***************************************************
码字不易,收藏之余,别忘了给我点个赞吧!
***************************************************
---------Start
本文不涉及tensorflow环境配置过程,只讲解整个项目代码大致内容。至于每个函数的每个参数意义,同学们可以百度了解或私信我,见谅!
第一部分(自定义模型结构)
数据集:二分类数据集,每个类别包含一个文件夹,文件夹中都保存了对应类别的图像数据。
Normal类
Tuberculosis类
1、项目结构
train.py:训练文件
test.py:测试文件
class_indices.json 类别信息文件(训练网络时自动生成)
our_model.py 模型文件
weights:权重文件(训练完毕之后,自动生成权重文件)

预先解释一下,训练一次:表示一部分(batch_size)数据送入网路,输出结果。
训练一轮:表示将训练集中的全部数据都训练一次。epoch表示训练的轮数。
2、train.py
2.1 配置路径
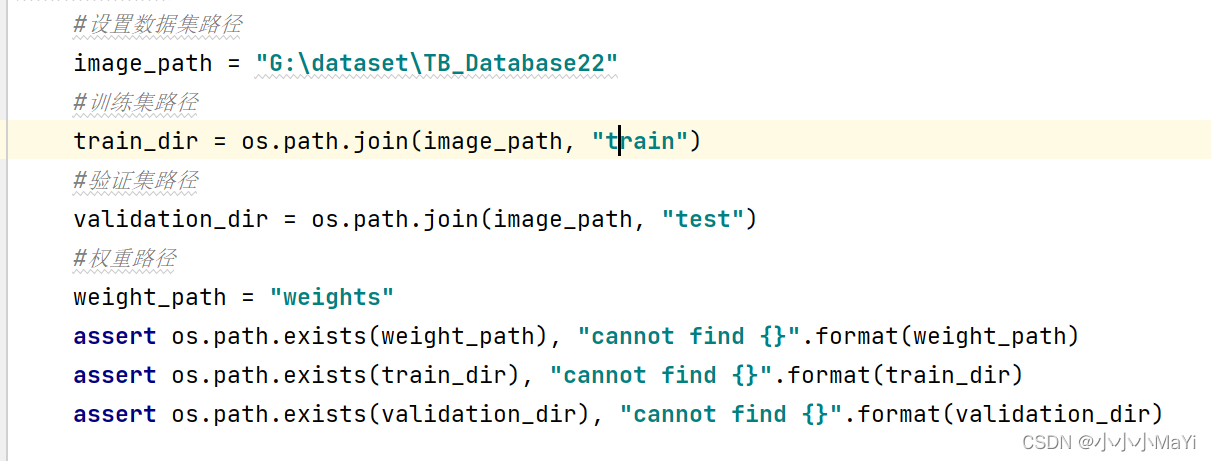
2.2 参数配置

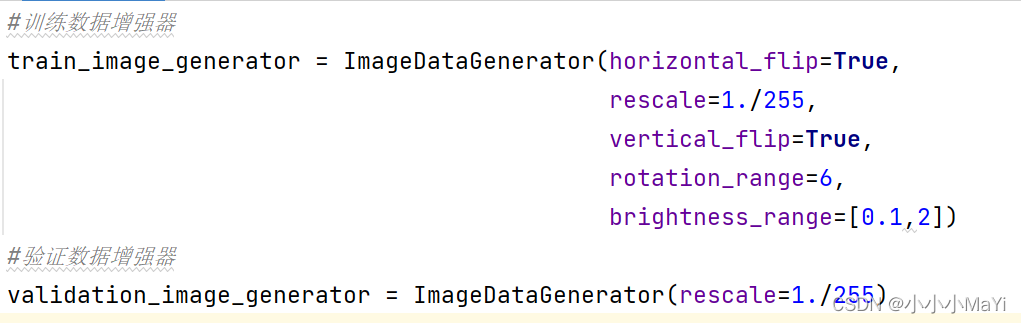
2.3 声明训练集和验证集数据增强器
增强器的作用是对数据进行预处理(归一化,翻转,旋转等等)
2.4 根据增强器生成打包后的数据
对数据集中的图像数据应用增强器生成网络所需要格式的数据

2.5 将数据集读取的标签形式写入文件
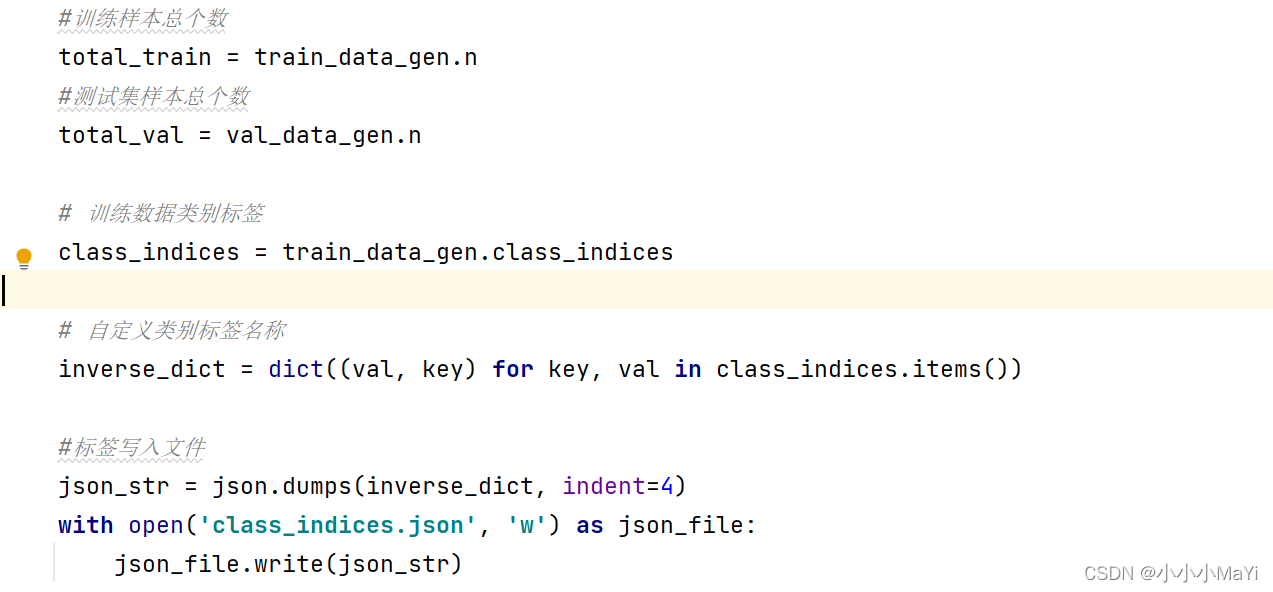
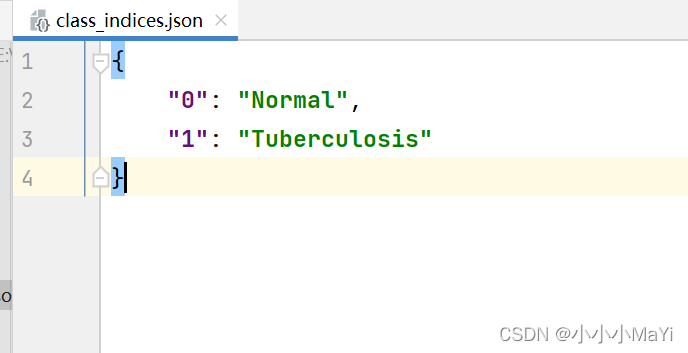
写入文件的内容如下图所示。本文任务是两个类别,0,1分别代表两个类别的编码,Normal和Tuberculosis分别代表两个类别的名称。
2.6 创建模型,损失函数,优化器和评价指标
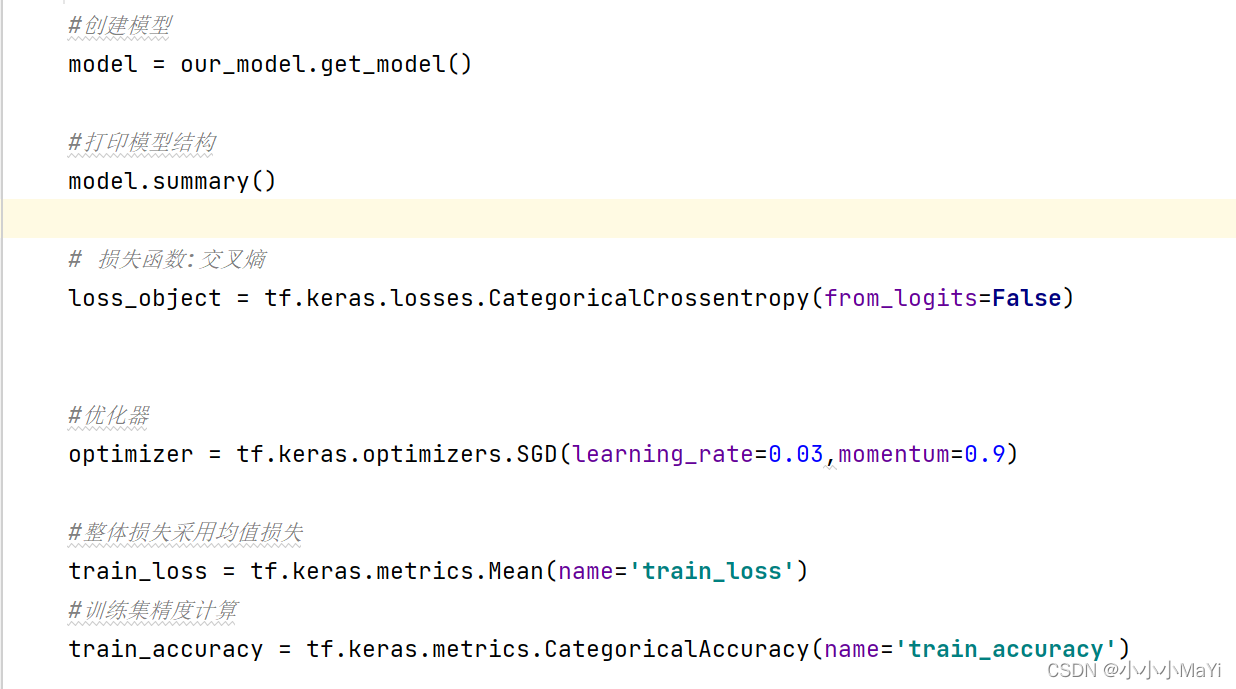

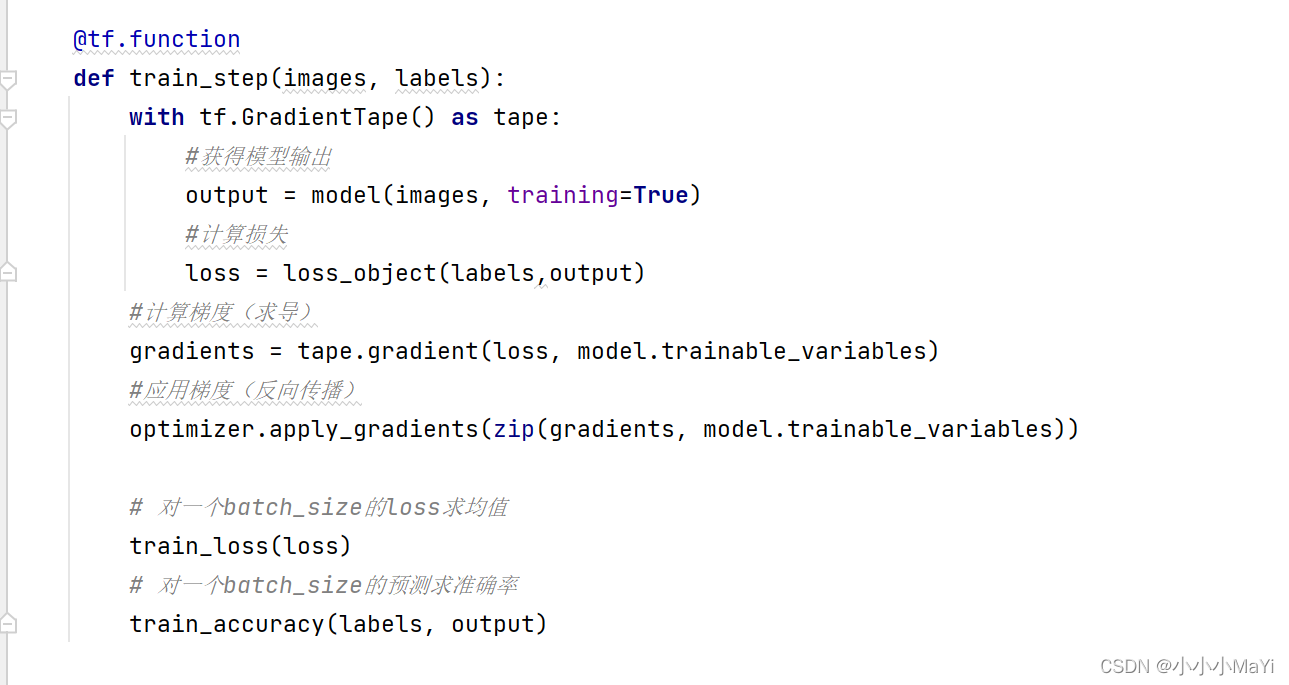
2.7 训练一次模型的函数
执行过程为:模型训练一次,计算损失,计算并更新梯度,计算精度。
2.8 验证一次模型的函数
执行过程为:模型训练一轮完毕后进行验证,计算损失,计算精度。验证过程不更新梯度。

2.9 开始epoch轮的训练
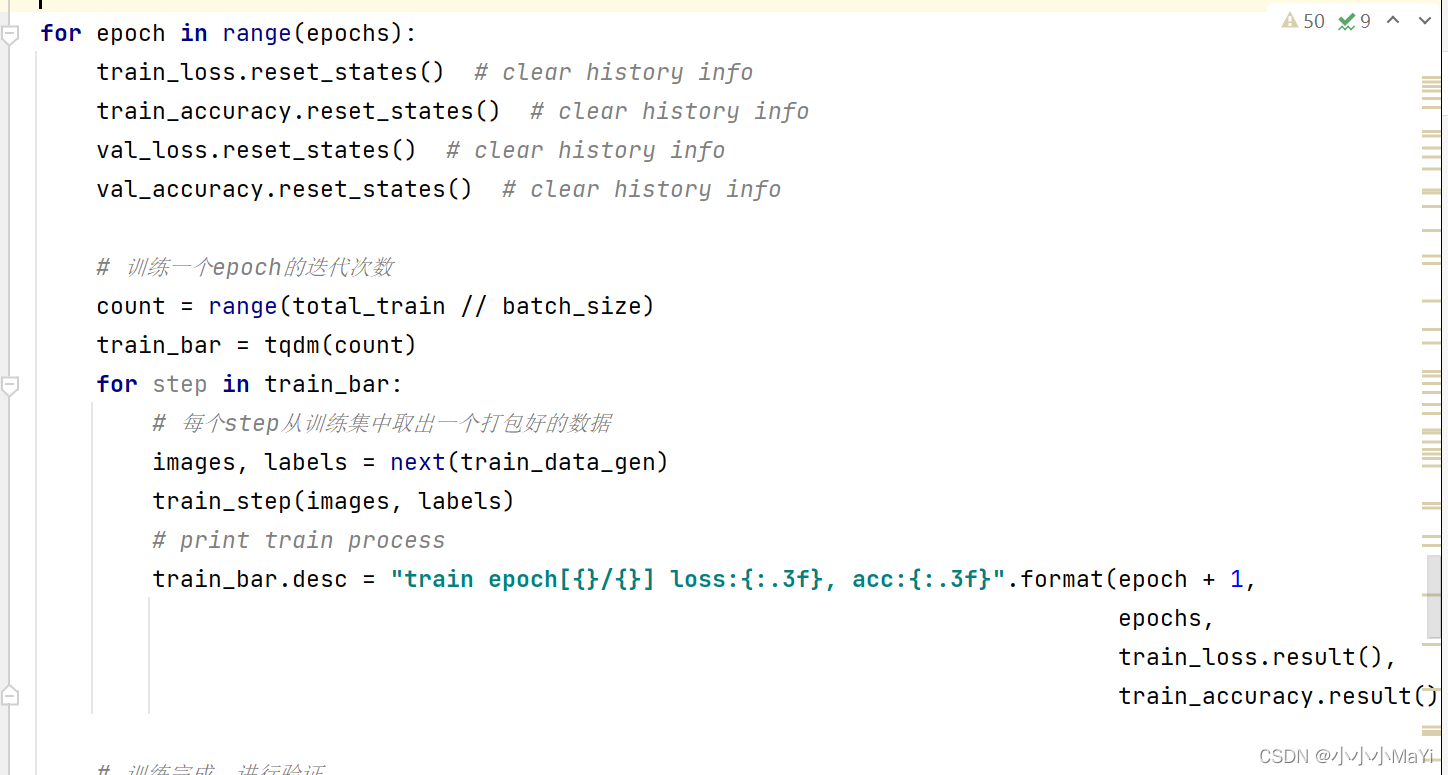
2.10 训练一轮后进行验证

2.11 记录精度和损失并保存权重
验证完成后,记录训练和验证过程的精度和损失,并保存模型权重。

2.12 模型训练成功
若出现以下效果,表示模型训练成功。

2.13 全部代码(our_model.py)
from tensorflow.keras import layers,Modeldef get_model():#输入层input_image = layers.Input(shape=(128, 128, 3), dtype="float32")#卷积层(输出通道数,卷积核大小,卷积步长)x = layers.Conv2D(filters=16, kernel_size=3, strides=2,use_bias=False)(input_image)#归一化层x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)#激活函数x = layers.ReLU()(x)x = layers.Conv2D(32, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(64, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(128, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(256, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(256, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.GlobalAvgPool2D(name="avgPool")(x) # 1*1*128 特征降维# DropOut层(失活比例)x = layers.Dropout(rate=0.5)(x)#全连接层(全连接层个数,激活函数)x= layers.Dense(units=100,activation="relu")(x)x= layers.Dropout(rate=0.5)(x)x = layers.Dense(2, name="logits")(x)#softmax层,保证输出的结果是[0,1]的概率值predict = layers.Softmax()(x)#构建模型model = Model(inputs=input_image, outputs=predict,name='tb_model')return model2.14 全部代码(train.py)
import os
# os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"#使用cpu进行训练
# os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
import json
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tqdm import tqdm
from train_models import our_modeldef main():#设置数据集路径image_path = "G:\dataset\TB_Database22"#训练集路径train_dir = os.path.join(image_path, "train")#验证集路径validation_dir = os.path.join(image_path, "test")#权重路径weight_path = "weights"assert os.path.exists(weight_path), "cannot find {}".format(weight_path)assert os.path.exists(train_dir), "cannot find {}".format(train_dir)assert os.path.exists(validation_dir), "cannot find {}".format(validation_dir)#参数配置#送入网络的图像大小im_height = 256im_width = 256#一次送入多少张图像到网络中batch_size = 4#训练总次数epochs = 2#学习率lr = 0.001#训练数据增强器train_image_generator = ImageDataGenerator(horizontal_flip=True,rescale=1./255,vertical_flip=True,rotation_range=6,brightness_range=[0.1,2])#验证数据增强器validation_image_generator = ImageDataGenerator(rescale=1./255)#生成训练集数据加载器train_data_gen = train_image_generator.flow_from_directory(directory=train_dir,batch_size=batch_size,shuffle=True,target_size=(im_height, im_width),class_mode='categorical')#生成验证集数据加载器val_data_gen = validation_image_generator.flow_from_directory(directory=validation_dir,batch_size=batch_size,shuffle=True,target_size=(im_height, im_width),class_mode='categorical')#训练样本总个数total_train = train_data_gen.n#测试集样本总个数total_val = val_data_gen.n# 训练数据类别标签class_indices = train_data_gen.class_indices# 自定义类别标签名称inverse_dict = dict((val, key) for key, val in class_indices.items())#标签写入文件json_str = json.dumps(inverse_dict, indent=4)with open('class_indices.json', 'w') as json_file:json_file.write(json_str)print("using {} images for training, {} images for validation.".format(total_train,total_val))#创建模型model = our_model.get_model()#打印模型结构model.summary()# 损失函数:交叉熵loss_object = tf.keras.losses.CategoricalCrossentropy(from_logits=False)#优化器optimizer = tf.keras.optimizers.SGD(learning_rate=lr,momentum=0.9)#整体损失采用均值损失train_loss = tf.keras.metrics.Mean(name='train_loss')#训练集精度计算train_accuracy = tf.keras.metrics.CategoricalAccuracy(name='train_accuracy')#验证集损失val_loss = tf.keras.metrics.Mean(name='val_loss')#验证集精度计算val_accuracy = tf.keras.metrics.CategoricalAccuracy(name='val_accuracy')@tf.functiondef train_step(images, labels):with tf.GradientTape() as tape:#获得模型输出output = model(images, training=True)#计算损失loss = loss_object(labels,output)#计算梯度(求导)gradients = tape.gradient(loss, model.trainable_variables)#应用梯度(反向传播)optimizer.apply_gradients(zip(gradients, model.trainable_variables))# 对一个batch_size的loss求均值train_loss(loss)# 对一个batch_size的预测求准确率train_accuracy(labels, output)@tf.functiondef