文章一览
- 前言
- 一、nmupy 简介和功能
- 二、numpy 安装
- 三、numpy基本使用
- 3.1、ndarray 对象
- 3.2、基础数据结构 ndarray 数组
- 3.3、ndarray 数组定义
- 3.4、ndarray 数组属性计算
- 3.5、ndarray 数组创建
- 3.5.1 通过 array 方式创建 ndarray 数组
- 3.5.2 通过 arange 创建数组
- 3.5.3 通过 linspace 函数创建数组
- 3.5.4 通过 logspace 函数创建数组
- 3.5.5 基础数组创建
- (1)生成相同元素为 1 的数组
- (2)生成相同元素为 0 的数组
- (3)生成对角线为 1 的数组
- 3.5.6 使用.tile()函数创建多维数组
- 3.5.7 ndarray 数组向量化和广播计算
- 3.5.8 数组和标量之间的运算(加减乘除)
- 3.5.9 改变 ndarray 数组元素类型
- 3.5.10 改变 ndarray 数组形状
- 3.5.11 创建随机数组
- 1) 均匀随机分布
- 2) 正态分布
前言
NumPy(Numeric Python的缩写)是一个开源的Python科学计算库,用于进行大规模数值和矩阵运算。它是Python中用于科学计算的核心库之一,广泛应用于数据分析、机器学习、科学计算和工程应用等领域。
一、nmupy 简介和功能
numpy(Numeric Python)是python用于科学计算的基础包。特点是运行速度快,支持多维数组和向量化计算,实用的线性代数、基本统计运算、排序、选择、随机模拟、傅里叶变换等。
在人工智能和深度学习中,通常会使用 numpy 实现数据预处理和一些模型指标的计算,也可以实现机器学习和深度学习算法实现。
二、numpy 安装
在命令行模式下:pip install numpy
pip (The Python Package Installer)是一个现代通用的 Python 管理工具。提供对 Python 包的查找、下载、安装、卸载等功能
pip 更新方式:python -m pip install --upgrade pip
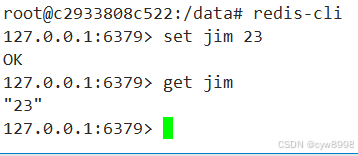
安装成功:
其中 np 作为 numpy 的别名。以后可以通过 np 来调用 numpy 里的功能
三、numpy基本使用
3.1、ndarray 对象
NumPy 包的核心是 ndarray 对象(数组),封装了同质数据类型的 n 维数组,numpy 数组和标准 Python 序列(列表、元组)数据之间有几个重要的区别。
- NumPy 数组在创建时具有固定的大小
- 数组中的元素都具有相同的数据类型,因此在内存中的大小相同
- 越来越多基于 Python 的科学和数学软件包使用 NumPy 数组;尽管通常支持 序列 数据输入,但在处理之前将这些输入转换为 NumPy 数组,通常也输出 NumPy 数组
- Numpy 底层是用 c 语言编写的,内置了并行计算功能,运行速度高于纯 Python 代码
- ndarray数组中实现了向量(矢量)和广播功能,矩阵运算时不需要写 for 循环基本运算
换句话说,为了高效地使用当今大部分基于 Python 的科学/数学软件,仅仅知道如何使用 Python 的内置序列类型是远远不够的,还需要知道如何使用 NumPy 数组。
3.2、基础数据结构 ndarray 数组
ndarray(多维)数组是 Numpy 中的基础数据结构式
- 如何创建ndarray数组
- ndarray数组的基本运算
- ndarray数组的切片和索引
- ndarray数组的统计运算
3.3、ndarray 数组定义
ndarray 是 numpy 中的基本数据结构,别名是 array。所有元素都是同一种类型,由 5 个一维数组构成,每个一维数组有 5 个元素。
维度(dimensions)称为轴(axis),轴的个数称为阶(rank)。

切记:
(1)numpy 数组的下标从 0 开始
(2)同一个 numpy 数组中所有元素的类型必须相同
3.4、ndarray 数组属性计算
在很多函数使用的时候,都可以加上 axis 参数。如果 axis = 0,就表示沿着第 0 轴进行操作,即对每一行进行操作,如果 axis = 1,就表示沿着第 1 轴进行操作,即对每一列进行操作:
