一. 康佳PC端实现:1080 → 4K 实时超分
1. 将图像预处理操作从 CPU → GPU 运行

2. 后处理部分操作 从 CPU → GPU 运行

inference_realesrgan_Animal_Video.py
import argparse
import cv2
import glob
import os
from basicsr.archs.rrdbnet_arch import RRDBNet
from basicsr.utils.download_util import load_file_from_urlfrom realesrgan import RealESRGANer
from realesrgan.archs.srvgg_arch import SRVGGNetCompact
import numpy as np
import time
import torch
# import cupy as cp
import subprocess
import threadingdef play_video():subprocess.call(["ffplay", "-nodisp", "-i", R"C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\第1集_桃园三结义_1080P.mp4"])# subprocess.call(["ffplay", "-i", "/home/tyzc/0416_syl_chaofen/rknn-multi-threaded-Super-Resolution-syl/cartorn/video_640.mp4"])def bgr_to_yuv(bgr_image):"""将 BGR 图像转换为 YUV 图像,并分离出 Y, U, V 通道:param bgr_image: 输入的 BGR 图像,类型为 CuPy 数组:return: Y, U, V 通道(都是 CuPy 数组)"""# 将 BGR 图像转换为 YUV# BGR 到 YUV 转换的矩阵# bgr_image = bgr_image.astype(cp.float32)Y = 0.299 * bgr_image[:, :, 2] + 0.587 * bgr_image[:, :, 1] + 0.114 * bgr_image[:, :, 0]U = -0.169 * bgr_image[:, :, 2] - 0.331 * bgr_image[:, :, 1] + 0.499 * bgr_image[:, :, 0] + 128V = 0.499 * bgr_image[:, :, 2] - 0.419 * bgr_image[:, :, 1] - 0.0813 * bgr_image[:, :, 0] + 128return Y, U, Vdef main():"""Inference demo for Real-ESRGAN."""parser = argparse.ArgumentParser()parser.add_argument('-i', '--input', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\weights\4K_Cartoon_Y', help='Input image or folder')parser.add_argument('-n','--model_name',type=str,default='RealESRGAN_x2plus',help=('Model names: RealESRGAN_x4plus | RealESRNet_x4plus | RealESRGAN_x4plus_anime_6B | RealESRGAN_x2plus | ''realesr-animevideov3 | realesr-general-x4v3'))parser.add_argument('-o', '--output', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\weights\4K_Cartoon_Y_2X', help='Output folder')parser.add_argument('-dn','--denoise_strength',type=float,default=0.5,help=('Denoise strength. 0 for weak denoise (keep noise), 1 for strong denoise ability. ''Only used for the realesr-general-x4v3 model'))parser.add_argument('-s', '--outscale', type=float, default=2, help='The final upsampling scale of the image')parser.add_argument('--model_path', type=str, default=R"C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\models\train_realesrnet_x2plus_32_1_16_4channel__123conv_1rdb1_net_oneresize_no_conv_hr_pairdata_0929_real_net_g_520000.pth", help='[Option] Model path. Usually, you do not need to specify it')# '--model_path', type=str, default="/home/sunyingli/Real-ESRGAN/experiments/train_realesrnet_x2plus_32_1_16_4channel__123conv_1rdb1_net_oneresize_no_conv_hr_pairdata_0806/models/net_g_410000.pth", help='[Option] Model path. Usually, you do not need to specify it')parser.add_argument('--suffix', type=str, default='', help='Suffix of the restored image')parser.add_argument('-t', '--tile', type=int, default=0, help='Tile size, 0 for no tile during testing')parser.add_argument('--tile_pad', type=int, default=10, help='Tile padding')parser.add_argument('--pre_pad', type=int, default=0, help='Pre padding size at each border')parser.add_argument('--face_enhance', action='store_true', help='Use GFPGAN to enhance face')parser.add_argument('--fp32', action='store_true', help='Use fp32 precision during inference. Default: fp16 (half precision).')parser.add_argument('--alpha_upsampler',type=str,default='realesrgan',help='The upsampler for the alpha channels. Options: realesrgan | bicubic')parser.add_argument('--ext',type=str,default='auto',help='Image extension. Options: auto | jpg | png, auto means using the same extension as inputs')parser.add_argument('-g', '--gpu-id', type=int, default=0, help='gpu device to use (default=None) can be 0,1,2 for multi-gpu')args = parser.parse_args()# determine models according to model namesargs.model_name = args.model_name.split('.')[0]if args.model_name == 'RealESRGAN_x4plus': # x4 RRDBNet modelmodel = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=4)netscale = 4file_url = ['https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth']elif args.model_name == 'RealESRNet_x4plus': # x4 RRDBNet modelmodel = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=23, num_grow_ch=32, scale=4)netscale = 4file_url = ['https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.1/RealESRNet_x4plus.pth']elif args.model_name == 'RealESRGAN_x4plus_anime_6B': # x4 RRDBNet model with 6 blocksmodel = RRDBNet(num_in_ch=3, num_out_ch=3, num_feat=64, num_block=6, num_grow_ch=32, scale=4)netscale = 4file_url = ['https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth']elif args.model_name == 'RealESRGAN_x2plus': # x2 RRDBNet modelmodel = RRDBNet(num_in_ch=1, num_out_ch=1, num_feat=32, num_block=1, num_grow_ch=16, scale=2)netscale = 2file_url = ['https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth']elif args.model_name == 'realesr-animevideov3': # x4 VGG-style model (XS size)model = SRVGGNetCompact(num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=16, upscale=4, act_type='prelu')netscale = 4file_url = ['https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.5.0/realesr-animevideov3.pth']elif args.model_name == 'realesr-general-x4v3': # x4 VGG-style model (S size)model = SRVGGNetCompact(num_in_ch=3, num_out_ch=3, num_feat=64, num_conv=32, upscale=4, act_type='prelu')netscale = 4file_url = ['https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.5.0/realesr-general-wdn-x4v3.pth','https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.5.0/realesr-general-x4v3.pth']# determine model pathsif args.model_path is not None:model_path = args.model_pathelse:model_path = os.path.join('weights', args.model_name + '.pth')if not os.path.isfile(model_path):ROOT_DIR = os.path.dirname(os.path.abspath(__file__))for url in file_url:# model_path will be updatedmodel_path = load_file_from_url(url=url, model_dir=os.path.join(ROOT_DIR, 'weights'), progress=True, file_name=None)# use dni to control the denoise strengthdni_weight = Noneif args.model_name == 'realesr-general-x4v3' and args.denoise_strength != 1:wdn_model_path = model_path.replace('realesr-general-x4v3', 'realesr-general-wdn-x4v3')model_path = [model_path, wdn_model_path]dni_weight = [args.denoise_strength, 1 - args.denoise_strength]# restorerupsampler = RealESRGANer(scale=netscale,model_path=model_path,dni_weight=dni_weight,model=model,tile=args.tile,tile_pad=args.tile_pad,pre_pad=args.pre_pad,half=not args.fp32,gpu_id=args.gpu_id)if args.face_enhance: # Use GFPGAN for face enhancementfrom gfpgan import GFPGANerface_enhancer = GFPGANer(model_path='https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.3.pth',upscale=args.outscale,arch='clean',channel_multiplier=2,bg_upsampler=upsampler)os.makedirs(args.output, exist_ok=True)if os.path.isfile(args.input):paths = [args.input]else:paths = sorted(glob.glob(os.path.join(args.input, '*')))# for idx, path in enumerate(paths):cap = cv2.VideoCapture(R'C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\整装待发发兵出征_720P.mp4')width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))idx = 0while (cap.isOpened()):idx += 1if idx == 1:one_all_start_time = time.time()print('Testing', idx)start_time = time.time()ret, frame = cap.read()frame_resize = frame[:,:width//2,]img_BGR = frame[:,width//2:,]end_time = time.time()print("1 " + str(end_time - start_time))start_time = time.time()img_yuv = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2YUV)Y, U, V = cv2.split(img_yuv)end_time = time.time()print("2 " + str(end_time - start_time))# image = img_BGR# image_cp = cp.asarray(image) # 将图像转换为 CuPy 数组# # 转换为 YUV,并分离通道# Y, U, V = bgr_to_yuv(image_cp)# # 将 Y, U, V 转换为 NumPy 数组以便查看(如果需要在 CPU 上操作)# Y_cpu = cp.asnumpy(Y)# U_cpu = cp.asnumpy(U)# V_cpu = cp.asnumpy(V)# # 显示 Y, U, V 通道的形状,或者将其保存为图像(可选)# print("Y channel shape:", Y_cpu.shape)# print("U channel shape:", U_cpu.shape)# print("V channel shape:", V_cpu.shape)# end_time = time.time()# print("1 " + str(end_time - start_time))# start_time = time.time()# # 将图像转换为 Tensor,并将数据移动到 GPU 上# img_tensor = torch.from_numpy(img_BGR).float().to(device)# end_time = time.time()# print("3 " + str(end_time - start_time))# 将图像数据从 BGR 转换为 YUV# BGR 到 YUV 转换矩阵# bgr_to_yuv_matrix = torch.tensor([# [0.114, 0.587, 0.299],# [-0.169, -0.331, 0.499],# [0.499, -0.419, -0.081]# ], dtype=torch.float32).cuda()# # 进行矩阵乘法,BGR -> YUV# start_time = time.time()# img_yuv_tensor = torch.matmul(img_tensor[..., :3], bgr_to_yuv_matrix.T)# # 分离 Y, U, V 通道# Y_tensor, U_tensor, V_tensor = img_yuv_tensor.split(1, dim=-1)# end_time = time.time()# print("4 " + str(end_time - start_time))# # 将结果从 GPU 移回 CPU# Y_cpu = Y_tensor.cpu().numpy()# U_cpu = U_tensor.cpu().numpy()# V_cpu = V_tensor.cpu().numpy()# # 你也可以保存图像# cv2.imwrite('Y_channel.png', Y_cpu.astype(np.uint8))# 将图像转换为 PyTorch 张量并移至 GPU# img_yuv = torch.tensor(img_BGR).permute(2, 0, 1).unsqueeze(0).float().to('cuda') # (1, 3, H, W)# img = img_yuv# 获取YUV三个通道img_mode = Noneoutput, _ = upsampler.enhance(Y, outscale=args.outscale)if args.ext == 'auto':extension = "png"else:extension = args.extif img_mode == 'RGBA': # RGBA images should be saved in png formatextension = 'png'if args.suffix == '':start_time = time.time()save_path = os.path.join(args.output, f'{idx}.{extension}')# 保存为彩色图像# 创建一个空白的彩色图像h, w = output.shape# 对U和V通道进行resizeresized_U = cv2.resize(U, (w, h))resized_V = cv2.resize(V, (w, h))# 合并resize后的YUV通道img_YUV_OUT = cv2.merge([output, resized_U, resized_V])# # 将图像从YUV颜色空间转换回BGR颜色空间img_BGR_OUT = cv2.cvtColor(img_YUV_OUT, cv2.COLOR_YUV2BGR)frame_resize = cv2.resize(frame_resize, (width, height * 2), 2, 2)# 创建一个空白帧,大小与输入视频相同result_frame = np.zeros((height*2, width*2, 3), dtype=np.uint8)# 将左半部分放置在左边result_frame[:, :width] = frame_resize# 将all_start_time右半部分放置在右边result_frame[:, width:] = img_BGR_OUTresult_frame[:, width:width+1, :] = (255, 255, 255)frame = result_frame# 启动视频播放线程# if idx == 1:# video_thread = threading.Thread(target=play_video)# video_thread.start()# one_all_start_time = time.time()# # 保存合成后的图像# 显示图像cv2.imshow('Image', frame)# 等待用户按键,按任意键继续,按 'q' 键退出if cv2.waitKey(1) & 0xFF == ord('q'):# out.release()break# cv2.imwrite(save_path, img_BGR_OUT)end_time = time.time()print("8 " + str(end_time - start_time))one_all_end_time = time.time()print("One Picture All Time: " + str(one_all_end_time - one_all_start_time))print("-"*60)if one_all_end_time - one_all_start_time < 0.04:time.sleep(0.04 - one_all_end_time + one_all_start_time)print("time.sleep: " + str(0.04 - one_all_end_time + one_all_start_time))# if one_all_end_time - one_all_start_time > 0.04:# delay_time = delay_time + one_all_end_time - one_all_start_time - 0.04one_all_start_time = time.time()cv2.destroyAllWindows()