val_step(images, labels):output = model(images, training=False)loss = loss_object(labels, output)val_loss(loss)val_accuracy(labels, output)best_val_acc = 0.trainloss=[]trainaccuracy = []valloss=[]valaccuracy = []for epoch in range(epochs):train_loss.reset_states() # clear history infotrain_accuracy.reset_states() # clear history infoval_loss.reset_states() # clear history infoval_accuracy.reset_states() # clear history info# 训练一个epoch的迭代次数count = range(total_train // batch_size)train_bar = tqdm(count)for step in train_bar:# 每个step从训练集中取出一个打包好的数据images, labels = next(train_data_gen)train_step(images, labels)# print train processtrain_bar.desc = "train epoch[{}/{}] loss:{:.3f}, acc:{:.3f}".format(epoch + 1,epochs,train_loss.result(),train_accuracy.result())# 训练完成,进行验证val_bar = tqdm(range(total_val // batch_size))for step in val_bar:test_images, test_labels = next(val_data_gen)val_step(test_images, test_labels)# print val processval_bar.desc = "valid epoch[{}/{}] loss:{:.3f}, acc:{:.3f}".format(epoch + 1,epochs,val_loss.result(),val_accuracy.result())#一个epoch之后,记录loss和acctrainloss.append(train_loss.result().numpy())trainaccuracy.append(train_accuracy.result().numpy())valloss.append(val_loss.result().numpy())valaccuracy.append(val_accuracy.result().numpy())# 仅仅保存最优的权重if val_accuracy.result() > best_val_acc:best_val_acc = val_accuracy.result()model.save_weights(weight_path+"\epoch{}-acc{:.3f}-loss{:.3f}_newModel.ckpt".format(epoch,val_accuracy.result(),val_loss.result()),save_format='tf')print("trainloss:{}".format(trainloss))print("trainaccuracy:{}".format(trainaccuracy))print("valloss:{}".format(valloss))print("valaccuracy:{}".format(valaccuracy))