- ndarray.ndim – 维度(轴的数量称为rank)
- ndarray.shape – 各个轴(维)上数组的长度
- ndarray.size – 元素总个数
- ndarray.dtype – 元素类型
- ndarray.itemsize – 元素字节大小
ndarray 的属性包括形状 shape、数据类型 dtype、元素个数 size 和维度 ndim 等
-
ndarray.dtype:数组的数据类型,int64,float64
-
ndarray.shape:数组的形状(行列):
- 一维数组 (M, )
- 二维数组 (M, N)
- 三维数组(K,M N)
-
ndarray.ndim:数组的维度大小
-
ndarray.size:数组中包含的元素个数:其大小等于各个维度的长度的乘积
3.5、ndarray 数组创建
有多种方式可以创建 ndarray 数组:
3.5.1 通过 array 方式创建 ndarray 数组
通过 array 方式创建,向 array 中传入一个 list 或 tuple 实现
# ndarray 数组创建
import numpy as np
a = np.array([1,2,3])
>>> type(a)
<class 'numpy.ndarray'>
>>> a.ndim
1
>>> a.shape()
(3, )
# ndarray 数组创建
import numpy as np
a = np.array(([1,2,3],[4,5,6]))
>>> a.ndim
2
>>> a.shape
(2, 3)
# shape[0] = 2 shape[1] = 3
>>> a.size
6
一维数组叫作向量(vector),这个向量有 3 个元素,所以被称为 3 维向量
不要把 3 维向量和 ndim = 3 维度弄混! 向量只有一个轴,沿着轴有 3 个维度。
3.5.2 通过 arange 创建数组
arange 函数用于创建等差数组,使用频率非常高,arange 非常类似 range 函数
-
range() 返回的是 列表,而 np.arange() 返回的是 数组(向量)。两者都可用于迭代;
-
两者都有三个参数:start🔚step;
-
range() 不支持步长为小数,np.arange()支持步长为小数;
>>> import numpy as np
>>> a = np.arange(12)
>>> print (a)
[0 1 2 3 4 5 6 7 8 9 10 11]
#创建一个 1-2 间隔为 0.2 的行向量
>>> import numpy as np
>>> a = np.arange(1,2,0.2)
>>> print (a)
[1. 1.2 1.4 1.6 1.8]
3.5.3 通过 linspace 函数创建数组
使用linspace在给定区间内创建间隔(等差数列)相等的数组。可以通过endpoint 参数指定是否包含终值,默认值为 True,即包含终值
linspace(start,stop,num = 50,endpoint = True)
>>> import numpy as np
>>> a = np.linspace(1,2,10)
>>> print (a)
[1. 1.11111111 1.22222222 1.33333333 1.44444444 1.555555561.66666667 1.77777778 1.88888889 2. ]
>>> import numpy as np
>>> a = np.linspace(1,2,10,endpoint = False)
>>> print (a)
[1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9]
3.5.4 通过 logspace 函数创建数组
使用 logspace 可以在对数尺度上生成均匀间隔的自定义点数
logspace(start, stop, num = 50, endpoint = Ture, base = 10.0, dtype = None )

>>> import numpy as np
>>> print(np.logspace(1, 3, 3, base = 2))
[2. 4. 8.]
