存算分离架构,作为数据处理领域的一个重要概念,从其最初的雏形到如今广泛应用,经历了多次迭代和变革。雁飞老师在分享中从过去的存算架构,逐步讲述存算分离的演进,现今的存算分离架构的优势及其在 Databend 中的体现,直至未来存算分离的发展方向。
一、存算一体架构局限性
在传统的数据处理架构中,计算和存储往往是紧密耦合在一起的。这种存算一体的架构虽然在早期的数据需求中表现优异,但随着业务复杂度和数据量的激增,逐渐显现出了一些无法克服的缺陷:
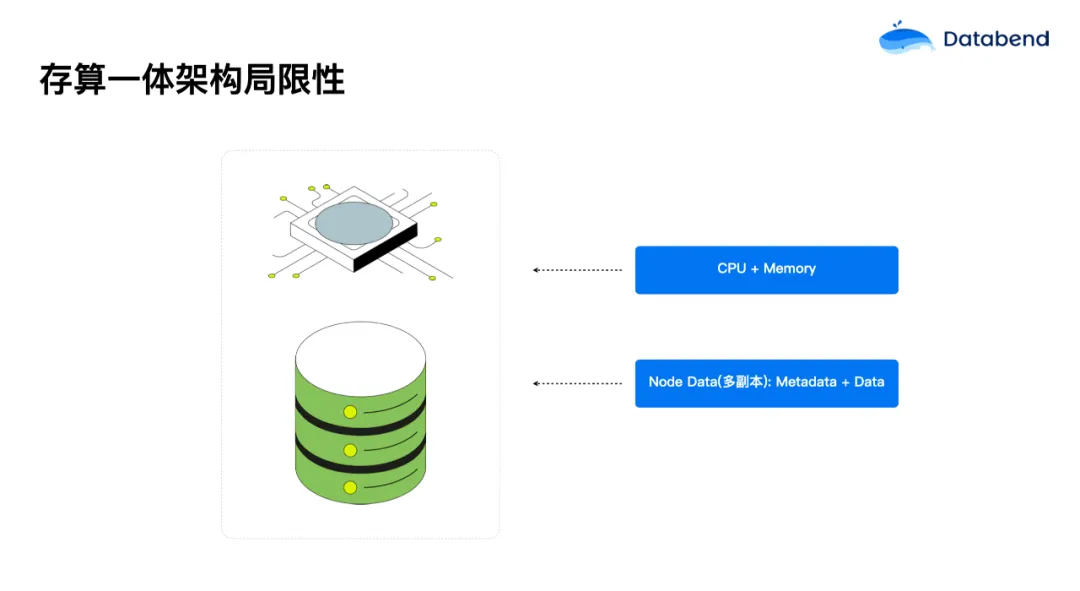
- 扩展性不足:新增一个计算节点时,数据(包括 MetaData 和 Data)需要在节点之间同步,导致扩展效率低下,且增加了系统的复杂性和管理成本;
- 资源分配不灵活:由于计算与存储资源是紧密耦合的,因此在业务负载发生变化时,⽆法根据业务负载做资源动态分配,⽆法灵活调整计算和存储资源,资源利⽤率低(Node 多副本),成本控制难;
- 故障影响大:在这种架构中,计算节点和存储节点之间共享数据,导致一个节点的故障可能会影响整个系统的稳定性,⽆法根据业务类型做资源隔离,资源争抢、故障影响范围⼤,⽆法保证稳定性。
二、存算分离进化:存算一体到分离
存算分离架构的发展可以大致分为三个阶段,每个阶段都在逐步解决存算一体架构中的缺陷,并使数据处理系统变得更加灵活和高效。
