1. Go语言进阶
1.1 Goroutine
package mainimport ("fmt""time"
)func hello(i int) {println("hello goroutine : " + fmt.Sprint(i))
}func main() {for i := 0; i < 5; i++ {go func(j int) { hello(j) }(i) // 启动一个新的 goroutine,传入参数}time.Sleep(time.Second) // 主 goroutine 睡眠 1 秒
}
输出如下:
hello goroutine : 3
hello goroutine : 0
hello goroutine : 4
hello goroutine : 1
hello goroutine : 2
-
hello(i int) 函数:
hello 函数接受一个 int 参数,并打印 “hello goroutine : i”,其中 i 是传入的整数。 -
main 函数的循环:
在 main 函数中,for 循环执行 5 次,i 从 0 到 4。每次循环都会启动一个新的 goroutine。
这里,go 关键字用于启动一个新的 goroutine,并将当前的 i 值传递给一个匿名函数。匿名函数接收一个 j 参数,并调用 hello(j)。
关键点是这里的 匿名函数。在 Go 中,匿名函数可以定义并立刻调用,而它的参数可以是传递给它的值。在这个例子中,i 是从外部传递给匿名函数的参数 j。
-
为什么要用闭包(匿名函数)?
Go 语言中的 goroutine 是并发执行的。如果我们直接将 i 传递给 hello(i),我们就会遇到一个 竞争条件 问题,因为 i 是一个在主线程中递增的变量,它的值在每次 goroutine 启动时都可能变化。也就是说,所有 goroutine 可能都能获取到相同的 i 值,导致它们都打印相同的值。
通过使用 闭包(匿名函数),每个 goroutine 都会捕获它所启动时的 i 值(即使外部循环 i 的值发生变化),避免了共享变量的问题。匿名函数会传递当前的 i 值作为参数 j,从而确保每个 goroutine 得到正确的值。 -
time.Sleep(time.Second)
因为 goroutine 是并发执行的,main 函数在启动 goroutine 后会立刻返回。为了确保主 goroutine(main 函数的执行线程)能够等待其他 goroutines 完成工作,代码调用了 time.Sleep(time.Second),这会使主线程暂停 1 秒钟。这样,主线程会等待一段时间,让其他 goroutines 有机会打印它们的信息。
注意:这里的 time.Sleep 只是为了让 goroutines 有时间执行。在实际的生产代码中,我们可能会使用更合适的同步机制(如 sync.WaitGroup)来确保 goroutines 执行完毕。
1.2 通信
Go通过通信共享内存而不是通过共享内存实现通信。

