文件由文件内容和文件属性构成,因此对文件的操作就是对文件内容或文件属性的操作。所谓的“打开一个文件”就是将文件的属性或内容加载到内存中,而没有被打开的文件存在于磁盘上。打开的文件称作“内存文件”,未被打开的文件称作“磁盘文件”。当我们使用一系列文件函数(fopen,fread等)访问文件时,其本质是这些文件程序转换成可执行程序,运行起来后执行对应的代码才是对文件的一系列操作,其实就是进程对文件进行操作。
系统调用和库函数:

open函数
open函数用于打开或创建一个文件的系统调用。
flags有五个选项(严格来说不知五个,目前只了解五个)
- O_RDONLY:以只读的方式打开文件;
- O_WRONLY:以只写的方式打开文件;
- O_RDWR:以读写的方式打开文件;
- O_CREAT:如果文件不存在则创建文件;
- O_TRUNC:如果文件已经存在且为只写或读写,则将其长度截断为0;(即清空文件内容)
close函数
int close(int fd);fd表示要关闭的文件的描述符,是一个非负整数,通常由open等系统调用获得,成功时返回0,出错返回-1。
write函数
ssize_t write(int fd, const void *buf, size_t count);fd表示文件描述符,通常由open这一类系统调用获得,buf表示要写入文件的数据缓冲区指针,count表示要写入缓冲区的字节数,成功时返回写入的字节数,失败时返回-1,并通过errno显示错误类型。
read函数
ssize_t read(int fd, void *buf, size_t count);count表示要读取的最大字节数。read函数将fd文件中的内容读取到buf中。成功时,read返回实际读取的字节数,失败时返回-1,通过errno显示错误信息。read系统调用不会因为'\0'而停止读取,他会一直读取到buf数组的最大值后结束。
open打开不存在文件的权限
使用open函数打开一个不存在的文件时不能使用第一个类型的参数列表,此时创建出来的文件权限存在一个s权限,该权限表示强制位权限,易造成系统安全问题。因此在打开一个不存在文件时要使用第二个参数列表。但是即使我将文件权限设置为777时,按理来说此时文件权限应为"-rwx rwx rwx",但是别忘记文件权限还与umask码有关。默认umask为002,新创建的文件权限结果计算方法为:文件权限&(~umask)。
通过修改umask的值使得创建的文件t1.txt的权限为"-rwx rwx rwx"。




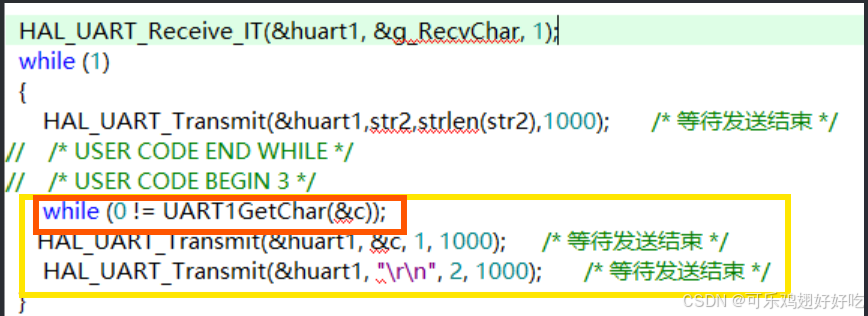
C语言中"w"的底层逻辑
如上图,继续在已经有内容的文件中写入数据,是一种覆盖式的写入,如何做到清空原有数据内容,重新写入数据呢?
将打开文件方式设为"O_TRUNC",表示当文件已经存在时会将其长度截断,也就是清空其内容,这也是C语言函数中fopen("filename","w")的底层逻辑