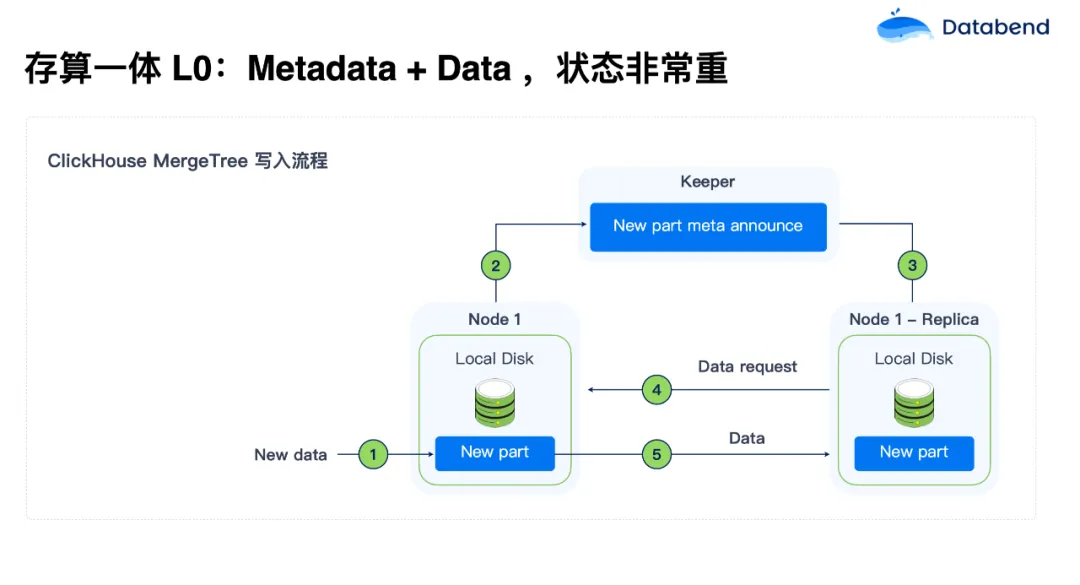
- 存算分离 L0:Metadata+Data,状态非常重
- 在早期阶段,例如 ClickHouse,在 MergeTree 写入流程中,元数据与业务数据的耦合程度很高。这种方式的存储状态非常重,节点需要频繁同步数据,导致扩展和管理都极其复杂。
- 存算分离 L1:Metadata 状态,状态重
- 在 L1 阶段,以 ClickHouse 的 SharedMergeTree 写入流程为例(SharedMergeTree 不开源),元数据与数据的分离有了一定的改进。元数据独立存储在集中化的系统中(如 Keeper,类似 ZooKeeper),而业务数据则可以存储在对象存储中,例如 S3。虽然这种方式减轻了数据节点的负担,但元数据管理依旧是系统的瓶颈。

- 存算分离 L2:计算无状态化
- 随着对计算资源和存储资源的独立需求不断增长,Databend 使用了彻底的存算分离架构。在 L2 级别,计算节点彻底无状态化,状态全部持久化在对象存储中。这使得计算节点可以根据负载需求弹性调整,启动时间也缩短到了小于 5 秒,大大提升了系统的可扩展性和资源利用率。
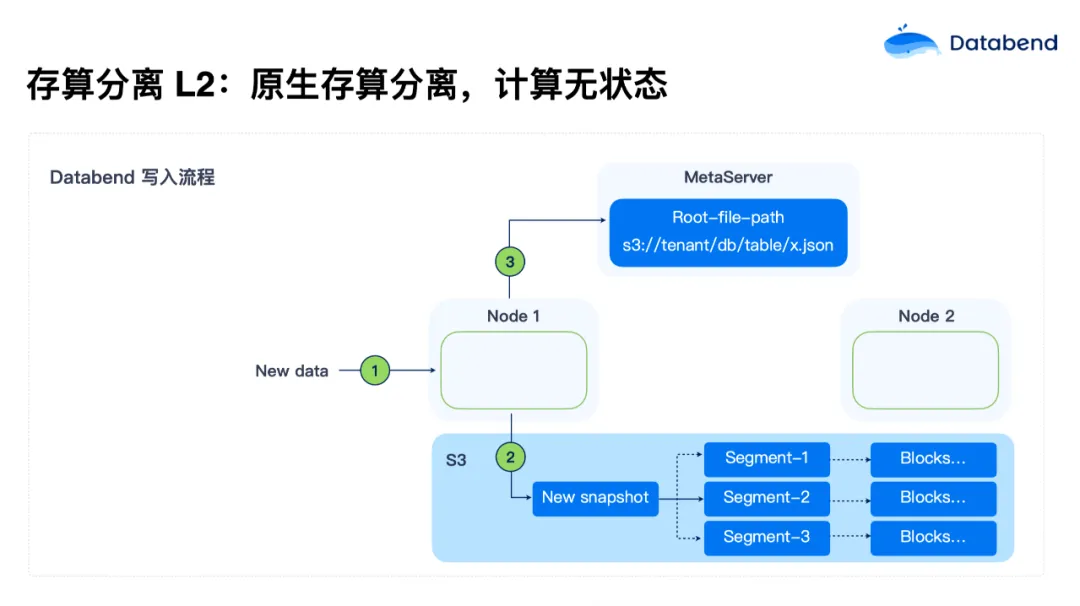
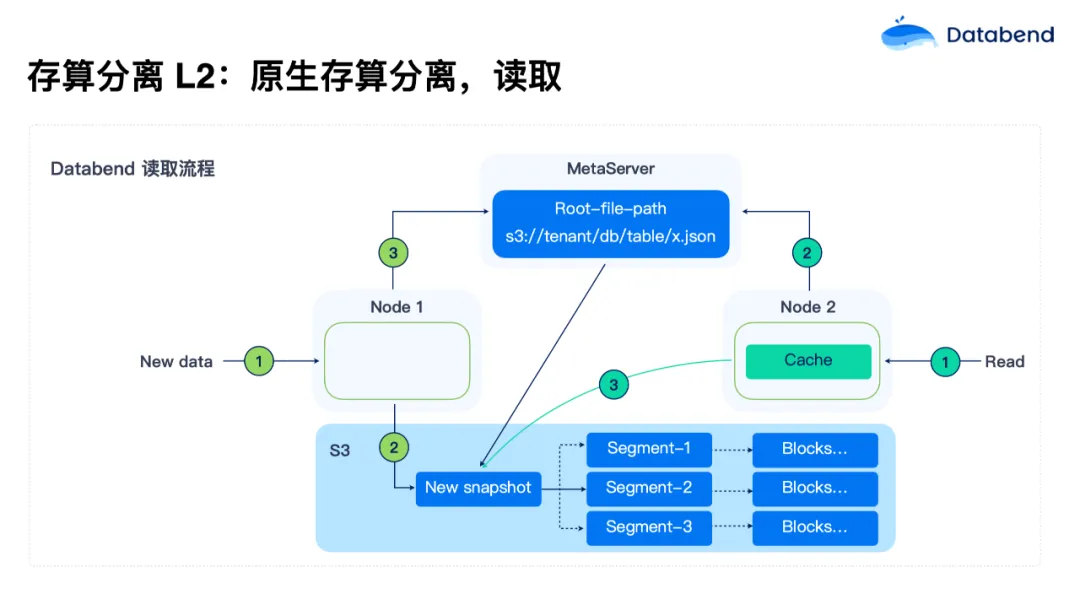
存算一体为什么不能“进化”到 L2?