1.2.1 Channel
make(chan元素类型,[缓冲大小])
无缓冲通道 make(chan int)
有缓冲通道 make(chan int,2)

package mainimport ("fmt"
)func hello(i int) {println("hello goroutine : " + fmt.Sprint(i))
}func main() {src := make(chan int) // 创建一个无缓冲的 channel 用于传递整数dest := make(chan int, 3) // 创建一个带缓冲区大小为3的 channel,用于存储计算结果// 启动第一个 goroutine,向 src channel 发送数据go func() {defer close(src) // 完成后关闭 src channelfor i := 0; i < 10; i++ {src <- i // 向 src channel 发送数据 i}}()// 启动第二个 goroutine,从 src channel 接收数据并计算平方,然后将结果发送到 dest channelgo func() {defer close(dest) // 完成后关闭 dest channelfor i := range src { // 从 src 接收数据直到 src 关闭dest <- i * i // 将接收到的数据平方后发送到 dest}}()// 主 goroutine 从 dest 接收并处理数据for i := range dest { // 从 dest 接收计算结果直到 dest 关闭// 复杂操作(这里只是打印)println(i) // 打印每个接收到的结果}
}
- Channel 的创建与作用
src := make(chan int):这是一个 无缓冲的 channel,它用于在第一个 goroutine 中传递数据。因为它是无缓冲的,每次发送操作都会阻塞,直到有其他 goroutine 来接收数据。
dest := make(chan int, 3):这是一个 带缓冲的 channel,它用于在第二个 goroutine 中传递计算后的数据。缓冲区大小为 3,意味着它最多可以存储 3 个数据,超出会阻塞发送操作,直到有地方消费数据。
执行流程
第一个 goroutine 会依次将数字 0 到 9 发送到 src channel 中。
第二个 goroutine 从 src 接收每个数字,计算它的平方,然后发送到 dest channel。
主 goroutine 从 dest 接收平方结果并打印。
1.3 并发安全Lock
对变量执行2000次+1操作,5个协程并发执行
带缓冲的channel不会因为消费者的消费速度影响生产者的生产效率
package mainimport ("sync""time"
)var (x int64 // 全局共享变量 xlock sync.Mutex // 互斥锁,用于保护对 x 的并发访问
)// addWithLock 函数:使用互斥锁来保证对 x 的并发访问安全
func addWithLock() {for i := 0; i < 2000; i++ {lock.Lock() // 上锁,确保只有一个 goroutine 能访问 xx += 1 // 对共享变量 x 进行加法操作lock.Unlock() // 解锁,允许其他 goroutine 访问 x}
}// addWithoutLock 函数:不使用互斥锁直接对 x 进行并发加法操作
