文章目录
- 前言
- 1. 安装下载软件
- 1.1 内网安装使用USB Redirector
- 1.2 下载安装cpolar内网穿透
- 2. 完成USB Redirector服务端和客户端映射连接
- 3. 设置固定的公网地址
前言
我们每天都在与各种智能设备打交道,从手机到电脑,再到各种外设,它们已经成为了生活中不可或缺的一部分。但你有没有遇到过这样的烦恼:明明有一个重要的文件存储在U盘里,却因为不在身边而无法访问?或者你的打印机只能连接一台电脑,其他设备需要打印时就变得异常麻烦?
今天我要给大家推荐一个超级实用的工具——USB Redirector!这款应用程序不仅能够让你轻松共享和远程访问各种USB设备,还能结合cpolar内网穿透技术,实现无缝对接。想象一下,在家里的办公室里工作时,你可以随时调用公司电脑上的打印机;或者在旅行途中,可以快速读取保存在家中的U盘文件——这一切都变得如此简单!
1. 安装下载软件
cpolar可以将内网的usb redirector映射到外网实现内外网跨网USB共享通信访问。
需要的工具如下:
- cpolar客户端
- usb redirector technician edition(服务端)
- USB Redirector Technician Edition-custormer module(客户端)
1.1 内网安装使用USB Redirector
进入官网下载:https://usb-redirector.net/download/
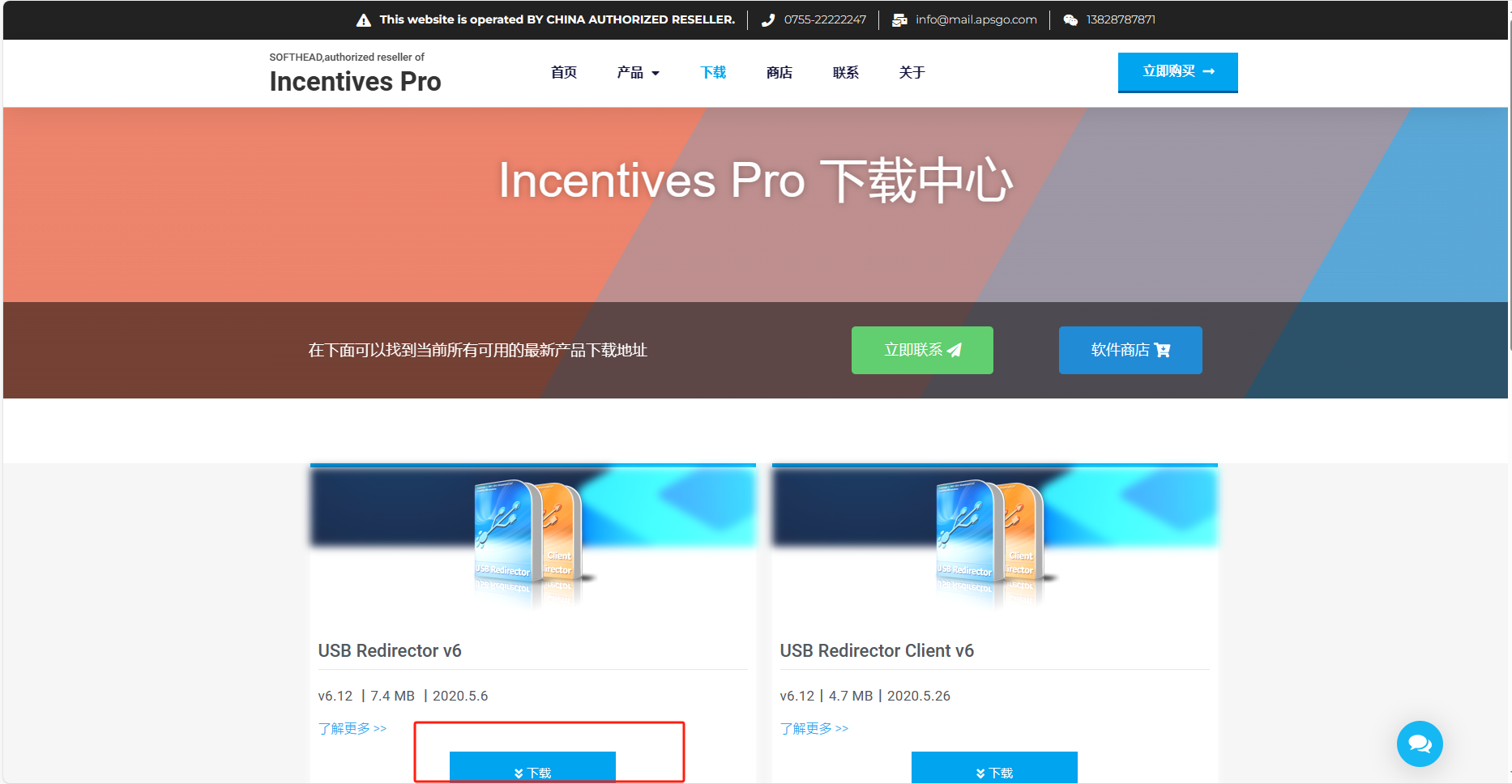
安装包下载完成后,准备USB客户端。在需要远程使用USB设备的Windows 计算机上,安装USB Redirector Client(客户端)。这将是您的USB客户端。
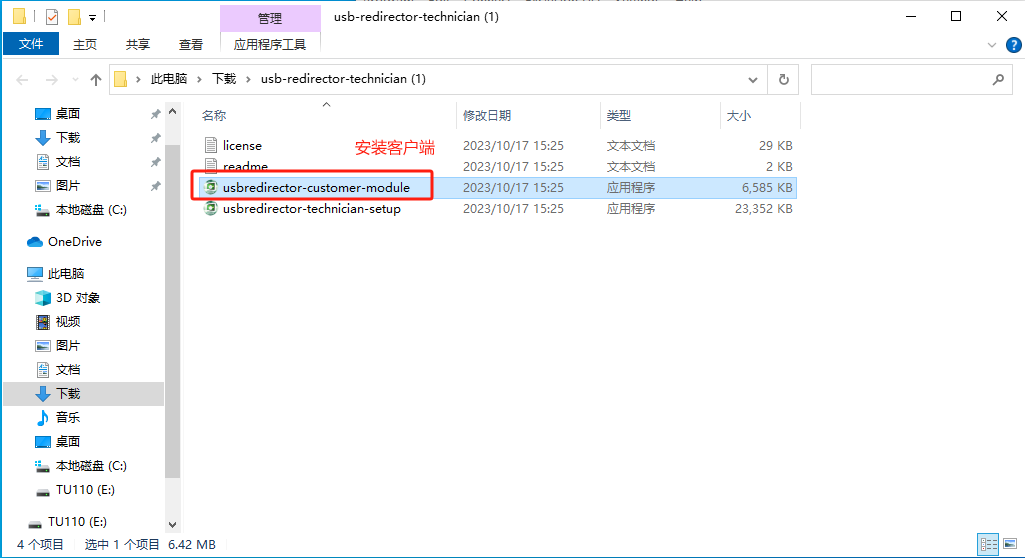
继续点击第二个安装包,下载安装USB服务端。
1.2 下载安装cpolar内网穿透