第一,状态剥离挑战大。如果将一套 ClickHouse 代码改成完全存算分离架构,首先要做到状态剥离:Metadata 剥离,数据剥离。为此,你需要造一个高性能 Metadata service ,把数据全部放到 S3上,重新设计 MergeTree 引擎数据存储格式,挑战巨大;
第二,分布式网络传输挑战。在分布式架构下,数据要在节点间做 Shuffle。假如要做一个很复杂的 join,哪个节点需要数据,就拉到哪个节点。但像 Databend 这种真正的存算分离架构,数据都在 S3上,传的不是数据实体,而是一个文件路径。系统会告诉你要的数据在哪个位置,而不是把数据内容都传给节点。这是 Databend 做完全存算分离时做出的一个巨大改变,既减少了网络传输。这对 ClickHouse 等传统存算一体架构来说就很难,需要重新设计交互方式,改很多东西;
第三,Metadata 膨胀挑战。ClickHouse 虽然将数据剥离了,但 Metadata 还没剥离,随着数据量的增长,Metadata 会越来越大。一旦高并发来了,会直接压垮。所以 ClickHouse 每个节点即使是存算分离,也要在本地维护一份自己的 Metadata ,以减少 ZooKeeper 的压力;
第四,调度器。调度器在传统存算一体架构中,是面向本地盘设计的。它认为本地盘 IO 是无限的,只要尽量把随机的变成顺序,就可以把性能提上去。但是对象存储的设计完全不一样,对象存储只要有足够的并行,就能把带宽拉满,所以调度器上也要改很多东西;
第五,多租户。ClickHouse 如果做多租户,它的 Zookeeper 会比较有挑战。基本上要每个集群一个 Zookeeper,如果是多租户,这个数据量会更大。所以 Databend 在设计时,Metadata Service 本身就是多租户的;
第六,旧架构局限性大,真正要做到存算分离需要进行大规模的重构和改造。
三、Databend:现在,开源,场景
我们在设计 Databend 时的思路,并不是站在技术的角度上追求要比 ClickHouse 更快,而是站在用户角度,让数据从进来到清洗,入表、分析、出库,包括中间所有的 transform 全部一体地在 Databend 内部完成。

所以我们在数据写入上做了非常大的改进,用 COPY/Mergelnto 命令实现高效数据导入,可以非常快地把数据导入。数据导入后,还可以快速解析和转化复杂 JSON,简化数据清洗过程。