if __name__ == '__main__':main()utils.py
import cv2
import math
import numpy as np
import os
import queue
import threading
import torch
from basicsr.utils.download_util import load_file_from_url
from torch.nn import functional as F
import timeROOT_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))class RealESRGANer():"""A helper class for upsampling images with RealESRGAN.Args:scale (int): Upsampling scale factor used in the networks. It is usually 2 or 4.model_path (str): The path to the pretrained model. It can be urls (will first download it automatically).model (nn.Module): The defined network. Default: None.tile (int): As too large images result in the out of GPU memory issue, so this tile option will first cropinput images into tiles, and then process each of them. Finally, they will be merged into one image.0 denotes for do not use tile. Default: 0.tile_pad (int): The pad size for each tile, to remove border artifacts. Default: 10.pre_pad (int): Pad the input images to avoid border artifacts. Default: 10.half (float): Whether to use half precision during inference. Default: False."""def __init__(self,scale,model_path,dni_weight=None,model=None,tile=0,tile_pad=10,pre_pad=10,half=False,device=None,gpu_id=None):self.scale = scaleself.tile_size = tileself.tile_pad = tile_padself.pre_pad = pre_padself.mod_scale = Noneself.half = half# initialize modelif gpu_id:self.device = torch.device(f'cuda:{gpu_id}' if torch.cuda.is_available() else 'cpu') if device is None else deviceelse:self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') if device is None else deviceif isinstance(model_path, list):# dniassert len(model_path) == len(dni_weight), 'model_path and dni_weight should have the save length.'loadnet = self.dni(model_path[0], model_path[1], dni_weight)else:# if the model_path starts with https, it will first download models to the folder: weightsif model_path.startswith('https://'):model_path = load_file_from_url(url=model_path, model_dir=os.path.join(ROOT_DIR, 'weights'), progress=True, file_name=None)loadnet = torch.load(model_path, map_location=torch.device('cpu'))# prefer to use params_emaif 'params_ema' in loadnet:keyname = 'params_ema'else:keyname = 'params'model.load_state_dict(loadnet[keyname], strict=True)model.eval()self.model = model.to(self.device)if self.half:self.model = self.model.half()def dni(self, net_a, net_b, dni_weight, key='params', loc='cpu'):"""Deep network interpolation.``Paper: Deep Network Interpolation for Continuous Imagery Effect Transition``"""net_a = torch.load(net_a, map_location=torch.device(loc))net_b = torch.load(net_b, map_location=torch.device(loc))for k, v_a in net_a[key].items():net_a[key][k] = dni_weight[0] * v_a + dni_weight[1] * net_b[key][k]return net_adef pre_process(self, img):"""Pre-process, such as pre-pad and mod pad, so that the images can be divisible"""self.img = torch.from_numpy(img).unsqueeze(0).unsqueeze(0).to(self.device).float() / 255.0# img = torch.from_numpy(img)# self.img = img.unsqueeze(0).to(self.device)if self.half:self.img = self.img.half()# # pre_pad# if self.pre_pad != 0:# self.img = F.pad(self.img, (0, self.pre_pad, 0, self.pre_pad), 'reflect')# mod pad for divisible bordersif self.scale == 2:self.mod_scale = 2# elif self.scale == 1:# self.mod_scale = 4if self.mod_scale is not None:self.mod_pad_h, self.mod_pad_w = 0, 0_, _, h, w = self.img.size()if (h % self.mod_scale != 0):self.mod_pad_h = (self.mod_scale - h % self.mod_scale)if (w % self.mod_scale != 0):self.mod_pad_w = (self.mod_scale - w % self.mod_scale)self.img = F.pad(self.img, (0, self.mod_pad_w, 0, self.mod_pad_h), 'reflect')def process(self):# model inference# self.output = self.model(self.img)# cv2.imwrite("/home/sunyingli/y_channel.jpg", ((self.img[:, 2, :, :].cpu().numpy()*255).astype(np.uint8)[0]))# self.output = self.model(self.img[:, 2, :, :].unsqueeze(1))start_time = time.time()print(self.img.shape)self.output = self.model(self.img[:, :, :, :])end_time = time.time()print("Input_size: " + str(self.img[:, :, :, :].shape))print("Inference Time: ", str(end_time - start_time))# from thop import profile# # 2 相当于只取Y通道# f = open(os.devnull, "w")# import sys# sys.stdout = f# flops, params = profile(self.model, inputs=(self.img[:, 2, :, :].unsqueeze(1),))# sys.stdout = sys.