项目场景:
简单爬取粤菜菜谱。
实现思路:
-
访问主页,获取每个菜品的菜名、图片、详情页面网址。

-
访问上一步中获得的所有详情页面,获取工艺、口味、时间、主料、辅料信息。
-
清洗所获得的数据。
-
保存至本地文件。
实现过程:
- 获取菜品详情的网址、菜名、图片网址:
from bs4 import BeautifulSoup
import requests
import chardet
import pandas as pd
import re# 构造请求头
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) Chrome/65.0.3325.181'}
# 构造网址
url = ''
# 发起请求
rqg = requests.get(url, headers=ua)
# 调整编码
rqg.encoding = chardet.detect(rqg.content)['encoding']
# 初始化HTML
html = rqg.content.decode('utf-8')
# 生成BeautifulSoup对象
soup = BeautifulSoup(html, "lxml")
# print(soup)
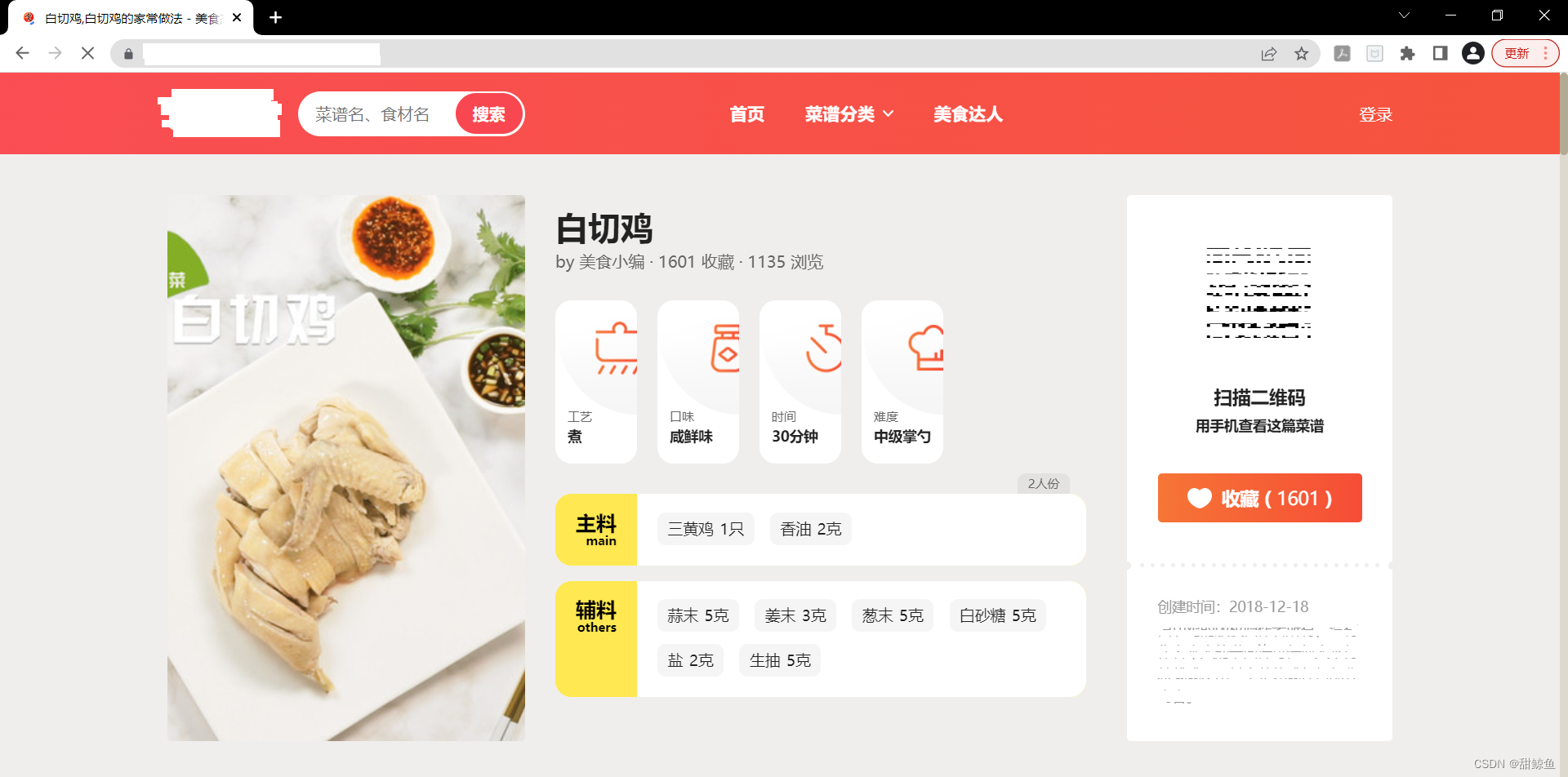
在主页中需要获取信息的地方右键检查,以获取菜品封面图片为例:
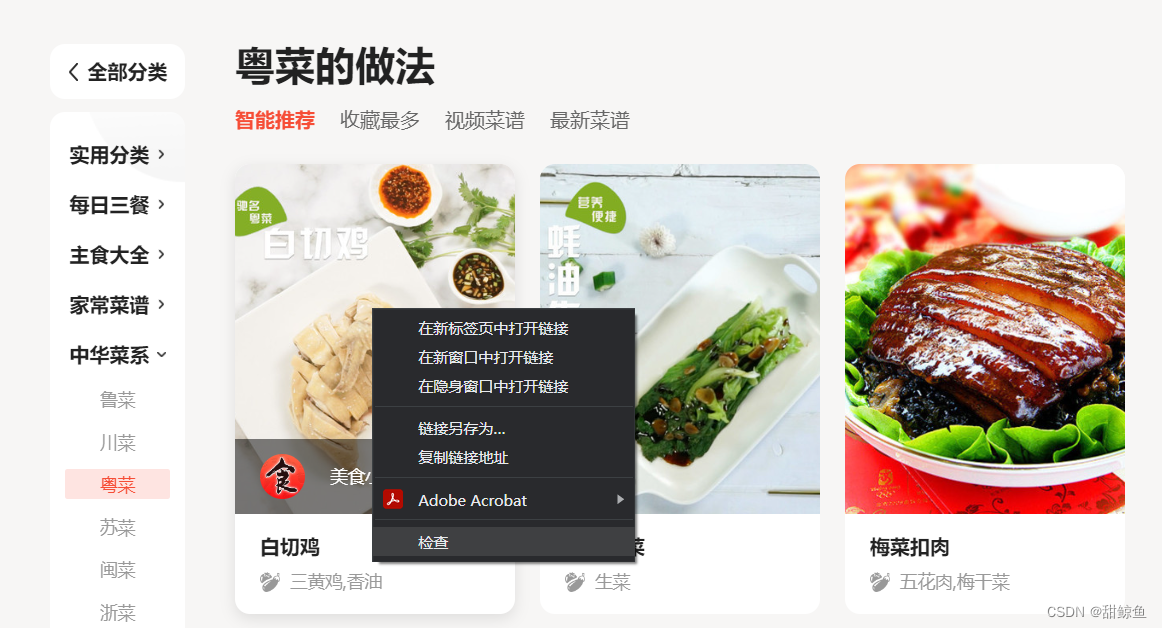
这样就定位到了图片网址,其中还包括了详情页面的网址:
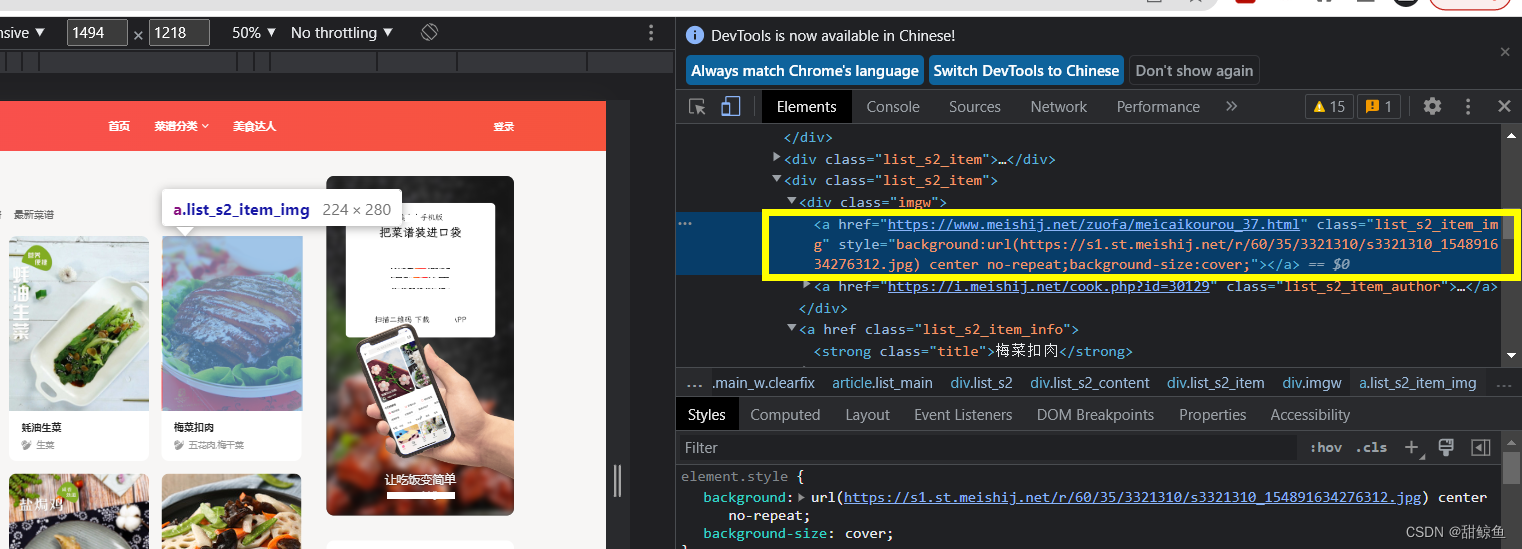
以同样的方式在主页定位菜名:
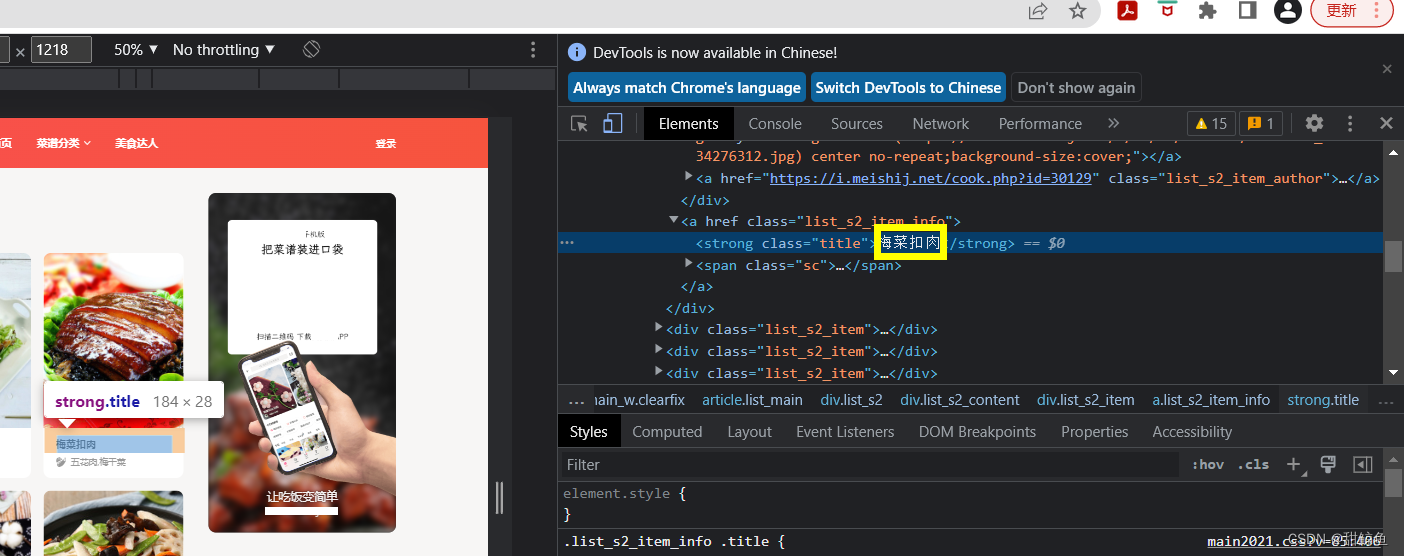
| 菜品(详情页面)网址 | 菜名 | 菜品图片网址 | |
|---|---|---|---|
| 定位方法 | <a> 标签及其类名 | <a> 标签类名 + <strong> 标签类名 | <a> 标签及其类名 |
| 保存至 | urls 列表 | titles 列表 | imgs 列表 |