c语言中"a"的底层逻辑
多次运行./a.out,数据以追加的形式写入到t1.txt文件中,这也是c语言中fopen("t1.txt","a")实现的底层逻辑。

文件描述符
为什么文件描述符从3开始?
验证0.1.2就是标准IO
验证0.1.2对应的就是stdin,stdout,stderr
因为stdin,stdout以及stderr是FILE*类型的指针,而FILE结构体内部封装了_fileno用于存放该FILE指针关联的文件描述符,通过访问_fileno就可以获得其对应的文件描述符。
进程与文件的关系
文件在内存中被打开,一个进程又可以打开多个文件,OS如何对打开的文件进行管理呢。OS通过先描述,再组织的方式,通过构建结构体struct file使各个文件之间通过struct file*指针的方式(类似链表)使各个文件之间建立关系。我们知道进程一旦被创建就会有PCB,也就是task_struct,这个结构体里面就含有struct files_struct* files,其指向的是struct files_struct。在struct files_struct中有含有一个struct file* fd_arr[]数组,该数组专门存放struct file*类型的指针,也就是指向的文件地址即struct file(该结构体内存放各种文件属性)。
那么0、1、2对应的是stdin、stdout、stderr其对应的又是键盘、显示器,如何将这些硬件使用文件描述符对应的呢?
理解这个问题先理解“Linux下一切皆文件”:尽管在计算机中有许多硬件(如硬盘、显示器、网卡等),但是OS仍然能通过类似文件的读写方法对这些硬件进行使用、访问等操作。OS会创建不同的struct file,这其中就包含各种对硬件的读写方法函数指针,OS通过这些函数指针找到函数然后对硬件进行访问。
文件描述符的分配规则
如上图所示,文件描述符会按照数组中最小的空下标进行分配。
重定向的使用
如上图所示,当将数组下标为1的文件描述符指向的内容关闭后(也就是关闭stdout),那么此时ret的值就为1(参考文件描述符的分配规则),此时运行编译后的文件时,write函数直接将内容写到ret指向的文件中,而不会再将“Hello linux”显示在输出设备(因为1对应的是stdout,即显示器)上,而是显示在此时对应的数组中1指向的内容中去(也就是T1.txt文件中)。这就是“重定向”。
使用系统接口实现重定向:这里需要用到dup2函数int dup2(int oldfd, int newfd);该函数用于文件描述符的重定向,其头文件是<unistd.h>,该函数允许将文件描述符newfd重定向到另一个文件描述符oldfd(源文件描述符,也就是要进行重定向的文件描述符),newfd表示目标文件描述符。函数调用成功返回新文件的描述符,失败返回-1,并可以以perror显示错误类型。
重定向使用演示
如上图,第一次演示时,write函数直接将str数据写到了文件描述符1上(也就是显示器),此时虽然创建了T4.txt,但是该文件中没有内容。第二次演示时,通过dup2函数将文件描述符1改为ret(因为dup2(oldfd,newfd),new是old的一份拷贝,也就是说old的值给了new,并且new会被关闭,此时old文件描述符是new),因此这里1已经被改为ret(也就是T4.txt)。所以再次write时就会写到T4.txt文件中。
如上图,对T4.txt进行追加内容的操作,在第二次演示中,通过read函数从0(对用的就是stdin,键盘)中读取数据,并将数据写到str(注意:代码第23行中,read函数第三个参数有误,)。第三次演示中,重定向文件描述符0为ret,也就是T4.txt,此时fgets函数就从T4.txt文件中获取数据。
缓冲区的概念
缓冲区存在的意义在于解放使用缓冲区的进程的时间(例如啊当一个进程要打印数据在显示器上时,进程会将数据放入缓冲区,之后该进程就去执行自己的代码了),并且缓冲区可以集中数据刷新,减少IO次数,从而提高整机的效率。
在左边代码中printf通过\n刷新缓冲区,内容会立即被刷新到显示器中。在右边代码中,printf没有\n刷新缓冲区,因此数据不会立即被刷新。而write函数又是立即刷新的,printf函数又封装了write函数,那么write函数的缓冲区在哪里?首先肯定的是write函数的缓冲区一定不在wirte函数内部,如果write函数缓冲区在write函数内部,那么printf函数即使没有\n也应该立即刷新缓冲区(因为printf函数封装了write函数,而write函数又是立即刷新缓冲区的),显然右边代码演示就否定的这一判断。其实write函数的缓冲区由C语言提供的,是一种语言级别的缓冲区。因此在C语言中每次打开一个文件时,都会有一个FILE*返回(fopen函数),每一个文件都有一个fd和一个属于他自己的语言缓冲区。
在printf(包括fprintf,fputs等函数)中都显示或隐式的包含stdout,而stdout又是FILE*类型的,而FILE是一个结构体,其内部包含各种属性,其中包含fd以及FILE对应的语言级别的缓冲区,也就是说FILE内部封装了自己的缓冲区。因此当printf打印数据时,此时数据会被先存储到stdout对应的缓冲区中,当数据达到缓冲区的容量时,此时OS就会刷新缓冲区,将数据写到硬件上,从而达到减少IO次数,提高整机效率,减少进程使用缓冲区的时间。
那么缓冲区什么时候刷新一次合适呢(也就是刷新策略)?如果缓冲区还没刷新但是关闭了文件描述符?
刷新策略:
- 行缓冲:逐行刷新
- 全缓冲:缓冲区满才刷新,(磁盘)
- 无缓冲:立即刷新
- 强制刷新:fflush
- 进程退出。