__stdout__# f.close()# # 将FLOPs转换为TOPs,计算精度为32位# tops = flops*24 / 10**12# print("24 frames per second computing power: ")# # 打印结果# print("FLOPs:", flops)# print("TOPs:", tops)# print("Params:", params)# print("-"*60)def tile_process(self):"""It will first crop input images to tiles, and then process each tile.Finally, all the processed tiles are merged into one images.Modified from: https://github.com/ata4/esrgan-launcher"""batch, channel, height, width = self.img.shapeoutput_height = height * self.scaleoutput_width = width * self.scaleoutput_shape = (batch, channel, output_height, output_width)# start with black imageself.output = self.img.new_zeros(output_shape)tiles_x = math.ceil(width / self.tile_size)tiles_y = math.ceil(height / self.tile_size)# loop over all tilesfor y in range(tiles_y):for x in range(tiles_x):# extract tile from input imageofs_x = x * self.tile_sizeofs_y = y * self.tile_size# input tile area on total imageinput_start_x = ofs_xinput_end_x = min(ofs_x + self.tile_size, width)input_start_y = ofs_yinput_end_y = min(ofs_y + self.tile_size, height)# input tile area on total image with paddinginput_start_x_pad = max(input_start_x - self.tile_pad, 0)input_end_x_pad = min(input_end_x + self.tile_pad, width)input_start_y_pad = max(input_start_y - self.tile_pad, 0)input_end_y_pad = min(input_end_y + self.tile_pad, height)# input tile dimensionsinput_tile_width = input_end_x - input_start_xinput_tile_height = input_end_y - input_start_ytile_idx = y * tiles_x + x + 1input_tile = self.img[:, :, input_start_y_pad:input_end_y_pad, input_start_x_pad:input_end_x_pad]# upscale tiletry:with torch.no_grad():output_tile = self.model(input_tile)except RuntimeError as error:print('Error', error)print(f'\tTile {tile_idx}/{tiles_x * tiles_y}')# output tile area on total imageoutput_start_x = input_start_x * self.scaleoutput_end_x = input_end_x * self.scaleoutput_start_y = input_start_y * self.scaleoutput_end_y = input_end_y * self.scale# output tile area without paddingoutput_start_x_tile = (input_start_x - input_start_x_pad) * self.scaleoutput_end_x_tile = output_start_x_tile + input_tile_width * self.scaleoutput_start_y_tile = (input_start_y - input_start_y_pad) * self.scaleoutput_end_y_tile = output_start_y_tile + input_tile_height * self.scale# put tile into output imageself.output[:, :, output_start_y:output_end_y,output_start_x:output_end_x] = output_tile[:, :, output_start_y_tile:output_end_y_tile,output_start_x_tile:output_end_x_tile]def post_process(self):# remove extra padif self.mod_scale is not None:_, _, h, w = self.output.size()self.output = self.output[:, :, 0:h - self.mod_pad_h * self.scale, 0:w - self.mod_pad_w * self.scale]# remove prepadif self.pre_pad != 0:_, _, h, w = self.output.size()self.output = self.output[:, :, 0:h - self.pre_pad * self.scale, 0:w - self.pre_pad * self.scale]return self.output@torch.no_grad()def enhance(self, img, outscale=None, alpha_upsampler='realesrgan'):# start_time = time.time()# # img: numpy# img = img.astype(np.float16)# max_range = 255# img = img / max_rangeimg_mode = 'RGB'# img = np.expand_dims(img, axis=0)# end_time = time.time()# print("3 " + str(end_time - start_time))# ------------------- process image (without the alpha channel) ------------------- #start_time = time.time()self.pre_process(img)end_time = time.time()print("4 " + str(end_time - start_time))if self.tile_size > 0:self.tile_process()else:start_time = time.time()self.process()end_time = time.time()print("4 " + str(end_time - start_time))start_time = time.time()output_img = self.post_process()end_time = time.time()print("5 " + str(end_time - start_time))start_time = time.time()# output_img = output_img.data.squeeze().float().cpu().clamp_(0, 1).numpy()output_img = output_img.data[0].clamp_(0, 1)*255output = output_img.round().to(torch.uint8).cpu().numpy()[0]end_time = time.time()print("6 " + str(end_time - start_time))# ------------------------------ return ------------------------------ ## start_time = time.time()# output = (output_img * 255.0).round().astype(np.uint8)# end_time = time.time()# print("7 " + str(end_time - start_time))return output, img_modeclass PrefetchReader(threading.Thread):"""Prefetch images.Args:img_list (list[str]): A image list of image paths to be read.num_prefetch_queue (int): Number of prefetch queue."""def __init__(self, img_list, num_prefetch_queue):super().__init__()self.que = queue.Queue(num_prefetch_queue)self.img_list = img_listdef run(self):for img_path in self.img_list:img = cv2.imread(img_path, cv2.IMREAD_UNCHANGED)self.que.put(img)self.que.put(None)def __next__(self):next_item = self.que.get()if next_item is None:raise StopIterationreturn next_itemdef __iter__(self):return selfclass IOConsumer(threading.Thread):def __init__(self, opt, que, qid):super().__init__()self._queue = queself.qid = qidself.opt = optdef run(self):while True:msg = self._queue.get()if isinstance(msg, str) and msg == 'quit':breakoutput = msg['output']save_path = msg['save_path']cv2.imwrite(save_path, output)print(f'IO worker {self.qid} is done.')