这里我们用cpolar内网穿透工具,它支持http/https/tcp协议,不需要公网IP,不需要设置路由器,使用不限制流量。
cpolar官网:https://www.cpolar.com/
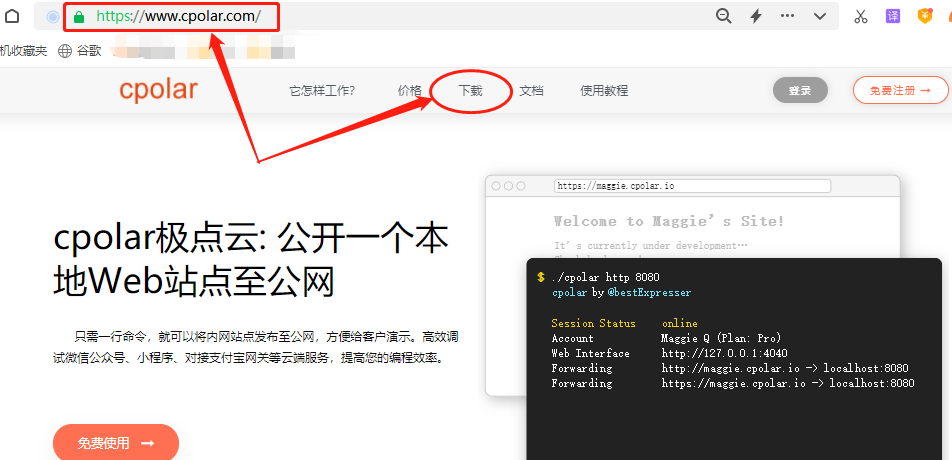
在cpolar的下载页面中,找到对应版本的cpolar安装程序,笔者使用的是Windows操作系统,因此选择Windows版下载。
下载完成后,将下载的文件解压,并双击其中的.msi文件,就能自动执行cpolar的安装程序,我们只要一路Next,就能完成安装。
由于cpolar会为每个用户创建独立的数据隧道,并辅以用户密码和token码保证数据安全,因此我们在使用cpolar之前,需要进行用户注册。注册过程也非常简单,只要在cpolar主页右上角点击用户注册,在注册页面填入必要信息,就能完成注册。