func addWithoutLock() {for i := 0; i < 2000; i++ {x += 1 // 不加锁的并发访问,可能会导致数据竞争}
}// Add 函数:演示加锁和不加锁情况下的并发访问
func Add() {x = 0 // 重置 x 的值为 0// 启动 5 个 goroutine 并发执行 addWithoutLock 函数(不使用锁)for i := 0; i < 5; i++ {go addWithoutLock() // 启动一个新的 goroutine,进行不加锁的操作}// 等待一段时间,确保 goroutines 执行完毕time.Sleep(time.Second)// 打印不加锁情况下的 x 值println("WithoutLock:", x)// 重置 x 的值为 0x = 0// 启动 5 个 goroutine 并发执行 addWithLock 函数(使用锁)for i := 0; i < 5; i++ {go addWithLock() // 启动一个新的 goroutine,进行加锁的操作}// 等待一段时间,确保 goroutines 执行完毕time.Sleep(time.Second)// 打印加锁情况下的 x 值println("WithLock:", x)
}func main() {Add() // 调用 Add 函数,启动并发操作
}(1)全局变量
x:这是一个全局共享变量,它将在多个 goroutines 中被访问和修改。
lock:一个 sync.Mutex 类型的变量,用于在 addWithLock 函数中对共享数据 x 加锁,确保在并发情况下对 x 的访问是安全的。
(2)addWithLock 函数
该函数每次在修改共享数据 x 时都会通过 lock.Lock() 来加锁,修改完后再通过 lock.Unlock() 来释放锁。
由于加了锁,确保了在同一时刻只有一个 goroutine 能对 x 进行操作,避免了数据竞争(data race)。
addWithoutLock 函数:
该函数与 addWithLock 函数类似,但没有加锁保护共享数据 x。
因为没有锁的保护,多个 goroutine 并发修改 x 时会发生数据竞争,可能导致结果不正确(即多个 goroutine 同时读取和修改 x 的值,造成丢失更新)。
(3)Add 函数
首先将 x 重置为 0,然后启动 5 个 goroutines 来执行 addWithoutLock 函数,这些 goroutines 在不加锁的情况下并发地修改 x。
主 goroutine 在启动所有 goroutines 后,调用 time.Sleep(time.Second) 来等待这些 goroutines 执行完毕。
然后打印 x 的值。由于没有加锁,可能会出现 x 的值不准确的情况,因为并发修改会引发数据竞争。
接下来,重置 x 为 0,启动 5 个 goroutines 来执行 addWithLock 函数,这些 goroutines 通过 sync.Mutex 来确保对 x 的访问是互斥的。
主 goroutine 等待这些 goroutines 执行完毕,并打印出 x 的值。由于加了锁,x 的值应该是准确的,每个 goroutine 都会安全地对 x 进行加法操作。
运行结果:
WithoutLock: 7728
WithLock: 10000
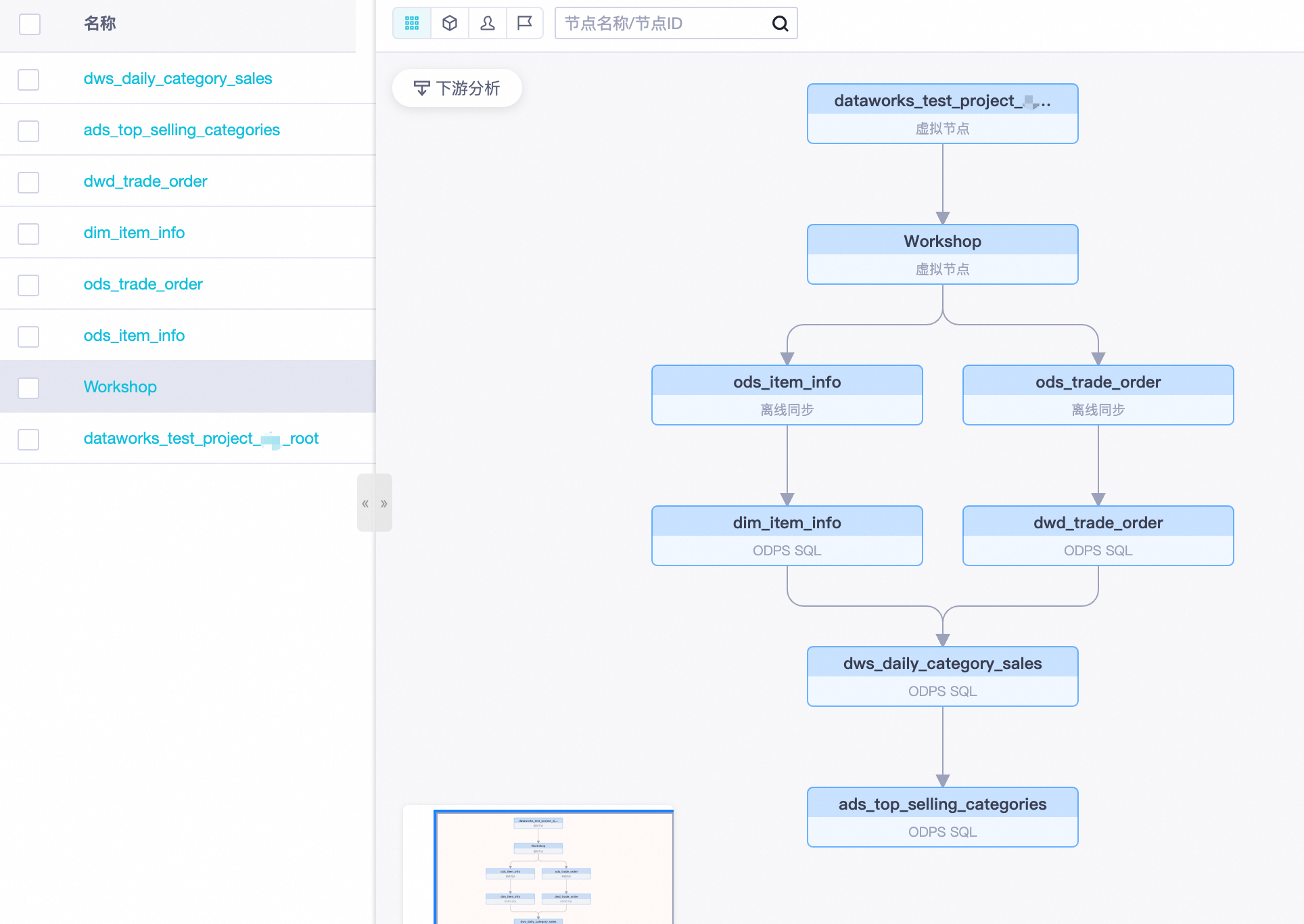
2. 依赖管理
2.1 背景与演进
- GOPATH
- Go Vendor
- Go Module
2.2 GOPATH
GOPATH是Go语言支持的一个环境变量,vlue是Go项目的工作区。