3. PC端多线程加速( I/O 密集型任务)
PC端 多线程加速( I/O 密集型任务)和 多进程加速(CPU 密集型任务)
Python 多线程
1. 适合 I/O 密集型任务
多线程在 I/O 密集型任务(如文件读写、网络请求、数据库访问等)可显著提高程序性能。
多线程可以在 I/O 等待时间内可以执行其他任务。
即使 GIL(全局解释器锁) 限制了 CPU 密集型任务的并发性,多线程在 I/O 密集型任务中, 可以在等待 I/O 操作的同时让其他线程继续运行。
2. 共享内存, 共享变量
所有线程共享同一进程的内存空间,内存消耗较少。
线程间的数据交换和共享(直接共享变量)。
3. 受 GIL(全局解释器锁) 影响,不适合 CPU 密集型任务
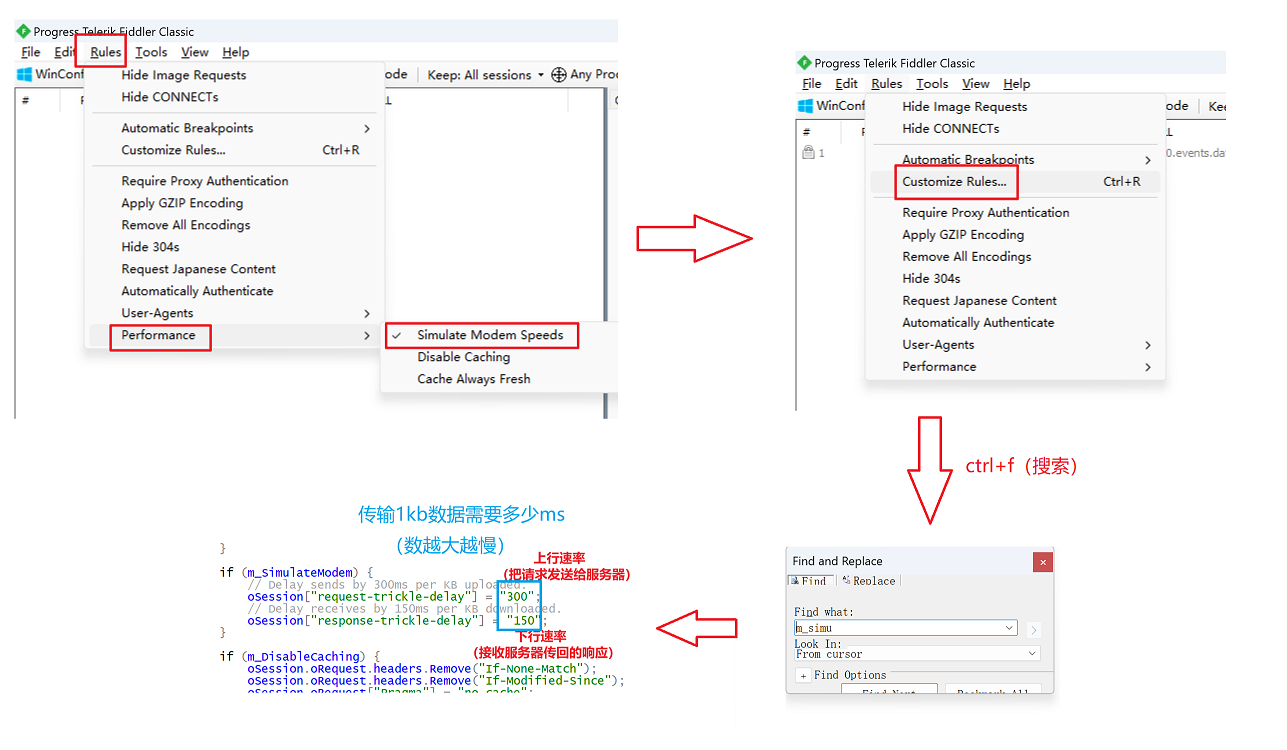
下面为实现的python代码,对于频繁的cv2.imshow,确实可提升整体帧率。
import argparse
import os
# os.add_dll_directory(r'D:\CUDA\CUDA02\bin')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_img_hash460.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_img_hash460d.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_world460.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_world460d.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin')import cv2
import time
import threading
import queue
import argparse
import os
from basicsr.archs.rrdbnet_arch import RRDBNet
from realesrgan import RealESRGANerdef process_image(q, args):args.model_name = args.model_name.split('.')[0]if args.model_name == 'RealESRGAN_x2plus': # x2 RRDBNet modelmodel = RRDBNet(num_in_ch=1, num_out_ch=1, num_feat=32, num_block=1, num_grow_ch=16, scale=2)netscale = 2if args.model_path is not None:model_path = args.model_pathelse:model_path = os.path.join('weights', args.model_name + '.pth')dni_weight = Noneupsampler = RealESRGANer(scale=netscale,model_path=model_path,dni_weight=dni_weight,model=model,tile=args.tile,tile_pad=args.tile_pad,pre_pad=args.pre_pad,half=not args.fp32,gpu_id=args.gpu_id)os.makedirs(args.output, exist_ok=True)cap = cv2.VideoCapture(args.input)while cap.isOpened():ret, frame = cap.read()if not ret:breakimg_yuv = cv2.cvtColor(frame, cv2.COLOR_BGR2YUV)Y, U, V = cv2.split(img_yuv)output, _ = upsampler.enhance(Y, outscale=args.outscale)h, w = output.shaperesized_U = cv2.resize(U, (w, h))resized_V = cv2.resize(V, (w, h))img_YUV_OUT = cv2.merge([output, resized_U, resized_V])img_BGR_OUT = cv2.cvtColor(img_YUV_OUT, cv2.COLOR_YUV2BGR)q.put(img_BGR_OUT)print("Processed frame and added to queue")def display_image(q):idx = 0all_start_time = Nonewhile True:if not q.empty():start_time = time.time()img_BGR_OUT = q.get()cv2.imshow('Image', img_BGR_OUT)idx += 1if idx == 1:all_start_time = time.time()if cv2.waitKey(1) & 0xFF == ord('q'):breakend_time = time.time()print("Display time for this frame: " + str(end_time - start_time))print("------------------------------------ Frame rate: " + str(idx / (time.time() - all_start_time)))else:time.sleep(0.001)cv2.destroyAllWindows()def main():"""Inference demo for Real-ESRGAN."""parser = argparse.ArgumentParser()parser.add_argument('-i', '--input', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\real\穆桂英挂帅_李胜素_整装待发_发兵出征_1080P.mp4', help='Input Video')parser.add_argument('-n','--model_name',type=str,default='RealESRGAN_x2plus')parser.add_argument('-o', '--output', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\weights\4K_Cartoon_Y_2X', help='Output folder')parser.add_argument('-dn','--denoise_strength',type=float,default=0.5)parser.add_argument('-s', '--outscale', type=float, default=2, help='The final upsampling scale of the image')parser.add_argument('--model_path', type=str, default=R"C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\weights\32_1_16_pairdata_0929_animal_net_g_345000_39.2444.pth")parser.add_argument('--suffix', type=str, default='', help='Suffix of the restored image')parser.add_argument('-t', '--tile', type=int, default=0, help='Tile size, 0 for no tile during testing')parser.add_argument('--tile_pad', type=int, default=10, help='Tile padding')parser.add_argument('--pre_pad', type=int, default=0, help='Pre