if __name__ == '__main__':main()2.15 全部代码(test.py)
import glob
from time import timeimport numpy as np
import os
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tqdm import tqdm
import tensorflow as tf
from train_models.our_model import get_model
from tool import genConfusionMatrix
from tool import roc_auc#加载测试集
rootpath=r"G:\dataset\TB_Database22\test"
assert os.path.exists(rootpath), "cannot find {}".format(rootpath)
tf.compat.v1.enable_eager_execution(config=None,device_policy=None,execution_mode=None
)im_height = 224
im_width = 224
batch_size = 2#创建模型
model =get_model()
weights_path = r'./weights/epoch0-acc0.500-loss0.717_newModel.ckpt'
assert len(glob.glob(weights_path + "*")), "cannot find {}".format(weights_path)#加载权重
model.load_weights(weights_path)#测试集数据归一化
test_image_generator = ImageDataGenerator(rescale=1./255)#创建数据集生成器,打包测试集数据
test_data_gen = test_image_generator.flow_from_directory(directory=rootpath,target_size=(im_height,im_width),batch_size=batch_size,class_mode='sparse',shuffle=False)
#获取所有的测试集样本数
total_test = test_data_gen.n#测试过程验证集进度条
val_bar = tqdm(range(total_test // batch_size))#预测类别
result = np.array([],dtype=int)
#真实类别
label = np.array([],dtype=int)times = 0.0for step in val_bar:#加载测试数据test_images, test_labels = next(test_data_gen)start = time()#将一个batch数据送入网络,获得输出data_numpy = model(test_images, training=False)#记录测试的时间times+=(time()-start)#转化成numpy格式data_numpy = data_numpy.numpy()#获取预测结果result = np.append(result,data_numpy.argmax(axis=1))#获得真实标签label = np.append(label,test_labels)end = time()print("耗费时间:",times/total_test)
#计算所需要的指标
label = label.astype(np.int8)
matrix = genConfusionMatrix(2,result,label)