注册完后,登录cpolar的客户端,(可以在浏览器中输入localhost:9200直接访问,也可以在开始菜单中点击cpolar客户端的快捷方式),点击客户端主界面左侧隧道管理——创建隧道按钮,进入本地隧道创建页面
-
隧道名称:可以看做cpolar本地的隧道信息注释,只要方便我们分辨即可 -
协议:选择http协议 -
本地地址:本地地址即为本地网站的输出端口号,USB内网默认端口为32038,这里填入32038(这个是固定的服务端口) -
域名类型:如果打算创建临时数据隧道,则直接勾选“随机域名”,由cpolar客户端自行生成网络地址 -
地区:与cpolar云端预留的信息一样,我们依照实际使用地填写即可
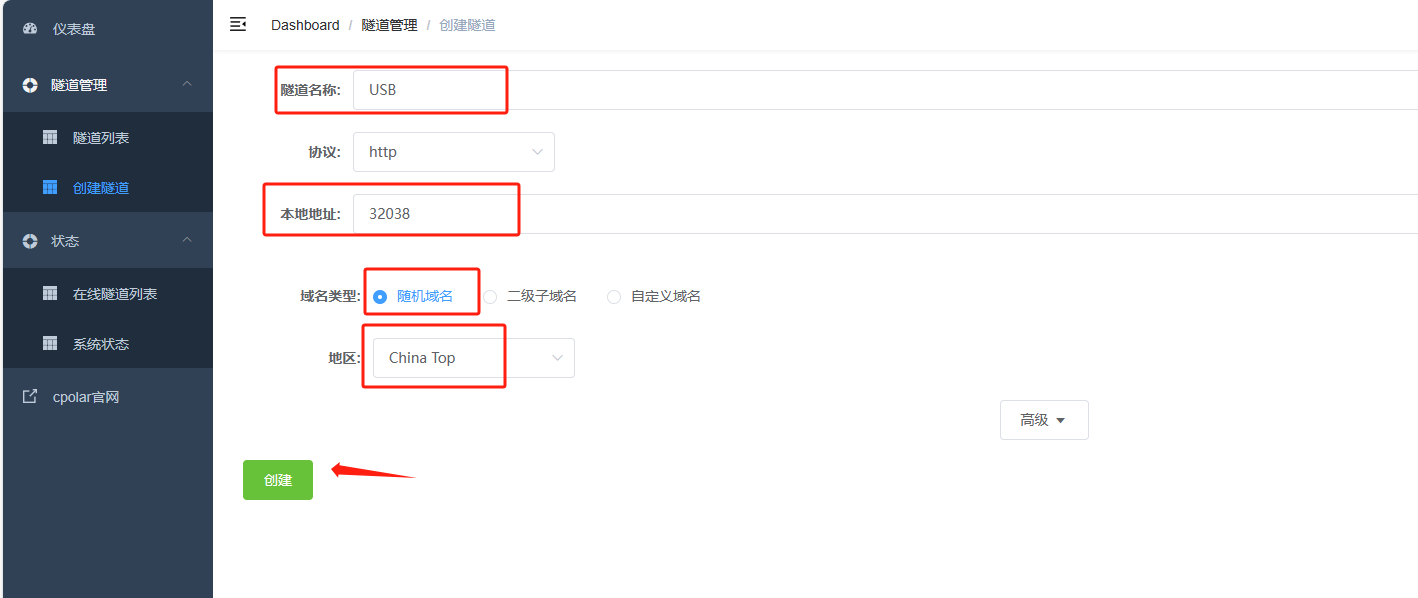
完成这些设置后,就可以点击下方按钮。
数据隧道创建完成后,cpolar会自动跳转至隧道管理——隧道列表页面。在这个页面,我们可以对这条数据隧道进行管理,包括开启、关闭或删除这条隧道,也可以点击编辑按钮,对这条数据隧道的信息进行修改。
