题目《Transfer learning with graph neural networks for improved molecular property prediction in the multi-fidelity setting》
这篇文章主要讨论了如何在多保真数据环境(multi-fidelity setting)下,利用图神经网络(GNNs)结合迁移学习技术,改进分子性质预测的效果。
研究背景:
在分子性质预测中,不同来源的数据通常具有不同的保真度:
- 低保真数据:便宜、容易获取,但预测精度较低(如粗粒度模拟数据)。
- 高保真数据:更准确,但代价昂贵(如实验测量或高精度量子化学计算)
-
迁移学习的基本方法
-
迁移学习(Transfer Learning)是解决多保真问题的一种策略,分为两个步骤:
-
预训练(Pre-training):
- 在低保真数据集 DSD_SDS 上训练模型,学习低保真领域的特征。
- 结果是一个在低保真任务上的预测器 fSf_SfS。
-
微调(Fine-tuning):
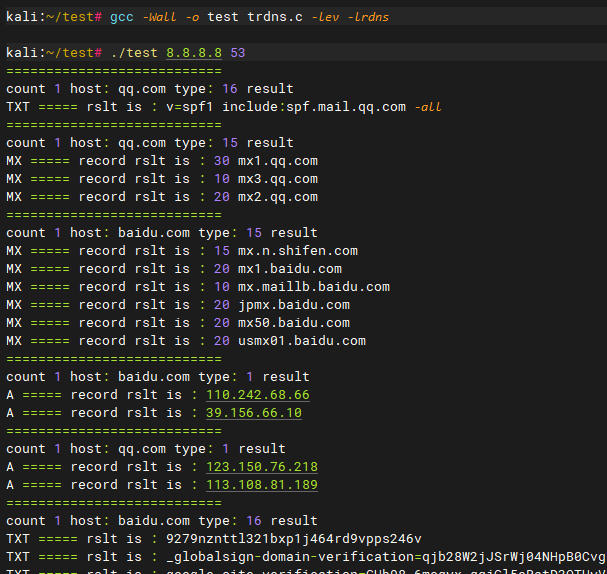
- 将预训练模型的部分权重迁移到高保真任务的模型 fTf_TfT,并在高保真数据集 DTD_TDT 上进行微调。
- 通常,模型的一些层会被冻结(如图卷积层),只训练其余部分,以避免过拟合并减少计算复杂度。
图神经网络中的实现
在 GNN 框架下,模型可以分为两部分:
- 图卷积层(GCN layers):提取图结构的特征。
- 读出层(Readout layers):将图卷积层的输出转换为最终预测。
冻结策略:
GNN 的迁移学习可以根据冻结部分的不同分为以下三种方法:
- 冻结图卷积层,训练读出层:只更新输出部分,适合低保真和高保真领域特征相似的场景。
- 训练图卷积层,冻结读出层:对图结构进行进一步调整。
- 全部可训练:不冻结任何层,适合当领域间差异较大时。
文章中的实验结果表明,冻结图卷积层、训练读出层的效果最好。
方法:
迁移学习

:带自适应读出层的图神经网络(GNN) 和 监督式变分图自动编码器(VGAE)

基于图神经网络的多保真度数据迁移学习结构图
图神经网络中的标准读出函数(如求和、求平均和求最大值)没有任何参数,因此不适合迁移学习任务。本文提出了一种新的神经网络架构读出函数,它能够将学习到的节点表示聚合为图嵌入。在微调阶段,固定图神经网络中负责学习节点表示的部分,并在小样本的下游任务中微调读出层。本文采用了集合Transformer读出函数,保留了标准读出函数的排列不变性特性。因为图可以看作节点的集合,本文利用这种架构作为图神经网络的读出函数。
在该Transformer中,编码器由多个经典的多头注意力块组成,但没有位置编码。解码器组件由投影的多头注意力块组成,经过多个自注意力模块链和线性投影块进行进一步处理。与典型的基于集合的神经网络结构只能单独处理单个元素不同,本文提出的自适应读出函数能够建模由邻域聚合方案生成的所有节点表示之间的相互作用。该架构的一个特点是,图表示的维度可以从节点输出的维度和聚合方案中分离出来。
变分图自编码器(VGAE)
变分图自编码器(VGAE)由概率编码器和概率解码器组成。与在向量值输入上操作的标准变分自编码器(VAE)架构不同,VGAE通过图卷积层的叠加得到编码器部分,学习表示隐空间编码高斯分布的参数矩阵μ和σ。该模型通常假设图中存在自环,即邻接矩阵的对角线由1组成。解码器通过sigmoid函数传递隐变量之间的内积,从而重构邻接矩阵中的元素。通过优化证据下界(ELBO)损失函数来训练VGAE,该损失函数由表示学习的重建误差和变分分布q(⋅)与先验p(⋅)之间的Kullback-Leibler散度(KL散度)正则化项组成。由于图的邻接矩阵通常是稀疏的(即Aij=0的元素远多于Aij=1的元素),因此在训练过程中通常对Aij=0的样本进行采样,而不是取所有的负样本。
作者通过在VGAE的表示空间中加入前馈组件,将标签信息引入VGAE的训练优化过程,从而实现了有监督的变分图自编码器。实际上,从传统的VAE过渡到图上的VGAE,再到建模分子结构的VGAE并非简单的过程,主要有以下两个原因:一是原始VGAE只重建图的连通性信息,而不重建节点(原子)特征。这与传统的VAE不同,后者的潜在表示直接针对实际输入数据进行优化。二是对于分子级别的预测任务和潜在空间表示,VGAE的读出功能至关重要。标准读出函数会导致类似完全无监督训练的无信息表示,在迁移学习任务中表现较差。因此,本文提出的监督变分图自编码器在图表示学习方面是一个重要进步,尤其适用于建模具有挑战性的分子任务。















![[ubuntu]编译共享内存读取出现read.c:(.text+0x1a): undefined reference to `shm_open‘问题解决方案](https://i-blog.csdnimg.cn/direct/ce94ee59a33a46609c048ed2299578ad.png)