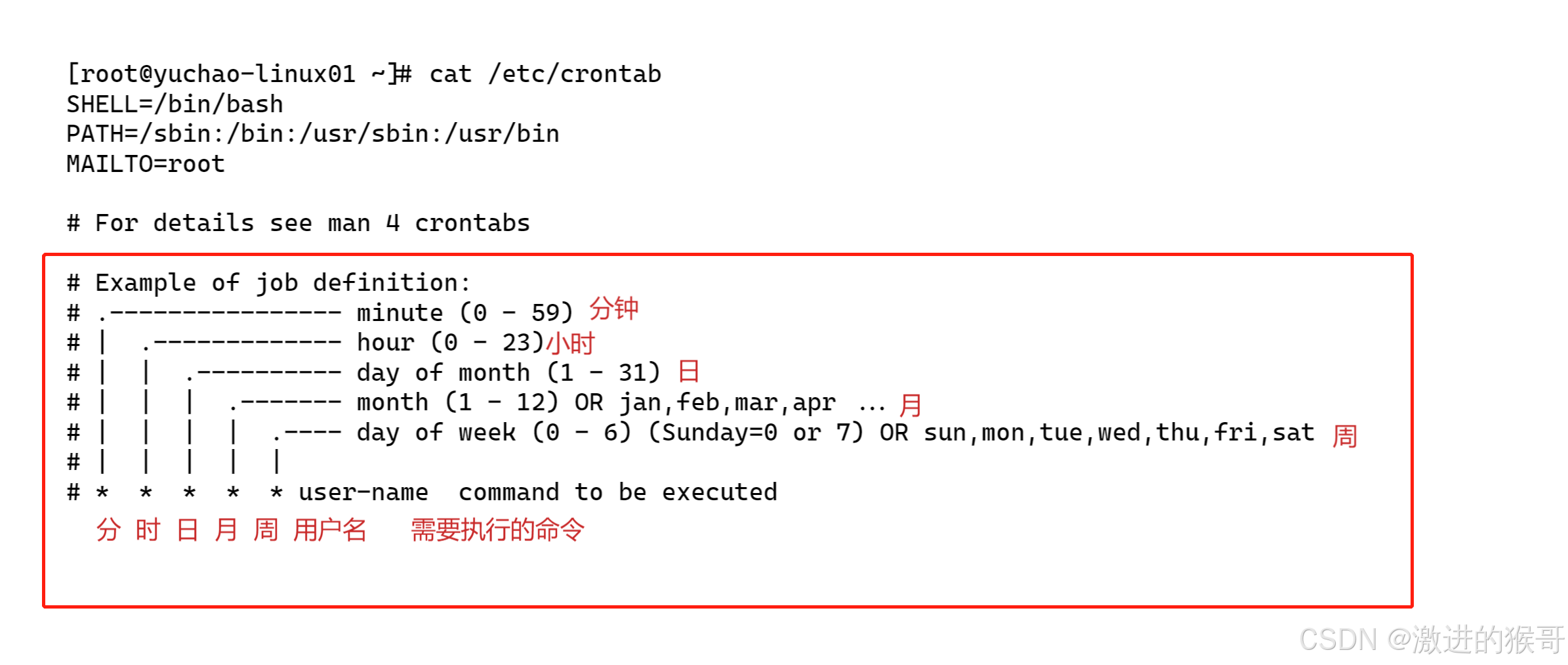
参考:https://juejin.cn/post/6870837414852886542#heading-9
一般计算大文件的md5都是前端来做,因为如果后端来做,那得等到上传成功后才能计算md5值,并且读取的时间也很长。
为了解决文件大传输慢的问题,前端可以通过分片读取的方式来读取文件,并进行分片,将分片的数据传给后端,当传输完成后,由后端完成合并转码的操作。
tips:计算md5和分片传输本质都是分片来完成的,但不应该放一起或有关联,因为只有计算完md5值后我们才知道后端有没有这个大文件,从而实现秒传;有关联是指不应该把读取后的数据放到全局变量中,在分片传输时直接用不需要读,因为这样会导致客户端内存过大
实现了大文件上传的分片、合并、秒传、断点续传
前端
计算大文件md5
使用spark-md5来计算大文件的md5值,Spark-md5实现了在浏览器中对文件进行哈希计算,每次会将填充后的消息和64位表示原始消息长度的数拼接到一起,形成一个新的消息,这也就不会造成读取大文件的内存非常大,我们只需要对该大文件进行分片读并将读取到的分片数据给到 Spark-md5 帮我们计算
计算hash值
抽样计算hash值
代码和策略如下:
/*** 计算文件的hash值,计算的时候并不是根据所用的切片的内容去计算的,那样会很耗时间,我们采取下面的策略去计算:* 1. 第一个和最后一个切片的内容全部参与计算* 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算* 这样做会节省计算hash的时间*/
const calculateHash = async (fileChunks: Array<{file: Blob}>) => {return new Promise(resolve => {const spark = new sparkMD5.ArrayBuffer()const chunks: Blob[] = []fileChunks.forEach((chunk, index) => {if (index === 0 || index === fileChunks.length - 1) {// 1. 第一个和最后一个切片的内容全部参与计算chunks.push(chunk.file)} else {// 2. 中间剩余的切片我们分别在前面、后面和中间取2个字节参与计算// 前面的2字节chunks.push(chunk.file.slice(0, 2))// 中间的2字节chunks.push(chunk.file.slice(CHUNK_SIZE / 2, CHUNK_SIZE / 2 + 2))// 后面的2字节chunks.push(chunk.file.slice(CHUNK_SIZE - 2, CHUNK_SIZE))}})const reader = new FileReader()reader.readAsArrayBuffer(new Blob(chunks))reader.onload = (e: Event) => {spark.append(e?.target?.result as ArrayBuffer)resolve(spark.end())}})
}
计算全量hash值
异步处理
//计算文件的md5值
const computeMd5 = (fileItem) => {let file = fileItem.filelet blobSize = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice //获取file对象的slice方法,确保在每个浏览器都能获取到const fileSize = file.sizelet chunks = computeChunks(fileSize)let currentChunkIndex = 0 //当前读到第几个分片,最开始为0let spark = new SparkMD5.ArrayBuffer();let fileReader = new FileReader();let loadNext = () => {let start = currentChunkIndex * chunkSizelet end = start + chunkSize >= fileSize ? fileSize : start + chunkSizefileReader.readAsArrayBuffer(blobSize.call(file, start, end))}loadNext()return new Promise((resolve, reject) => {let resultFile = getFileItemByUid(file.uid)fileReader.onload = (e) => { //读取成功后调用spark.append(e.target.result)currentChunkIndex++if (currentChunkIndex < chunks) { //继续分片 let percent = Math.floor(currentChunkIndex / chunks * 100)resultFile.md5Progress = percentloadNext()}else{let md5 = spark.end()spark.destroy()resultFile.md5Progress = 100 resultFile.status = STATUS.uploading.valueresultFile.md5 = md5loadNext = nullresolve(resultFile.file.uid)}}fileReader.onerror = (e) =>{ //读取出错调用fileItem.md5Progress = 1fileItem.status = STATUS.fail.valueloadNext = nullresolve(resultFile.file.uid)}}).catch(error=>{loadNext = nullconsole.log(error);return null});
