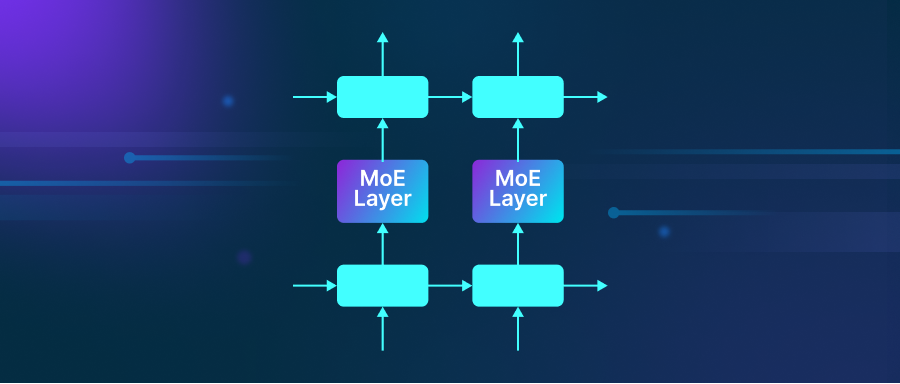
假设一个专家团队共同解决复杂问题。每位专家都拥有独特的技能,团队通过高效分配任务实现了前所未有的成功。这就是混合专家(Mixture-of-Experts,MoE)模型架构背后的基本思想,这种方法允许机器学习系统,特别是神经网络,高效扩展。MoE 不是让一个单一的神经网络处理所有任务,而是将工作分配给多个专门的“专家”,由一个门控网络决定针对每不同输入激活哪些专家。
随着模型变得越来越大、越来越复杂,保持效率和准确性成为最大挑战,尤其是在自然语言处理(NLP)和大型语言模型(LLM)领域中参数扩展到数十亿甚至数万亿的局面下。传统模型对每个输入都激活神经网络中的所有层和神经元,计算成本巨大,减慢了推理速度,并消耗大量内存。在追求速度和可扩展性的实际应用中部署如此庞大的模型是一项艰巨的任务。
混合专家通过一次只激活一小部分专家来解决这个问题,从而在不牺牲性能的情况下减少计算开销。在 MoE 中,这种协作方法在 NLP 和像 OpenAI GPT 这样的 LLM 中变得越来越重要,这些模型需要在保持效率和准确性的同时扩展到数十亿参数。
本文将介绍 MoE 的核心概念、LLM、训练、推理以及 MoE 在现代 AI 模型中的作用。
01.
MoE 的定义及核心概念
简而言之,混合专家(Mixture of Experts,MoE)是一种先进的神经网络架构,它通过动态选择专门的子模型或“专家”来处理输入的不同部分,以提高模型的效率和可扩展性。这个概念可以类比为劳动分工,每个专家专注于某个大问题中的特定一小部分任务,从而生成更快、更准确的结果。
混合专家模型由三个关键组件组成:
专家(Experts):专门针对特定任务的子模型。
门控网络(Gating Network):一个选择器,它将输入数据路由到相关的专家。
稀疏激活(Sparse Activation):只有少数专家针对每个输入被激活的方法,优化了计算效率。
1.1 专家
在 MoE 架构中,专家是指训练好的子网络(神经网络或层),它们专门处理特定的数据或任务。例如,在图像分类任务中,一个专家可能专门识别纹理,而另一个专家可能识别边缘或形状。这种分工有助于整个模型更高效地处理问题,因为每个专家只处理它最适合的数据类型。
1.2 门控网络或路由器
门控网络充当一个选择器,它决定将哪些输入数据发送给哪些专家。不是所有专家都同时工作,而是门控网络将数据路由到最相关的专家那里。类似于 token 选择路由策略,路由算法为每个 token 选择最佳的一个或两个专家。例如,在下图中,输入令牌 1,“我们”,被发送到第二个专家,而输入令牌 2,“喜欢”,被发送到第一个网络。
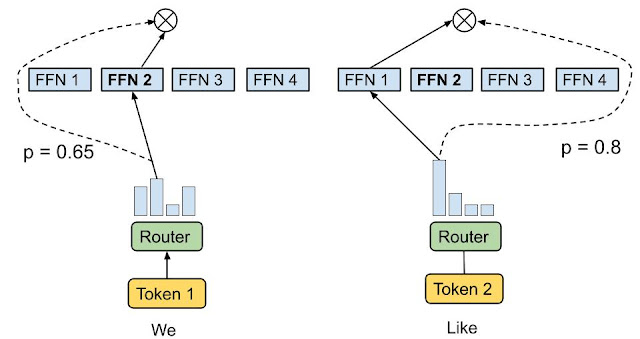
Token 选择路由(来源:https://research.google/blog/mixture-of-experts-with-expert-choice-routing/)
