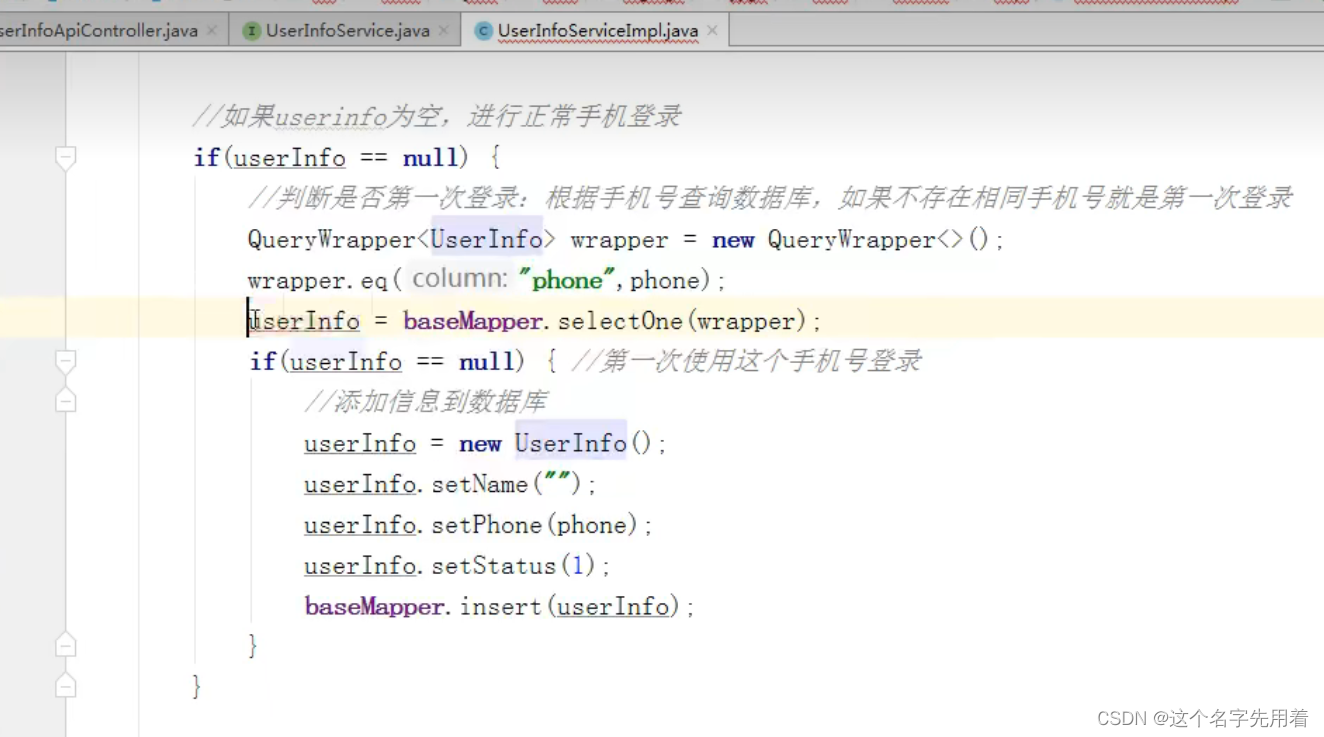
作者 | 布道
11 月 6 日,湖南卫视已经开播被称作年度压轴的大戏“猎场”,迅速占领各大榜单,成为一部高热度的电视剧。但是在豆瓣上却形成了两极分化。截止 11 月 8 日,该剧在豆瓣上的评分为 5.7 分。相比较胡歌之前《琅琊榜》的 9.1,《伪装者》的 8.3 等来说,这一评分确实不高。有趣的是,首页的评分比例与“短评”、“剧评”的比例存在非常大的差异!