urls,titles,imgs = [],[],[]# 提取菜品网址
for tag in soup.find_all("a", attrs={'class': 'list_s2_item_img'}):urls.append(tag['href'])# 提取菜名
for tag in soup.select('.list_s2_item_info .title'):titles.append(tag.text)# 提取图片网址
com = re.compile(r'background:url\((.*?)\).*?')
for tag in soup.find_all("a", attrs={'class': 'list_s2_item_img'}):res = re.findall(com, tag['style'])imgs.append(re.findall(com, tag['style'])[0])
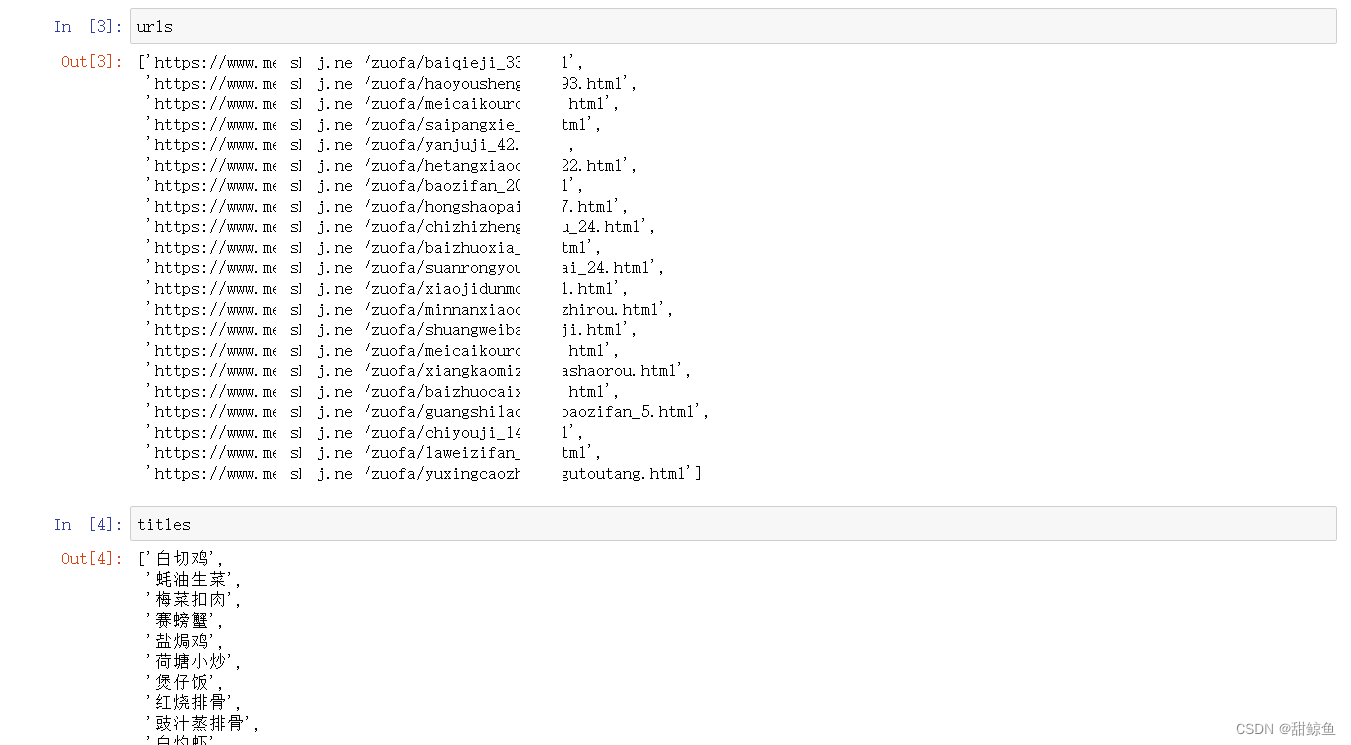
