型基于这样的假设:一个变量的当前值可以作为其过去值的函数来预测。
- AE:auto encoding,自编码模型;从损坏的输入数据中预测重建原始数据。可以使用上下文的信息,Bert就是使用的AE

预训练任务一:MLM
带掩码的语言模型(Masked Language Model, MLM)是一种特殊的预训练任务,它通过随机地将输入文本中的一些词元替换为特殊的掩码标记(如mask),然后让模型预测这些被掩码的词元 。
受完形填空任务启发,通过使用“掩码语言模型”(MLM)预训练目标来实现前面提到的单向性约束(Taylor,1953)其实也就是说在做完型填空的时候不能只看一侧而应该关注左右两边的信息。
这种训练方式使得模型能够学习到词汇之间的语义关系和上下文依赖。在BERT等模型中,这种掩码策略通常包括将80%的词汇被替换为MASK,10%被替换为随机词汇,剩余10%保持不变 。这样的随机替换策略既保证了模型能够学习到足够的上下文信息,又避免了模型过度依赖MASK标记而忽略真实的词汇信息 。

预训练任务二:下一句子预测NSP
NSP:
NSP的样本如下:
- 从训练语料库中取出两个连续的段落作为正样本
- 从不同的文档中随机创建一对段落作为负样本
也就是预测:预测一个句子对中两个句子是不是相邻的这一个任务了。
也就是让我们的训练样本中:50%概率选择相邻句子对:50%概率选择随机句子对:将对应的输出放到一个全连接层来预测。
最后需要解释的就是我们输入的token序列对是如何进行的它包含的两个字符[CLS]和[SEP]的两个部分。
- 每个序列的标记始终是一个特殊的分类标记([CLS])
- 句子对被打包成一个序列。 我们以两种方式区分句子。 首先,我们用一个特殊的标记([SEP])将它们分开。

下面的这个图就是我们嵌入层的一个关系图也就是之前提到的编码方式。

-
Input:作为词嵌入层的一个输入属于是这里的[CLS]是用于NSP任务的一个标志词[SEP]用来将两个句子断开。
-
第二部分的Segment Embeddings层这里将我们的第一个句子的编码EA设置为0,第二个部分的编码设置为1即可
-
第三部分是位置编码的部分:这里是随机初始化让我们的模型自己学习出来
微调
更多的情况下我们不会去预训练一个BERT的模型而是使用大公司给我们预训练模型并在此基础上进行微调的操作。
也就是如何更好的将我们的BERT应用到下游的任务中去。
这里的微调就是:
- 在相同领域 上继续训练LM (Domain transfer)
- 在任务相关的小数据上继续训练LM(Tasktransfer)