以下是一些主流的Token 路由技术:
Top-k 路由:这是最简单的方法。门控网络选择亲和力得分(affinity score)最高的 top k 个专家,并将输入数据发送给它们。
专家选择路由:与根据数据选择专家不同,这种方法由专家决定它们最能处理哪些数据。这种策略旨在实现最佳的负载均衡,并支持以多种方式将数据映射到专家。
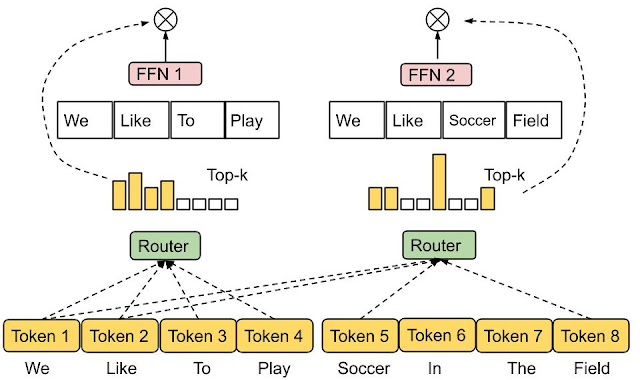
专家选择路由(来源:https://research.google/blog/mixture-of-experts-with-expert-choice-routing/)
1.3 稀疏激活
稀疏激活是 MoE 模型的关键部分和优势之一。与所有专家或参数对输入都活跃的密集模型不同,稀疏激活确保只有一小部分专家根据输入数据被激活。这种方法在保持性能的同时减少了计算需求,因为任何时候只有最相关的专家是活跃的。
稀疏路由:稀疏激活的一种特定技术,其中门控网络针对每个输入只激活少数专家。
02.
MoE 在深度学习中的历史演变
MoE 的来自于 1991 年的论文《Adaptive Mixture of Local Experts》(https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf)。这篇论文引入了将复杂问题分解为子问题并分配给多个专门模型的思想。这种分而治之的策略成为了 MoE 架构的核心。
接下来,两个关键研究领域进一步塑造了 MoE 的演变:
专家作为组件(Experts as components):最初,MoE 被应用于支持向量机(Support Vector Machines,SVM)和高斯过程(Gaussian Processes)等模型中。然而,Eigen、Ranzato 和 Ilya 的研究通过将 MoE 集成为深度神经网络中的组件,使它们能够作为更大模型中的层来运作,扩展了这种方法。
条件计算:传统的神经网络处理通过所有层处理输入,但 Yoshua Bengio 的研究引入了条件计算,根据输入选择性地激活或停用网络组件。这种动态方法提升了计算效率,因为每个输入只使用了模型中必要的部分。
2.2 大规模 NLP 模型中的 MoE:GShard 和 Switch Transformer
MoE 对自然语言处理(NLP)的影响随着 GShard 和 Switch Transformer 等模型的出现而得到巩固。2021 年,谷歌的 Switch Transformer 模型拥有 1.6 万亿参数,证明了 MoE 能够处理需要大量计算资源的任务。通过每个输入只激活少数专家,模型在参数数量增长的同时保持了效率。
另一个重要的里程碑是在 2017 年,Shazeer 等人引入了稀疏门控混合专家层(Sparsely Gated Mixture-of-Experts Layer),实现深度学习中的稀疏激活。这使得模型能够通过高达 1370 亿参数处理机器翻译等任务,同时通过每个输入只激活最相关的专家来维持较低的推理成本。