}
web workder 线程处理
这里我们使用js中的多线程worker来计算md5,因为计算md5值很耗费cpu并且会影响页面的性能同时它不能通过异步来解决效率问题,只能一段一段的读取、计算
//hash.js
import SparkMD5 from 'spark-md5'
import { ElMessage } from 'element-plus'const computeChunks = (totalSize, chunkSize) => {return Math.ceil(totalSize / chunkSize)
}
// 生成文件 hash
self.onmessage = e => {let { fileItem } = e.datalet file = fileItem.filelet blobSize = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice //获取file对象的slice方法,确保在每个浏览器都能获取到const fileSize = file.sizeconst chunkSize = 1024 * 1024 * 10 //每个分片10Mlet chunks = computeChunks(fileSize, chunkSize)let currentChunkIndex = 0 //当前读到第几个分片,最开始为0let spark = new SparkMD5.ArrayBuffer();let fileReader = new FileReader();let loadNext = () => {let start = currentChunkIndex * chunkSizelet end = start + chunkSize >= fileSize ? fileSize : start + chunkSizefileReader.readAsArrayBuffer(blobSize.call(file, start, end))}loadNext()fileReader.onload = (e) => { //读取成功后调用spark.append(e.target.result)currentChunkIndex++if (currentChunkIndex < chunks) { //继续分片 let percent = Math.floor(currentChunkIndex / chunks * 100)self.postMessage({percentage: percent,});loadNext()} else {let md5 = spark.end()spark.destroy()self.postMessage({md5,percentage: 100});loadNext = nullself.close(); // 关闭 worker 线程,线程如果不关闭,则会一直在后台运行着,}}fileReader.onerror = (e) => { //读取出错调用console.log(e);self.close();ElMessage.error('读取文件出错')loadNext = null}
};
主线程代码:
let worker = new Worker(new URL('./hash.js', import.meta.url))worker.postMessage({ fileItem: fileItem })fileItem = getFileItemByUid(fileItem.file.uid)worker.onmessage = function (event) {const { md5, percentage } = event.datafileItem.md5Progress = percentageif (md5 != null) {fileItem.status = STATUS.uploading.valuefileItem.md5 = md5callBack(fileItem.file.uid)}}worker.onerror = function (event) {console.log(event);worker.terminate() //出错后关闭子线程}
主线程负责开启子线程并给出文件信息,及时拿到子线程计算的结果即可
分片传输
根据分片结果异步调用后台分片接口实现分片传输
后端