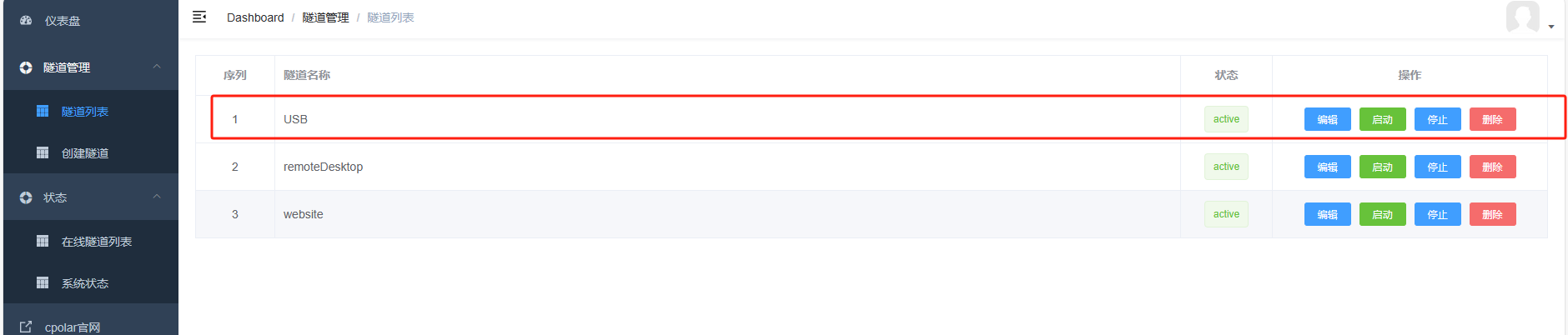
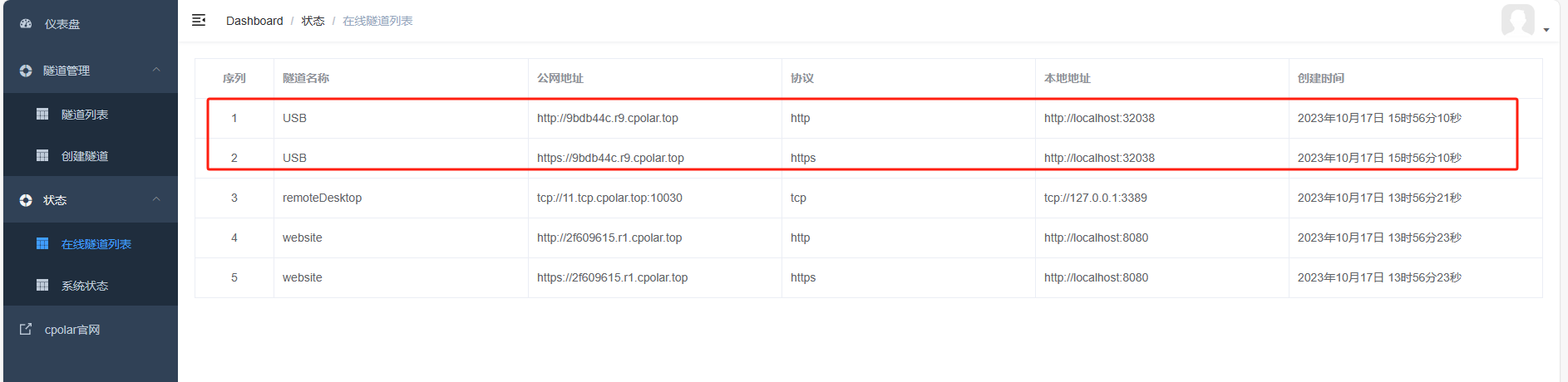
USB数据隧道入口(公共互联网访问地址),则可以在状态——在线隧道列表中找到。
复制两个隧道的任意一个公网地址,粘贴到公网浏览器中。
2. 完成USB Redirector服务端和客户端映射连接
在客户端直接双击打开 USB Redirector Technician Edition-custormer module 这个程序。
然后一直点Next。
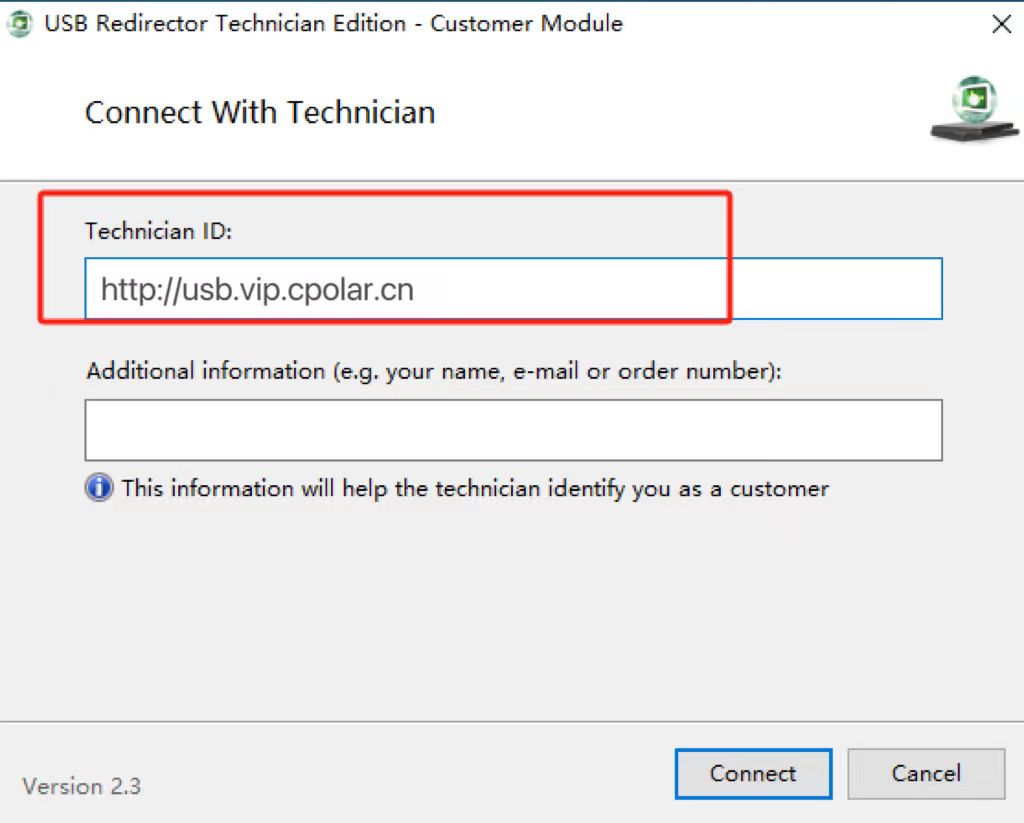
输入刚才复制的公网地址,下方输入自己名字备注给服务端。
点击Connect
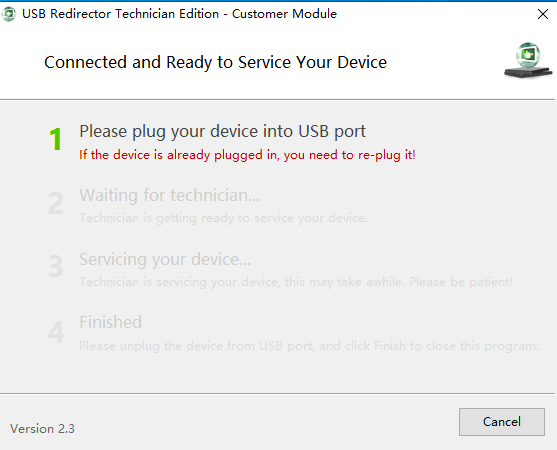
提示重新拔插下U盘设备
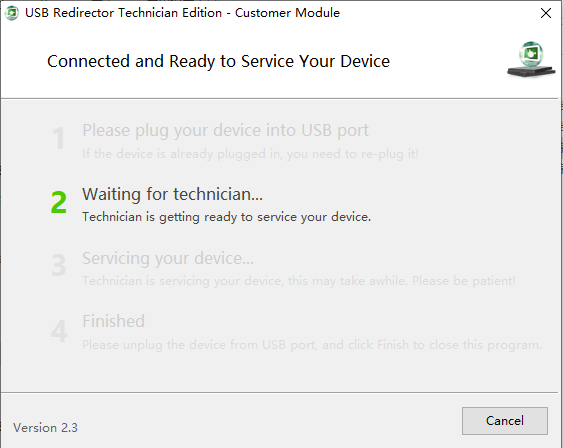
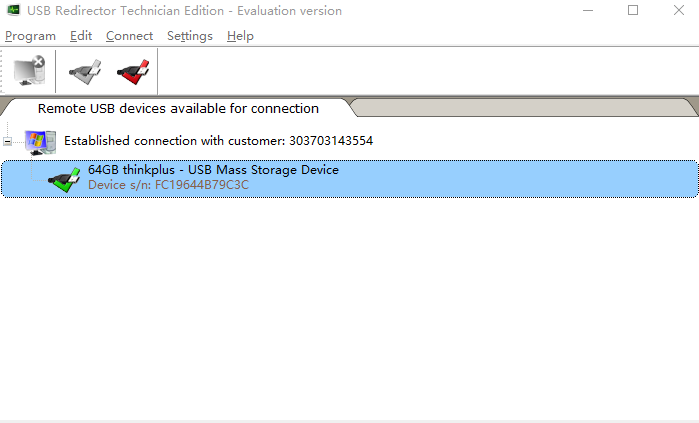
