拼写纠正系列
NLP 中文拼写检测实现思路
NLP 中文拼写检测纠正算法整理
NLP 英文拼写算法,如果提升 100W 倍的性能?
NLP 中文拼写检测纠正 Paper
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
一个提升英文单词拼写检测性能 1000 倍的算法?
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
nlp-hanzi-similar 汉字相似度
word-checker 中英文拼写检测
pinyin 汉字转拼音
opencc4j 繁简体转换
sensitive-word 敏感词
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计和开源实现。
FASPell
FASPell:一种基于DAE解码器范式的快速、适应性强、简单、强大的中文拼写检查器
作者: Yuzhong Hong, Xianguo Yu, Neng He, Nan Liu, Junhui Liu
单位: 爱奇艺智能平台部
电子邮件: {hongyuzhong, yuxianguo, heneng, liunan, liujunhui}@qiyi.com
摘要:
我们提出了一种中文拼写检查器——FASPell,基于一种新的范式,该范式由去噪自动编码器(DAE)和解码器组成。
与之前的最先进模型相比,这种新范式使我们的拼写检查器在计算上更快,能够方便地适应简体和繁体中文文本(无论是人类还是机器生成的),并且结构更加简化,同时在错误检测和修正方面仍然非常强大。这四个成就得以实现,主要是因为该新范式绕过了两个瓶颈。
首先,DAE通过利用无监督预训练的掩码语言模型(如BERT、XLNet、MASS等)的能力,减少了监督学习所需的中文拼写检查数据量(减少到 < 10k句子)。
其次,解码器帮助消除了困扰传统方法的混淆集问题,避免了混淆集在灵活性和充分性上存在的缺陷,能够更好地利用中文字符相似性的显著特征。
1 引言
自上世纪90年代初期一些开创性的工作(Shih等人,1992;Chang,1995)以来,中文文本中的拼写错误检测与修正已经有了长时间的研究。
然而,尽管大多数研究将拼写错误简化为替换错误,并且多个近期共享任务(如Wu等人,2013;Yu等人,2014;Tseng等人,2015;Fung等人,2017)的努力取得了一定进展,中文拼写检查仍然是一项具有挑战性的任务。
此外,针对英语等语言的方法几乎无法直接应用于中文,因为中文文本中没有单词间的分隔符,且中文缺乏形态变化,这使得每个汉字的句法和语义解释高度依赖于其上下文。
相关工作与瓶颈
几乎所有之前的中文拼写检查模型都采用了一个共同的范式,在这个范式中,每个汉字都有一个固定的相似字符集合(称为混淆集),这些相似字符被用作候选项,并通过一个过滤器从中选择最佳候选项来替代给定句子中的错误字符。
这种简单的设计面临着两个主要瓶颈,其负面影响至今未能成功缓解:
- 过拟合于资源不足的中文拼写检查数据
由于中文拼写检查数据需要繁琐的专业人工工作,因此一直处于资源不足的状态。为了防止过滤器出现过拟合,Wang等人(2018)提出了一种自动生成伪拼写检查数据的方法。然而,当生成的数据量达到4万句时,他们的拼写检查模型的精度不再提升。Zhao等人(2017)使用了大量的临时语言学规则来过滤候选项,但即便如此,他们的模型表现仍不如我们的模型,尽管我们的模型并未利用任何语言学知识。
- 混淆集在利用字符相似性方面的僵化性和不足性
中文字符相似性是拼写错误的主要原因之一,其特征非常显著(见2.2小节)。然而,混淆集在利用字符相似性时存在以下问题:
- 在不同场景下的僵化性:在一个场景中混淆的字符,在另一个场景中可能并不混淆。例如,简体与繁体中文的差异(见表1)就是一个例子。Wang等人(2018)也指出,对于机器来说,混淆字符与人类的混淆字符是不同的。因此,在实际应用中,给定混淆集内可能并不存在正确的替代候选字符,从而影响召回率。而为了提高召回率,考虑更多相似字符则可能会降低精度。
- 在利用字符相似性方面的不足性:由于混淆集是通过量化的字符相似性(Liu等人,2010;Wang等人,2018)来确定的,相似的字符在混淆集中的处理是没有区别的。这意味着字符相似性的信息并没有得到充分利用。为了解决这个问题,Zhang等人(2015)提出了一种拼写检查器,但该模型不得不考虑许多不那么显著的特征,比如词语分割,这些增加了模型的不必要噪声。
1.2 动机与贡献
本文的动机是通过改变中文拼写检查的范式,绕过1.1小节中提到的两个瓶颈。
作为主要贡献,并以我们提出的中文拼写检查模型为例(见图1),新范式的最一般形式由一个去噪自动编码器(DAE)和一个解码器组成。
为了证明这确实是一个新的贡献,我们将其与两种类似的范式进行了比较,并展示了它们的差异,如下所示:
与之前中文拼写检查模型中使用的旧范式相似,DAE-解码器范式下的模型也会生成候选项(由DAE)并通过解码器过滤候选项。然而,候选项是根据上下文即时生成的。如果DAE足够强大,我们应当期待所有在上下文中合适的候选项能够被召回,从而避免了使用混淆集所导致的僵化性问题。DAE还能够防止过拟合问题,因为它可以通过大量自然文本进行无监督训练。此外,解码器可以在不丢失任何信息的情况下利用字符相似性。
DAE-解码器范式是一个序列到序列的结构,这使其类似于机器翻译、语法检查等任务中的编码器-解码器范式。然而,在编码器-解码器范式中,编码器提取语义信息,解码器生成体现这些信息的文本。相对而言,在DAE-解码器范式中,DAE提供候选项以基于上下文特征从损坏的文本中重建文本,而解码器通过结合其他特征选择最佳候选项。
除了新范式本身,我们提出的中文拼写检查模型还有两个额外的贡献:
我们提出了一种比Liu等人(2010)和Wang等人(2018)提出的更精确的字符相似性量化方法(见2.2小节);
我们提出了一种在实践中有效的解码器,用来根据最大化精度并最小化对召回率的损害的原则来过滤候选项(见2.3小节)。
1.3 成就
得益于1.2小节中提到的贡献,我们的模型相较于之前的最先进模型可以总结出以下几项成就,因此我们将其命名为FASPell:
我们的模型是快速的。如3.3小节所示,FASPell在过滤方面比之前的最先进模型更快,无论是在绝对时间消耗还是时间复杂度上,都有显著的优势。
我们的模型具有适应性。为了验证这一点,我们在不同场景下的文本上进行了测试——包括人类生成的文本,如中文作为外语学习者(CFL)编写的文本,以及机器生成的文本,如光学字符识别(OCR)文本。尽管存在一个挑战性问题,即一些在繁体文本中错误使用的字符在简体文本中被视为有效用法(见表1),我们的模型仍能适用于简体中文和繁体中文。根据我们所知,之前的最先进模型仅关注传统中文文本中的人为错误。
表1:
左侧的示例在简体中文(SC)中被视为有效用法。
右侧的注释说明了它们在繁体中文(TC)中是如何错误的,并提供了建议的修正方法。
这种不一致性源于在简化过程中,多个传统字符被合并为相同的字符。我们的模型仅在繁体文本中修正这种类型的错误。在简体文本中,这些错误不会被检测出来。
| 简体中文示例 | 关于繁体中文用法的注释 |
|---|---|
| 周末 (weekend) | 周 → 週 仅在“周到”等词中使用“周” |
