原作者:展贝
原文地址:https://mp.weixin.qq.com/s/nnYCcVtwowvmj7Zn9XLIUg
在当今数据驱动的环境中,理解内存指标和程序行为对于确保应用程序的性能和可靠性至关重要。在依赖实时数据处理和高可用性的行业中尤其如此。通过利用可观测工具,可以深入了解应用程序如何使用内存,识别性能瓶颈,观察系统运行状态。而且随着最近几年业务系统的复杂性增加,很多高负荷的组件,需要更多的内存去运行,而且这些组件对性能的要求又比较严苛。所以通过监控内存指标,分析程序行为并对行为进行异常预测和及时告警就显得很重要。
内存关键指标和行为分析
- 堆栈使用情况:该指标显示当前使用的堆内存与可用堆内存的比例。高堆使用情况可能表明内存泄漏或低效的内存分配。
- 垃圾回收(GC)活动:GC指标揭示垃圾回收的频率,所需时间以及GC的效果。频繁的GC周期可能导致应用程序暂停,从而影响性能。而且过于频繁的GC可能存在对象创建销毁的问题,可以考虑是否重用对象减少创建销毁的过程。
- 内存占用:这衡量应用程序消耗的总内存,包括堆和非堆内存。服务一直存在较大的内存占用可能导致更高的基础设施成本和较低的可扩展性。短时间内较高内存占用,可能表示系统在承受较大流量。或者存在较大的需要计算的流程,而服务计算能力不足导致。
- 内存中TopN的大对象:这部分可以衡量在程序运行中,是否在某一步骤中存在阻塞,比如:一个数据处理的程序,应该是快速消费->快速处理->然后快速输出,如果在这个过程中存在某些对象大量存在,可能会存在某些可以优化的地方(窗口过大,加锁,对象无法销毁等情况)。
系统运行中出现某些故障的时候,内存会有异常波动,具体的原因可能是由于CPU计算能力不足,网络、请求吞吐量、或者服务上下游存在瓶颈。内存的异常只是程序行为的一种表现,具体的根因分析需要结合多种指标和上下流进行分析定位。
在DataBuff平台内,对服务的监控是全面的,不仅仅包括服务本身,还包括服务所在的环境,以及服务的上下游。在对故障进行分析的时候,也尽可能地分析导致程序行为异常的根本原因。尽快协助定位问题,解决问题。
案例:某充电桩业务服务内存系统监控
客户背景