等待服务端连接,服务端点击上方绿色对号图标
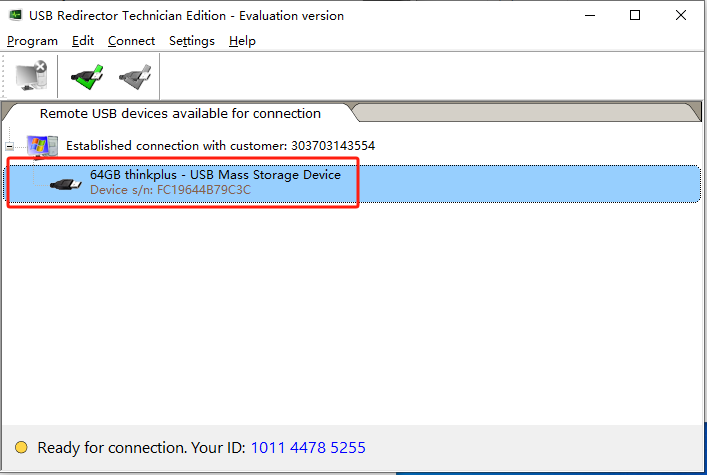
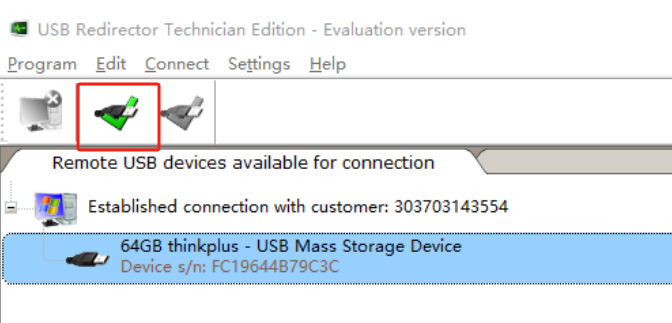
服务端连接到客户端的USB设备
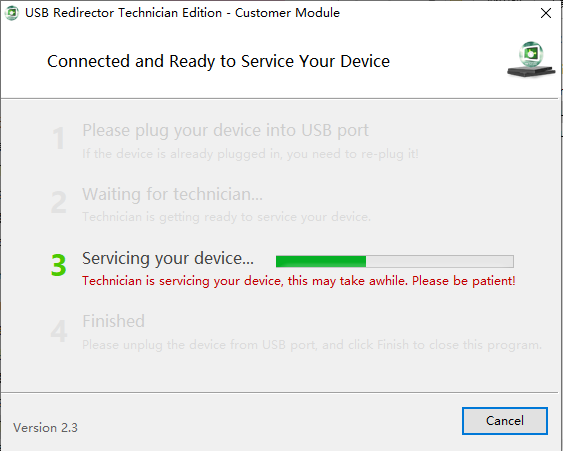
这时,在服务端的电脑上可以看到显示了USB设备,并进行远程的维修设置了。
3. 设置固定的公网地址
由于以上使用cpolar所创建的隧道使用的是随机公网地址,24小时内会随机变化,不利于长期远程访配置映射。因此我们可以为其配置二级子域名,该地址为固定地址,不会随机变化。
登录cpolar官网,点击左侧的预留,选择保留二级子域名,设置一个二级子域名名称,点击保留,保留成功后复制保留的二级子域名名称。
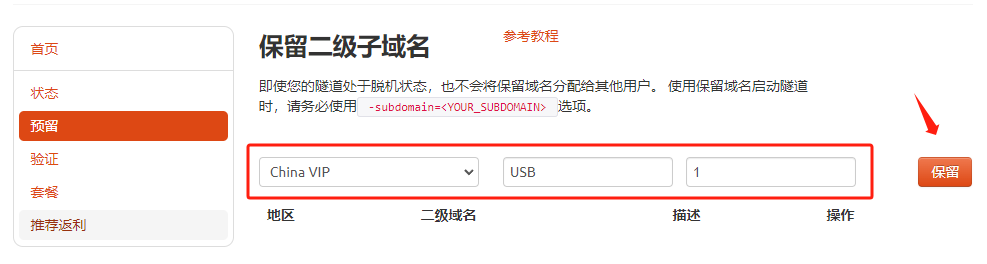
保留成功后复制保留成功的二级子域名的名称