| 旅游 (trip) | 游 → 遊 仅在“游泳”等词中使用“游” |
| 制造 (make) | 制 → 製 仅在“制度”等词中使用“制” |
我们的模型是简单的。如图1所示,它仅包含一个掩码语言模型和一个过滤器,而不像之前的最先进模型那样使用多个特征生成模型和过滤器。此外,我们的模型只需要一个小的训练集以及一组字符的视觉和语音特征,无需额外的数据,包括混淆集。这使得我们的模型更加简洁。
我们的模型是强大的。在基准数据集上,它在检测和修正层面上达到了与之前最先进模型相似的F1性能(见3.2小节)。在我们的OCR数据集上,它的精度也相当高(检测精度为78.5%,修正精度为73.4%)。
2 FASPell
如图1所示,我们的模型使用掩码语言模型(参见2.1小节)作为去噪自动编码器(DAE)来生成候选项,并使用置信度相似度解码器(参见2.2和2.3小节)来过滤候选项。实际上,进行多轮完整的过程也被证明是有帮助的(参见3.4小节)。
2.1 掩码语言模型
掩码语言模型(MLM)猜测在标记化句子中被掩盖的词汇。使用MLM作为DAE来检测和修正中文拼写错误是直观的,因为它与中文拼写检查的任务高度契合。在BERT的原始训练过程中(Devlin等,2018),错误是随机掩盖的,80%的时间使用特殊标记[MASK],10%的时间使用词汇表中的随机词,10%的时间保留原始词。当使用随机词作为掩码时,模型实际上学习如何修正错误字符;当保留原始字符时,模型则学习如何检测字符是否有误。为了简化起见,FASPell采用了BERT(Devlin等,2018)中的MLM架构。最近的变体——XLNet(Yang等,2019)、MASS(Song等,2019)也有更复杂的MLM架构,但它们同样适用。
然而,单独使用预训练的MLM会引发一个问题,即由随机掩码引入的错误可能与拼写检查数据中的实际错误大不相同。因此,我们提出以下方法来在拼写检查训练集上微调MLM:
- 对于没有错误的文本,我们遵循BERT中的原始训练过程;
- 对于有错误的文本,我们创建两种类型的训练样本:
- 给定一句话,我们用错误的词汇替换它们,并将其目标标签设置为对应的正确字符;
- 为了防止过拟合,我们还用正确的词汇替换那些没有错误的词汇,并将它们的目标标签设置为它们自己。
这两种类型的训练样本的数量大致相同,保持平衡。
微调预训练的MLM在许多下游任务中已被证明非常有效(Devlin等,2018;Yang等,2019;Song等,2019),因此可以认为这就是FASPell的主要力量来源。
然而,我们要强调的是,FASPell的强大不应仅仅归功于MLM。事实上,我们在消融实验(参见3.2小节)中展示,MLM本身只能作为一个非常弱的中文拼写检查器(它的F1得分可能低至28.9%),而利用字符相似性的解码器(参见2.2和2.3小节)对于生成强大的中文拼写检查器是不可或缺的。
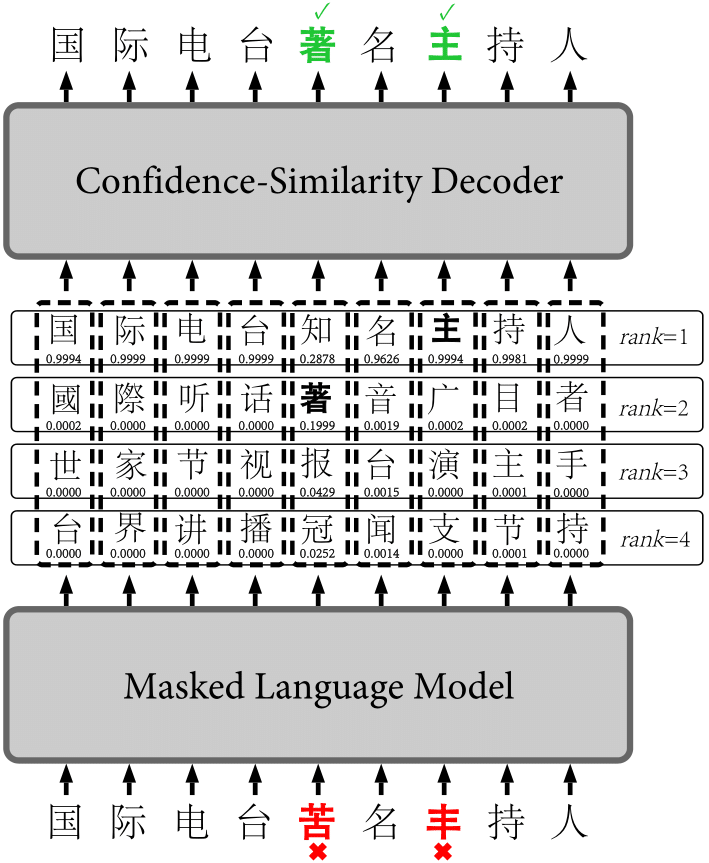
- 图1:
一个实际示例,展示了一个带有错误的句子(原意为“一个著名的国际广播电台”)如何通过FASPell成功进行拼写检查。
句子中的两个错误字符“苦”和“丰”被检测并纠正。
请注意,使用我们提出的置信度相似度解码器时,最终的替换选择不一定是排名第一的候选项。
2.2 字符相似性
中文文本中的错误字符通常在视觉(2.2.1小节)或语音(2.2.2小节)上与正确字符相似,或者两者都有相似性(Chang, 1995; Liu等, 2010; Yu和Li, 2014)。OCR产生的错误字符通常也具有视觉相似性(Tong和Evans, 1996)。