2.3 不只 NLP:视觉和多模态模型中的 MoE
MoE 不仅限于 NLP 领域。例如,谷歌的 V-MoE 架构使用稀疏 MoE 框架进行计算机视觉任务,使用视觉变换器(Vision Transformers,ViT)进行图像分类,并实现专家架构。这允许我们像扩展文本模型一样扩展图像模型。
随着研究的进一步发展,MoE 越来越多应用到不同领域的复杂任务中。MoE 成为了现代 AI 架构中的重要基石,是深度学习中更高效、可扩展的解决方法。
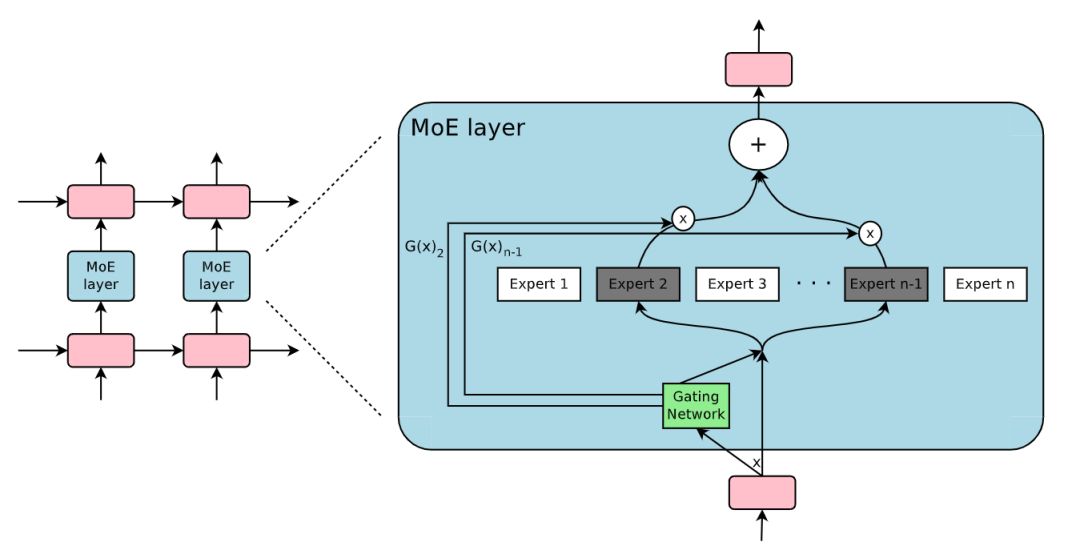
MoE 层 (来源:https://arxiv.org/pdf/1701.06538)
03.
详解 MoE 架构及原理
MoE 系统主要分为两个流程:
训练(Training)
推理(Inference)
3.1 训练
像其他机器学习模型一样,MoE 模型从数据中学习,但它们的训练过程是独特的。MoE 不是将整个模型作为一个单一实体进行训练,而是专注于分别训练其各个组成部分——专家和门控网络。通过这种方式,每个专家可以专门处理指定的任务,而门控网络学会有效地将输入路由到适当的专家。
3.1.1 专家训练
MoE 模型中的每个专家被视为一个单独的神经网络,并在数据或任务的子集上进行训练。每个专家的训练遵循标准的神经网络训练过程,最小化其特定数据子集的损失函数。
例如,在自然语言处理模型中,一个专家可能在正式文件数据集上进行训练,以专用于处理正式语言。相比之下,另一个可能在社交媒体对话上进行训练,以精通非正式交流表达。这种个性化训练使专家能够在其特定领域变得高度熟练。
3.1.2 门控网络训练
门控网络充当决策者,为给定输入选择最合适的专家。它与专家网络一起训练,但扮演不同的角色。门控网络的输入与整个模型输入的数据相同,可以包括文本、图像或任何基于模型任务的输入。门控网络的输出是一个概率分布,指示哪个或哪些专家最适合处理当前输入。
门控网络的训练通常是监督式的,在训练阶段提供标记数据。门控网络学会根据提供的标签对输入进行分类,并将其分配给正确的专家。在训练期间,门控网络被优化以准确选择专家,并提高 MoE 模型的整体性能。
3.1.3 联合训练
在联合训练阶段,整个 MoE 系统,包括专家模型和门控网络,都进行训练。这种策略确保门控网络和专家能够和谐工作。联合训练中的损失函数结合了各个专家和门控网络的损失,确保两个组成部分都有助于整体性能。
然后,组合的损失梯度通过门控网络和专家模型传播,促进更新,以提高 MoE 系统的性能。
3.2 推理阶段
在推理过程中,门控网络接收输入并选择最有可能提供正确输出的 top k 个专家。被选中的专家处理输入并生成它们的预测,然后将这些预测组合起来产生最终输出。与全连接模型相比,这种选择性激活专家的方式允许 MoE 以较低的计算成本进行预测。
04.