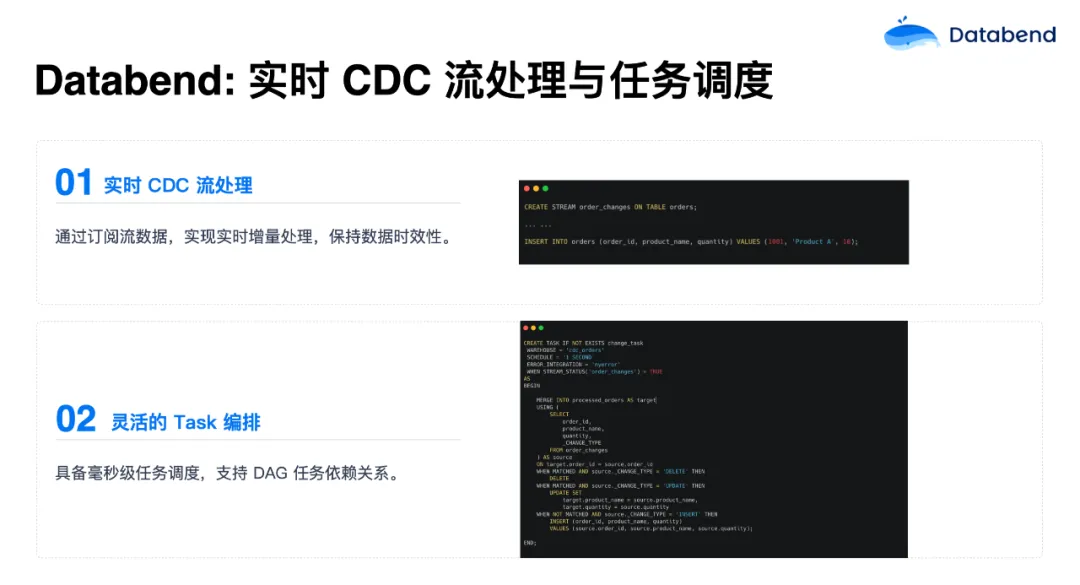
人们可能比较关注数据上游实时的增量处理,不想再在中间挂一个其他流做增量处理,再写到 Databend 内部。Databend 可以订阅流数据,在内部就把这个事搞定了,实现了实时增量处理,保持数据时效性。
在Databend 内部有一个流(Stream)的概念,在源表上面挂一个流。源表一更新,这个流的变更就会捕获,然后对其进行一次性消费。还可以结合 Databend Task 机制去做更加灵活的编排,毫秒级的调度机制,并支持 DAG 任务依赖关系,让你可以更加灵活的把数据链路自动化起来。
我们在设计 Databend 时有一个理念,尽量不引入第三方工具,所有数据处理就在 Databend 内部完成。以前用 Flink 做的事,Databend 里面都可以做。
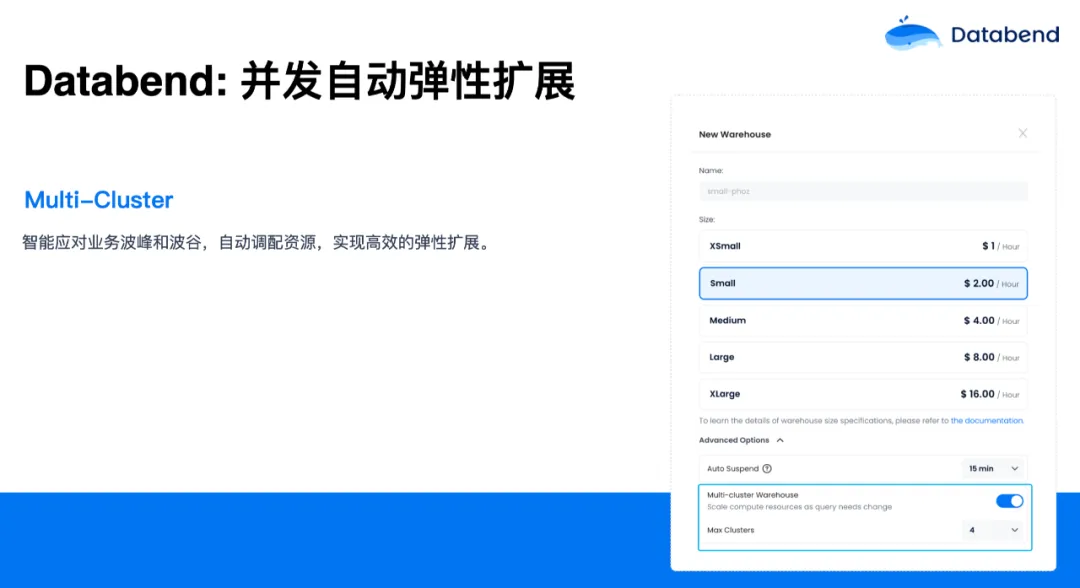
对于数仓大家比较关心的还有一点是并发能力,当并发达到一定能力后,该怎么去扩展?Databend 对此有一个 Multi-Cluster 的概念。你的业务如果有高峰期和低峰期的话,可以在 Databend 中打开这个选项(如上图),你可以设置 Multi-Cluster 的数量。当遇到业务高峰时,就会自动扩展当前的这个集群。当业务处于低峰后,Multi-Cluster 又会慢慢往回缩,最后缩到 1。这样你就不用关心业务高峰还是低峰,只需定义好这个 Multi-Cluster 数量,Databend 会自动根据压力做扩展和缩容。

另外,Databend 在设计的时候,非常注重权限管理。因为 Databend 是从数据进来的行为就开始纳管,一直到数据出去,中间会有很多安全上的问题。如果安全做不好,用户用起来就会比较混乱。所以 Databend 有着一套完整的权限管理,大家平时在业务上能用到、能想到的都可以完成,如权限继承、角色分层、职责分离等等原则。在 Databend 里每一个对象,如 库(Database),表(Table)、流(Stream)等都可以赋予权限。
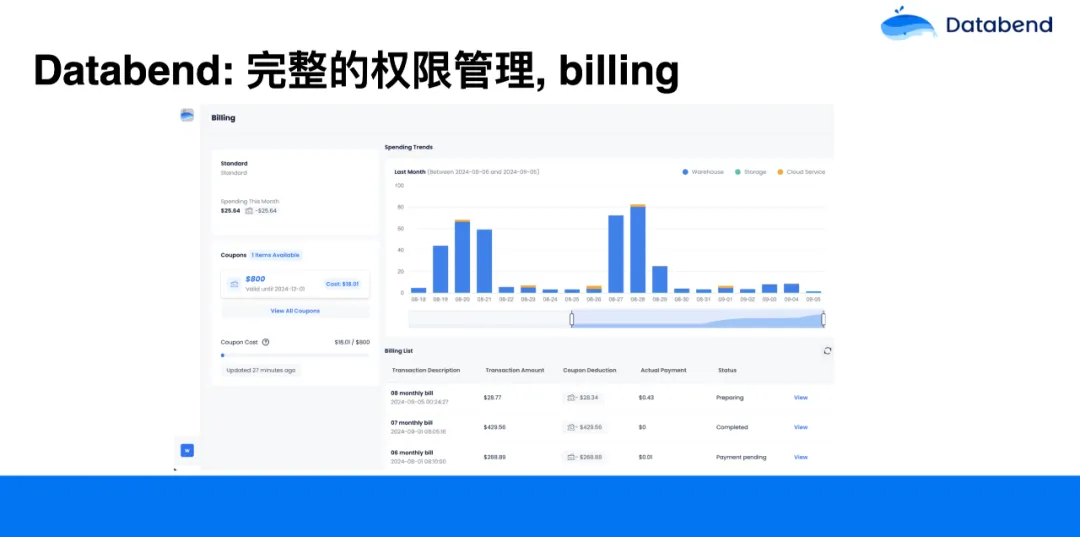
在有些公司里,财务人员可能只关心账单,我们就可以给财务人员的账户授予一个 Billing 权限。在给这些人 Billing 的权限后, 他看不到业务的 warehouse 等,也不能执行 warehouse 跟业务相关的一些操作, 能看到的只是账单。