>>> print(np.logspace(2.0, 3.0))
[ 100. 104.81131342 109.8541142 115.13953993 120.67926406126.48552169 132.57113656 138.94954944 145.63484775 152.64179672159.98587196 167.68329368 175.75106249 184.20699693 193.06977289202.35896477 212.09508879 222.29964825 232.99518105 244.20530945255.95479227 268.26957953 281.1768698 294.70517026 308.88435965323.74575428 339.32217719 355.64803062 372.75937203 390.69399371409.49150624 429.19342601 449.8432669 471.48663635 494.17133613517.94746792 542.86754393 568.9866029 596.36233166 625.05519253655.12855686 686.648845 719.685673 754.31200634 790.60432109828.64277285 868.51137375 910.29817799 954.09547635 1000. ]
3.5.5 基础数组创建
(1)生成相同元素为 1 的数组
numpy. ones (shape,dtype=None, order='C')
- ones 函数用于生成指定形状和数据类型的数组,其中的元素都为 1
- shape:数组的形状(维度),可以是整数或整数列表/元组
- dtype:生成的数组的数据类型,默认为 None
- order:数组在内存中的存储顺序, ‘C’(按行存储)或 ‘F’(按列存储)
>>> import numpy as np
>>> n = np.ones(5)
[1. 1. 1. 1. 1.]
>>> n = np.ones([3,3])
[[1. 1. 1.][1. 1. 1.][1. 1. 1.]]
>>> n = np.ones((4,4))
[[1. 1. 1. 1.][1. 1. 1. 1.][1. 1. 1. 1.][1. 1. 1. 1.]]
(2)生成相同元素为 0 的数组
numpy.zeros (shape,dtype=float, order='C')
- zeros 函数用于生成指定形状和数据类型的全 0 数组
- shape:数组的形状(维度),可以是整数或整数列表/元组
- dtype:生成的数组的数据类型,默认为 float
- order:数组在内存中的存储顺序, ‘C’(按行存储)或 ‘F’(按列存储)
import numpy as np
n = np.zeros(5)n = np.zeros([3,3])n = np.zeros((4,4))
(3)生成对角线为 1 的数组
numpy. eye(N, M = None, k = O, dtype = float)
- eye 函数用于创建一个二维数组,其中对角线上为 1 ,其余元素为 0
- N:生成的矩阵的行数
- M:生成的矩阵的列数(可选,默认为 N)
- k:对角线的索引(默认为 0 ,即主对角线,k>0 为上对角线,k<0 为下对角线)
>>> import numpy as np
>>> n = np.eye(4)
[[1. 0. 0. 0.][0. 1. 0. 0.][0. 0. 1. 0.][0. 0. 0. 1.]]
>>> n = np.eye(3,4)
[[1. 0. 0. 0.][0. 1. 0. 0.][0. 0. 1. 0.]]
>>> n = np.eye(4,k = 1)
[[0. 1. 0. 0.][0. 0. 1. 0.][0. 0. 0. 1.][0. 0. 0. 0.]]
3.5.6 使用.tile()函数创建多维数组
np.tile()正确的使用方式是 numpy.tile(A, reps),其中 A 是你想要重复的数组,而 reps 是一个整数或整数元组,指定了沿每个轴重复的次数。
import numpy as np# 创建一个一维数组
a = np.array([0, 1, 2])# 使用 numpy.tile 沿第一个轴(行)重复3次,沿第二个轴(列,但在这个一维数组的情况下不存在)重复1次(这是默认的)
# 结果是一个3x3的二维数组
b = np.tile(a, (3, 1)) # 注意这里的(3, 1),因为即使第二个维度是1(即不改变列数),也需要明确指定print(b)
# 输出:
# [[0 1 2]
# [0 1 2]
# [0 1 2]]# 如果你只指定一个整数作为 reps,那么它会被视为在所有维度上重复的次数
c = np.tile(a, 3)
# 这等价于 np.tile(a, (3, 3)),但在这个例子中,由于 a 是一维的,所以结果会是一个一维数组,长度为 3*3=9
print(c)
# 输出: [0 1 2 0 1 2 0 1 2]# 要注意,如果你想要得到一个二维结果,你需要明确指定两个维度,即使其中一个维度是1
3.5.7 ndarray 数组向量化和广播计算
list 列表 VS ndarray 数组处理多个元素的操作
# 对 a 列表的每个元素 + 1
a = [1,2,3,4,5]
print (a)
for i in range(5):a[i] = a[i] + 1
print (a)# 对 a 数组的每个元素 + 1
import numpy as np
a = np.array([1,2,3,4,5])
a = a + 1
print (a)
这个例子显示了 NumPy 的 向量化 功能,不需要循环!