matrix_se = matrix[1][1]/(matrix[1][0]+matrix[1][1])
matrix_sp = matrix[0][0]/(matrix[0][1]+matrix[0][0])
matrix_acc = (matrix[0][0]+matrix[1][1])/np.sum(matrix)
matrix_auc = roc_auc(label,result)
matrix_pre = matrix[1][1]/(matrix[0][1]+matrix[1][1])
matrix_youden = matrix_se+matrix_sp-1
print("混淆矩阵:")
print(matrix)
print("matrix_se",matrix_se)
print("matrix_sp",matrix_sp)
print("matrix_auc",matrix_auc)
print("matrix_acc",matrix_acc)
print("matric_pre",matrix_pre)
print("约登指数",matrix_youden)
print("weights_path:", weights_path)第二部分(迁移学习)
第一部分是我们自定义的模型结构并实现了训练过程,这个部分我们使用tensorflow.keras自带的模型结构和预训练好的权重来实现迁移学习(transfer learning)。在预训练权重之上继续训练模型,既节省了训练时间又可以达到不错的准确率。
使用MobileNetV2实现迁移学习
此时,主要修改our_mode.py文件, 新增MobileNetV2模型结构,而train.py, test.py只需要修改模型调用的代码。在our_model.py新增如下代码:
修改的原理:去掉MobileNetV2的全连接分类部分,换成我们自定义的分类部分(根据分类任务确定),这样修改后的网络结构仍然可以使用官网的权重,实现迁移学习。
def get_MobileNetV2():feature = MobileNetV2(input_shape=(224,224,3),include_top=False,weights='imagenet')#冻结feature层不训练,只训练除feature层之外的层。feature.trainable=Falsemodel = Sequential([feature,layers.GlobalAveragePooling2D(),layers.Dense(1000, activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2,activation='relu')layers.Softmax()],name='MobileNetV2')return model
导包代码:
from tensorflow.keras.applications import MobileNetV2,NASNetMobile,InceptionV3,ResNet50
在train.py,test.py中改变模型的调用:
#创建模型model = get_MobileNetV2()
至此,迁移学习对于代码修改的部分已经完毕,执行train.py开始训练。
说明
tensorflow.keras提供了很多官方网路结构,通过语句from tensorflow.keras.applications import 模型名称 可以直接使用,初次调用模型时会自动联网下载好权重,再次调用模型时则不需要联网。在此,我将自己的our_model.py放在文末,需要的小伙伴可以直接拿去用哦。
from tensorflow.keras import layers,Model,Sequential
