论文速读|Dynamic Rewarding with Prompt Optimization Enables Tuning-free Self-Alignment of Language Models
论文信息:

简介:
本文探讨的背景是多模态大型语言模型(MLLMs)在多模态推理能力上的局限性,尤其是在链式推理(Chain-of-Thought,CoT)性能方面。现有的开源MLLMs通常采用预训练和监督式微调(Supervised Fine-Tuning,SFT)的训练过程,但这些模型在推理时受到分布偏移的影响,限制了它们的多模态推理能力。特别是在CoT任务中,模型的表现往往不如直接回答任务。本文动机在于提升MLLMs的多模态推理能力,使其能够更好地处理多模态数据并提高CoT任务的性能。作者希望通过引入偏好优化(Preference Optimization,PO)技术,使模型的输出更符合期望的推理模式,从而增强模型的推理能力,并减少幻觉(hallucinations)现象。
论文方法:

本文提出了一种名为混合偏好优化(Mixed Preference Optimization,MPO)的方法,它结合了偏好优化和监督式微调。具体来说,本文的方法包括两个主要部分:数据层面和模型层面。
数据层面:作者设计了一个自动化的偏好数据构建流程,创建了一个大规模的多模态推理偏好数据集(MMPR)。这个数据集包含了约300万个样本,通过自动化流程高效生成高质量的偏好对。
模型层面:在模型层面,作者探索了将PO与MLLMs集成的方法,提出了MPO方法。MPO通过结合偏好损失(Lp)、质量损失(Lq)和生成损失(Lg)来训练模型,使模型能够学习响应之间的相对偏好、单个响应的绝对质量以及生成偏好响应的过程。具体来说:
偏好损失(Lp):使用直接偏好优化(DPO)作为偏好损失,使模型能够学习选择响应和拒绝响应之间的相对偏好。
质量损失(Lq):使用二分类优化(BCO)作为质量损失,帮助模型理解单个响应的绝对质量。
生成损失(Lg):使用SFT损失作为生成损失,帮助模型学习生成偏好响应的过程。
此外,本文还提出了Dropout Next Token Prediction(DropoutNTP)方法来生成没有明确真值的样本的拒绝响应,以及基于正确性的流程来生成有明确真值的样本的偏好对。通过这些方法,模型在多模态推理任务中表现出了显著的性能提升。
论文实验:
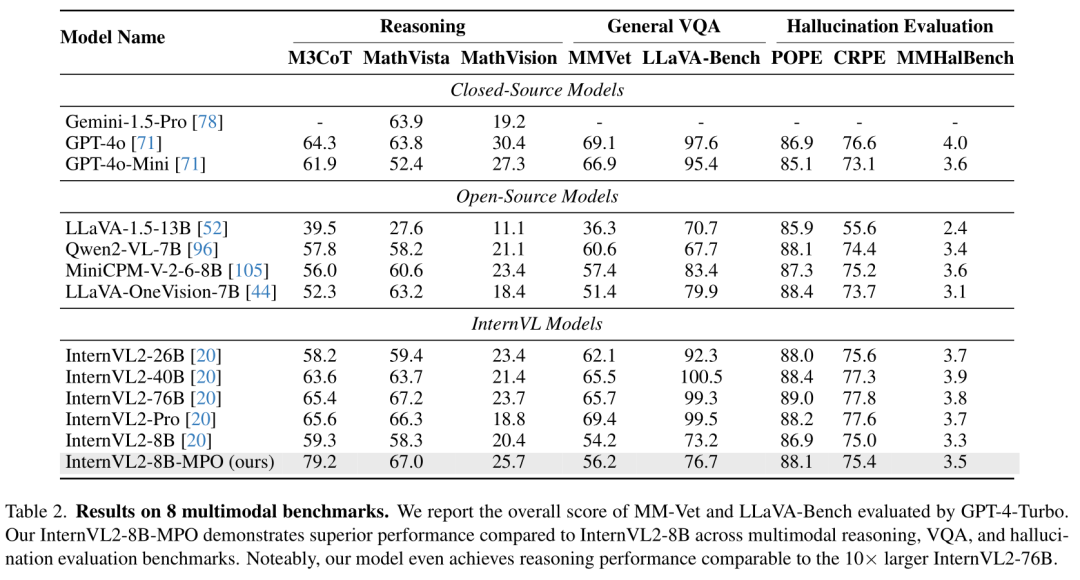
根据Table 2,论文的实验部分主要评估了作者提出的InternVL2-8B-MPO模型在多个多模态基准测试中的表现,并与其他领先的多模态大型语言模型(MLLMs)进行了比较。实验涉及了多个不同的基准测试,包括多模态推理、复杂视觉问答(VQA)和幻觉评估任务。
作者的模型InternVL2-8B-MPO在所有基准测试中都展现出了优越的性能,特别是在多模态推理任务上。在M3CoT(多领域多步多模态链式推理)基准测试中,InternVL2-8B-MPO的得分为79.2,远高于InternVL2-8B的59.3,显示出MPO方法在增强推理能力方面的有效性。在MathVista(多模态数学推理)基准测试中,InternVL2-8B-MPO的准确率达到了67.0%,比InternVL2-8B的58.3%高出8.7个百分点,并且与比InternVL2-8B大10倍的InternVL2-76B的性能相当。InternVL2-8B-MPO在8个多模态基准测试中的整体得分均优于InternVL2-8B,这表明通过MPO方法,模型在多模态推理、VQA和幻觉评估方面的能力都得到了显著提升。
论文链接:
https://arxiv.org/pdf/2411.10442