我们基于两个开放数据库来计算字符相似性:Kanji Database Project 和 Unihan Database,因为它们为所有CJK统一表意文字(CJK Ideographs)提供了形状和发音的表示。
2.2.1 视觉相似性
Kanji Database Project 使用Unicode标准中的“表意描述序列(IDS)”来表示字符的形状。如图2所示,字符的IDS正式表示为一个字符串,但本质上它是一个有序树的前序遍历路径。在我们的模型中,我们仅采用字符串形式的IDS。我们定义两个字符之间的视觉相似性为:1减去它们的IDS表示之间的标准化Levenshtein编辑距离。
标准化的原因有两个。首先,我们希望相似性范围从0到1,以便后续的过滤处理。
其次,如果一对更复杂的字符与一对较简单的字符有相同的编辑距离,我们希望更复杂的字符相似性略高于较简单的字符(参见表2中的示例)。
尽管树形IDS在直观上似乎更合适,但我们没有使用树形IDS,原因有两个。
首先,即使使用目前最有效的算法(Pawlik和Augsten, 2015, 2016),树编辑距离(TED)的时间复杂度仍然远高于字符串的编辑距离(O(mn(m + n)) vs. O(mn))。其次,我们在初步实验中尝试过TED,但在拼写检查性能上,与使用字符串的编辑距离相比,未发现显著差异。
- 图2
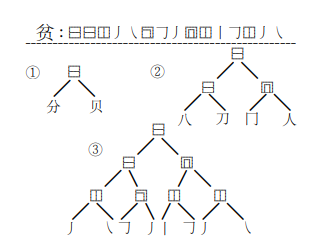
图2:一个字符的IDS可以在不同的粒度层次上给出,如图①-③所示,表示简体字“贫”(意思是贫穷)。
在FASPell中,我们仅使用笔画级别的IDS,形式如虚线标记线以上的那种。
与仅使用实际笔画(Wang等,2018)不同,Unicode标准的表意描述字符(例如树中的非叶节点)描述了字符的布局。
它们帮助我们建模由相同笔画组成的不同字符之间的微妙差异(参见表2中的示例)。因此,IDS为我们提供了更精确的字符形状表示。
表2:
字符相似度计算示例。IDS用于计算视觉相似度(V-sim),普通话(MC)、粤语(CC)、日语音读(JO)、韩语(K)和越南语(V)的发音表示用于计算语音相似度(P-sim)。
注意,编辑距离的归一化使得较简单的字符对(午, 牛)比更复杂的字符对(田, 由)具有更小的视觉相似度,尽管它们的IDS编辑距离都是1。
此外,午和牛在某些语言中的发音比在其他语言中更相似;多语言的发音组合为我们提供了更连续的语音相似度。
| 字符 | IDS | 普通话发音 (MC) | 粤语发音 (CC) | 日语音读 (JO) | 韩语 (K) | 越南语 (V) | 视觉相似度 (V-sim) | 语音相似度 (P-sim) |
|---|---|---|---|---|---|---|---|---|
| 午 | ⿱⿰丿一⿻一丨 | wu3 | ng5 | go | gyuu | o | 0.857 | 0.280 |
| 牛 | ⿻⿰丿一⿻一丨 | niu2 | ngau4 | gyuu | o | ngọ | 0.857 | 0.280 |
| 田 | ⿵⿰丨𠃌⿱⿻一丨一 | tian2 | tin4 | den | cen | điền | 0.889 | 0.090 |
| 由 | ⿻⿰丨𠃌⿱⿻一丨一 | you2 | jau4 | yuu | yu | do | 0.889 | 0.090 |
2.2.2 语音相似度
不同的汉字共享相同的发音是非常常见的现象(Yang et al., 2012),这也是所有CJK语言的普遍特点。
因此,如果我们仅使用某一种CJK语言的汉字发音来计算相似度,字符对的语音相似度将会局限于少数离散值。
然而,更连续的语音相似度是优选的,因为它能够使候选过滤时使用的曲线更加平滑(见子节2.3)。