from tensorflow.keras.applications import MobileNetV2,NASNetMobile,InceptionV3,ResNet50,VGG16,ResNet101,DenseNet121def get_model():#输入层input_image = layers.Input(shape=(128, 128, 3), dtype="float32")#卷积层(输出通道数,卷积核大小,卷积步长)x = layers.Conv2D(filters=16, kernel_size=3, strides=2,use_bias=False)(input_image)#归一化层x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)#激活函数x = layers.ReLU()(x)x = layers.Conv2D(32, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(64, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(128, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(256, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.Conv2D(256, kernel_size=3, strides=2,use_bias=False)(x)x = layers.BatchNormalization(momentum=0.9, epsilon=1e-5)(x)x = layers.ReLU()(x)x = layers.GlobalAvgPool2D(name="avgPool")(x) # 1*1*128 特征降维# DropOut层(失活比例)x = layers.Dropout(rate=0.5)(x)#全连接层(全连接层个数,激活函数)x= layers.Dense(units=100,activation="relu")(x)x= layers.Dropout(rate=0.5)(x)x = layers.Dense(2, name="logits")(x)#softmax层,保证输出的结果是[0,1]的概率值predict = layers.Softmax()(x)#构建模型model = Model(inputs=input_image, outputs=predict,name='tb_model')return modeldef get_MobileNetV2():feature = MobileNetV2(input_shape=(224,224,3),include_top=False,weights='imagenet')feature.trainable=Falsemodel = Sequential([feature,layers.GlobalAveragePooling2D(),layers.Dense(1000,activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2),layers.Softmax()],name='MobileNetV2')return modeldef get_NASNetMobile():feature = NASNetMobile(input_shape=(224,224,3),include_top=False,weights='imagenet')model = Sequential([feature,layers.GlobalAveragePooling2D(),layers.Dense(1000, activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2),layers.Softmax()],name='NASNetMobile')return modeldef get_InceptionV3():feature = InceptionV3(input_shape=(299,299,3),include_top=False,weights='imagenet')model = Sequential([feature,layers.GlobalAveragePooling2D(),layers.Dense(1000, activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2),layers.Softmax()],name='NASNetMobile')return modeldef get_ResNet50():feature = ResNet50(input_shape=(224, 224, 3), include_top=False, weights='imagenet')feature.trainable=Falsemodel = Sequential([feature,layers.GlobalAveragePooling2D(),layers.Dense(1000, activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2),layers.Softmax()],name='ResNet50')return modeldef get_vgg16():feature = VGG16(input_shape=(224,224,3),include_top=False, weights='imagenet')feature.trainable=Falsemodel = Sequential([feature,layers.Flatten(),layers.Dense(1000, activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2, activation='softmax')],name='Vgg16')return modeldef get_ResNet101():feature = ResNet101(input_shape=(224, 224, 3), include_top=False, weights='imagenet')feature.trainable=Falsemodel = Sequential([feature,layers.GlobalAveragePooling2D(),layers.Dense(1000, activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2),layers.Softmax()],name='ResNet101')return modeldef get_DenseNet121():feature = DenseNet121(input_shape=(224, 224, 3), include_top=False, weights='imagenet')feature.trainable=Falsemodel = Sequential([feature,layers.GlobalAveragePooling2D(),layers.Dense(1000, activation='relu'),layers.Dense(1000, activation='relu'),layers.Dense(2),layers.Softmax()],name='ResNet101')return model