稀疏激活的力量
MoE的一个关键优势在于其使用稀疏激活,这源自于条件计算的概念。与传统的“密集”模型不同,所有参数不会对每个输入都激活,MoE 有选择地只激活必要的网络部分。这种方法提供了几个好处:
效率:MoE 模型可以通过只激活最相关的专家来处理大量数据,从而使用更少的计算资源。这对于像 NLP 中使用的大规模模型尤其重要,这些模型的处理时间和内存需求可能迅速变得过高。一个显著的例子是 Mistral 8x7B——一个高质量的稀疏混合专家模型(SMoE),它使用具有八个专家的 MoE 框架。每个专家有 110 亿参数和 550 亿共享注意力参数,每个模型总计 1660 亿参数。有趣的是,在推理过程中,每个 token 只使用两个专家,使 AI 处理过程更加高效和专注。
负载均衡:稀疏激活的一个重要考虑因素是确保所有专家都得到充分的训练。如果只有少数专家被门控网络激活,它们可能变得过度专业化,而其他专家则未被充分利用。为了防止这种不平衡,现代 MoE 使用了诸如 Noisy Top-k Gating 等技术,Shazeer等人(2017年)添加了少量(可调的)噪声到专家选择过程中,确保所有专家之间的训练分布更加平衡。
05.
MoE 对比传统模型的优势及挑战
5.1 优势
混合专家(MoE)架构相比传统深度学习模型提供了几个优势:
更高可扩展性:凭借稀疏激活,MoE 模型可以轻松扩展到数十亿甚至数万亿参数,从而减少对巨大计算能力的需求。
更灵活:MoE 的一个好处是可以在不重新训练整个系统的情况下向现有模型添加新专家。这种灵活性允许模型轻松适应新任务和领域。
更高效率:由于 MoE 仅对每个输入激活最相关的专家,它能够比传统模型更有效地处理多样化任务。这使得它更快、更准确,因为专家可以专注于他们最擅长的事情。
并行处理:专家可以独立工作,从而实现高效的并行处理。这种方法可以缩短训练和推理时间。
5.2 挑战
尽管MoE模型具有上述优势,但也存在某些挑战和局限性。
训练复杂性:训练MoE模型可能具有挑战性,特别是在管理门控网络和平衡各个专家的贡献方面。重要的是要确保门控网络学会有效地给专家分配适当的权重,这可以防止过度拟合或未充分利用特定专家。
通信成本:MoE 模型在训练和推理期间需要大量的基础设施资源,这是因为模型需要管理多个专家和门控机制。此外,当在大规模部署时,尤其是在各种设备或分布式系统之间部署,通信开销是一个主要挑战。协调和同步来自不同服务器上不同专家的输出可能导致延迟和计算负载的增加。
专家容量:为了防止特定专家过载并确保工作负载平衡,对每个专家可以同时处理的输入数量设置了阈值。一种常见的方法是使用 top-2 路由和 1.25 的容量因子,这意味着每个输入选择两个专家,每个专家处理其通常容量的 1.25 倍。这种策略还为每个核心分配一个专家,优化性能和资源管理。
透明度:不透明已经是 AI 中的一个显著问题,包括对于 LLM。MoE 模型可能会加剧这一问题,因为它们更加复杂。我们不仅要看一个模型如何做出决策,还必须弄清楚不同的专家和门控系统如何协同工作。这种额外的复杂性可能让我们更难以理解为何模型做出特定选择。
06.