ndarray 数组的向量(矢量)计算能力使得不需要写 for 循环,就可以非常方便的完成数学计算,在操作向量或者矩阵时,可以像操作普通的数值变量一样编写程序,使得代码非常简洁。
这就是“向量化”思路!
向量化可以有效避免 for 循环
向量化 思路是“一次”在一个复杂 对象 上进行操作,或者应用某个函数,而不是通过在对象的单个元素上循环来进行。
向量化代码有许多优点,其中包括:
- 向量化代码更简洁,更易于阅读
- 更少的代码行通常意味着更少的 bug
- 如果没有向量化,代码将充满低效和难以读取的 for 循环
# 使用循环
import time
total = 0
s = time.time ()
# 遍历2万个数字
for item in range(0,20001):total = total + item
e = time.time ()
diff = e - s
print('sum is:' ,total)
print('循环耗时:' ,diff)# 使用向量化
import numpy as np
import time
# np.range创建2万个数字
arr = np.arange(20001)
s = time.time ()
total = np.sum(arr)
e = time.time ()
diff = e - s
print('sum is:' ,total)
print('向量耗时:' ,diff)
在做数据分析和处理的时候,通常关心整个一列或一行数据,而不关心每一个数据。因为一列数据代表一类特征,一行数据代表一个样本或一个对象。在操作的时候是关心一个整体,因此需要整体操作。要有向量化的思维方式。深度学习要求解决多个复杂的方程,而且是针对数亿和数十亿行的方程。在Python 中运行循环来解决这些方程非常慢,此时,向量化是最佳的解决方案。
“向量化”计算都是要转成 numpy的 数组(array)类型才能操作吗?
是的!用向量化的前提就是要把数据转换成多维数组!把整个数组当成一个对象直接对它进行数学上的处理。这种思维方式对做人工智能机器学习有很大帮助。
另外,数组还提供了广播机制,即会按一定规则自动对数组的维度进行扩展以完成计算,NumPy 操作通常是在逐元素的基础上对数组对执行的,即两个数组必须具有完全相同的形状。
# 两个数组元素相乘
>>> import numpy as np
>>> a = np.array([1, 2, 3])
>>> b = np.array([2, 2, 2])
>>> c = a * b
>>> print (c)
[2 4 6]
# 广播示例
>>> import numpy as np
>>> a = np.array([1, 2, 3])
>>> b = 2
>>> c = a * b
>>> print (c)
[2 4 6]
最简单的广播是把数组和标量值组合在一个操作中,可以想象标量 b 在算术运算期间被拉伸成与 a 形状相同的数组。

1 维数组和 2 维数组进行相加操作,ndarray 数组会自动扩展 1 维数组的维度,然后再对每个位置的元素分别相加, 即在某一维度(行或列)上形状一样就可以计算。

>>> import numpy as np
# d是二维数组维度 2x5
>>> d = np.array([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10]])
>>> print (d)
[[1 2 3 4 5 ]
[6 7 8 9 10]]
# c是一维数组,维度5
>>> c = np.array([ 4, 6, 8, 10, 12])
>>> print (c)
[[4 6 8 10 12]]
# e 是 d + c
>>> e = d + c
>>> print (e)
[[5 8 11 14 17]
[10 13 16 19 22]]
3.5.8 数组和标量之间的运算(加减乘除)
大小相等的数组之间的任何算数运算都会将运算应用到元素级。同样,数组与标量的算数运算也会将那个标量值传播到各个元素
#用标量乘、除数组的每一个元素
import numpy as np
a = np.array([[1., 2., 3.], [4., 5., 6.]])
b = 2.0 * a
c = 1./ a
数组 减去 数组, 用对应位置的元素相减
>>> import numpy as np
>>> a1 = np.array([[1., 2., 3.], [4., 5., 6.]])