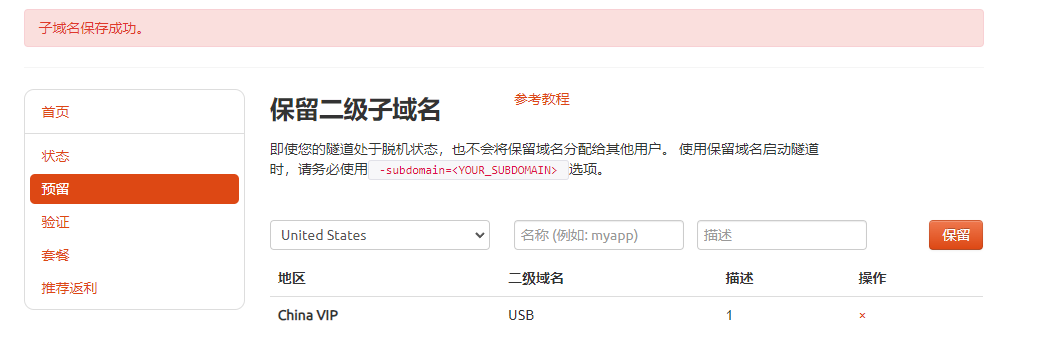
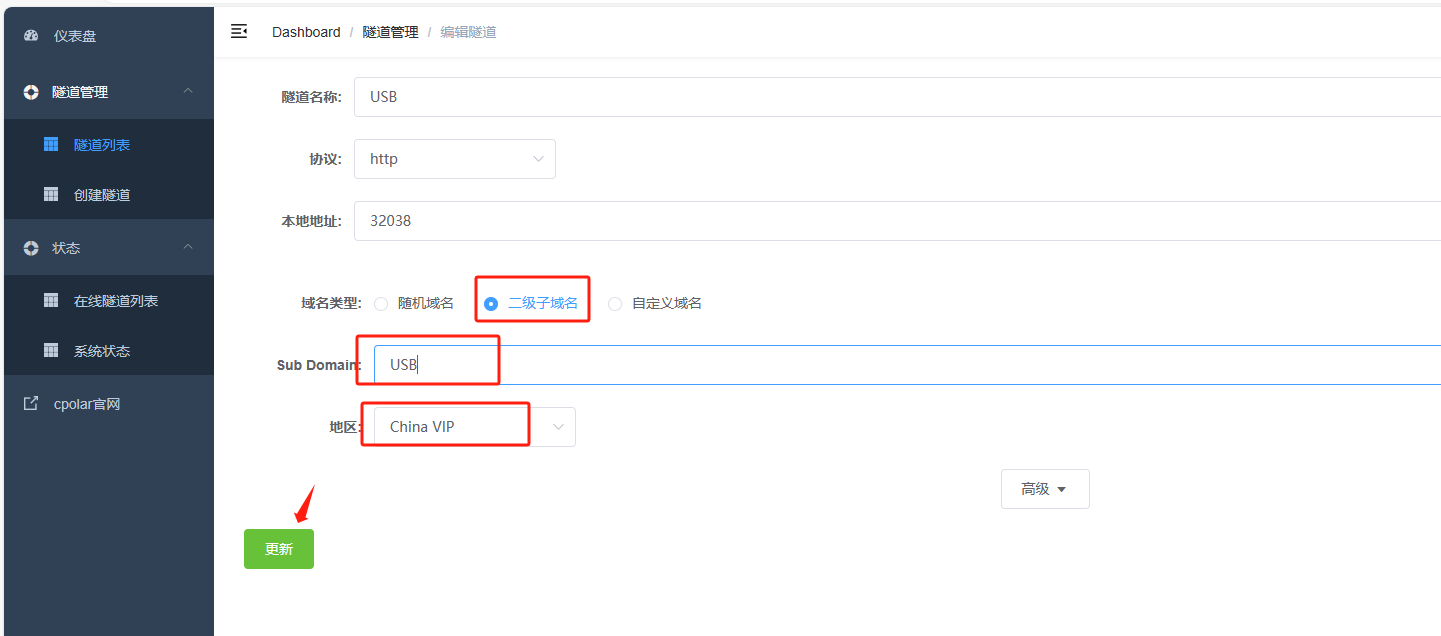
返回登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到所要配置的隧道,点击右侧的编辑

修改隧道信息,将保留成功的二级子域名配置到隧道中
- 域名类型:选择二级子域名
- Sub Domain:填写保留成功的二级子域名
点击更新(注意,点击一次更新即可,不需要重复提交)
更新完成后,打开在线隧道列表,此时可以看到公网地址已经发生变化,地址名称也变成了固定的二级子域名名称的域名
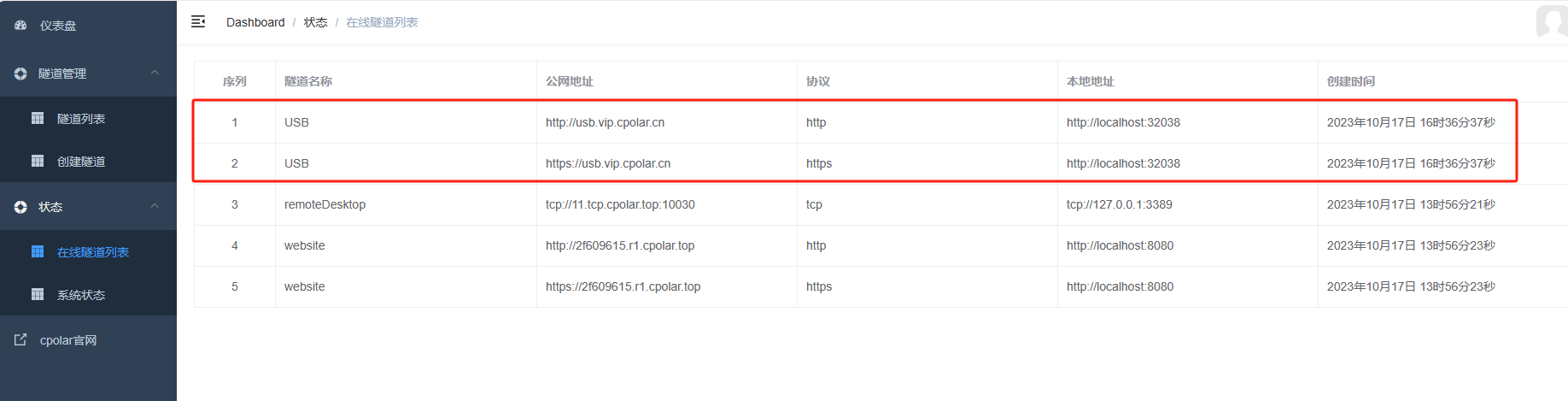
最后,我们使用固定的公网地址访问,可以看到访问成功,这样一个固定且永久不变的公网地址就设置好了,随时随地都可以远程访问USB Redirector客户端界面,提高工作效率!