MoE 应用
MoE 已经被广泛应用于多种应用中。
自然语言处理:MoE 模型非常适合翻译、情感分析和问答等语言任务,因为它可以将每个任务分配给专家。例如,OpenAI 的 GPT-4 据称采用了具有16个专家的 MoE 架构(尽管 OpenAI 尚未官方确认其设计细节)。另一个例子是微软的翻译 API,Z-code。Z-code 中的 MoE 架构允许模型在保持相同计算能力的同时支持大规模的模型参数。
计算机视觉:谷歌的 V-MoEs 是一种基于视觉变换器(Vision Transformers, ViT)的稀疏架构,展示了 MoE 在计算机视觉任务中的有效性。MoE 模型可以通过将不同任务分配给专门的专家来帮助图像处理。例如,一个专家可能专注于某些类型的物体、特定的视觉特征或图像的其他部分。
多模态学习:MoE 可以将来自多个来源的数据,如文本、图像和音频,整合到一个模型中。这使得 MoE 非常适合多模态搜索或内容推荐等应用,这些应用需要整合不同模态的数据。
07.
MoE 的未来方向
在未来几年中,MoE 的研究将集中在使模型更高效、更易于理解上。这包括改进专家如何协同工作,以及寻找更好的方法将任务分配给正确的专家。
进一步扩展:MoE模型可以扩展到更大的规模,同时最小化计算成本。这包括优化训练和推理阶段以处理不断增加的专家和数据规模。当前正在探索如分布式计算等技术,以更高效地将任务分布在多台机器上,减少瓶颈并加快模型的运行速度。
创新的路由机制:另一个研究领域集中在开发更高效的路由策略上。虽然像 top-k 路由这样的现有方法被普遍使用,但高级技术如专家选择路由(Expert Choice Routing)可以改进任务分配给专家的过程。这可以实现更高效的负载平衡并改进任务和专家的匹配程度,确保模型在不同条件下都能以最佳状态运行。
现实世界的应用:MoE模型在现实世界的应用中具有巨大潜力,如医疗保健和自动驾驶系统,因为它们能够处理复杂任务。在医疗保健领域,它们可以用于个性化治疗方案,而自动驾驶系统可以利用它们进行物体识别和决策。
08.
总结
Mixture-of-Experts(MoE)是一种强大的模型架构,它通过将任务分配给专门的专家,使神经网络能够高效地扩展。具有稀疏激活的 MoE 模型能够以较低的计算成本处理大规模数据集和复杂任务。尽管 MoE 在训练复杂性和通信成本方面确实存在挑战,但它在可扩展性、灵活性和效率方面的优势使其成为现代 AI 应用中越来越受欢迎的选择。从自然语言处理到计算机视觉和多模态任务,MoE 模型通过让专家在不同领域处理专门的任务,提高了模型速度和准确性。
更多资源
Enhancing ChatGPT with Milvus (https://zilliz.com/learn/enhancing-chatgpt-with-milvus)
Top 10 Best Multimodal AI Models You Should Know (https://zilliz.com/learn/top-10-best-multimodal-ai-models-you-should-know)
Multimodal Retrieval-Augmented Generation (RAG) (https://zilliz.com/learn/multimodal-RAG)
Getting Started with LLMOps: Building Better AI Applications (https://zilliz.com/blog/get-started-with-llmops-build-better-ai-applications)
What is a Vector Database and How Does It Work? (https://zilliz.com/learn/what-is-vector-database)
Build AI Apps with Retrieval Augmented Generation (RAG) (https://zilliz.com/learn/Retrieval-Augmented-Generation)
What Are AI Agents? What You Need to Know (https://zilliz.com/glossary/ai-agents)
CLIP Object Detection: Merging AI Vision with Language Understanding (https://zilliz.com/learn/CLIP-object-detection-merge-AI-vision-with-language-understanding)
How to build a Retrieval-Augmented Generation (RAG) system using Llama3 and Milvus (https://zilliz.com/learn/how-to-build-rag-system-using-llama3-ollama-dspy-milvus)
本文作者:Haziqa Sajid
推荐阅读

















![Vulnhub靶场案例渗透[9]- HackableIII](https://img-blog.csdnimg.cn/img_convert/d917041f4fec7c8a9eecd7f02f762f4a.png)