1.什么是Spring Cloud Data Flow?
Spring Cloud Data Flow 是一个用于构建和编排数据处理流水线的云原生框架。它提供了一种简化的方式来定义、部署和管理数据处理任务和流应用程序。以下是一些关键特性和组件:
关键特性
-
流处理:
- 支持实时数据流处理,可以通过定义源、处理器和接收器来构建数据流。
-
批处理任务:
- 支持批处理任务的调度和执行,适用于需要定期运行的任务。
-
可扩展性:
- 支持多种数据处理引擎,如 Apache Kafka、RabbitMQ 和 Apache Spark,允许用户根据需求选择合适的技术栈。
-
可视化界面:
- 提供基于 Web 的用户界面,用户可以通过拖放组件来设计数据流和任务。
-
监控和管理:
- 提供监控和管理工具,可以查看应用程序的运行状态、日志和指标。
组件
-
Spring Cloud Data Flow Server:
- 核心组件,负责管理和协调数据流和任务的部署。
-
Skipper:
- 用于应用程序的版本管理和滚动更新,确保在更新过程中最小化停机时间。
-
数据流应用程序:
- 由 Spring Boot 构建的微服务应用程序,分为源、处理器和接收器三种类型。
-
任务应用程序:
- 用于执行一次性任务或批处理作业。
Spring Cloud Data Flow 适用于需要处理大规模数据流和批处理任务的场景,特别是在分布式系统和云环境中。它简化了数据管道的开发和管理,使开发者能够专注于业务逻辑的实现
2.环境搭建
docker-compose.yml
version: '3'services:mysql:image: mysql:5.7.25container_name: dataflow-mysqlenvironment:MYSQL_DATABASE: dataflowMYSQL_USER: rootMYSQL_ROOT_PASSWORD: rootpwexpose:- 3306ports:- "3306:3306"volumes:- ./my.cnf:/etc/mysql/my.cnfkafka-broker:image: confluentinc/cp-kafka:5.3.1container_name: dataflow-kafkaexpose:- "9092"environment:- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka-broker:9092- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181- KAFKA_ADVERTISED_HOST_NAME=kafka-broker- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1depends_on:- zookeeperzookeeper:image: confluentinc/cp-zookeeper:5.3.1container_name: dataflow-kafka-zookeeperexpose:- "2181"environment:- ZOOKEEPER_CLIENT_PORT=2181dataflow-server:image: springcloud/spring-cloud-dataflow-server:2.6.3container_name: dataflow-serverports:- "9393:9393"environment:- spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.brokers=PLAINTEXT://kafka-broker:9092- spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.streams.binder.brokers=PLAINTEXT://kafka-broker:9092- spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.binder.zkNodes=zookeeper:2181- spring.cloud.dataflow.applicationProperties.stream.spring.cloud.stream.kafka.streams.binder.zkNodes=zookeeper:2181- spring.cloud.skipper.client.serverUri=http://skipper-server:7577/api- SPRING_DATASOURCE_URL=jdbc:mysql://mysql:3306/dataflow- SPRING_DATASOURCE_USERNAME=root- SPRING_DATASOURCE_PASSWORD=rootpw- SPRING_DATASOURCE_DRIVER_CLASS_NAME=org.mariadb.jdbc.Driverdepends_on:- kafka-brokerentrypoint: "./wait-for-it.sh mysql:3306 -- java -jar /maven/spring-cloud-dataflow-server.jar"volumes:- ${HOST_MOUNT_PATH:-.}:${DOCKER_MOUNT_PATH:-/root/scdf}app-import:image: springcloud/openjdk:2.0.0.RELEASEcontainer_name: dataflow-app-importdepends_on:- dataflow-servercommand: >/bin/sh -c "./wait-for-it.sh -t 180 dataflow-server:9393;wget -qO- 'http://dataflow-server:9393/apps' --post-data='uri=${STREAM_APPS_URI:-https://dataflow.spring.io/kafka-maven-latest&force=true}';echo 'Stream apps imported'wget -qO- 'http://dataflow-server:9393/apps' --post-data='uri=${TASK_APPS_URI:-https://dataflow.spring.io/task-maven-latest&force=true}';echo 'Task apps imported'"skipper-server:image: springcloud/spring-cloud-skipper-server:2.5.2container_name: skipperports:- "7577:7577"- "20000-20105:20000-20105"environment:- SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_LOCAL_ACCOUNTS_DEFAULT_PORTRANGE_LOW=20000- SPRING_CLOUD_SKIPPER_SERVER_PLATFORM_LOCAL_ACCOUNTS_DEFAULT_PORTRANGE_HIGH=20100- SPRING_DATASOURCE_URL=jdbc:mysql://mysql:3306/dataflow- SPRING_DATASOURCE_USERNAME=root- SPRING_DATASOURCE_PASSWORD=rootpw- SPRING_DATASOURCE_DRIVER_CLASS_NAME=org.mariadb.jdbc.Driverentrypoint: "./wait-for-it.sh mysql:3306 -- java -jar /maven/spring-cloud-skipper-server.jar"volumes:- ${HOST_MOUNT_PATH:-.}:${DOCKER_MOUNT_PATH:-/root/scdf}启动
docker-compose -f .\docker-compose.yml up -d
dashboard
http://localhost:9393/dashboard/
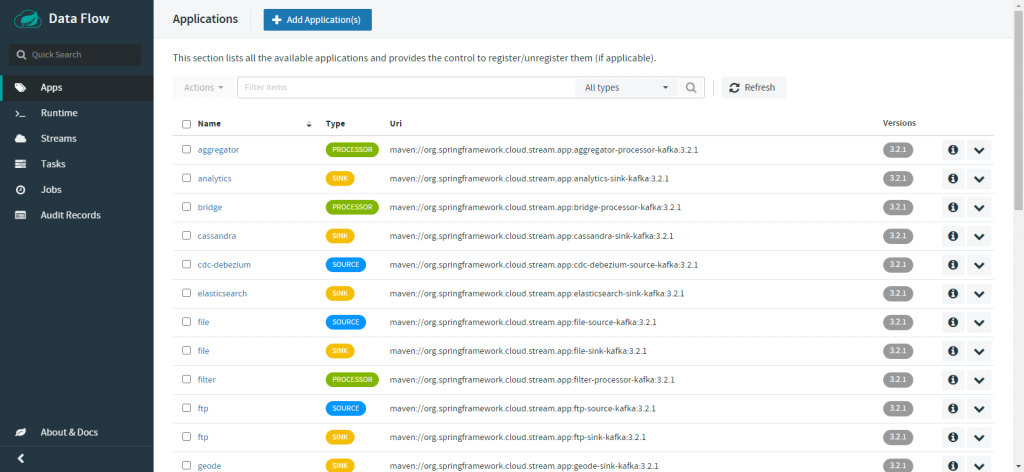
以上只是一些关键代码,所有代码请参见下面代码仓库
代码仓库
- https://github.com/Harries/springcloud-demo(Spring Cloud Data Flow)
3.使用指南
Task
任务处理用于一次性或批量数据处理,适合处理需要在特定时间点或周期性执行的任务。任务应用程序通常具有以下特性:
-
一次性执行:
- 任务在被触发时执行一次,完成后即停止。
- 适用于需要定期运行的批处理作业,如数据迁移、报告生成和数据清理。
-
批处理支持:
- 可以处理大量数据,通常与 Spring Batch 集成以支持复杂的批处理需求。
- 支持事务管理、重试机制和并行处理。
任务应用程序适用于需要在后台执行的长时间运行作业,特别是在需要处理大量数据的情况下
任务列表
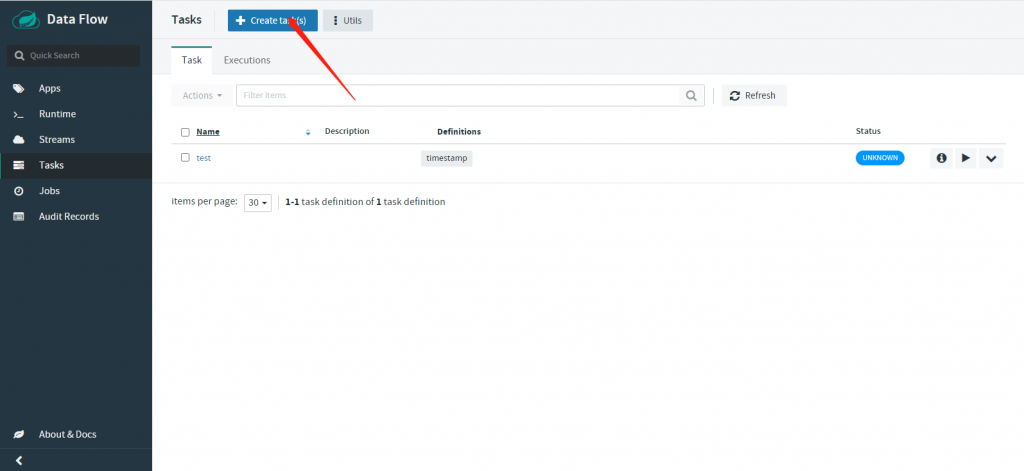
创建任务
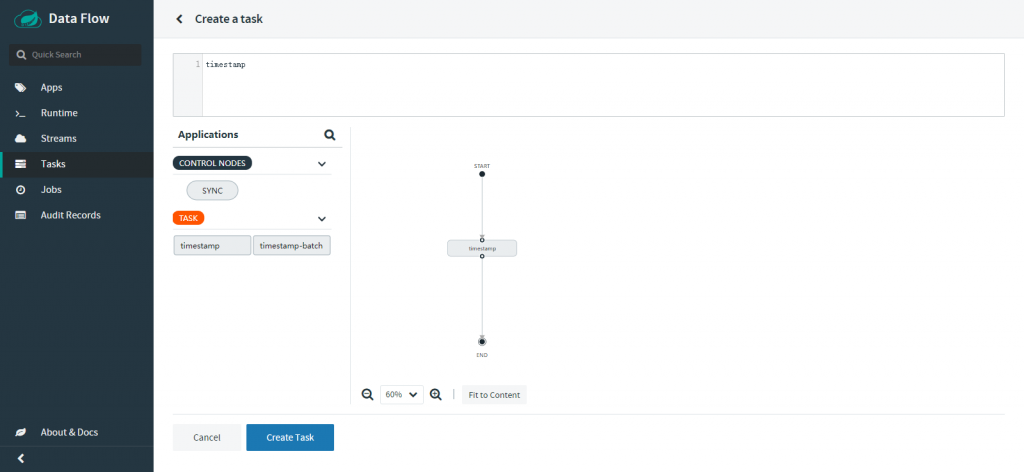
streams
流处理主要用于实时数据处理,适合处理持续不断的数据流。流应用程序通常由以下三种组件组成:
-
源(Source):
- 负责从外部系统(如消息队列、数据库、文件系统等)读取数据并将其发送到流中。
- 例如,从 Kafka 主题中读取消息。
-
处理器(Processor):
- 接收源发送的数据,对其进行处理或转换,然后将结果发送到下一个组件。
- 例如,对数据进行过滤、聚合或格式转换。
-
接收器(Sink):
- 负责将处理后的数据输出到目标系统(如数据库、文件系统、消息队列等)。
- 例如,将处理后的数据写入到数据库表中。
流应用程序通常用于需要低延迟和高吞吐量的场景,如实时数据分析、事件驱动架构和物联网数据处理。
streams列表

stream创建

4.引用
- Spring Cloud Data Flow
- Spring Cloud Data Flow快速入门Demo | Harries Blog™