/*** 分片上传接口*/@PostMapping("/common/uploadFile")public BaseResponse<UploadFileInfoResp> commonUploadFile(MultipartFile multipartFile,String fileMd5, //使用md5值来命名临时目录Integer chunkIndex, //当前是第几个分片Integer chunks //总共有多少个分片){if(chunkIndex >= chunks){return ResultUtils.error(CommonErrorEnum.BUSINESS_ERROR.getErrorCode(),"当前分片大于等于总分片");}UploadFileInfoResp uploadFileInfoResp = new UploadFileInfoResp();File tempFileFolder = null;boolean fileIsSuccess = true; // 文件是否上传成功标志,默认成功try{//暂存临时目录String tempFolderName = filePath + tempFolder;tempFileFolder = new File(tempFolderName+fileMd5);if(!tempFileFolder.exists()){ //创建该目录tempFileFolder.mkdirs();}File newFile = new File(tempFileFolder.getPath() + "/" + chunkIndex);if(newFile.exists() && newFile.length() == multipartFile.getSize()){ //断点续传,不需要在重新上传uploadFileInfoResp.setFileStatus(UploadStatusEnum.UPLOADING.getStatus());return ResultUtils.success(uploadFileInfoResp);}multipartFile.transferTo(newFile);uploadFileInfoResp.setFileStatus(UploadStatusEnum.UPLOADING.getStatus());return ResultUtils.success(uploadFileInfoResp);}catch (Exception e){log.error("文件上传失败 ",e);fileIsSuccess = false;}finally {if(!fileIsSuccess && Objects.nonNull(tempFileFolder)){ // 失败,删除临时目录FileUtil.del(tempFileFolder);}}return ResultUtils.success(uploadFileInfoResp);}
后端根据前端的分片信息和数据建一个临时目录,目录以计算的MD5值为命名,并将前端传输的分片的文件先上传到服务器上
前端
前端根据分片大小对大文件进行分片,得到总共有多少片,循环异步向后端发送分片上传请求
const chunkSize = 1024 * 1024 * 10 //每个分片10M
const computeChunks = (totalSize) => {return Math.ceil(totalSize / chunkSize)
}
//执行分片上传逻辑
const uploadFile = async (fileUid, fromChunkIndex) => {let fileItem = getFileItemByUid(fileUid)if (fileItem == undefined) returnif (fromChunkIndex == null) { //如果不是点击暂停继续上传const secondResult = await queryUploadFileApi(fileItem.md5)if (secondResult != null && secondResult.fileStatus == STATUS.upload_seconds.value) { //秒传fileItem.status = STATUS[secondResult.fileStatus].valuefileItem.uploadProgress = 100return;}}let chunkIndex = fromChunkIndex || 0let file = fileItem.filelet fileSize = file.size//分片上传let chunks = computeChunks(fileSize)const taskPool = []const maxTask = 6 //最大异步处理数量for (let i = chunkIndex; i < chunks; i++) {fileItem = getFileItemByUid(fileUid)if (fileItem == null || fileItem.pause) { //处理删除或暂停逻辑await Promise.all(taskPool)if(fileItem != null)recordAllStopChunkIndex.push({uid: file.uid,chunkIndex: i}) //记录暂停的具体信息return;}let start = i * chunkSizelet end = start + chunkSize >= fileSize ? fileSize : start + chunkSizelet chunkFile = file.slice(start, end)const