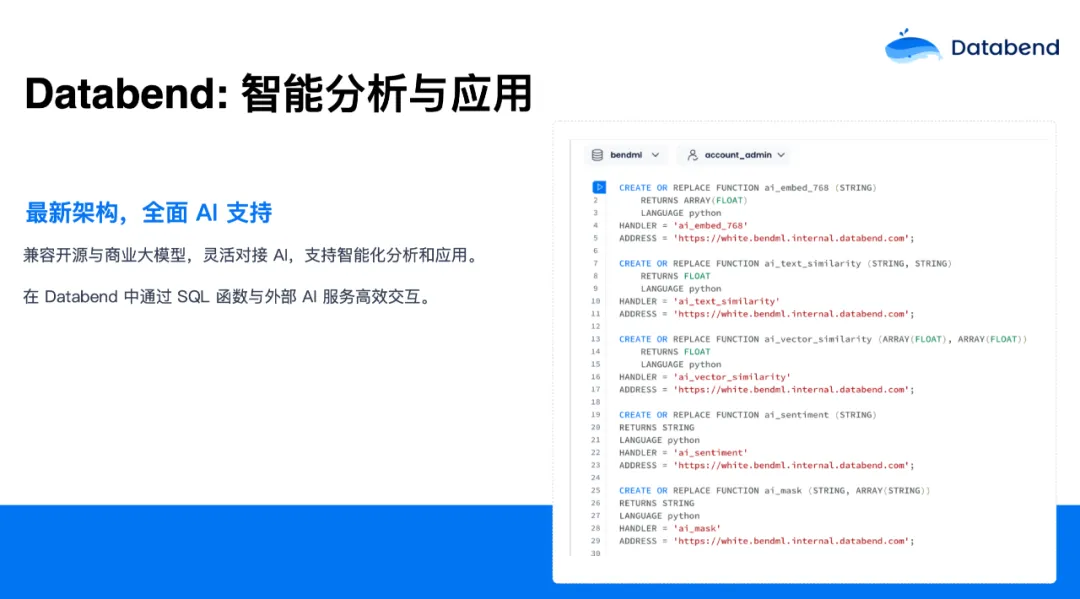
还有一块绕不开的就是与 AI 的结合,Databend 在这方面其实是从下至上重新设计了。你可以跟开源大模型,商业大模型随意结合,支持智能分析和应用。在 Databend 内部,你可以通过 UDF,去连接外部的 AI 服务或 API ,使用 Databend 通过 SQL 函数实现反向调用外部的 AI 服务。Databend 提供了一套框架让你实现自己的服务。目前,这些业务在线上已经有一些生产用户在用。 举个例子:
-- 创建一个情感分析的 External UDF
CREATE OR REPLACE FUNCTION ai_sentiment (STRING)
RETURNS STRING
LANGUAGE python
HANDLER = 'ai_sentiment'
ADDRESS = '<你的 AI UDF Server>';-- 调用这个 UDF
SELECT data, ai_sentiment(data) AS sentiment FROM texts;
Databend 也很专注数据湖领域,我们 team 有一个口号: Rewrite Big Data in Rust,简称 RBIR,就是要用 Rust 语言(内存占用少,性能高,安全性好)把整个大数据生态技术栈重写一遍。目前我们把 Hive、Iceberg、Delta Lake 都用 Rust 实现了。而且这些框架都在 Databend 内部集成,你可以用 Databend 去读 Hive 、Iceberg,后续我们还会支持写。你可以在 Databend 内借用 Rust 语言把之前一些 Java 的技术栈替换掉。我们用 Rust 重写了之后,效果提升比较明显。

目前,这个项目已经开源 https://github.com/rewrite-bigdata-in-rust/RBIR。Databend 大概有 50 多万行 Rust 代码,占整个项目代码量的 97.6%,已经非常高了,其他是 Shell、Python 写的一些测试脚本。这也证明了 Databend 三年前就用 Rust 语言写这么大一个项目,是一个很不错的选择。目前 Databend 社区有将近 200 个 Contributors,大家都是奔着 Rust、大数据生态过来的。
Databend 架构
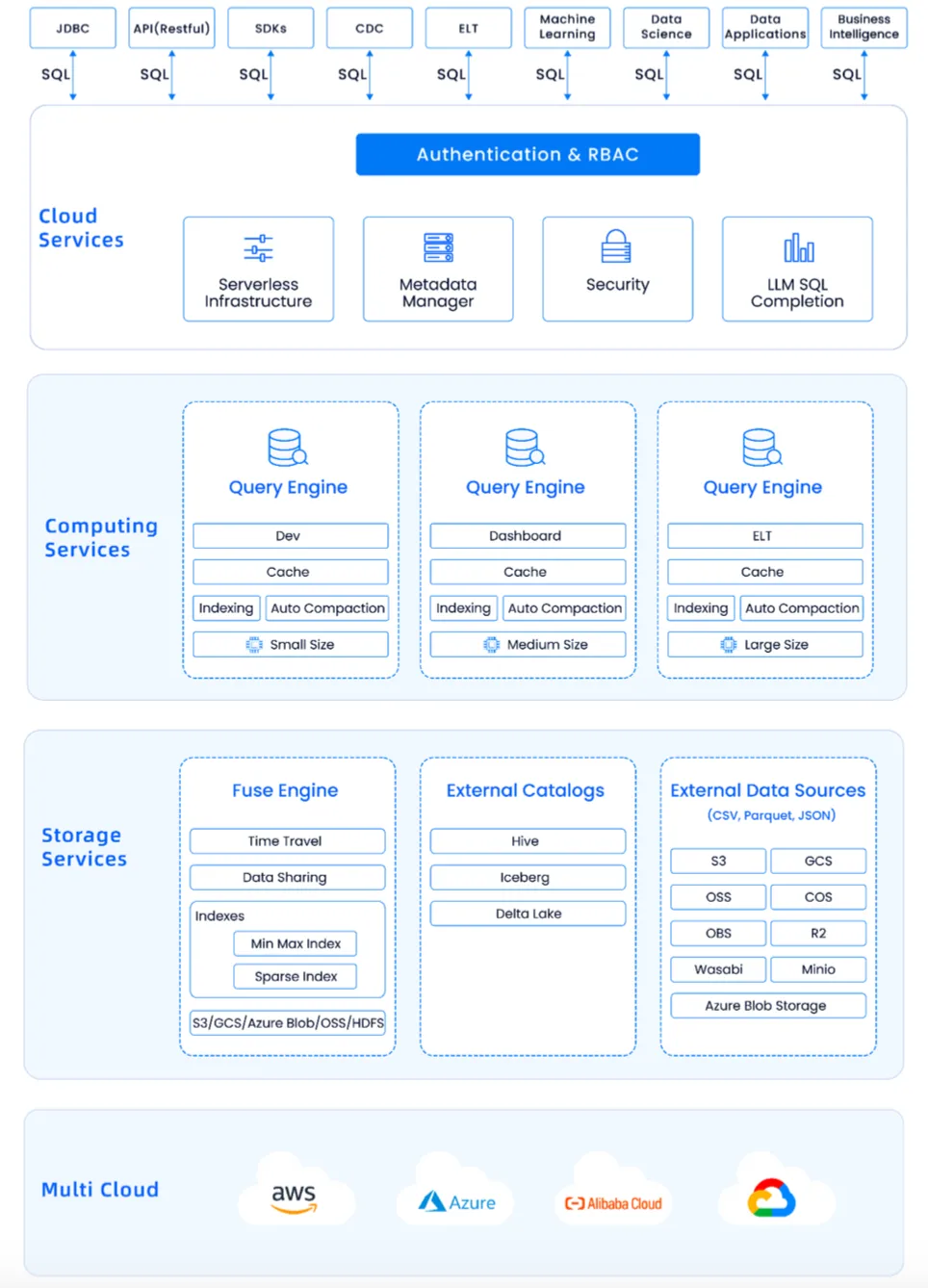