打印详情页面网址、菜名、图片网址,检查一下是否成功得到了想要的数据。
- 从菜品详情页提取工艺、口味、制作时长、食材:
对元素的定位方法同上一步相似,但要注意对字符串中空格的清除;特别地,因为爬取到的主料与辅料都是多个字符串,因此需要拼接(这里只保留了食材的种类,把主料与辅料拼接到一起,忽略食材的用量)。如果有需要的话,还需要对制作时长进行单位的转换。
process,flavor,cost,ingredients = [],[],[],[]for u in urls:# 发起请求r = requests.get(u, headers=ua)# 调整编码r.encoding = chardet.detect(r.content)['encoding']# 初始化HTMLh = r.content.decode('utf-8')# 生成BeautifulSoup对象s = BeautifulSoup(h, "lxml")# print(s)# 提取工艺# 获取所有class属性为info2_item info2_item1的div标签tag = s.find_all("div", attrs={'class': 'info2_item info2_item1'})temp = tag[0].textprocess.append(temp[3:].replace('\n',''))# 提取口味# 获取所有class属性为info2_item info2_item2的div标签tag = s.find_all("div", attrs={'class': 'info2_item info2_item2'})temp = tag[0].textflavor.append(temp[3:].replace('\n',''))# 提取制作时间# 获取所有class属性为info2_item info2_item3的div标签tag = s.find_all("div", attrs={'class': 'info2_item info2_item3'})temp = tag[0].textcost.append(temp[3:].replace('\n',''))# 提取主料与辅料temp = []com = re.compile(r'<strong><a .