task = uploaderFileApi({file: chunkFile, chunkIndex: i, chunks: chunks, fileMd5: fileItem.md5})task.then(res => {if (res.code == undefined && res.fileStatus === 'uploading' && fileItem != null) { //计算上传速度fileItem.uploadSize = fileItem.uploadSize + chunkFile.sizefileItem.uploadProgress = Math.floor((fileItem.uploadSize / fileSize) * 100)}taskPool.splice(taskPool.findIndex((item) => item === task),1) //清除已经完成的分片请求}).catch(error => { console.log(error); taskPool.splice(taskPool.findIndex((item) => item === task),1) })taskPool.push(task)if (taskPool.length >= maxTask) {await Promise.race(taskPool) //race方法会在这些请求中第一个完成后结束这个阻塞代码,限制最大请求数量}}await Promise.all(taskPool) //将剩下的分片发送并等待所有分片完成
}
因为这里用到了异步请求,那么就需要控制异步请求的最大并发数量,否则就会因为异步请求过多而对页面造成卡顿,我们可以使用异步的race函数,当有一个请求完成后就返回,循环结束后最后在等待未完成的分片上传完毕就可以执行合并操作了
合并
后端
后端根据临时目录的所有分片数据将他们进行合并,操作:依次按分片文件名从小到大读取每个分片文件,并将它写入到一个新的文件里
分片的文件名是按分片的顺序命名的
/*** 合并分片文件接口*/@PostMapping("/union/uploadFile")public BaseResponse<String> unionFile(@Valid UnionFileReq unionFileReq){ //合并文件String tempFolderName = null;try {String fileName = unionFileReq.getFileName();String fileMd5 = unionFileReq.getFileMd5();//文件夹路径String monthDay = DateUtil.format(new Date(),"yyyy-MM-dd");//真实的文件名String realFileName = IdUtils.simpleUUID() + MimeTypeUtils.getSuffix(fileName);//路径String newFilePath = monthDay + "/" + realFileName;//临时目录tempFolderName = filePath + tempFolder + fileMd5;//目标目录String targetFolderName = filePath + monthDay;File targetFolder = new File(targetFolderName);if(!targetFolder.exists()){targetFolder.mkdirs();}//目标文件String targetFileName = filePath + newFilePath;union(tempFolderName,targetFileName,realFileName,true);//合并成功,可以在这里记录数据库}catch (Throwable e){if(Objects.nonNull(tempFolderName)){ // 删除临时目录FileUtil.del(tempFolderName);}return ResultUtils.error(ErrorCode.OPERATION_ERROR);}return ResultUtils.success("ok");}public void union(String dirPath, String toFilePath, String fileName, Boolean del){File dir = new File(dirPath);if(!dir.exists()){throw new BusinessException("目录不存在");}File[] fileList = dir.listFiles(); //获取该目录的所有文件// 按文件名从小到大排序,确保合并顺序正确Arrays.sort(fileList, new Comparator<File>() {@Overridepublic int compare(File file1, File file2) {Integer value1 = Integer.valueOf(file1.getName());Integer value2 = Integer.valueOf(file2.getName());return value1 - value2;}});File targetFile = new File(toFilePath);RandomAccessFile