目录有以下结构:
- src:存放Go项目的源码(项目代码直接依赖src下的代码)
- pkg:存放编译的中间产物,加快编译速度
- bin:存放Go项目编译生成的二进制文件
go get下载最新版本的包到src目录下。
弊端:不同项目不能依赖同一个库的不同版本。
2.3 Go Vendor

Vendor是当前项目中的一个目录,其中存放了当前项目依赖的副本。在Vendor机制下,如果当前项目存在Vendor目录,会优先使用该目录下的依赖,如果依赖不存在,会从GOPATH中寻找。通过每个项目引入一份依赖的副本,解决了多个项目需要同一个package依赖的冲突问题。
项目目录下增加vendor文件,所有依赖包副本形式放在$ProjectRoot/vendor
依赖寻址方式:vendor=>GOPATH
但vendor无法很好解决依赖包的版本变动问题和一个项目依赖同一个包的不同版本的问题。
弊端:

- 无法控制依赖的版本变动问题和一个项目依赖同一个包的不同版本的问题
- 更新项目又可能出现依赖冲突,导致编译出错
2.4 Go Module
Go Modules是Go语言官方推出的依赖管理系统,解决了之前依赖管理系统存在的诸如无法依赖同一个库的多个版本等问题,go module从Go1.11开始实验性引入,Go1.16默认开启,一般读为go mod。
2.4.1 依赖管理三要素
1.配置文件,描述依赖 go.mod
2.中心仓库管理依赖库 Proxy
3.本地工具 go get/mod
2.4.2 依赖配置——go.mod
依赖的原生sdk版本最下面是单元依赖,每个依赖单元用模块路径+版本来唯一标示。

依赖标识:[Module Path][Version/Pseudo-version]
模块路径用来标识一个模块,从模块路径可以看出从哪里找到该模块,如果是github前缀则表示可以从Github仓库找到该模块,依赖包的源代码由github托管,如果项目的子包想被单独引用,则需要通过单独的init go.mod文件进行管理。
2.4.3 依赖配置——version

go path和go vendor都是源码副本方式依赖,没有版本规则概念,而go mod为了放方便管理定义了版本规则,分为语义化版本和基于commit的伪版本。
语义化版本包括不同的MAJOR、MINOR、PATCH。
- MAJOR版本表示是不兼容的API,所以即使是同一个库,MAJOR版本不同也会被认为是不同的模块。
- MINOR版本通常是新增函数或功能,前后兼容。
- PATCH版本一般是修复bug。
基于commit的伪版本包括基础版本前缀、时间戳和12位哈希码前缀。
- 基础版本前缀是和语义化版本一样的。
- 时间戳,也就是提交Commit的时间。
- 校验码(
abcdefabcdef),包含12位的哈希前缀,每次提交commit后Go都会默认生成一个伪版本号。
2.4.4 依赖配置——indirect
-
indirect后缀,表示go.mod对应的当前模块,没有直接导入该依赖模块的包,也就是非直接依赖,标示间接依赖。
-
incompatible,主版本2+模块会在模块路径增加
/vN后缀,这能让go module按照不同的模块来处理同一个项目不同主版本的依赖。
由于go module是1.11实验性引入所以这项规则提出之前已经有一些仓库打上了2或者更高版本的tag了,为了兼容这部分仓库,对于没有go.mod文件并且主版本在2或者以上的依赖,会在版本号后加上+incompatible后缀。