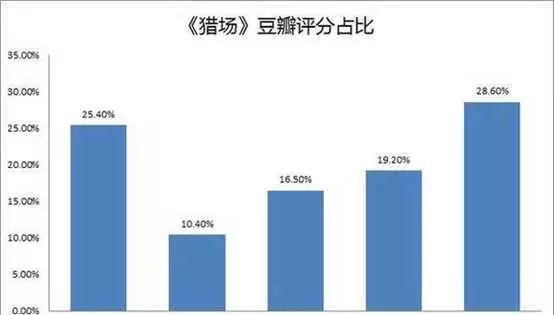
首页总评分评分两级分化严重,“差评”占主 在目前 11463 个评价中两级分化严重,“1 星”占比最高为 28.6%,其次为“5 星”的 25.4%。“好评”(5 星、4 星)占比为 35.80%,“一般”(3 星)为 16.50%,“差评”(2 星、1 星)占比为 47.80%。很明显,“差评”占了接近一半的比例。
在短评和剧评中的另一种景象 首页的豆瓣评分中“差评”占比很高,但是在豆瓣的短评和剧评中却是另一番景象。 在目前 5979 条短评中,“好评”占比 71%,“一般”为 5%,“差评”占比 24%。而在 392 条剧评中,“5 星”占了非常高的比例!84.7%的剧评给了“好评”。
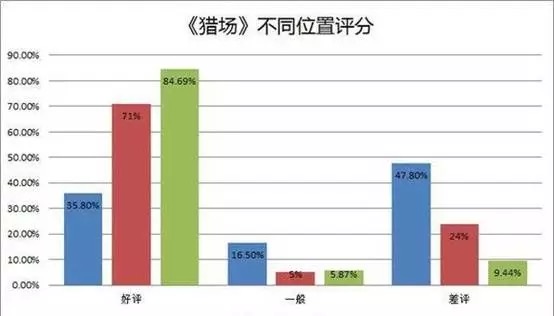
我们将三个位置的评分放在一起比较就会出现非常明显的差异。根据这个差异,我们可以大致判断:写出短评或者剧评的观众大部分给予了“好评”,但仍有大量观众直接给了差评,并没有说明任何原因。当然,我们并没有考虑那些不写评论,而只是点“有用”和“没用”观众。
才刚刚上映,剧情还在慢慢的铺,所以现在给整部剧下定论还太早。
《猎场》到底好不好看?我们还是想通过以 11 月 8 日为界,看看人们短评人的情绪,是积极,还是消息。利用词云看看大家都说了什么,希望能大家就是否建议观看给出建议。
一、爬取《猎场》热门短评,豆瓣的爬虫做的比较好,不登录爬虫很快就会被屏蔽掉,登录后获取 cookies 如下:
同时建议在循环抓取的时候进行 sleep,例如:
time.sleep(1 + float(random.randint(1, 100)) / 20)《猎场》热门短评内容和时间爬取了 22440 条评论,代码如下:
import re
import requests
import codecs
import time
import random
from bs4 import BeautifulSoup
absolute = 'https://movie.douban.com/subject/26322642/comments'
absolute_url = 'https://movie.douban.com/subject/26322642/comments?start=23&limit=20&sort=new_score&status=P&percent_type='
url = 'https://movie.douban.com/subject/26322642/comments?start={}&limit=20&sort=new_score&status=P'
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0','Connection':'keep-alive'}
def get_data(html):soup=BeautifulSoup(html,'lxml')comment_list = soup.select('.comment > p')next_page= soup.select('#paginator > a')[2].get('href')date_nodes = soup.select('..comment-time')return comment_list,next_page,date_nodes
if __name__ == '__main__':f_cookies = open('cookie.txt', 'r')cookies = {}for line in f_cookies.read().split(';'):name, value = line.strip().split('=', 1)cookies[name] = valuehtml = requests.get(absolute_url, cookies=cookies, headers=header).contentcomment_list = []# 获取评论comment_list, next_page,date_nodes= get_data(html,)soup = BeautifulSoup(html, 'lxml')comment_list = []while (next_page != []): #查看“下一页”的A标签链接print(absolute + next_page)html = requests.get(absolute + next_page, cookies=cookies, headers=header).contentsoup = BeautifulSoup(html, 'lxml')comment_list, next_page,date_nodes = get_data(html)with open("comments.txt", 'a', encoding='utf-8')as f:for node in comment_list:comment = node.get_text().strip().replace("\n", "")for date in date_nodes:date= node.get_text().strip()f.writelines((comment,date) + u'\n')time.sleep(1 + float(random.randint(1, 100)) / 20)二、对数据进行清洗:
import pandas as pd
import matplotlib.pyplot as plt
date_name=['date','comment']
df = pd.read_csv('./comment.csv',header=None,names=date_name,encoding= 'gbk')
df['date'] = pd.to_datetime(df['date'])样本数量:
print(df['date'].value_counts())
获取2017-11-06 – 2017-11-08 数据: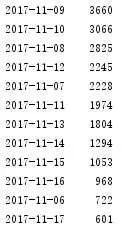
data6 = df['2017-11-06':'2017-11-08']
data6.to_csv('6.txt', encoding = 'utf-8', index = False)
print(data6.size)
5775
获取2017-11-09 – 2017-11-17 数据:
data9 = df['2017-11-09':'2017-11-17']
data9.to_csv('9.txt', encoding = 'utf-8', index = False)
print(data9.size)
16665三、情感分析和词云
对热门短评基于原有 SnowNLP 进行积极和消极情感分类,读取每段评论并依次进行情感值分析(代码:https://zhuanlan.zhihu.com/p/30107203),最后会计算出来一个 0-1 之间的值。

当值大于 0.5 时代表句子的情感极性偏向积极,当分值小于 0.5 时,情感极性偏向消极,当然越偏向两边,情绪越偏激。
2017-11-06 – 2017-11-08 分析:
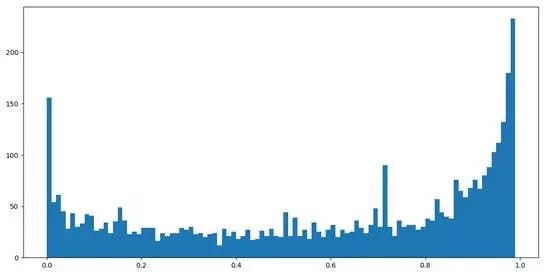
从上图情感分析(代码:https://zhuanlan.zhihu.com/p/30107203 )来看,影评者还是还是非常积极的,对《猎场》的期望很高。
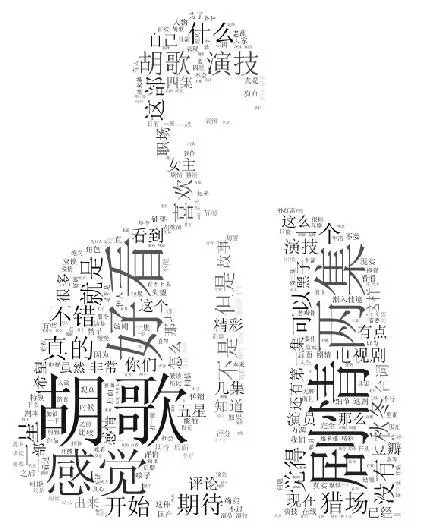
从词云(代码:https://zhuanlan.zhihu.com/p/30107203 )上来看:
2017-11-09 – 2017-11-17 分析
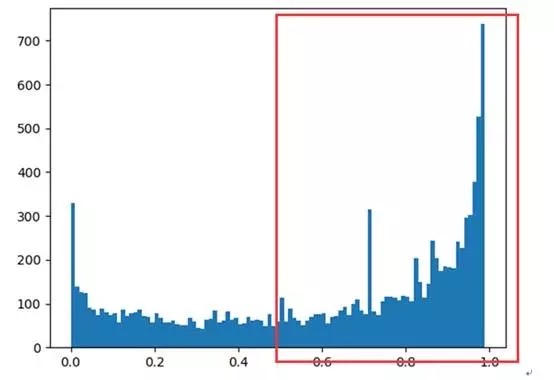
从上图情感分析(代码:https://zhuanlan.zhihu.com/p/30107203 )来看,积极的情绪已经远远超过消极的情绪,还是受到大家的好评。

从词云(代码:https://zhuanlan.zhihu.com/p/30107203 )上来看,出现好看、剧情、期待、喜欢等词。
总结
词云的背景是胡歌,大家看出来了嘛?目前豆瓣的分数已经是 6.2 分,目前剧情过半,相信接下来会更精彩,个人认为分数会在 7.5 分以上。

抛开豆瓣的推荐分数,通过的热门短评的情感和词云分析,是一部不错的现实剧,剧情犀利、深刻、启迪,很多人期待。如果您有时间,不妨看一下,或许能收获一些意想不到的东西。