上图是 Databend 整体架构图,最上面是所有的大数据生态 JDBC、SDKs、CDC、ELT、机器学习, 你都可以对接,并且对接模式很简单,就是 SQL。SQL 可以完成之前很难去做的事,Databend 通过一些自己的方式,把它们全都对接起来了。
再下面一层是 Cloud Services,这一层也很轻量化,只做一些元数据的管理。元数据非常小,大部分数据都在对象存储上。中间一层是计算, 就是 Databend 的 Query Engine,每个节点都有自己的 Cache、索引,你可以把不同的计算做不同的用处,可以开发、ETL 、Dashboard 等等。你可以选择业务类型选择不同规格的 Warehouse,随意扩展。
我们为了性能,又重新设计了一套 Fuse Engine 引擎。它可以支持分布式事物,如更新、删除、Time Travel。还支持 Hive、Iceberg 等外部的 Catalog 。对象存储方面,我们支持了市面上绝大部分的对象存储。这主要是因为我们中间有一层 OpenDAL,这一层屏蔽了其他对象存储的接口,做了统一的封装,可以和他们无缝打通。
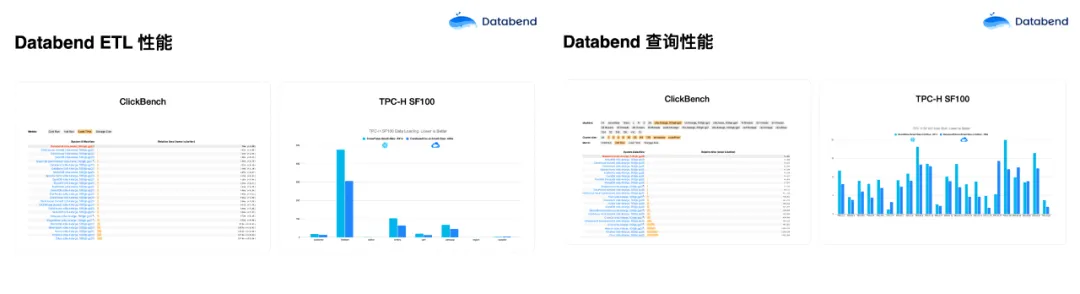
我们在 ClickBench 上做了一些测试,在榜单上数据导入是最快的,只有 70 多秒,其他数据库系基本上都是 Databend 耗时的两倍。Databend 和 Snowflake 在 TPC-H SF100 对比中,规格完全一样的情况下,导同样的数据,Snowflake 大概花了691 秒,Databend 是 446 秒。我们用 Rust 语言做了很多并行化设计,效果也比较明显。在 ClickBench 查询性能对比中,Databend 在好几个机型对比中基本都是第一。与 Snowflake 对比,Databend 基本也是基本比它快一点。
Databend 落地的场景

目前,Databend 支持的用户主要集中在实时分析、海量日志存储与计算、数据库归档、离线计算、非结构化到结构化利用 AI 的数据清洗。服务的用户包括多点、微盟、茄子快传、医药集团、新能源汽车等等。
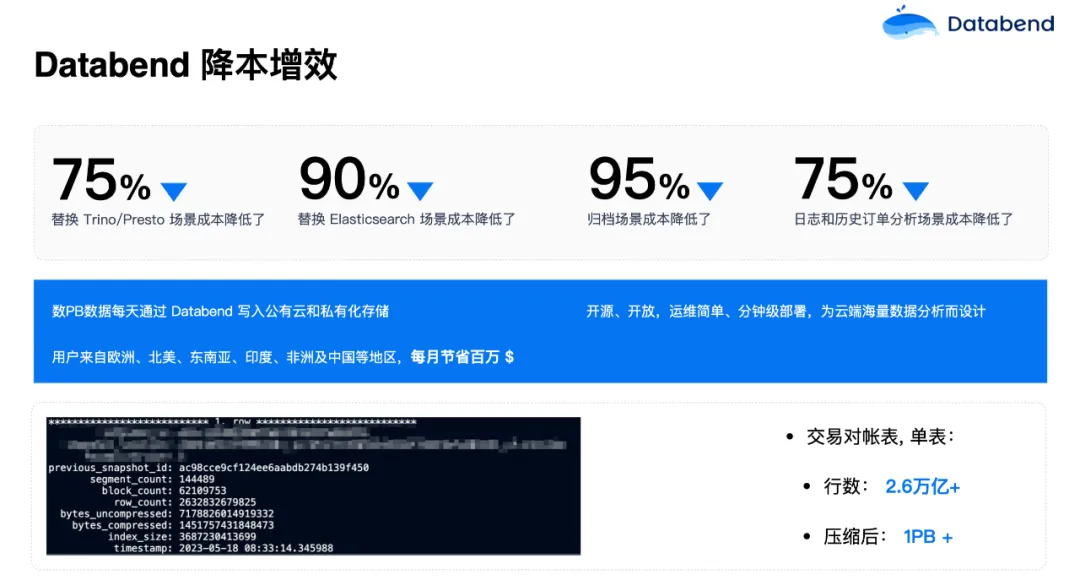