>>> a2 = np.array([[11., 12., 13.], [21., 22., 23.]])
>>> b = a1 - a2
>>> print (b)
[[-10. -10. -10. ]
[-17. -17. -17.]]
同理,数组 加 数组,用对应位置的元素相加
数组 乘 数组,用对应位置的元素相乘
数组 除 数组,用对应位置的元素相除
3.5.9 改变 ndarray 数组元素类型
创建 ndarray 之后,可以对其数据类型进行更改
import numpy as np
x = np.array([1, 2, 2.5])
y = x.astype(int)
3.5.10 改变 ndarray 数组形状
创建 ndarray 之后,可以对其形状进行调整
语法:numpy.reshape(a, newshape, order='C')
- a:要改变形状的数组
- newshape:新形状应与原始形状兼容(整数或整数元组 )。如果是整数,则结果将是该长度的一维数组。如果一个形状维度是 -1,该值是从数组的长度和剩余维度推断出来的
- order:C 是缺省值,按照行来填充;F: 按照列顺序填充
import numpy as np
a = np.arange(6)
b = np.reshape(a,(2,3))import numpy as np
a = np.arange(6).reshape(2,3)
import numpy as np
a = np.array([[1,2,3], [4,5,6]])
b = np.reshape(a, 6)
c = np.reshape(a, 6, 'F')import numpy as np
n = np.arange(20)
n = n.reshape(-1,4) # 根据数组剩余长度或维度去推断
print (n)
将行数组转换为二维的列数组
>>> import numpy as np
>>> n = np.arange(10)
>>> n.shape
(10,)
>>> m = np.reshape(n,[n.shape[0],-1])
>>> m.shape
(10, 1)
#或者插入新维度
>>> m = n[:,np.newaxis]
>>> m.shape
(10, 1)
在机器学习中,经常需要扁平化一个数据,即将多维数组降维为一维数组。Numpy 提供了两个方法:
-
import numpy as np a = np.array([[1., 2., 3.], [4., 5., 6.]]) b = a.flatten() -
import numpy as np a = np.array([[1., 2., 3.], [4., 5., 6.]]) b = a.ravel()
两个函数实现的功能一样,但平时使用的时候 flatten()更为合适, 这是为什么?
在使用过程中 flatten() 分配了新的内存,但 ravel() 返回的是一个数组的视图。
import numpy as np
a = np.array([[1., 2., 3.], [4., 5., 6.]])
b = a.flatten()
b[0] = 20import numpy as np
a = np.array([[1., 2., 3.], [4., 5., 6.]])
b = a.ravel()
b[0] = 20
因为 ravel()返回的是一个数组的视图,因此在修改视图时会影响原来的数组
3.5.11 创建随机数组
在 numpy 里可以生成随机数组,可以是均匀分布,也可以是正态分布
1) 均匀随机分布
(1)np.random.rand (n,m) 创建指定形状的数组(范围在0-1之间)
(2)np.random.uniform (n,m) 创建指定范围内的一个或一组随机浮点数
(3)np.random.randint (n,m, size = (x, y)) 创建指定范围内的一个或一组随机整数 (size可以指定矩阵大小)
import numpy as np
a = np.random.rand(3, 3)
print (a)

2) 正态分布
(1)np.random.normal (mean, std, (n,m)) 给定正态分布的均值/标准差/维度
# 生成正态分布随机数,指定均值和标准差
import numpy as np
a = np.random.normal(0.0, 1.0, (3,3))
print (a)

(2)np.random.randn (n, m) 指定形状的标准正态分布
标准正态分布是以 μ=0 为均值、以 σ=1 为标准差的正态分布,记为 N (0,1)

# 生成标准正态分布
import numpy as np
a = np.random.randn(2,3)
print (a)