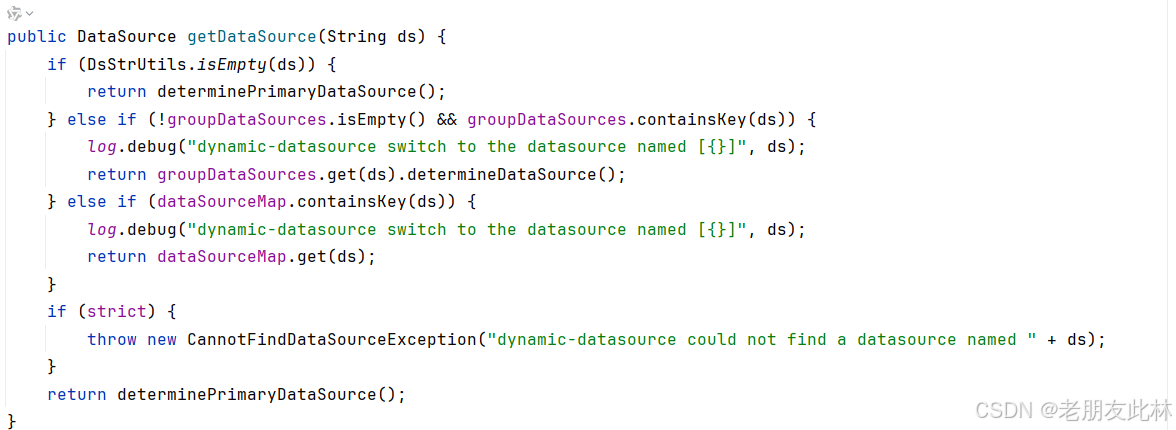
其中了解self-attention知道他的计算量是
Global Context Attention计算量变少从变成

NL:
(a)首先resize成C×HW然后通过1×1的卷积生成q,k,v,然后q乘 变成HW×HW,然后通过softmax进行归一化然后和v进行乘,再通过1×1的卷积,再和原图进行相加也就是特征融合
由于不同位置的q对应热图几乎一致,因此可以共用一张热图,从而简化成(b)

再通过数学技巧把 提出来,最后变成:



再借鉴se模块,将se的思路先降维后升维,这样减少计算量,并且加入了ln层更加稳定,形成最后的GCblock.