在所有这些用户场景中,替换 Trino/Presto 场景成本降低了 75%,替换 Elasticsearch 场景成本降低 90%,归档场景成本降低了 95%,其他的日志和历史订单分析等场景成本也都下降很明显。每天有数 PB 级数据通过 Databend 写入公有云和私有云对象存储。

多点是最早使用 Databend 的用户,当时还没有推出稳定版前,他们就第一个用起来。当时,多点的历史订单数据都存放在 MySQL 和 TiDB 中,要把订单数据导出来放到对象存储以节省存储成本。但他们面临着一个问题,为了做审计,还要把数据再导回来,所以起了一个很大的 MySQL 实例,做完审计再把这个实例关闭。在使用 Databend 后,我们帮助多点将 MySQL、TiDB 的数据直接写到对象存储,想做分析的时候,直接使用 Databend 进行分析。成本仅为原来的 1/10。并且在 10亿数据量级别下,常用查询均可做到秒级响应。

上图是某医药集团从 CDH 生态迁移到 Databend 的案例。当时,他们 CDH 的量太大,最大单表达到 93 亿行,原数据库无法满足数量存储需求,需要对数据迁移。迁移过程中,数据备份文件通过 Parquet 格式导到对象存储,然后通过 COPY INTO 命令加载到 Databend 进行计算。几 TB 的数据,不到一个小时就全部迁移完了。数据存储成本最高下降到原来的 1/30,对大表数据的查询加载速度提升了 2 倍多。
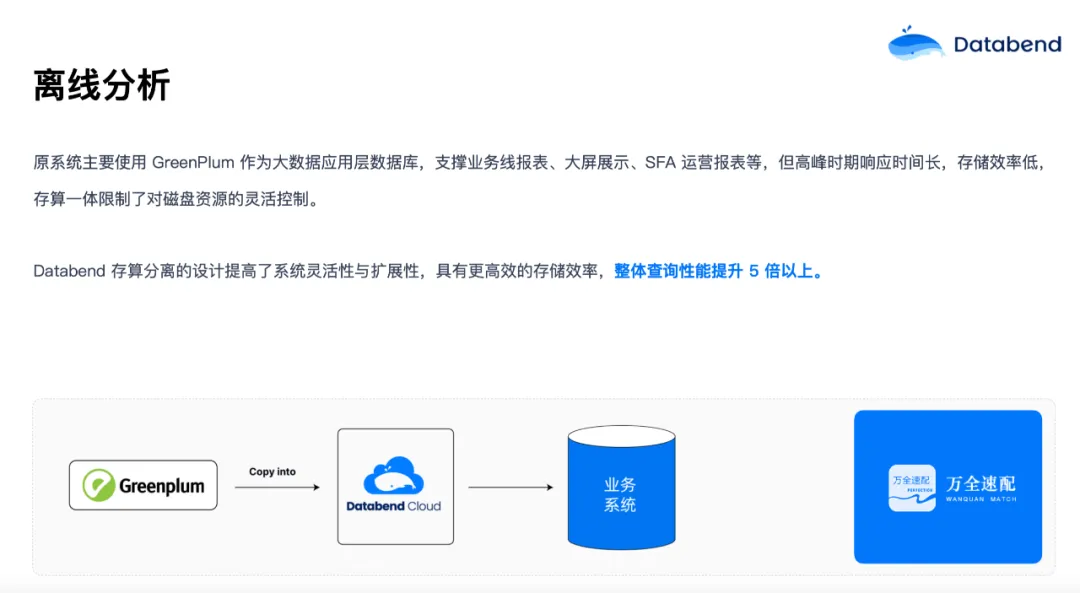
今年,在 Greenplum 将开源版做了类似于闭源的操作后,很多用户担心项目未来发展。所以有些海外和国内的用户就开始考虑要下掉 Greenplum,想迁移到新的架构。我们帮他们把数据导入对象存储,再通过 COPY INTO 的命令加载到 Databend 中,即使几 TB 的数据,基本上几十分钟也可以加载好。
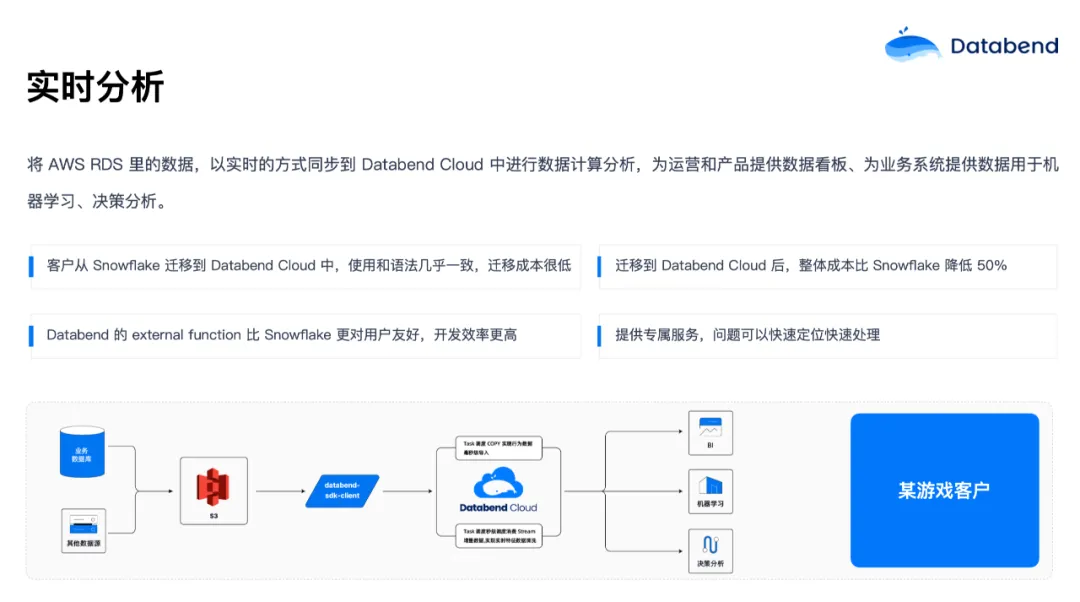
实时分析也是业务里面比较常见的场景。比如有些数据在 RDS 或者 MySQL 里面,但是想实时地将这些数据做一些分析。上图是一个游戏行业的典型场景,他们有很多用户行为数据,会先写到 AWS 的 RDS 或者消息队列里面,然后再把数据放到 S3 里做下游的分析。业务数据是增量地、实时地往 S3 写入,写入之后通过 Databend 的 Task 和 Stream 在 Databend 内部做实时的清洗,清洗后再将数据导到 BI、机器学习、决策分析等使用。整个流程在五秒内基本就可以搞定,Databend 的 Task 可以做到毫秒级的任务调度,所以数据新鲜度非常高。
