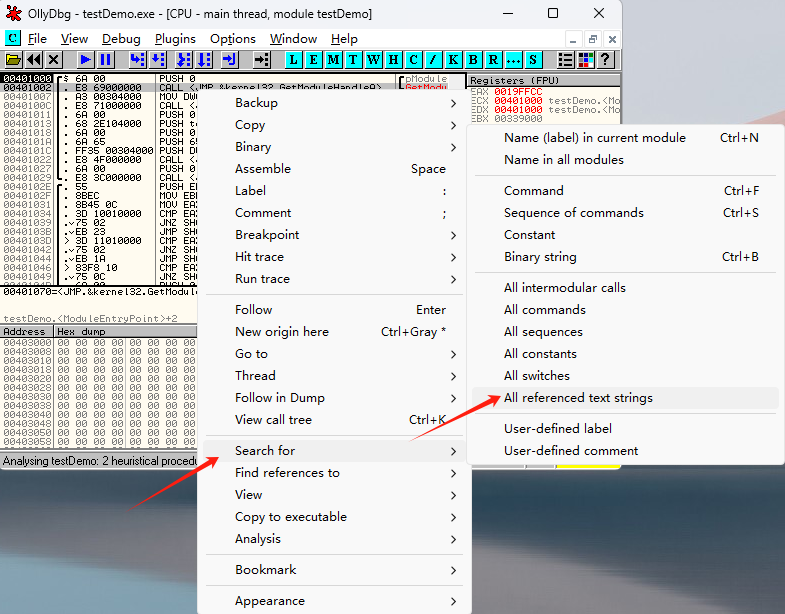
LeNet(LeNet-5)由两个部分组成:卷积编码器和全连接层密集块
x.view(): 对tensor进行reshape
import torch
from torch import nn
from d2l import torch as d2lclass Reshape(torch.nn.Module):def forward(self, x):return x.view(-1, 1, 28, 28)net = torch.nn.Sequential(Reshape(), nn.Conv2d(1, 6, kernel_size = 5, padding = 2), nn.Sigmoid(),nn.AvgPool2d(2, stride = 2),nn.Conv2d(6, 16, kernel_size = 5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10)
)torch.rand():生成随机数
layer.__class__.__name__:用self.__class__将实例变量指向类,然后再去调用__name__类属性
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__, 'output shape: \t', X.shape)
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)net.eval(): 变成评估模式
d2l.accuracy(y_hat, y):用于计算模型预测的准确性,即预测值与真实标签的匹配程度。
# 使用gpu进行训练
def evaluate_accuracy_gpu(net, data_iter, device=None):if isinstance(net, torch.nn.Module):net.eval()if not device: #如果没有给定device,遍历网络参数进行设备选择device = next(iter(net.parameters())).device# 如果device未提供,获取net中参数的设备,自动决定是在CPU还是GPU上运行metric = d2l.Accumulator(2) # 累计预测正确的数量(分子)和样本总数(分母)for X, y in data_iter:if isinstance(X, list):X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())# 将预测正确的数量和样本总数分别累加# 获取当前批次中标签的数量(样本总数)return metric[0] / metric[1]d2l.Timer(): 创建一个计时器实例,用于记录时间
timer.stop(): 停止计时,并返回从启动到停止的总运行时间
def train_ch6(net, train_iter, test_iter, num_epoch2, lr, device):def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator=d2l.Animator(xlabel='eopch', xlim=[1, num_epochs],legend=['train loss','train acc','test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()metric.add(1*X.shape[0], d2l.accuracy(y_hat, y),X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if(i+1)%(num_batches//5)==0 or i ==num_batches-1:animator.add(epoch+(i+1)/num_batches, (train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch+1, (None, None, test_acc))print(f'loss{train_l:.3f},train acc{train_acc:.3f},'f'test acc{test_acc:.3f}')print(f'{metric[2]*num_epochs/timer.sum():.1f} examples/sec'f'on{str(device)}')d2l.try_gpu():如果有可用 GPU,则返回 GPU 设备;否则返回 CPU 设备。
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())


![[代码随想录Day16打卡] 找树左下角的值 路径总和 从中序与后序遍历序列构造二叉树](https://i-blog.csdnimg.cn/direct/d31df4f58b6d413b8ad8c40e0eaf5974.png)