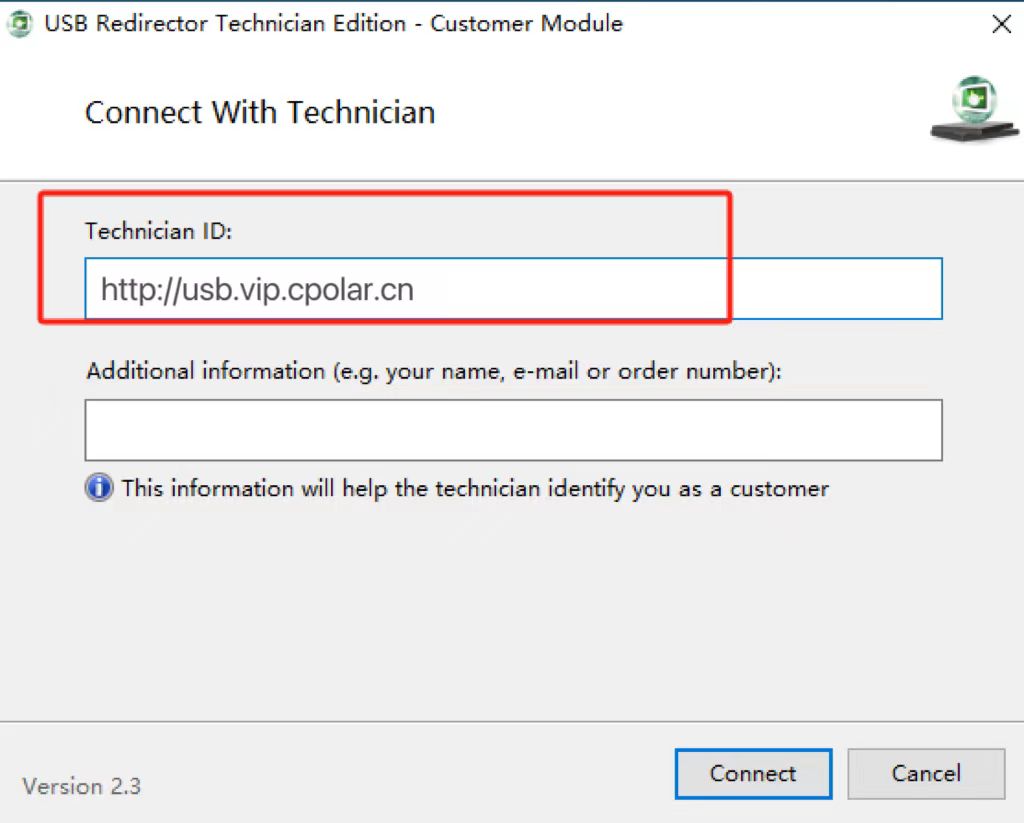
最后,我们使用固定的公网地址访问,可以看到访问成功,这样一个固定且永久不变的公网地址就设置好了,随时随地都可以远程访问USB Redirector客户端界面,提高工作效率!
USB Redirector是一款真正改变了我们使用和管理USB设备方式的神器。它不仅功能强大、操作简便,还能与cpolar内网穿透完美结合,让你随时随地都能享受到高效便捷的技术带来的便利。无论是工作还是生活中的各种场景,有了这款工具,你再也不会因为设备不在身边而烦恼了!快来试试吧,相信你会爱上它的!