padding size at each border')parser.add_argument('--face_enhance', action='store_true', help='Use GFPGAN to enhance face')parser.add_argument('--fp32', action='store_true')parser.add_argument('--alpha_upsampler',type=str,default='realesrgan')parser.add_argument('--ext',type=str,default='auto',)parser.add_argument('-g', '--gpu-id', type=int, default=0)args = parser.parse_args()q = queue.Queue()thread1 = threading.Thread(target=process_image, args=(q, args))thread2 = threading.Thread(target=display_image, args=(q,))thread1.start()thread2.start()thread1.join()thread2.join()if __name__ == '__main__':main()Python 多进程
1. 高效的 CPU 密集型任务
多进程适合处理 CPU 密集型任务,如复杂的数学运算、数据分析、图像处理等。
多进程可以绕过 Python 中的 GIL,因为每个进程都有独立的内存空间和 Python 解释器实例。
多进程因此可以充分利用多核 CPU 的性能,使得 CPU 密集型任务可以并行处理。
2. 进程间通信复杂:
多进程间无法直接共享内存,需要使用 IPC(进程间通信)机制,例如管道(Pipe)、队列(Queue)、共享内存(Shared Memory)等方式来交换数据。
3. 内存消耗大、启动和管理开销高
多进程实现, 不适合I/O密集任务,进程间通信代价大,速度并未满足要求。
import argparse
import os
# os.add_dll_directory(r'D:\CUDA\CUDA02\bin')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_img_hash460.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_img_hash460d.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_world460.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_world460d.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin')import cv2
print(f'OpenCV: {cv2.__version__} for python installed and working')
import glob
from basicsr.archs.rrdbnet_arch import RRDBNet
from basicsr.utils.download_util import load_file_from_urlfrom realesrgan import RealESRGANer
from realesrgan.archs.srvgg_arch import SRVGGNetCompact
import numpy as np
import time
import multiprocessing as mpdef process_image(queue, args):# determine models according to model namesargs.model_name = args.model_name.split('.')[0]if args.model_name == 'RealESRGAN_x2plus': # x2 RRDBNet modelmodel = RRDBNet(num_in_ch=1, num_out_ch=1, num_feat=32, num_block=1, num_grow_ch=16, scale=2)netscale = 2# determine model pathsif args.model_path is not None:model_path = args.model_pathelse:model_path = os.path.join('weights', args.model_name + '.pth')# use dni to control the denoise strengthdni_weight = None# restorerupsampler = RealESRGANer(scale=netscale,model_path=model_path,dni_weight=dni_weight,model=model,tile=args.tile,tile_pad=args.tile_pad,pre_pad=args.pre_pad,half=not args.fp32,gpu_id=args.gpu_id)os.makedirs(args.output, exist_ok=True)if os.path.isfile(args.input):paths = [args.input]else:paths = sorted(glob.glob(os.path.join(args.input, '*')))cap = cv2.VideoCapture(args.input)while cap.isOpened():start_time = time.time()ret, frame = cap.read()if not ret:break# 图像处理: BGR 到 YUV 转换img_yuv = cv2.cvtColor(frame, cv2.COLOR_BGR2YUV)Y, U, V = cv2.split(img_yuv)# 提交任务给上采样进程output, _ = upsampler.enhance(Y, outscale=args.outscale)# 图像重采样h, w = output.shaperesized_U = cv2.resize(U, (w, h))resized_V = cv2.resize(V, (w, h))img_YUV_OUT = cv2.merge([output, resized_U, resized_V])img_BGR_OUT = cv2.cvtColor(img_YUV_OUT, cv2.COLOR_YUV2BGR)queue.put(img_BGR_OUT)# queue.put((output, resized_U, resized_V))# end_time = time.time()# if end_time - start_time < 0.04:# time.sleep(0.04 - end_time + start_time)end_time = time.time()print("----------- process_image ------------- " + str(end_time - start_time))def display_image(queue):idx = 0while True:if queue.qsize() < 24:start_time = time.time()img_BGR_OUT = queue.get()# 合并通道并转换# 显示图像cv2.imshow('Image', img_BGR_OUT)idx += 1if idx == 1:all_start_time = time.time()# 如果按下 'q' 键则退出if cv2.waitKey(1) & 0xFF == ord('q'):breakend_time = time.time()print("----------- display_image ------------- " + str(end_time - start_time))print("---------------------- 帧率 ---------------------- " + str(idx / (time.time() - all_start_time)))else:# 如果队列为空,稍微等待一下,避免CPU空转time.sleep(0.001)def main():"""Inference demo for Real-ESRGAN."""parser = argparse.ArgumentParser()parser.add_argument('-i', '--input', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\real\穆桂英挂帅_李胜素_整装待发_发兵出征_1080P.mp4', help='Input Video')parser.add_argument('-n','--model_name',type=str,default='RealESRGAN_x2plus')parser.add_argument('-o', '--output', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\weights\4K_Cartoon_Y_2X', help='Output folder')parser.add_argument('-dn','--denoise_strength',type=float,default=0.5)parser.add_argument('-s', '--outscale', type=float, default=2, help='The final upsampling scale of the image')parser.add_argument('--model_path', type=str, default=R"C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\weights\32_1_16_pairdata_0929_animal_net_g_345000_39.2444.pth")parser.add_argument('--suffix', type=str, default='', help='Suffix of the restored image')parser.add_argument('-t', '--tile', type=int, default=0, help='Tile size, 0 for no tile during testing')parser.add_argument('--tile_pad', type=int, default=10, help='Tile padding')parser.add_argument('--pre_pad', type=int, default=0, help='Pre padding size at each border')parser.add_argument('--face_enhance', action='store_true', help='Use GFPGAN to enhance face')parser.add_argument('--fp32', action='store_true')parser.add_argument('--alpha_upsampler',type=str,default='realesrgan')parser.add_argument('--ext',type=str,default='auto',)parser.add_argument('-g', '--gpu-id', type=int, default=0)args = parser.parse_args()# 通过 Queue 在进程之间传递数据queue = mp.Queue()# 创建多进程process1 = mp.Process(target=process_image, args=(queue, args))process2 = mp.Process(target=display_image, args=(queue,))# 启动进程process1.start()process2.start()# 等待进程结束process1.join()process2.join()cv2.destroyAllWindows()if __name__ == '__main__':main()多线程优化版
避免速度差异导致内存占用过多。
if q.qsize() > 30:time.sleep(0.025)
推理代码如下;
import argparse
import os
# os.add_dll_directory(r'D:\CUDA\CUDA02\bin')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_img_hash460.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_img_hash460d.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_world460.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin\opencv_world460d.dll')
os.add_dll_directory(R'C:\Users\kk\Downloads\opencv_contrib_cuda_4.6.0.20221106_win_amd64\install\x64\vc17\bin')import cv2
import time
import threading
import queue
import argparse
import os
from basicsr.archs.rrdbnet_arch import RRDBNet
from realesrgan import RealESRGANerdef process_image(q, args):args.model_name = args.model_name.split('.')[0]if args.model_name == 'RealESRGAN_x2plus': # x2 RRDBNet modelmodel = RRDBNet(num_in_ch=1, num_out_ch=1, num_feat=32, num_block=1, num_grow_ch=16, scale=2)netscale = 2if args.model_path is not None:model_path = args.model_pathelse:model_path = os.path.join('weights', args.model_name + '.pth')dni_weight = Noneupsampler = RealESRGANer(scale=netscale,model_path=model_path,dni_weight=dni_weight,model=model,tile=args.tile,tile_pad=args.tile_pad,pre_pad=args.pre_pad,half=not args.fp32,gpu_id=args.gpu_id)os.makedirs(args.output, exist_ok=True)cap = cv2.VideoCapture(args.input)while cap.isOpened():start_time = time.time()ret, frame = cap.read()if not ret:breakimg_yuv = cv2.cvtColor(frame, cv2.COLOR_BGR2YUV)Y, U, V = cv2.split(img_yuv)output, _ = upsampler.enhance(Y, outscale=args.outscale)if q.qsize() > 30:time.sleep(0.025)q.put((output, U, V))print("Processed frame and added to queue")end_time = time.time()print("------Processed time for this frame: " + str(end_time - start_time))def display_image(q):idx = 0all_start_time = Nonewhile True:if not q.empty():start_time = time.time()# 获取图像的尺寸output, U, V = q.get()h, w = output.shaperesized_U = cv2.resize(U, (w, h), interpolation=cv2.INTER_CUBIC)resized_V = cv2.resize(V, (w, h), interpolation=cv2.INTER_CUBIC)img_YUV_OUT = cv2.merge([output, resized_U, resized_V])img_BGR_OUT = cv2.cvtColor(img_YUV_OUT, cv2.COLOR_YUV2BGR)cv2.imshow('Image', img_BGR_OUT)idx += 1if idx == 1:all_start_time = time.time()if cv2.waitKey(1) & 0xFF == ord('q'):breakend_time = time.time()print("------Display time for this frame: " + str(end_time - start_time))print("------------------------------------------------------------------------ Frame rate: " + str(idx / (time.time() - all_start_time)))else:time.sleep(0.001)cv2.destroyAllWindows()def main():"""Inference demo for Real-ESRGAN."""parser = argparse.ArgumentParser()parser.add_argument('-i', '--input', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\real\穆桂英挂帅_李胜素_整装待发_发兵出征_1080P.mp4', help='Input Video')parser.add_argument('-n','--model_name',type=str,default='RealESRGAN_x2plus')parser.add_argument('-o', '--output', type=str, default=R'C:\Users\kk\Downloads\Real-ESRGAN-master\weights\4K_Cartoon_Y_2X', help='Output folder')parser.add_argument('-dn','--denoise_strength',type=float,default=0.5)parser.add_argument('-s', '--outscale', type=float, default=2, help='The final upsampling scale of the image')parser.add_argument('--model_path', type=str, default=R"C:\Users\kk\Downloads\Real-ESRGAN-master\inputs\weights\32_1_16_pairdata_0929_animal_net_g_345000_39.2444.pth")parser.add_argument('--suffix', type=str, default='', help='Suffix of the restored image')parser.add_argument('-t', '--tile', type=int, default=0, help='Tile size, 0 for no tile during testing')parser.add_argument('--tile_pad', type=int, default=10, help='Tile padding')parser.add_argument('--pre_pad', type=int, default=0, help='Pre padding size at each border')parser.add_argument('--face_enhance', action='store_true', help='Use GFPGAN to enhance face')parser.add_argument('--fp32', action='store_true')parser.add_argument('--alpha_upsampler',type=str,default='realesrgan')parser.add_argument('--ext',type=str,default='auto',)parser.add_argument('-g', '--gpu-id', type=int, default=0)args = parser.parse_args()q = queue.Queue()thread1 = threading.Thread(target=process_image, args=(q, args))thread2 = threading.Thread(target=display_image, args=(q,))thread1.start()thread2.start()thread1.join()thread2.join()if __name__ == '__main__':main()4. 最终实现效果:在康佳 4090 设备上,实现了1080P实时超分。
二. 精简模型:
近一周作了大量尝试:
1. 像素重排到16通道。
发现最后一层通道 16→1 时,Mac利用率小于1%, 时间花费爆炸。
2. 不使用像素重拍。
输入卷积层的通道数为1。导致H*W过大,而RK3588通道是32对齐的。
如果通道C满足32对齐,则导致计算量非常大;
如果通道C较小,则导致Mac利用率过低;

3. 将 PixelUnshuffle 和 PixelShuffle 使用卷积和转置卷积替换,经训练后,确认成功。
# 使得 pixel_unshuffle (reshape, transpose, reshape) CPU 运行# 转移到 NPU 上运行卷积self.pixel_unshuffle = nn.Conv2d(num_in_ch // (self.scale ** 2),num_in_ch,kernel_size=self.scale, stride=self.scale, padding=0, bias=False)# 使用转置卷积实现 pixel_shuffle 的效果self.pixel_shuffle = nn.ConvTranspose2d(num_in_ch,num_in_ch // (self.scale ** 2),kernel_size=(self.scale),stride=(self.scale),padding=0, bias=False)
4. 去除不必要的 Add, Max 操作,经训练后,确认成功。
5. 精简 concat 数量,经训练后,确认成功。
6. 所以尝试将最后一层,在 CPU 上执行。
原因: RK3588输出通道越大,Mac利用率越高。但是我们超分后的结果,输出通道必须要<=3。

所以尝试将最后一层,在 CPU 上执行。
实际效果:
通过 pubin11 实现 python 调用 C++ 加速操作。最终结果是CPU内存占用大,且时间花费多,未能满足要求。


7. 最终效果:得到两种更轻量化的超分模型,目前正在训练中。

其他:
- 下载 4K 视频,为第三方检测作准备。
- 安装 cv2 的 cuda 版本, 但数据要在CPU GPU上频繁传输,受限于数据传输速度,总体速度反而变慢了。(花费时间较长)
- RK3588 内存零拷贝,但调研结果速度差异不大。