客户是一家专注于电动汽车领域的综合服务平台,通过与充电运营商的合作,提供从充电基础设施建设到充电解决方案,再到车辆租赁及车联网等一系列服务。用户可以通过手机APP轻松完成站点搜索、路线规划、查看充电桩实时状态以及账户充值等多种功能。
客户痛点
每天晚上六点到七点之间的充电高峰时间段内,服务的请求量、数据处理量会在短时间内快速上升,相应的服务内存占用也会飙升。
解决方案
在触发边界(可能导致宕机)之前第一时间发现内存飙升的情况并及时处理,可以有效保障服务的稳定性和可用性(比如:及时调整k8s自动扩容策略,启用备用节点)。
模拟数据展示如下:
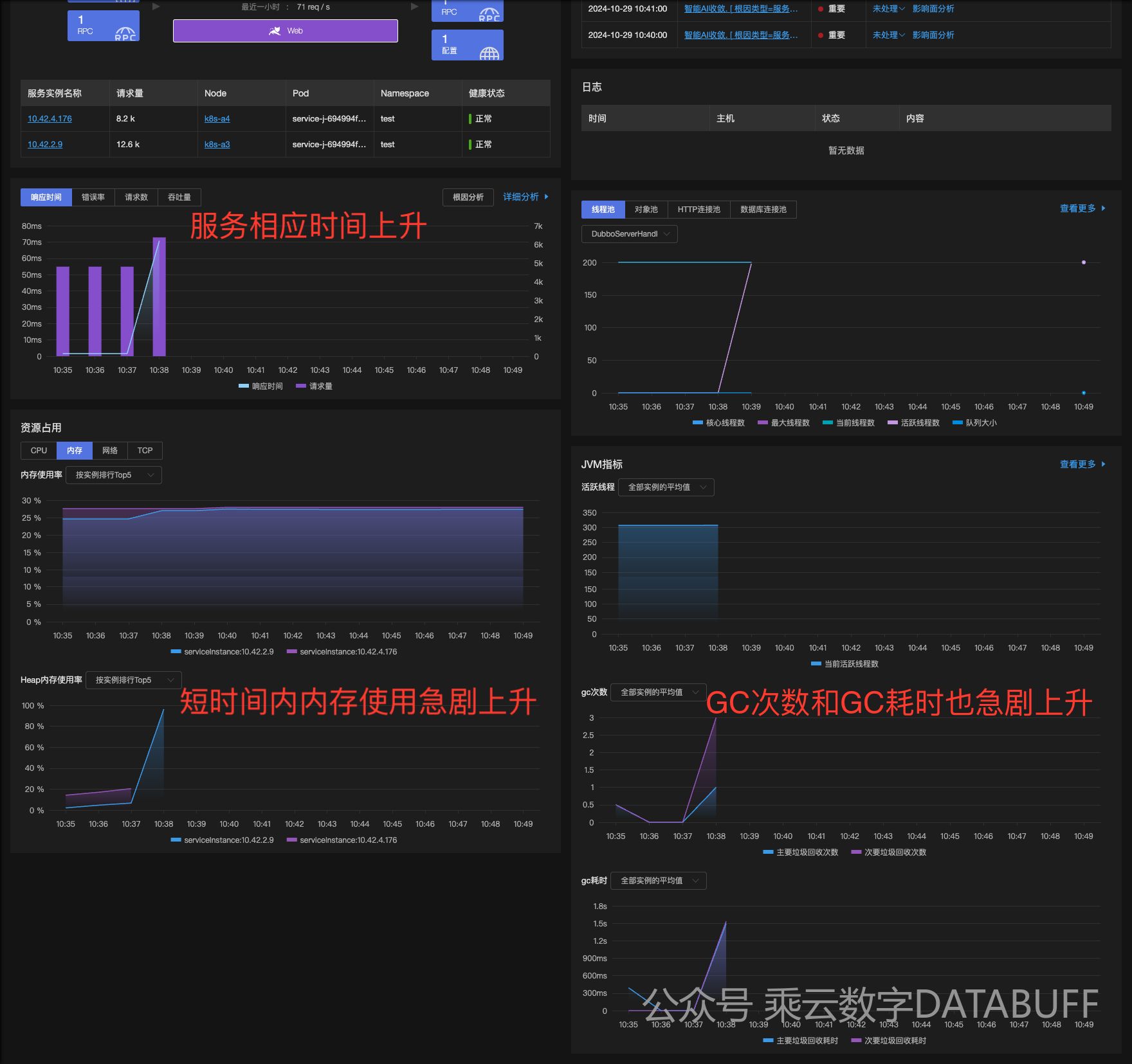
说明:内存使用率一直存在因为pod并没有挂掉,服务OOM了。
内存指标分析
- 短时间内,可以监控到业务系统堆栈使用情况,高峰期间内存消耗激增。
- GC指标显示,GC次数明显增加,GC时间上升,但是每次GC后内存清理效果很差。
- TopN的对象,查看到存在大量的订单无法被及时处理,大量支付订单请求被挤压。
程序行为洞察
共享资源竞争
从内存行为可以分析出,大量用户访问充电系统,并在短暂时间内存在访问大量共享资源(这里指充电桩),导致系统在短时间内要处理大批量的请求信息
下单和充值系统负载
短时间内的请求锁单和进行充值,处理订单系统(核销,优惠,折扣等订单系统内容)吞吐量已经达到最大瓶颈,消费处理延迟,可能需要增加消费者,延迟扣费,错峰交易(对订单进行可容忍时间延迟)
后续措施
有效的全面监控
使用DataBuff不仅能实现对系统内存的监控,还包括服务网络、CPU、请求、以及服务上下游全面的监控。
告警及根因分析
当服务内存指标存在突增风险的情况下,进行及时告警,并对告警内容的上下文进行根因分析,针对性地对业务系统进行主动干预。使用DataBuff平台的智能告警以及告警中的根因分析,帮助运维人员避免服务崩溃带来的灾难性后果。
及时、全面地监控和告警,并进行根因分析。

结论
在高流量平台的背景下,有效的内存管理不仅提高了性能,还增强了用户满意度,推动了业务成功。采用全面的可观测,企业可以释放应用程序的全部潜力,同时将内存管理相关的风险最小化。随着应用程序的日益复杂化,部署可观测性平台可以有效应对不断增长的业务需求,维持业务系统的可靠性和可扩展性。