2.5 依赖配置——回源
github是比较常见的代码托管系统平台,而Go Modules系统中定义的依赖,最终可以对应到多版本代码管理系统中某一项目的特定提交或版本,对于go.mod中定义的依赖,则直接可以从对应仓库中下载指定软件依赖,从而完成依赖分发。
但直接使用版本管理仓库下载依赖,存在多个问题。
- 无法保证构建确定性:软件作者可以直接代码平台增加/修改/删除软件版本,导致下次构建使用另外版本的依赖,或者找不到依赖版本。
- 无法保证依赖可用性:依赖软件作者可以直接代码平台删除软件,导致依赖不可用。
- 大幅增加第三方代码托管平台压力。
2.5 依赖分发——Proxy

Go Proxy是一个服务站点,它会缓源站中的软件内容,缓存的软件版本不会改变,并且在源站软件删除之后依然可用,从而实现了供"immutability’"和"available’"的依赖分发;使用Go Proxy之后,构建时会直接从Go Proxy站点拉取依赖。
2.6 依赖分发——变量 GOPROXY

Go Modulesi通过GOPROXY环境变量控制,GOPROXY是一个Go Proxy站点URL列表,使用"direct”表示源站。对于示例配置,整体的依赖寻址路径,会优先从proy1下载依赖,如果proxy1不存在,后下钻proxy2寻找,如果proy2,中不存在则会回源到源站直接下载依赖,缓存到proy站点中。
2.7 工具——go get

2.7 工具——go mod

尽量提交之前执行下go tidy,减少构建时无效依赖包的拉取。
3. 测试
3.1 分类

- 回归测试一般是QA同学手动通过终端回归一些固定的主流程场景。
- 集成测试是对系统功能维度做测试验证。
- 单元测试测试开发阶段,开发者对单独的函数、模块做功能验证
层级从上至下,测试成本逐渐减低,而测试覆盖率确逐步上升,所以单元测试的覆盖率一定程度上决定这代码的质量。
3.2 单元测试

单元测试主要包括,输入,测试单元,输出,以及校对。
单元的概念比较广,包括接口,函数,模块等;用最后的校对来保证代码的功能与我们的预期相符;单测可以保证质量,在整体覆盖率足够的情况下,一定程度上既保证了新功能本身的正确性,又未破坏原有代码的正确性。可以提升效率,在代码有bug的情况下,通过编写单测,可以在一个较短周期内定位和修复问题。
3.2.1 单元测试——规则

3.2.2 单元测试——覆盖率
- 一般覆盖率:50%~60%,较高覆盖率80%+。
- 测试分支相互独立、全面覆盖。
- 测试单元粒度足够小,函数单一职责。
3.2.3 单元测试——依赖
单测需要保证稳定性和幂等性,稳定是指相互隔离,能在任何时间,任何环境,运行测试。幂等是指每一次测试运行都应该产生与之前一样的结果。要实现这一目的就要用到mock机制。

单测需要依赖本地的文件,如果文件被修改或者删除测试就会fail。为了保证测试case的稳定性,我们对读取文件函数进行mock,屏蔽对于文件的依赖。
工具:monkey https://github.com/bouk/monkey
是一个开源的mock测试库,可以对method,或者实例的方法进行mock反射,指针赋值。
Mockey Patch的作用域在Runtime,在运行时通过通过Go的unsafe包,能够将内存中函数的地址替换为运行时函
数的地址。将待打桩函数或方法的实现跳转。

通过patch对Readfineline进行打桩mock,默认返回ine110。
通过deferf卸载mock,这样整个测试函数就摆脱了本地文件的束缚和依赖。

3.3 基准测试
Go语言还提供了基准测试框架,基准测试是指测试一段程序的运行性能及耗费CPU的程度。







![[Unity Demo]从零开始制作空洞骑士Hollow Knight第二十集:制作专门渲染HUD的相机HUD Camera和画布HUD Canvas](https://i-blog.csdnimg.cn/direct/bef698481c144956bb0bce1d6490b548.png)