*?>(.*?)</a>(.*?)</strong>')for tag in s.find_all("div", attrs={'class': 'recipe_ingredients'}):item = re.findall(com, str(tag))for i in range(len(item)):# print(item[i])# temp.append(item[i][0])temp.append(item[i][0].replace(' ','')) # 删去空格# 对食材作字符串拼接igd = ''for item in temp:igd = igd + item + '、'ingredients.append(igd[:-1])
- 保存至本地文件:
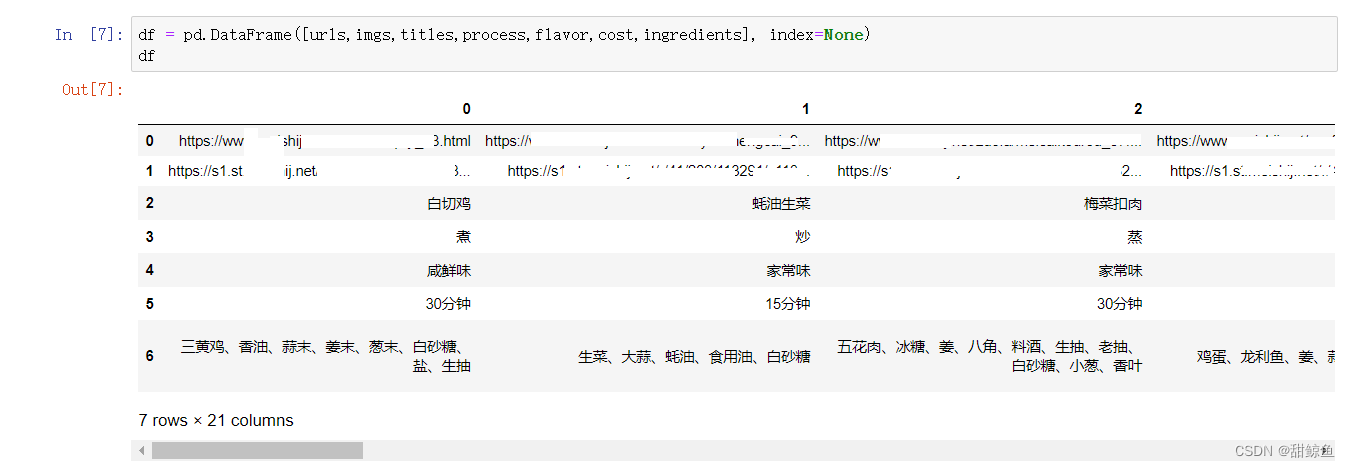
先把数据一起放到 DataFrame 里看看:
df = pd.DataFrame([urls,imgs,titles,process,flavor,cost,ingredients], index=None)
df
按照(我)对数据的使用习惯,需要对这个DataFrame做个转置:
df = df.T
df.columns = ['url','img','title','process','flavor','cost','ingredient']
df
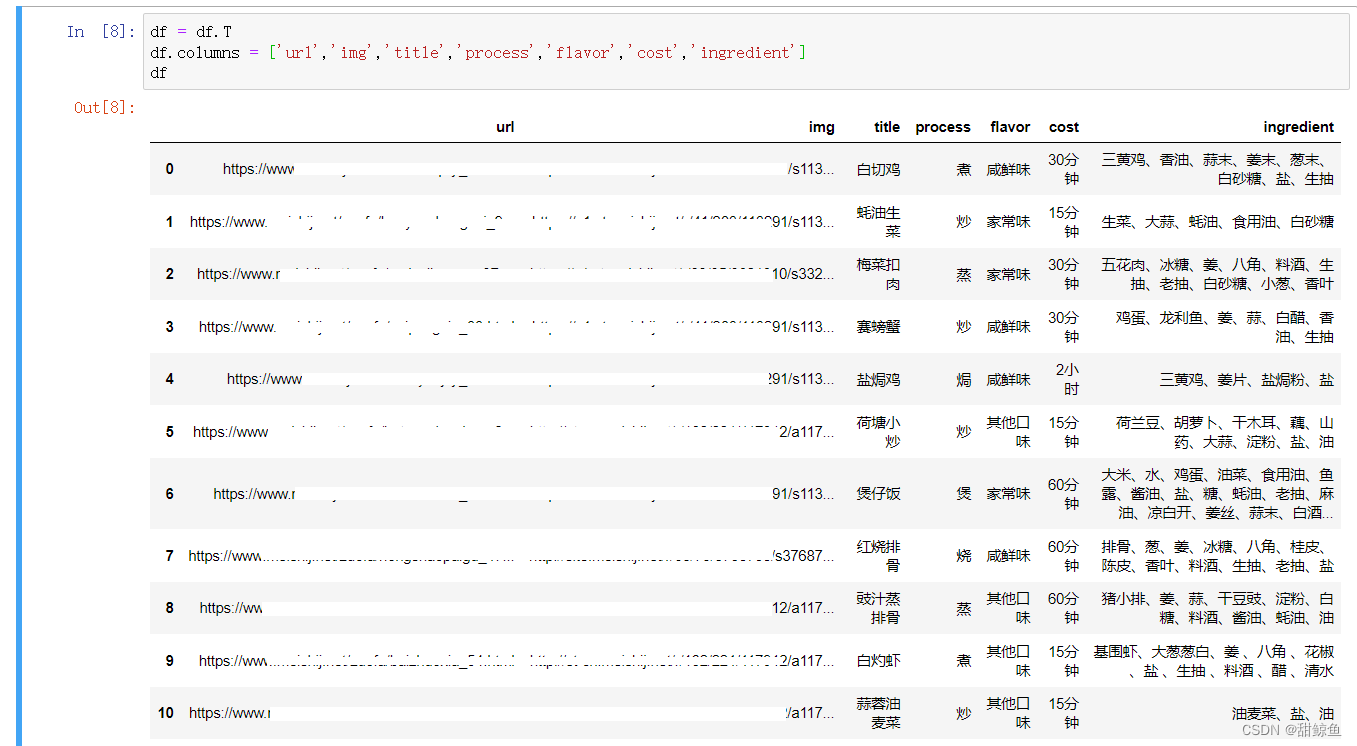
这样看着舒服多了。然后存入本地 xlsx 文件。我选的 utf8,也可以用 gb2312 或者其他的编码方式。
df.to_excel('Cantonese.xlsx', encoding='utf8')
最后可以打开文件看看写入的结果:
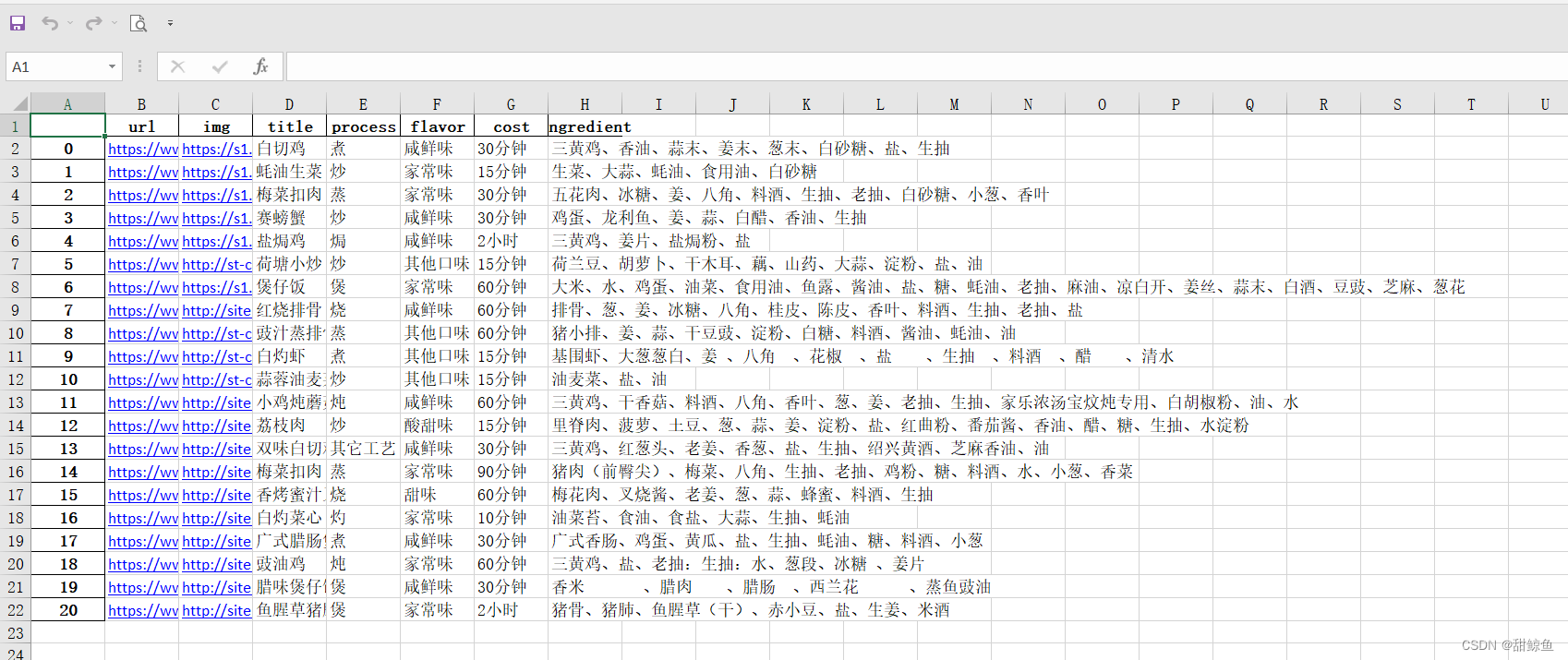
这里因为之前处理食材数据换行符的时候忘记一起删去空格了,所以这个 xlsx 里的数据还不是很干净,但上面的代码已经改了。