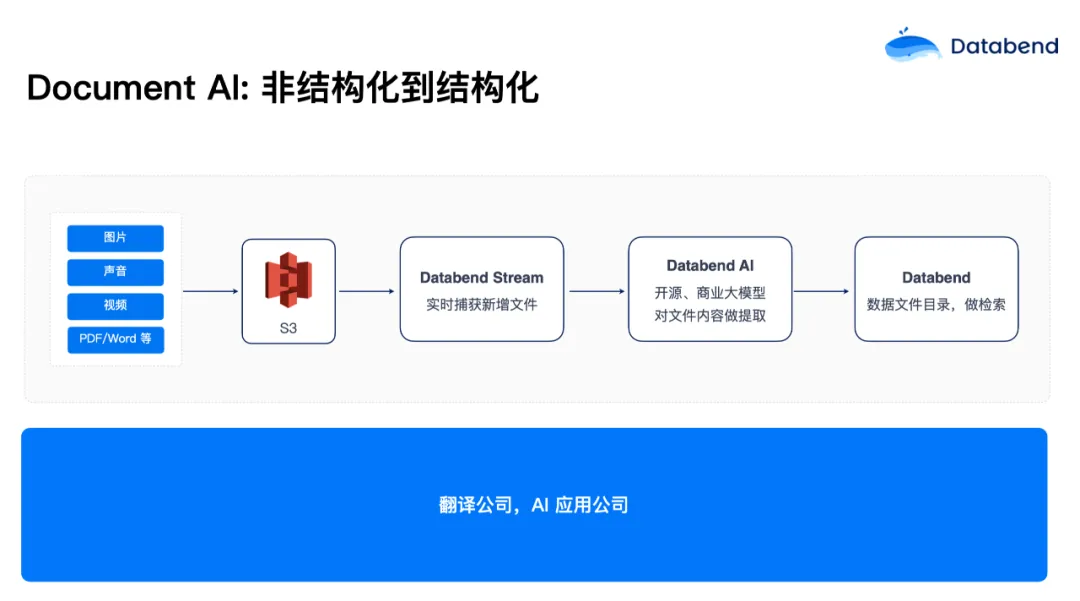
今年有一些翻译公司、 AI 应用公司也在与我们合作。这些用户有很多视频、图片、非结构化的 PDF 和 word 文档存放在对象存储上,他们想做数据目录服务,当用户搜索一个关键词的时候,能把图片、声音等数据结构化展现出来。Databend 可以通过 Stream 把 S3 上的图片、声音、视频增量捕获做实时分析,调 AI Services 进行分析。比如数据是图片,就去提取一些里面的标签或描述,声音里面的内容是什么,视频第几帧出现什么关键词,全部从非结构化数据转成结构化,写到结构化的表里面。当用户查询搜索时,就可以根据 AI 提取出来的内容来做一些检索。
Databend:未来

2025 年,Databend 有几个优化方向。第一个还是稳定性。用户的核心业务对稳定要求非常高,很多用户找我们,就是因为他们现在使用的产品、技术栈的稳定性支撑不了核心业务。所以稳定性我们始终放在首位,持续提升系统可靠性,与 Snowflake 看齐,提供企业级高可用的数据平台;
第二个是资源组的管理。 有一些用户在做 Databend 私有化的部署,在这些私有化的场景中,用户的资源怎么做隔离?怎么做负载,做路由?对私有化用户来说挑战非常大。所以我们会做一些资源组的概念,通过模拟云上的资源分配,专为私有化场景设计,实现灵活的资源分组与隔离,优化资源分配与本地部署效率;
第三个是地理空间的分析支持。 我们现在接到很多用户的需求,比如有燃气公司需要对一些空间数据进行处理,所以我们准备增加一个 GIS 的新数据类型,把用户的空间数据放进来;
最后一个是将 Databend 打造成一体化 数仓 。 支持离线、实时、数据湖、流处理、地理空间和 AI 等多元数据类型和场景,简化技术栈,实现数据价值最大化。目前这些功能其实大部分都支持,明年我们会以更加产品化的形态去实现。
关于 Databend
Databend 是一款开源、弹性、低成本,基于对象存储也可以做实时分析的新式数仓。期待您的关注,一起探索云原生数仓解决方案,打造新一代开源 Data Cloud。
👨💻 Databend Cloud:databend.cn
📖 Databend 文档:docs.databend.cn/
💻 Wechat:Databend
✨ GitHub:github.com/datafuselab…