writeFile = null;try{writeFile = new RandomAccessFile(targetFile,"rw");byte [] b = new byte[10 * 1024] ;//一次读取1MBfor (int i = 0; i < fileList.length; i++) {File chunkFile = new File(dirPath + "/" +i);RandomAccessFile readFile = null;try {readFile = new RandomAccessFile(chunkFile,"r");while ( readFile.read(b) != -1 ){writeFile.write(b,0, b.length);}}catch (Exception e){log.error("合并分片失败",e);throw new BusinessException("合并分片失败");}finally {if(Objects.nonNull(readFile))readFile.close();}}} catch (Exception e) {log.error("合并文件:{}失败",fileName,e);throw new RuntimeException(e);}finally {try {if(Objects.nonNull(writeFile))writeFile.close();if(del && dir.exists()){ // 删除临时目录FileUtil.del(dir);}} catch (IOException e) {e.printStackTrace();}}}
前端
在等待所有分片上传完成后调用后端合并接口即可
也就是在原有上传函数在加上一个调用合并接口操作
//所有分片上传完成,执行合并操作unionUploadFileApi({ fileName: file.name, fileMd5: fileItem.md5,pid: fileItem.filePid }).then(res => {if (res == "ok") {fileItem.uploadProgress = 100fileItem.status = STATUS["upload_finish"].value} else {fileItem.status = STATUS["fail"].valuefileItem.errorMsg = res.message}}).catch(error => { console.log(error); fileItem.status = STATUS["fail"].value; fileItem.errorMsg = '合并失败' })
秒传
后端
根据md5去查询数据库有没有上传过即可
/*** 查询大文件的md5值,秒传逻辑*/@PostMapping("/query/uploadFile")public BaseResponse<UploadFileInfoResp> queryUploadFile(String fileMd5){UploadFileInfoResp uploadFileInfoResp = new UploadFileInfoResp();UploadFile queryByMd5 = uploadFileDao.queryByMd5(fileMd5);//秒传if(Objects.nonNull(queryByMd5)){uploadFileInfoResp.setFileStatus(UploadStatusEnum.UPLOAD_SECONDS.getStatus());return ResultUtils.success(uploadFileInfoResp);}return ResultUtils.success(uploadFileInfoResp);}
前端
上文的代码中已经实现了秒传,在计算md5后最开始的地方调用后端秒传接口即可
const secondResult = await queryUploadFileApi(fileItem.md5)if (secondResult != null && secondResult.fileStatus == STATUS.upload_seconds.value) { //秒传fileItem.status = STATUS[secondResult.fileStatus].valuefileItem.uploadProgress = 100return;}
断点续传
断点续传就是用户已经上传过的分片不需要上传,直接返回即可。
我们的临时目录是以文件的MD5值命名的,分片文件的命名逻辑也一样,所以如果服务器中有该文件,并且它的文件大小跟要分片的文件大小一样,那就一定是上传成功的,逻辑分片上传的接口已经实现了,如下:
File newFile = new File(tempFileFolder.getPath() + "/" + chunkIndex);if(newFile.exists() && newFile.length() == multipartFile.getSize()){ //断点续传,不需要在重新上传uploadFileInfoResp.setFileStatus(UploadStatusEnum.UPLOADING.getStatus());return ResultUtils.success(uploadFileInfoResp);}