因此,我们利用所有CJK语言的字符发音(见表2中的示例),这些发音数据由Unihan数据库提供。
为了计算两个字符的语音相似度,我们首先计算它们在所有CJK语言中的发音表示的Levenshtein编辑距离(归一化后)的1减值。
然后,我们对所有语言的结果取平均值。
因此,最终的相似度应该在0到1之间。
2.3 Confidence-Similarity Decoder
在许多先前的模型中,候选过滤器是基于为候选字符的多个特征设置不同的阈值和权重。
与这种简单的方法不同,我们提出了一种基于尽可能提高精度并最大限度减少召回损失的原则的有效方法。由于解码器利用了上下文信心和字符相似度,我们称其为信心-相似度解码器(CSD)。
CSD的机制解释如下,并且其有效性也得到了验证:
首先,考虑最简单的情况,即每个原始字符只提供一个候选字符。对于那些与原始字符相同的候选字符,我们不进行替换。对于那些不同的候选字符,我们可以绘制一个信心-相似度散点图。如果我们将候选字符与真实标签进行比较,图形将类似于图3中的①。我们可以观察到,真实的检测和修正候选字符密集分布在右上角;错误检测的候选字符分布在左下角;真实检测但错误修正的候选字符分布在中间区域。
如果我们绘制一条曲线来过滤掉错误检测的候选字符(图3中的②),并将其余候选字符作为替换,那么我们可以优化字符级精度,同时最大限度地减少对检测召回的损害;如果我们也过滤掉真实检测但错误修正的候选字符(图3中的③),我们可以在修正的效果上得到相同的效果。在FASPell中,我们优化修正性能,并通过训练集手动找到过滤曲线,假设其与相应的测试集一致。但是在实践中,我们必须找到两条曲线——分别用于每种类型的相似度,然后取过滤结果的并集。
现在,考虑候选字符数量为c > 1的情况。为了将其简化为前面描述的最简单情况,我们根据上下文信心对每个原始字符的候选字符进行排序,并将排名相同的候选字符放入同一组(即总共c组)。
因此,我们可以为每组候选字符找到如前所述的过滤器。所有c个过滤器的组合进一步缓解了召回损害,因为更多的候选字符被考虑进来。
在图1的示例中,候选字符有c = 4组。我们从排名为1的组中获得正确的替代丰 → 主,从排名为2的组中获得另一个正确的替代苦 → 著,而从其他两组中则没有得到更多的替代。
- 图3
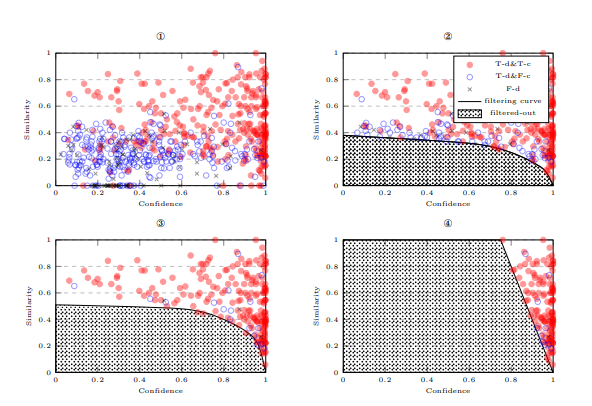
Figure 3: 所有四个图都展示了相同的信心-相似度候选图,其中候选字符被分类为真实检测和真实修正(T-d&T-c)、真实检测和错误修正(T-d&F-c)以及错误检测(F-d)。
但是,每个图展示了不同的候选过滤方式:
- 图①:没有过滤任何候选字符。
- 图②:过滤优化检测性能。
- 图③:如FASPell中所采用的,过滤优化修正性能。
- 图④:如之前的模型所采用的,候选字符通过设置加权信心和相似度的阈值进行过滤(例如:0.8 × 信心 + 0.2 × 相似度 < 0.8)。
需要注意的是,这四个图使用了我们OCR数据集(T rnocr)中的实际首选候选字符(使用视觉相似度计算),不过我们仅随机抽取了30%的候选字符进行绘制,以便在纸面上展示时更加清晰可见。
致谢
作者感谢匿名评审人提出的宝贵意见。
同时,我们也感谢爱奇艺(iQIYI)公司IT基础设施团队提供的硬件支持。
特别感谢早稻田大学(Waseda University)IPS研究生院的Yves Lepage教授,感谢他对本文的深刻建议。





![[Python3] Sanic中间件](https://i-blog.csdnimg.cn/direct/8b542065dc8641c3815bdda52ccea793.png)